(十一) 数据库查询处理之连接(Join)
(十一) 数据库查询处理之连接(Join)
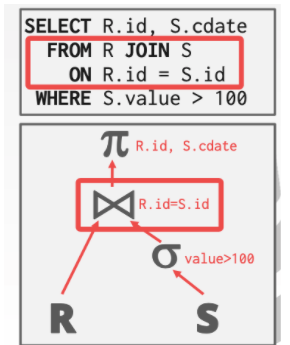
1. 连接操作的一个例子
把外层关系和内层关系中满足一定关系的属性值拼接成一个新的元组
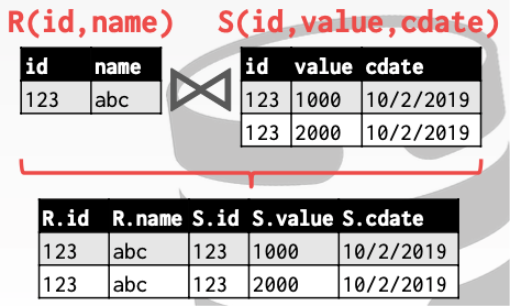
一种现在仍然十分有用的优化思路Late Materialization
在匹配记录的时候先只复制join keys. 对于上面的例子

这种机制非常适合列存储,因为DBMS不复制查询不需要的数据。剩下需要的元素则在连接之后在进行copy。
2. 连接算法
2.1 Nested Loop Join
2.1.1 Simple / Stupid
就是简单的二重循环暴力搜索。
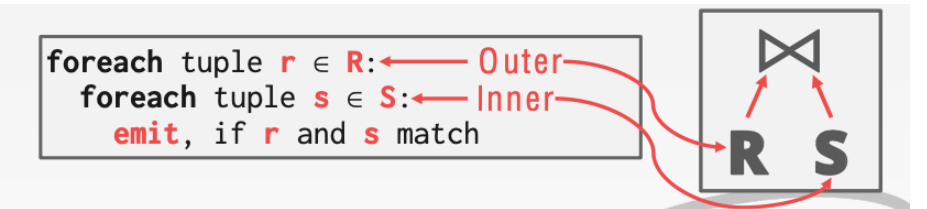
可以非常简单的分析这个时间复杂度就是\(N_S \times N_R\)
2.1.2 Block
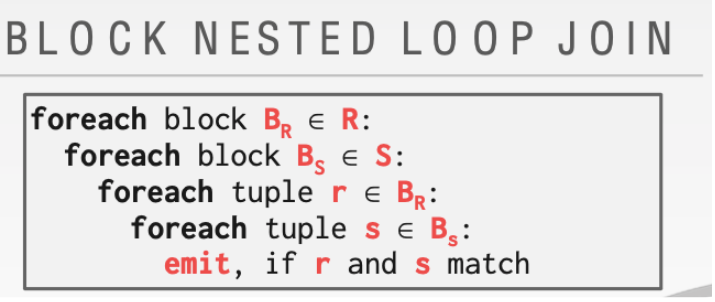
可以发现代码整体和上面的傻瓜版本差别并不大。但是可以让时间复杂度有一个显著提高。下面进行分析

主要的改进就是在这里。这里只需要一次磁盘访问。所以会显著的降低时间消耗。改进思想来自于缓冲区太小不能放下整个关系。但是可以放下一个块的关系。
如果我们有B个buffer可以用
对于R有M个Pages、m个tuples。S有N个Pages、n个tuples。
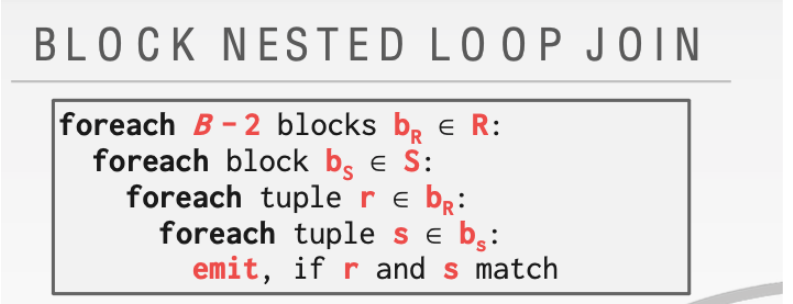
由于可以用B - 2 个buffer来sacn 关系R所以时间复杂度就可以减少非常多。因为我们把m个关系R中的tuple读到内存中只需要
\(M/(B - 2)\) 次。
2.1.2 Index
如果利用索引的话。我门就可以避免顺序查找了。

对于外层循环中的每一个元素。我们利用索引在内层关系中进行查找。假设索引所带来的消耗为C
所以总的时间就变成了\(M + (m \times C)\)
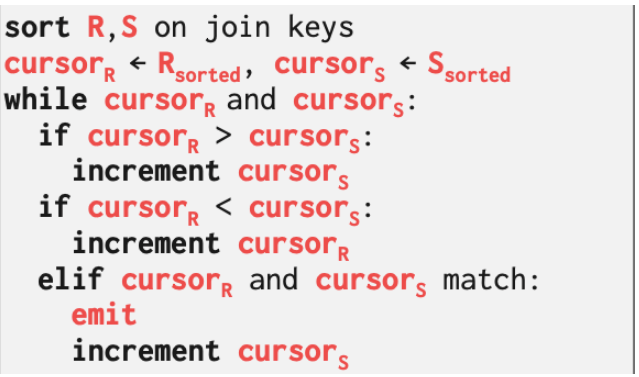
2.2 Sort - Merge - Join
又称为sort - merge -join算法。其大抵思想可以参考双指针算法
具体例子如下

然后就是经典的双指针匹配问题了
R: 100、200、300、400、500、600、700
S :100、100、200、400、500
如果匹配就输出。并且内层关系的指针向下移动。

如果不匹配外层关系的指针向下移动
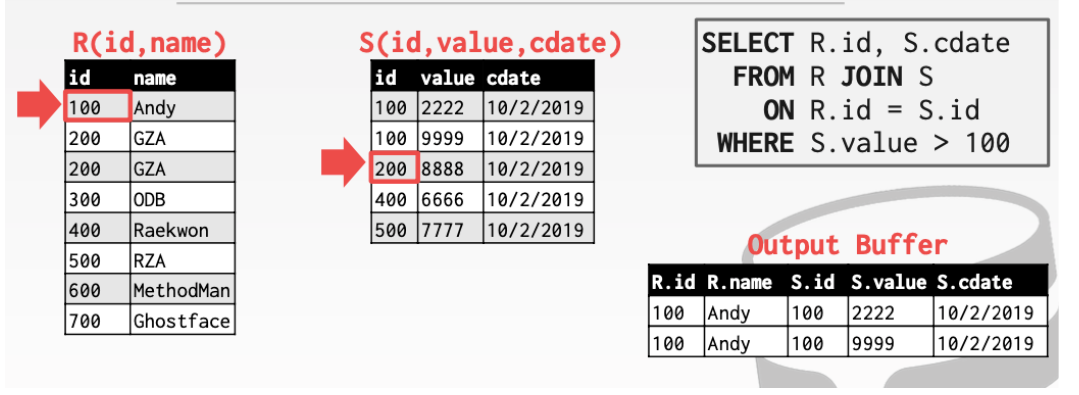
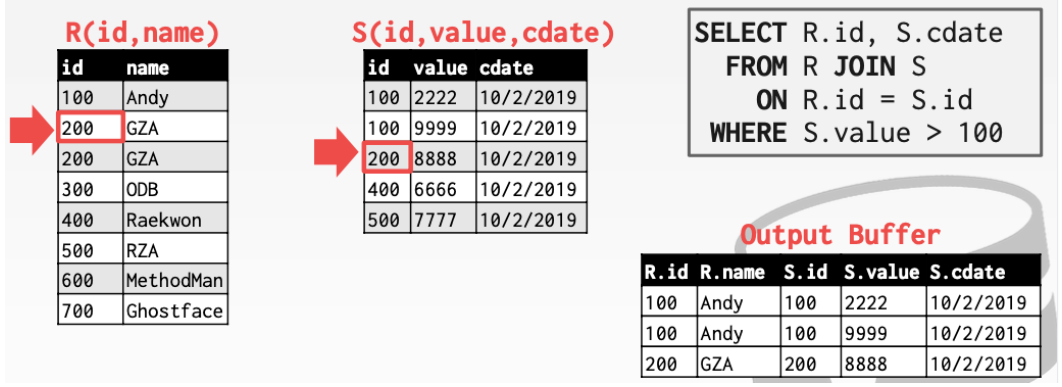
以此类推就可以完成join操作。想一想归并排序就是这样做的。
复杂度分析
由两部分组成。一部分是排序的消耗另一部分就是merge的消耗

2.3 Hash Join
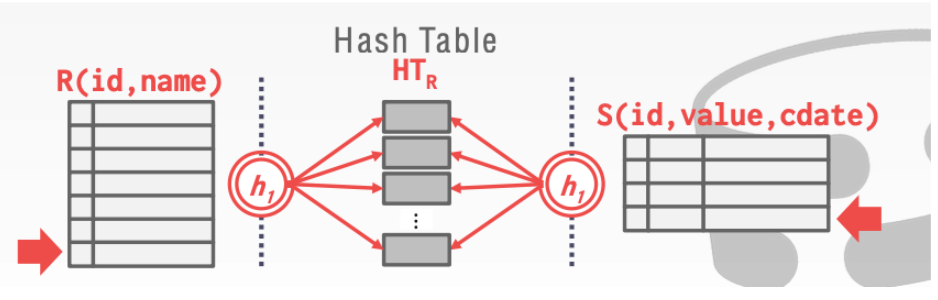
1. 基本的hash连接算法
- 建立对于关系R的hash表

-
在该hash表上进行probe
如果在关系S中的id拥有和关系R中id一样的值。那么他们利用相同的hash函数进行映射之后。就必然会去到相同的桶内。
2. Probe 阶段的优化
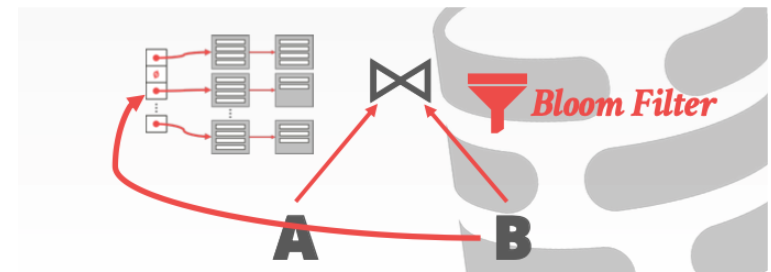
可以创建Bloom Filter进行优化。
何谓Bloom Filter
Bloom-Filter,即布隆过滤器,是一种多哈希函数映射的快速查找算法。通常应用在一些需要快速检测一个元素是否在一个集合中,但是并不严格要求100%正确的场合。Bloom Filter的空间利用效率很高,使用位数组表示一个待检测集合,使用它可以大大节省存储空间。利用这个算法我们可以实现去重效果。
Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不在集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误(不在的一定不在,在的不一定在)。
看一个例子。如果我们存入baidu
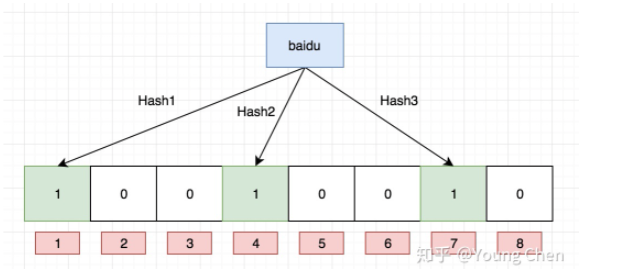
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:

加入我们现在查询alibaba。它经过哈希函数如果返回3、7、8我们会发现这三个位全为1.这样如果我们就会认为alibaba已经存在了。所以这也就是Bloom Filter不保证完全正确的原因。
引入Bloom Filter之后我们可以在探测之前先利用它进行判断。
3. GRACE HASH JOIN
适合于内存比较小的情况
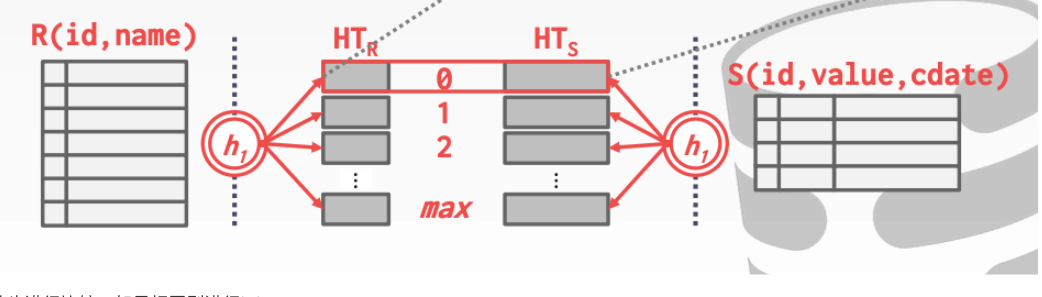
从头进行比较。如果相同则进行join
如果某一个桶内的元素太多。内存中无法放下。则进行递归分块。利用不同的hash函数进行rehash
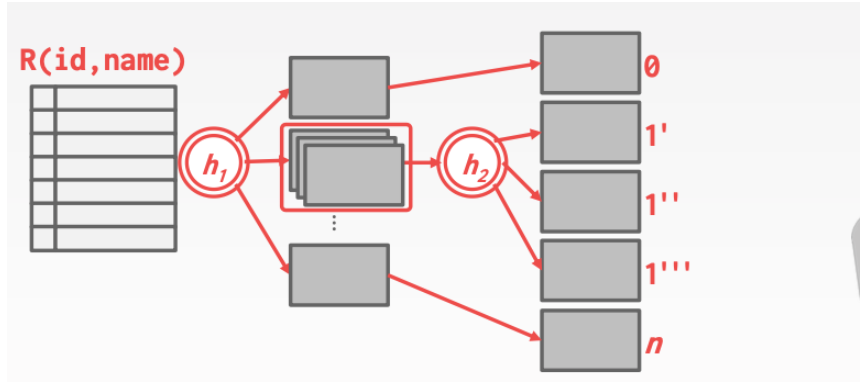
时间复杂度分析


 浙公网安备 33010602011771号
浙公网安备 33010602011771号