
01 Spark架构与运行流程
1. 阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系,为什么要引入Yarn和Spark。
(1)引用Yarn是为了解决原始Hadoop扩展性差,不支持多计算框架而提出的
(2)Spark的速度比Hadoop更快。同样的事情,Hadoop要两分钟,而Spark可能只需要1秒。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成一套完整生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark可以部署在资源管理器YARN之上,提供一站式的大数据解决方案。因此,Spark所提供的生态系统同时支持批处理、交互式查询和流数据处理。
3. 用图文描述你所理解的Spark运行架构,运行流程。
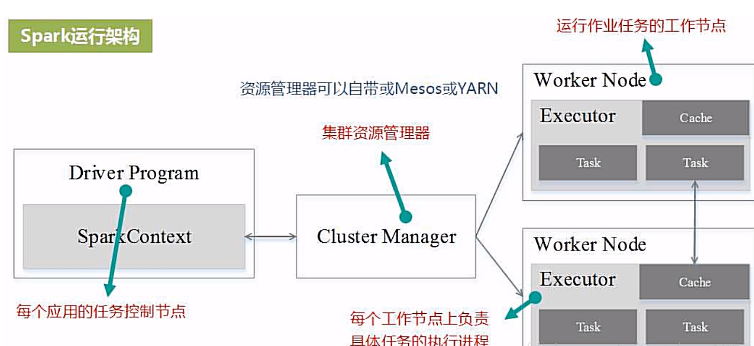
(1)Spark运行架构
Spark包括Cluster Manager、Worker Node、Driver和Executor。Cluster Manager可以是Spark自带的资源管理器,也可以是其它资源管理框架。就系统架构而言,Spark采用“主从架构”。
在Spark中,一个应用由一个任务控制节点和若干个作业构成再往下细分是阶段和任务。
执行一个应用时,任务控制节点向集群管理器申请资源,启动Executor 并向其发送信息,然后在Executor上执行任务。运行结束后返回结果。
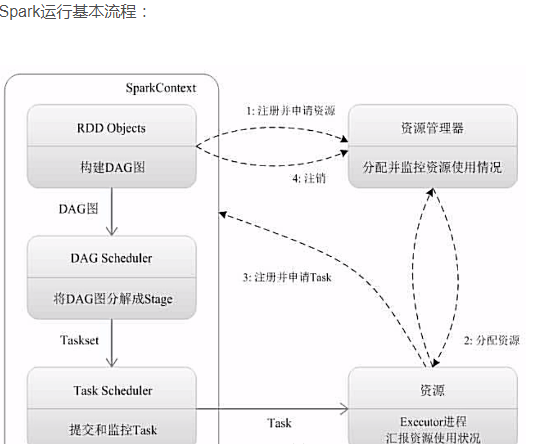
(2)Spark运行基本流程
为应用构建运行环境,资源管理器为其分配资源,启动相关的进程。
进行其他的相关准备。
运行后反馈结果,最后写入数据并释放所有资源。
4. 软件平台准备:Linux-Hadoop。
