1. 基础算法(I)
1.1 排序算法
排序算法(英语:Sorting algorithm)是一种将一组特定的数据按某种顺序进行排列的算法。排序算法多种多样,性质也大多不同。我们评价一种排序算法,主要考虑以下 \(3\) 个方面:
- 稳定性:即排序后数组内相同的数的相对顺序是否发生了变化。更为形式化地,若在原本的数组中 \(a=b\) 且 \(a\) 在 \(b\) 之前,排序后的数组中 \(a\) 仍然在 \(b\) 之前,则称该排序算法是稳定的,否则称该排序算法是不稳定的。
- 时间复杂度:即该排序算法的时间复杂度的上限。基于比较的排序算法的最优时间复杂度是 \(O(n\log n)\) 的。
- 空间复杂度:即该算法所占的空间规模(相对考虑较少)。
下图(图 \(\texttt{1-1}\))展示了各种排序算法的时间复杂度比较:

1.1.1 基本排序算法
以下的“排序”皆指将数组从小到大排序,且下标默认从 \(1\) 开始。
1.1.1.1 选择排序
选择排序的基本过程:
- 遍历整个未排序的数组,找到最小的一个数,将其与数组的首个未排序元素交换。
- 重复第 1 步,直至所有数都已经排序。
例如,将数组 \(a=\{2,4,3,1\}\) 排序。第 \(1\) 次遍历从第 \(1\) 个数开始,找到最小的数是 \(1\),将 \(1\) 和第 \(1\) 个数 \(2\) 交换,此时数组变为 \(\{1,4,3,2\}\);第 \(2\) 次遍历从第 \(2\) 个数开始,找到最小的数是 \(2\),将 \(2\) 和第 \(2\) 个数 \(3\) 交换,此时数组变为 \(\{1,2,4,3\}\)……以此类推,最终得到排序后的 \(a\) 数组为 \(\{1,2,3,4\}\)。
选择排序是一种不稳定的排序算法,时间复杂度 \(O(n^2)\)。
1.1.1.2 冒泡排序
冒泡排序的基本过程:
- 遍历整个数组,若 \(a_i>a_{i+1}\),则交换 \(a_i,a_{i+1}\)。
- 重复第 1 步,直至 \(\forall i\in [1,n)\),不存在 \(a_i>a_{i+1}\)。
例如,将数组 \(a=\{2,4,3,1\}\) 排序。第 \(1\) 次遍历,由于 \(a_2>a_3\),所以交换 \(a_2,a_3\),得到 \(\{2,3,4,1\}\),此时又有 \(a_3>a_4\),所以交换 \(a_3,a_4\),得到 \(\{2,3,1,4\}\);第 \(2\) 次遍历,由于 \(a_2>a_3\),所以交换 \(a_2,a_3\),得到 \(\{2,1,3,4\}\)……以此类推,最终得到排序后的 \(a\) 数组是 \(\{1,2,3,4\}\)。
冒泡排序是一种稳定的排序算法,时间复杂度见下表:
| 最好情况 | 平均情况 | 最坏情况 |
|---|---|---|
| \(O(n)\) | \(O(n^2)\) | \(O(n^2)\) |
1.1.1.3 插入排序
插入排序的基本过程:
- 将所有元素分为“已排序”和“待排序”两组。
- 将“待排序”中的第 \(1\) 个元素插入至“已排序”中正确的位置。
- 重复第 2 步,直到所有元素都位于“已排序”中。
例如,将数组 \(a=\{2,4,3,1\}\) 排序。首先“已排序”组中没有数,“未排序”组中的数为 \(\{2,4,3,1\}\)。第 \(1\) 次将 \(2\) 插入“已排序”组中,此时“已排序”组中的数为 \(\{2\}\),“未排序”组中的数为 \(\{4,3,1\}\);第 \(2\) 次将 \(4\) 插入“已排序”组中,由于 \(2<4\),所以此时“已排序”组中的数为 \(\{2,4\}\),“未排序”组中的数为 \(\{3.1\}\);第 \(3\) 次将 \(3\) 插入“已排序”组中,由于 \(2<3<4\),所以此时“已排序”组中的数为 \(\{2,3,4\}\),“未排序”组中的数是 \(1\)……以此类推,最终得到排序后的 \(a\) 数组是 \(\{1,2,3,4\}\)。
插入排序是一种稳定的排序算法,时间复杂度见下表:
| 最好情况 | 平均情况 | 最坏情况 |
|---|---|---|
| \(O(n)\) | \(O(n^2)\) | \(O(n^2)\) |
1.1.1.4 其他排序算法
- 计数排序 稳定,\(O(n+w)\)。
- 基数排序 在值域较小时可以使用,稳定,\(O\left(kn+\displaystyle\sum_{i=1}^kw_i\right)\)。
- 希尔排序 对插入排序的改进,不稳定,最优 \(O(n)\),最优的最坏复杂度为 \(O(n\log^2n)\)。
- 堆排序 不稳定,\(O(n\log n)\)。
- 桶排序 稳定,最优 \(O(n+n^2/k+k)\)(当 \(k\approx n\) 时接近 \(O(n)\)),最坏 \(O(n^2)\)。
1.1.2 快速排序
题目:给你一个长度为 \(n\) 的数组 \(a\),将这个数组从小到大排序。\(1\le n\le 10^5,1\le a_i\le 10^9\)。
思路:
运用分治的思想。对区间 \([l,r]\) 进行快速排序的步骤如下:
- 依据参照值 \(x\) 将数列划分为两部分,小于等于 \(x\) 的放在左边,大于 \(x\) 的放在右边。
- 将左右两边分别进行快速排序。
- 直接将左右两边拼接在一起。
那么只要解决了第 1 步,我们就完成了快速排序。\(x\) 的取值一般为区间左端点 \(l\),区间右端点 \(r\),区间中点 \(mid=\left\lfloor\dfrac{l+r}{2}\right\rfloor\) 或随机选取。维护两个指针 \(i,j\),如果 \(a_i>x\) 则将其放至右侧,如果 \(a_j\le x\) 则将其放至左侧。
快速排序是一种不稳定的排序算法,最优和平均时间复杂度为 \(O(n\log n)\),最坏时间复杂度为 \(O(n^2)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n;
int q[N];
void qsort(int q[], int l, int r) {
if (l >= r) return ; //边界条件
int x = q[(l+r)/2]; //选取界点x
int i = l-1, j = r+1;
while (i < j) { //将数组以x为分界点划分为两部分
do i ++; while (q[i] < x);
do j --; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
qsort(q, l, j), qsort(q, j+1, r); //继续递归划分两边
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) scanf("%d", &q[i]);
qsort(q, 1, n);
for (int i = 1; i <= n; ++i) printf("%d ", q[i]);
return 0;
}
题目:给你一个长度为 \(n\) 的数组 \(a\),求出其中第 \(k\) 大的数。\(1\le k\le n\le 10^5,1\le a_i\le 10^9\)。
思路:对数组 \(a\) 进行快速排序后直接输出 \(a_{k}\) 即可,时间复杂度 \(O(n\log n)\)。 本题实际上还有期望 \(O(n)\) 做法:即在划分区间时按照左边元素个数 \(i-l+1\) 和 \(k\) 的大小关系来递归求解。
1.1.3 归并排序
题目:给你一个长度为 \(n\) 的数组 \(a\),将这个数组从小到大排序。\(1\le n\le 10^5,1\le a_i\le 10^9\)。
思路:
运用分治的思想。对区间 \([l,r]\) 进行归并排序的步骤如下:(其中 \(mid=\left\lfloor\dfrac{l+r}{2}\right\rfloor\))
- 递归排序区间 \([l,mid]\) 和 \([mid+1,r]\)。
- 定义数组 \(tmp\),将 \([l,r]\) 之间的数按从小到大的顺序存入 \(tmp\) 中。
- 将 \(tmp\) 中的数覆盖至区间 \([l,r]\) 上。
归并排序的重点在于第 2 步。维护三个指针 \(i,j,k\),若 \(a_i\le a_j\),则 \(tmp_k=a_i\),否则 \(tmp_k=a_j\)。
归并排序是稳定的排序算法,时间复杂度 \(O(n\log n)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n;
int q[N], tmp[N];
void msort(int q[], int l, int r) {
if (l >= r) return ; //边界条件
int mid = l + r >> 1;
msort(q, l, mid), msort(q, mid+1, r); //递归排序区间[l,mid]和[mid+1,r]
int i = l, j = mid+1, k = 1; //[l,mid]和[mid+1,r]已经排好序,将它们按从小到大的顺序存入tmp中
while (i <= mid && j <= r) { //每次将ai,aj中较小的一个存入tmp中
if (q[i] <= q[j]) tmp[k ++] = q[i ++];
else tmp[k ++] = q[j ++];
}
while (i <= mid) tmp[k ++] = q[i ++]; //如果左边还没有存完,就继续存
while (j <= r) tmp[k ++] = q[j ++]; //如果右边还没有存完,就继续存
for (int i = l, j = 1; i <= r; ++i, ++j) q[i] = tmp[j]; //将tmp中的数覆盖至区间[l,r]上
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) scanf("%d", &q[i]);
msort(q, 1, n);
for (int i = 1; i <= n; ++i) printf("%d ", q[i]);
return 0;
}
题目:我们定义:在数组 \(a\) 中若 \(i<j\) 且 \(a_i>a_j\),则称 \((i,j)\) 是一个逆序对。给你一个长度为 \(n\) 的数组 \(a\),求出 \(a\) 中逆序对的数量。\(1\le n\le 10^5,1\le a_i\le 10^9\)。
思路:
定义 \(f(l,r)\) 表示区间 \([l,r]\) 中逆序对的数量。 想求出 \(f(l,r)\),我们可以分类讨论。
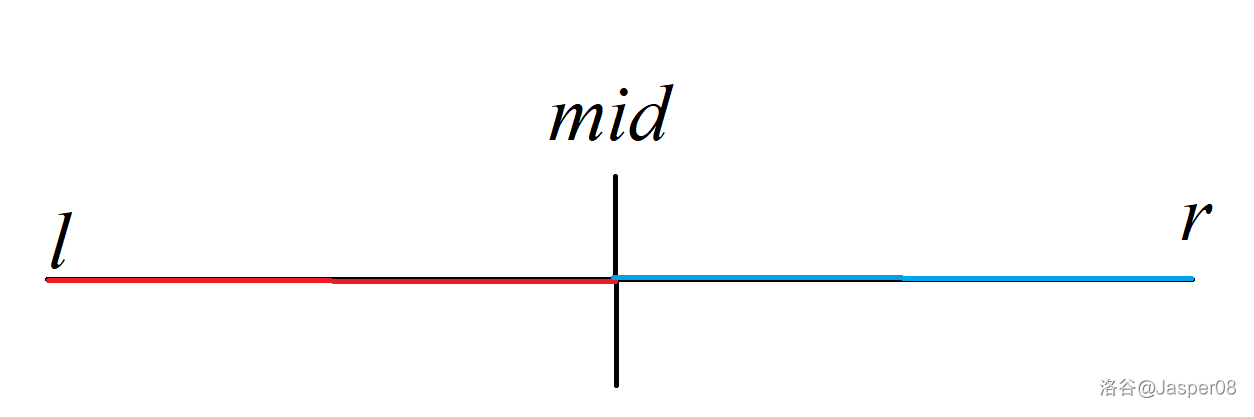
如图 \(\texttt{1-2}\),以区间中点 \(mid=\left\lfloor\dfrac{l+r}{2}\right\rfloor\) 为分界线,逆序对 \((i,j)\) 可以分为 \(3\) 种情况:
- \(l\le i<j\le mid\):即 \(i,j\) 均位于 \(mid\) 左边。这种情况的逆序对数量显然是 \(f(l,mid)\)。
- \(mid<i<j\le r\):即 \(i,j\) 均位于 \(mid\) 右边。这种情况的逆序对数量显然是 \(f(mid,r)\)。
- \(l\le i\le mid<j\le r\):即 \(i\) 位于 \(mid\) 左边,\(j\) 位于 \(mid\) 右边。不妨先把区间 \([l,mid]\) 和 \((mid,r]\) 都从小到大排好序(并不会影响逆序对数量)。那么对于若 \(a_i>a_j\),则 \(a_{i+1}\sim a_{mid}\) 也均大于 \(a_j\)。
以上的 \(3\) 种情况,可以通过归并排序的过程求出。
时间复杂度 \(O(n\log n)\)。
主要代码:
int msort(int q[], int l, int r) { //归并排序求逆序对
if (l >= r) return 0; //如果只有1个数,就不可能有逆序对,直接返回0
int mid = l + r >> 1;
int ans = msort(q, l, mid) + msort(q, mid+1, r); //第1种情况和第2种情况
int i = l, j = mid+1, k = 1;
while (i <= mid && j <= r) { //计算第3种情况
if (q[i] <= q[j]) tmp[k ++] = q[i ++];
else tmp[k ++] = q[j ++], ans += mid-i+1; //如果ai>aj,则a{i+1}~a{mid}均大于aj,可以与j构成逆序对
}
while (i <= mid) tmp[k ++] = q[i ++];
while (j <= r) tmp[k ++] = q[j ++];
for (int i = l, j = 1; i <= r; ++i, ++j) q[i] = tmp[j];
return ans;
}
1.2 二分
1.2.1 整数二分
题目:给你一个长度为 \(n\) 的按升序排列的数组 \(a\) 和 \(q\) 次询问,每次询问给出一个整数 \(k\),求出 \(k\) 在 \(a\) 中的起始位置与结束位置(位置从 \(0\) 开始计数,若 \(k\) 不存在则输出 -1 -1)。\(1\le n\le 10^5,1\le q\le 10^4, 1\le k,a_i\le 10^4\)。
思路:
由于题目已经排好序了,所以我们可以采用二分的方法。如何进行二分呢?如图 \(\texttt{1-3}\),将区间 \([l,r]\) 从中间分为两段。
- 寻找 \(k\) 的起始位置时,取 \(mid=\left\lfloor\dfrac{l+r}{2}\right\rfloor\)。 由于 \(a\) 是不严格单调递增的,当 \(a_{mid}\ge k\) 时,\(k\) 一定在区间 \([l,mid]\) 中;否则,当 \(a_{mid}<k\) 时,\(k\) 一定在区间 \((mid,r]\) 中。
- 寻找 \(k\) 的结束位置时,取 $$mid=\left\lfloor\dfrac{l+r+1}{2}\right\rfloor$$。 当 \(a_{mid}\le k\) 时,\(k\) 一定在区间 \([mid,r]\) 中;否则,当 \(a_{mid}>k\) 时,\(k\) 一定在区间 \([l,mid)\) 中。
如上,整数二分写法有 \(2\) 种:
- 缩小范围时,\(r=mid\) 或 \(l=mid+1\),取中间值时,\(mid=(l+r)/2\)。
- 缩小范围时,\(l=mid\) 或 \(r=mid-1\),取中间值时,\(mid=(l+r+1)/2\)。
时间复杂度 \(O(q\log n)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n, q;
int a[N];
int findl(int k) { //寻找k的起始位置,注意这里下标从1开始,没找到返回0
int l = 1, r = n;
while (l < r) {
int mid = l + r >> 1;
if (a[mid] >= k) r = mid;
else l = mid+1;
}
return (a[l] == k) ? l : 0;
}
int findr(int k) { //寻找k的结束位置
int l = 1, r = n;
while (l < r) {
int mid = l + r + 1 >> 1; //注意一定要加上1,不然会出现错误
if (a[mid] <= k) l = mid;
else r = mid-1;
}
return (a[l] == k) ? l : 0;
}
int main() {
scanf("%d%d", &n, &q);
for (int i = 1; i <= n; ++i) scanf("%d", &a[i]);
while (q -- ) {
int k;
scanf("%d", &k);
int l = findl(k)-1; //由于题目中说了下标从1开始,所以要减去1
int r = findr(k)-1;
printf("%d %d\n", l, r);
}
return 0;
}
1.2.2 实数二分
题目:给你一个整数 \(n\),求出 \(\sqrt[3]n\),保留 \(6\) 位小数。\(-10^5\le n\le 10^5\)。
思路:类似整数二分,只需确定好所需的精度 \(eps\),以 \(l+eps<r\) 为循环条件,每次根据在 \(mid\) 上的判定选择 \(r=mid\) 或 \(l=mid\) 的分支之一即可。通常需要保留 \(k\) 位小数时,\(eps=10^{-k-3}\)。
时间复杂度 \(O(\log n)\)
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const double eps = 1e-9; //实数二分所取的误差值一般为所需求的小数位的1/1000左右
double n;
double cube_root(double n) { //求n的三次方根
double l = -100, r = 100;
while (r-l > eps) {
double mid = (l+r) / 2;
if (mid*mid*mid > n) r = mid;
else l = mid;
}
return l;
}
int main() {
cin >> n;
double ans = cube_root(n);
printf("%.6f\n", ans);
return 0;
}
1.3 高精度
1.3.1 高精度加法
题目:给你两个不含前导 \(0\) 的正整数 \(A,B\),计算 \(A+B\) 的值。\(1\le \lg A,\lg B\le 10^5\)。
思路:模仿竖式加法。
比如,计算 \(149+287\) 的值,我们通常是采用下图的方法:

那如何让计算机模拟加法的计算呢?主要有以下 \(3\) 步:
- 将输入的 \(A,B\) 反过来;
- 从最高位(即原来的最低位)开始,一位一位计算加法,同时记录每次的进位;
- 倒序输出最后的结果。
时间复杂度 \(O(\max(\log A,\log B))\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> add(vector<int> &A, vector<int> &B) {
int t = 0; //t记录进位
vector<int> C; //C存储结果
for (int i = 0; i < A.size() || i < B.size() || t; ++i) {
if (i < A.size())
t += A[i];;
if (i < B.size())
t += B[i];
C.push_back(t % 10);
t /= 10;
}
return C;
}
int main() {
string a, b;
cin >> a >> b;
vector<int> A, B;
for (int i = a.size()-1; i >= 0; --i) //将A,B反过来
A.push_back(a[i]-'0');
for (int i = b.size()-1; i >= 0; --i)
B.push_back(b[i]-'0');
vector<int> C = add(A, B);
for (int i = C.size()-1; i >= 0; --i) //倒序输出A,B之和
printf("%d", C[i]);
return 0;
}
1.3.2 高精度减法
题目:给你两个不含前导 \(0\) 的正整数 \(A,B\),计算 \(A-B\) 的值。\(1\le \lg A,\lg B\le 10^5\)。
思路:与高精度加法类似,模仿竖式计算即可。时间复杂度 \(O(\max(\log A,\log B))\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
bool cmp(vector<int> &A, vector<int> &B) { //比较A,B的大小
if (A.size() != B.size()) return A.size() > B.size();
for (int i = A.size()-1; i >= 0; --i) if (A[i] != B[i]) return A[i] > B[i];
return 1;
}
vector<int> sub(vector<int> &A, vector<int> &B) { //高精减
vector<int> C;
int t = 0;
for (int i = 0; i < A.size(); ++i) {
t = A[i] - t;
if (i < B.size()) t -= B[i];
C.push_back((t+10) % 10);
t = (t >= 0) ? 0 : 1;
}
while (C.back() == 0 && C.size() > 1) C.pop_back();
return C;
}
int main() {
string a, b;
cin >> a >> b;
vector<int> A, B;
for (int i = a.size()-1; i >= 0; --i) A.push_back(a[i]-'0');
for (int i = b.size()-1; i >= 0; --i) B.push_back(b[i]-'0');
vector<int> C;
if (cmp(A, B)) C = sub(A, B);
else putchar('-'), C = sub(B, A); //如果B>A,说明A-B为负数,先输出负号,再计算B-A
for (int i = C.size()-1; i >= 0; --i) printf("%d", C[i]);
return 0;
}
1.3.3 高精度乘法
1.3.3.1 高精乘低精
题目:给你两个不含前导 \(0\) 的非负整数 \(A,B\),计算 \(A\times B\) 的值。\(1\le \lg A\le 10^5,1\le B\le 10^5\)。
思路:将 \(B\) 视作一个整体,模仿竖式计算即可。时间复杂度 \(O(\log A)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> mul(vector<int> &A, int b) { //高精乘
vector<int> C;
int t = 0;
for (int i = 0; i < A.size() || t; ++i) {
if (i < A.size()) t += A[i] * b;
C.push_back(t % 10);
t /= 10;
}
while (C.back() == 0 && C.size() > 1) C.pop_back();
return C;
}
int main() {
string a; int b;
cin >> a >> b;
vector<int> A;
for (int i = a.size()-1; i >= 0; --i) A.push_back(a[i]-'0');
vector<int> C = mul(A, b);
for (int i = C.size()-1; i >= 0; --i) printf("%d", C[i]);
return 0;
}
1.3.3.2 高精乘高精
题目:给你两个不含前导 \(0\) 的非负整数 \(A,B\),计算 \(A\times B\) 的值。\(1\le \lg A,\lg B\le 10^5\)。
思路:
与高精加不同的是,高精乘高精的进位在最后统一处理。其余与竖式计算类似:
循环遍历 \(A\) 和 \(B\) 的每一位,对于 \(A\) 的第 \(i\) 位和 \(B\) 的第 \(j\) 位,在不考虑进位的情况下,显然有 \(C_{i+j}=A_i\times B_j\)。
时间复杂度 \(O(\log (A\cdot B))\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> mul(vector<int> &A, vector<int> &B) {
vector<int> C(A.size()+B.size()+10, 0); //开一个大小为A.size()+B.size()+10的vector,初始化全为0
for (int i = 0; i < A.size(); ++i) {
for (int j = 0; j < B.size(); ++j)
C[i+j] += A[i] * B[j];
}
int t = 0; //处理进位
for (int i = 0; i < C.size(); ++i) {
t += C[i];
C[i] = t % 10;
t /= 10;
}
while (C.size() > 1 && C.back() == 0) C.pop_back(); //去前导0
return C;
}
int main() {
string a, b;
cin >> a >> b;
vector<int> A, B;
for (int i = a.size()-1; i >= 0; --i)
A.push_back(a[i]-'0');
for (int i = b.size()-1; i >= 0; --i)
B.push_back(b[i]-'0');
vector<int> C = mul(A, B);
for (int i = C.size()-1; i >= 0; --i)
cout << C[i];
return 0;
}
1.3.4 高精度除法
题目:给你两个不含前导 \(0\) 的非负整数 \(A,B\),计算 \(A/B\) 的商和余数。\(1\le \lg A\le 10^5,1\le B\le 10^5\)。
思路:
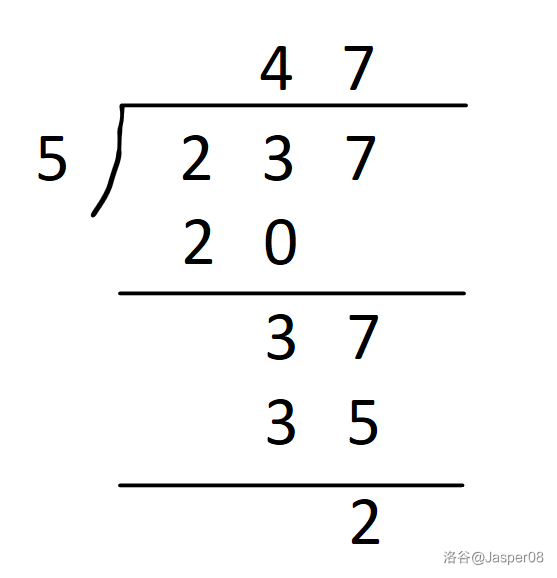
如图 \(\texttt{1-5}\) 展示了通过竖式除法计算 \(237/5\) 的过程:
- \(2\) 除以 \(5\),无法除。余 \(2\)。
- \(23\) 除以 \(5\),商 \(4\) 余 \(3\)。
- \(37\) 除以 \(5\),商 \(7\) 余 \(2\)。
所以 \(237\div 5=45\cdots\cdots2\)。
仿照上述过程,不难写出竖式除法的代码。注意,高精加、减、乘都是从低位到高位计算,而除法是从高位到低位计算。
时间复杂度 \(O(\log A)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
#include <cstring>
using namespace std;
vector<int> div(vector<int> &A, int b, int &r) { //高精除
r = 0; //r为余数
vector<int> C; //C为商
for (int i = A.size()-1; i >= 0; --i) {
r = r*10 + A[i];
C.push_back(r / b);
r %= b;
}
reverse(C.begin(), C.end()); //为了最后倒序输出,C需要额外反转一次
while (C.size() > 1 && C.back() == 0) C.pop_back(); //去前导0
return C;
}
int main() {
string a; int b;
cin >> a >> b;
vector<int> A;
for (int i = a.size()-1; i >= 0; --i) A.push_back(a[i]-'0'); //反向读入
int r = 0;
vector<int> C = div(A, b, r);
for (int i = C.size()-1; i >= 0; --i) printf("%d", C[i]); //倒序输出
puts("");
printf("%d", r);
return 0;
}
1.4 前缀和与差分
1.4.1 前缀和
1.4.1.1 一维前缀和
题目:给你一个包含 \(n\) 个整数的数组 \(a\) 和 \(m\) 次询问,每次询问包含 \(2\) 个正整数 \(l,r\),求出 \(\displaystyle\sum_{l\le i\le r} a_i\)(数组下标从 \(1\) 开始)。\(1\le n,m\le 10^5,-1000\le a_i\le 1000\)。
思路:
暴力计算,时间复杂度 \(O(nm)\),不能接受,我们需要考虑更加快速的做法。
不妨设 \(s_i=\displaystyle\sum_{k=1}^ia_k\),定义 \(s_0=0\),我们有:
接下来思考如何计算 \(s_i\)。 有:
时间复杂度 \(O(n+m)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n, m;
int a[N], s[N]; //s[i]表示前i个数之和
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; ++i) {
scanf("%d", &a[i]);
s[i] = s[i-1] + a[i]; //预处理前缀和,即1.2
}
while (m -- ) {
int l, r;
scanf("%d%d", &l, &r);
printf("%d\n", s[r]-s[l-1]); //式1.1
}
return 0;
}
1.4.1.2 二维前缀和
题目:给你一个 \(n\times m\) 大小的矩阵 \(a\) 和 \(q\) 次询问,每次询问包含 \(4\) 个整数 \(x_1,y_1,x_2,y_2\),求出 \(\displaystyle\sum_{x_1\le i\le x_2}\sum_{y_1\le j\le y_2}a_{i,j}\)。 \(1\le n,m\le 10^3,1\le q\le 2\times 10^5,-1000\le a_{i,j}\le 1000\)。
思路:
仿照一维前缀和,定义 \(s_{i,j}=\displaystyle\sum_{x=1}^i\sum_{y=1}^ja_{i,j}\)。
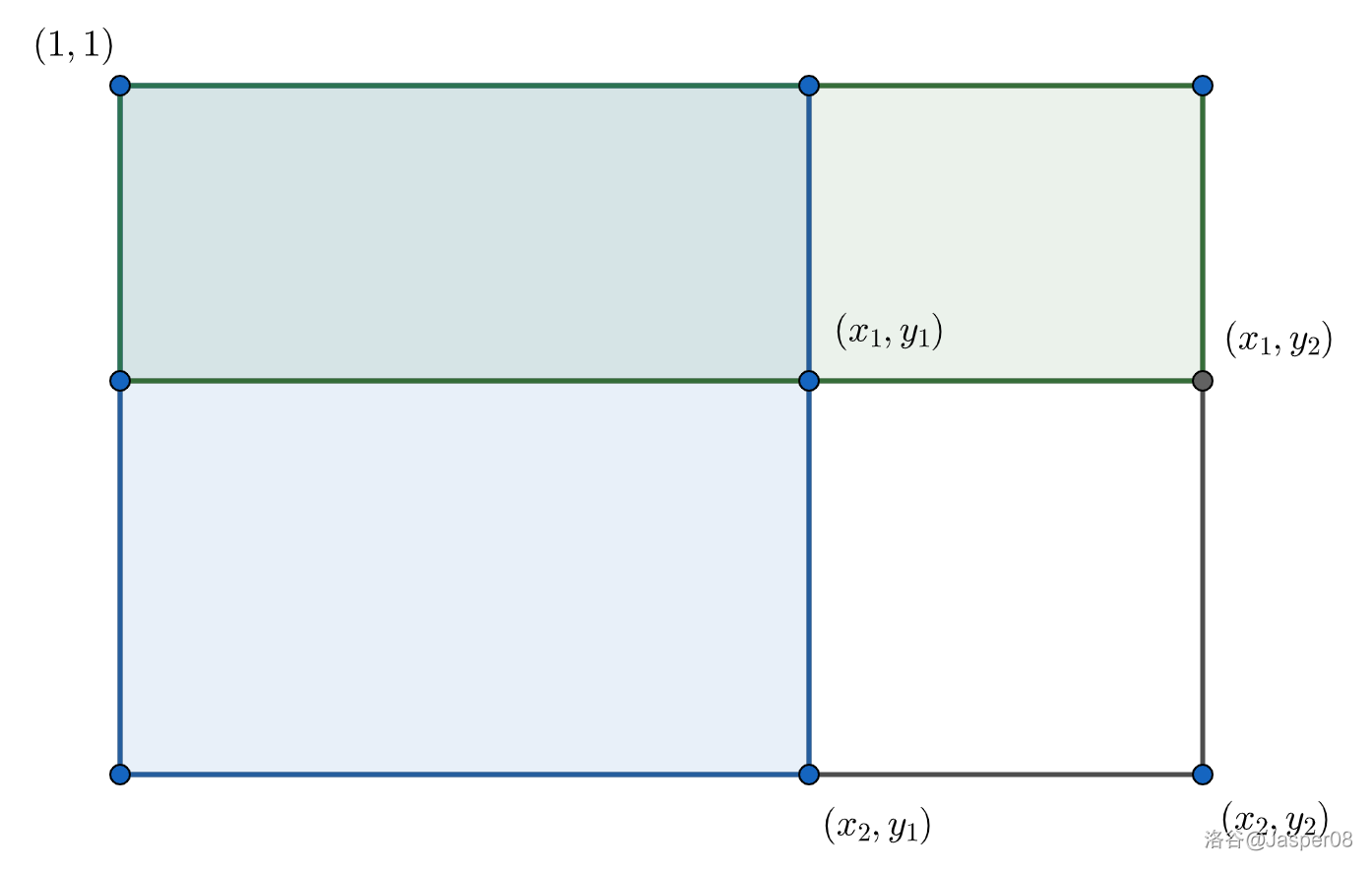
如上图,由容斥原理,可得:
类似地,有:
时间复杂度 \(O(nm+q)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1010;
int n, m, q;
int a[N][N], s[N][N]; //s即为前缀和数组
int main() {
scanf("%d%d%d", &n, &m, &q);
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
scanf("%d", &a[i][j]);
s[i][j] = s[i][j-1]+s[i-1][j]-s[i-1][j-1]+a[i][j]; //式1.4
}
}
while (q -- ) {
int x1, y1, x2, y2;
scanf("%d%d%d%d", &x1, &y1, &x2, &y2);
int ans = s[x2][y2]-s[x1-1][y2]-s[x2][y1-1]+s[x1-1][y1-1]; //式1.3
printf("%d\n", ans);
}
return 0;
}
1.4.2 差分
1.4.2.1 一维差分
题目:给你一个长度为 \(n\) 的整数序列 \(a\) 和 \(m\) 次操作,每次操作包含 \(3\) 个整数 \(l,r,c\),表示将区间 \([l,r]\) 间的数都加上 \(c\)。 求出最后得到的序列。\(1\le n,m\le 10^5,-1000\le a_i\le 1000,-1000\le c\le 1000\)。
思路:
暴力模拟,时间复杂度 \(O(nm)\),无法通过。
定义 \(a\) 的差分数组 \(p\),其中:
- \(p_1=a_1\);
- \(p_i=a_i-a_{i-1}\;(i>1)\)。
对于每次修改操作 l r c,只需将 \(p_l\) 加上 \(c\),\(p_{r+1}\) 减去 \(c\) 即可。最后只需要对 \(p\) 数组求一遍前缀和,即可得到操作后的 \(a\) 数组。
首先我们来证明将 \(p\) 求一遍前缀和就能得到 \(a\)。 根据 \(p\) 的定义,可知:
得证。
然后我们来证明修改操作。同样由 \(p\) 的定义,将 \(p_l\) 加上 \(c\) 后,有
- \(a_l\) 的值变为 \(\displaystyle\sum_{i=1}^lp_i+c=a_l+c\);
- \(a_{l+1}\) 的值变为 \(\displaystyle\sum_{i=1}^{l+1}p_i+c=a_{l+1}+c\);
以此类推,直到 \(a_n\) 的值变为 \(\displaystyle\sum_{i=1}^np_i+c=a_n+c\)。
但我们给 \(a_{r+1}\sim a_n\) 多加了一个 \(c\),所以要再给 \(p_{r+1}\) 减去 \(c\)。
时间复杂度 \(O(n+m)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n, m;
int a[N], p[N]; //p为差分数组
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; ++i) {
scanf("%d", &a[i]);
p[i] = a[i] - a[i-1];
}
while (m -- ) {
int l, r, c;
scanf("%d%d%d", &l, &r, &c);
p[l] += c, p[r+1] -= c; //修改操作
}
for (int i = 1; i <= n; ++i) {
a[i] = a[i-1]+p[i]; //求出修改后的a数组
printf("%d ", a[i]);
}
return 0;
}
1.4.2.2 二维差分
题目:给你一个 \(n\times m\) 大小的矩阵 \(a\) 和 \(q\) 次操作,每次操作包含 \(5\) 个整数 \(x_1,y_1,x_2,y_2,c\),表示将左上角坐标为 \((x_1,y_1)\),右下角坐标为 \((x_2,y_2)\) 的子矩阵中的数全部加上 \(c\)。 输出最终的矩阵。\(1\le n,m\le 1000,1\le q\le 10^5,-1000\le a_{ij}\le 1000,-1000\le c\le 1000\)。
思路:
仿照一维差分,定义 \(a\) 的差分矩阵为 \(p\)。 不同的是,此时我们不需要考虑如何初始化(可以通过插入操作完成)。
对于每次操作,将 \(p_{x_1,y_1}\) 添加 \(c\),\(p_{x_2+1,y_1}\) 减少 \(c\),\(p_{x_1,y_2+1}\) 减少 \(c\),\(p_{x_2+1,y_2+1}\) 增加 \(c\) 即可。
最后再对 \(p\) 求一遍二维前缀和就可以得到更新后的矩阵。
时间复杂度 \(O(nm+q)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1010;
int n, m, q;
int p[N][N]; //p即为差分矩阵
void insert(int x1, int y1, int x2, int y2, int c) { //插入操作
p[x1][y1] += c, p[x1][y2+1] -= c, p[x2+1][y1] -= c, p[x2+1][y2+1] += c;
}
int main() {
scanf("%d%d%d", &n, &m, &q);
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
int x;
scanf("%d", &x);
insert(i, j, i, j, x); //相当于将左上角坐标为(i,j),右下角坐标为(i,j)的矩阵增加x
}
}
while (q -- ) {
int x1, y1, x2, y2, c;
scanf("%d%d%d%d%d", &x1, &y1, &x2, &y2, &c);
insert(x1, y1, x2, y2, c);
}
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
p[i][j] = p[i][j] + p[i-1][j] + p[i][j-1] - p[i-1][j-1]; //通过前缀和求出更新后的矩阵
printf("%d ", p[i][j]);
}
puts("");
}
return 0;
}
1.5 双指针算法
题目:给你一个包含 \(n\) 个元素的数组 \(a\),求出其最长不重复子序列。\(1\le n\le 10^5,1\le a_i\le 10^5\)。
思路:运用双指针算法。
先考虑朴素 \(O(n^2)\) 算法:枚举终点 \(i\),再遍历区间 \([1,i]\) 找到起点 \(j\)。 我们可以用双指针算法将其优化至 \(O(n)\)。
维护两个指针 \(i,j\),分别指向连续不重复子序列的终点和起点。当 \(i\) 每向右移一个数时,我们需要判断此时 \([j,i]\) 是不是连续不重复子序列,如果不是,\(j\) 就向右移动直到 \([j,i]\) 为连续不重复子序列。
通过反证法,不难证明 \(j\) 不可能向左移动:若 \([j,i]\) 是中包含重复元素,则 \([j-1,i]\) 中也必定包含重复元素,矛盾。
然后我们来思考如何判断 \([j,i]\) 合法。不妨设 \([j,i-1]\) 已经为一个合法序列,可以开一个桶 \(s\),动态记录 \([j,i-1]\) 中每个数的出现数量。若 \(s_{i}>1\),说明 \([j,i]\) 不合法,\(j\) 需要向右移动,同时 \(s_j:=s_j-1\)。
每次取 \(i-j+1\) 的最大值即为答案。
时间复杂度 \(O(n)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n;
int a[N], s[N];
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) scanf("%d", &a[i]);
int ans = 0;
for (int i = 1, j = 1; i <= n; ++i) {
s[a[i]] ++; //将ai加入桶中
while (j <= i && s[a[i]] > 1) s[a[j]] --, j ++; //向右寻找j使得[j,i]合法
ans = max(ans, i-j+1);
}
cout << ans << endl;
return 0;
}
题目:给你两个长度分别为 \(n,m\) 的升序数组 \(A,B\),求出一个数对 \((i,j)\) 使得 \(a_i+b_j=x\)(下标从 \(0\) 开始)。\(1\le n,m\le 10^5\),\(1\le a_i,b_j\le 10^9\),保证有唯一解。
思路:
由于 \(A,B\) 均为升序,所以若 \(a_{i}+b_j>x\),那么 \(a_{i+1}+b_j\) 一定也大于 \(x\)。 我们可以维护两个指针 \(i,j\),初始时 \(i\) 指向 \(a_0\),\(j\) 指向 \(b_m\)。 若 \(a_i+b_j>x\) 则 \(j\) 向左移动,若 \(a_i+b_j<x\) 则 \(i\) 向右移动。最后输出 \(i,j\) 即可。
时间复杂度 \(O(n)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n, m, x;
int a[N], b[N];
int main() {
scanf("%d%d%d", &n, &m, &x);
for (int i = 1; i <= n; ++i) scanf("%d", &a[i]);
for (int i = 1; i <= m; ++i) scanf("%d", &b[i]);
int i = 1, j = m;
while (true) {
while (a[i]+b[j] > x) j --;
if (a[i]+b[j] == x) break;
i ++;
}
printf("%d %d\n", i-1, j-1); //由于这里的下标从1开始,所以要额外减去1
return 0;
}
题目:给你两个长度分别为 \(n,m\) 的数组 \(a,b\),判断 \(a\) 是否是 \(b\) 的子序列。\(1\le n,m\le 10^5,-10^9\le a_i,b_j\le 10^9\)。
思路:
若 \(a\) 为 \(b\) 的子序列,则 \(a\) 中的元素一定在 \(b\) 按相同顺序出现。通过双指针维护即可。
初始时,\(i\) 指向 \(a_1\),\(j\) 指向 \(b_1\)。 \(j\) 向右移动直到 \(b_j=a_i\),随后 \(i\) 继续向右移动。最终若 \(i\) 未遍历完 \(a\) 说明 \(a\) 不是 \(b\) 的子序列。
时间复杂度 \(O(n+m)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
const int N = 1e5+10;
int n, m;
int a[N], b[N];
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; ++i) scanf("%d", &a[i]);
for (int i = 1; i <= m; ++i) scanf("%d", &b[i]);
int i = 1, j = 1;
while (i <= n && j <= m) { //双指针遍历
while (b[j] != a[i] && j < m) j ++;
i ++, j ++;
}
i --, j --;
if (i == n && a[i] == b[j]) puts("Yes");
else puts("No");
return 0;
}
1.6 位运算
题目:给你 \(n\) 个数,求出每个数 \(x\) 的二进制表示中 \(1\) 的个数。
思路:我们可以使用 \(\text{lowbit}\) 函数。
首先我们要知道 \(\text{lowbit}\) 函数的定义:\(\text{lowbit}(x)=x\;\&\;-x\)。 其中的 \(\&\) 为按位与,\(x\) 为正整数。
例如,\(\text{lowbit}(10)=(00001010)_{补}\;\&\;(11110110)_{补}=(00000010)_{补}=2\)。 不难发现,若正整数 \(x\) 的补码表示为 \(0\cdots1\underset{n个0}{\underbrace{00\cdots0}}\),那么 \(\text{lowbit}(x)=1\underset{n个0}{\underbrace{00\cdots0}}\)。
我们来证明这个结论。由于 \(-x\) 的补码为 \(\sim x+1\),所以 \(-x\) 的补码即为 \(1\cdots0\underset{n个1}{\underbrace{11\cdots1}}+1=1\cdots1\underset{n个0}{\underbrace{00\cdots0}}\)。 所以 \(\text{lowbit}(x)=x\;\&\;-x\) 即为 \(1\underset{n个0}{\underbrace{00\cdots0}}\)。
回到正题,如何求出 \(x\) 的二进制表示中有多少个 \(1\) 呢?显然,每次 \(x\) 减去 \(\text{lowbit}(x)\) 后,\(x\) 的二进制表示中 \(1\) 的数量就会减少 \(1\)。 循环减去 \(\text{lowbit}(x)\),减的次数即为 \(1\) 的个数。
时间复杂度 \(O(n\log x)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
using namespace std;
int n;
int lowbit(int x) { //lowbit函数
return x & -x;
}
int main() {
scanf("%d", &n);
while (n -- ) {
int x;
scanf("%d", &x);
int cnt = 0;
while (x) {
x -= lowbit(x); //每次减去lowbit(x),1的个数减少1
cnt ++;
}
printf("%d ", cnt);
}
return 0;
}
1.7 离散化
题目:
有一根无限长的数轴,初始时每个点的值都为 \(0\)。 有 \(n\) 次增加操作和 \(m\) 次询问操作:
- 对于每次增加操作,输入两个整数 \(x,c\),表示给数轴上表示点 \(x\) 的点的值增加 \(c\);
- 对于每次询问操作,输入两个整数 \(l,r\),输出区间 \([l,r]\) 内所有点的值之和。
其中,\(-10^9\le x\le 10^9,1\le n,m\le 10^5,-10^9\le l,r\le 10^9,-10^4\le c\le 10^4\)。
思路:观察到值域很大但实际使用的数很少,考虑运用离散化的思想。
先将每次操作的 \(x,l,r\) 存下来,先排序后去重。通过二分查找每个数在去重后的离散化数组内出现的位置,用前缀和优化即可。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> pii;
const int N = 5e5+10;
int n, m;
int a[N], s[N]; //离散化后的前缀和数组
vector<pii> nums, query; //nums存储每次的增加操作,query存储每次询问操作
vector<int> alls; //alls存储所有用到的数
int find(int x) { //在alls中找到等于x的数
int l = 0, r = alls.size()-1;
while (l < r) {
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid+1;
}
return l+1; //由于数组a,s的下标是由1开始的,而alls的下标是从0开始的,所以要额外+1
}
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; ++i) {
int x, c;
scanf("%d%d", &x, &c);
nums.push_back({x, c}); //存储增加操作
alls.push_back(x);
}
for (int i = 1; i <= m; ++i) {
int l, r;
scanf("%d%d", &l, &r);
query.push_back({l, r}); //存储询问操作
alls.push_back(l), alls.push_back(r);
}
sort(alls.begin(), alls.end()); //排序
alls.erase(unique(alls.begin(), alls.end()), alls.end()); //去重
for (auto op : nums) { //处理每次增加操作
int x = op.first, c = op.second;
a[find(x)] += c;
}
for (int i = 1; i <= alls.size(); ++i) s[i] = s[i-1] + a[i]; //预处理前缀和
for (auto op : query) { //处理每次询问操作
int l = op.first, r = op.second;
int ans = s[find(r)] - s[find(l)-1];
printf("%d\n", ans);
}
return 0;
}
1.8 区间合并
题目:给你 \(n\) 个区间 \([l_i,r_i]\),求出合并有交集的区间(在端点处相交也视作交集)后所有区间的数量。\(1\le n\le 10^5,-10^9\le l,r\le 10^9\)。
思路:
先将 \(n\) 个区间根据左端点排序。然后维护两个指针 \(l,r\),分别指向合并后区间的左端点和右端点。那么如何判断区间 \([l_i,r_i]\) 和 \([l,r]\) 是否有交集呢?
- 若 \(l_i>r_i\),则两个区间没有交点,区间数量增加 \(1\);
- 否则,将右端点更新为 \(\max(r_i,r)\)。
代码:
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
typedef pair<int, int> pii;
int n;
vector<pii> segs; //存储每个区间
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; ++i) {
int l, r;
scanf("%d%d", &l, &r);
segs.push_back({l, r});
}
sort(segs.begin(), segs.end()); //排序
int cnt = 0;
int l = segs[0].first, r = segs[0].second;
for (int i = 1; i < segs.size(); ++i) {
if (segs[i].first > r) l = segs[i].first, r = segs[i].second, cnt ++; //无法合并,区间数量+1
else r = max(segs[i].second, r); //可以合并,r更新为max(ri,r)
}
cnt ++; //注意还需要统计最后一个区间
printf("%d\n", cnt);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号