Object wait() 、notify()
一、wait() 、notify() 方法
1. 为什么必须和synchronized一起使用?
因为wait()、notify()是通过对象来进行线程通信的,而依靠对象进行线程通信需要同步保证。
同步的作用:
- 防止notify()有wait()方法的执行的顺序错乱,导致wait线程无法被唤醒;
- 防止内存可见性问题
两个线程之间要通信,对于同一个对象来说,一个线程调用该对象的wait(),另一个线程调用该对象的notify(),该对象本身就需要同步!所以,在调用wait()、notify()之前,要先通过synchronized关键字同步给对象,也就是给该对象加锁。
—— 摘自:Java并发实现原理:JDK源码剖析
2. 为什么是放在Object对象?而不是Thread?
考虑到synchronized是对象锁,可将任何对象当做锁的普遍性;wait()、notify()又需要通过synchronzied保证同步,考虑到普遍性,所以将wait()、notify()一起放在Object。
synchronized关键字可以加在任何对象的成员函数上面,任何对象都可能成为锁。那么,wait()和notify()要同样如此普及,也只能放在Object里面了。
—— 摘自:Java并发实现原理:JDK源码剖析
二、 JMM与happen-before
1. 为什么出现内存可见性?
首先要知道CPU的架构设计,CPU 为了提高计算效率,提供了多级缓存(L1,L2,L3)。因为CPU存在缓存一致性协议,如MESI协议,保证了多个CPU之间的缓存不会出现不同步的问题,不会出现“内存可见性问题”;
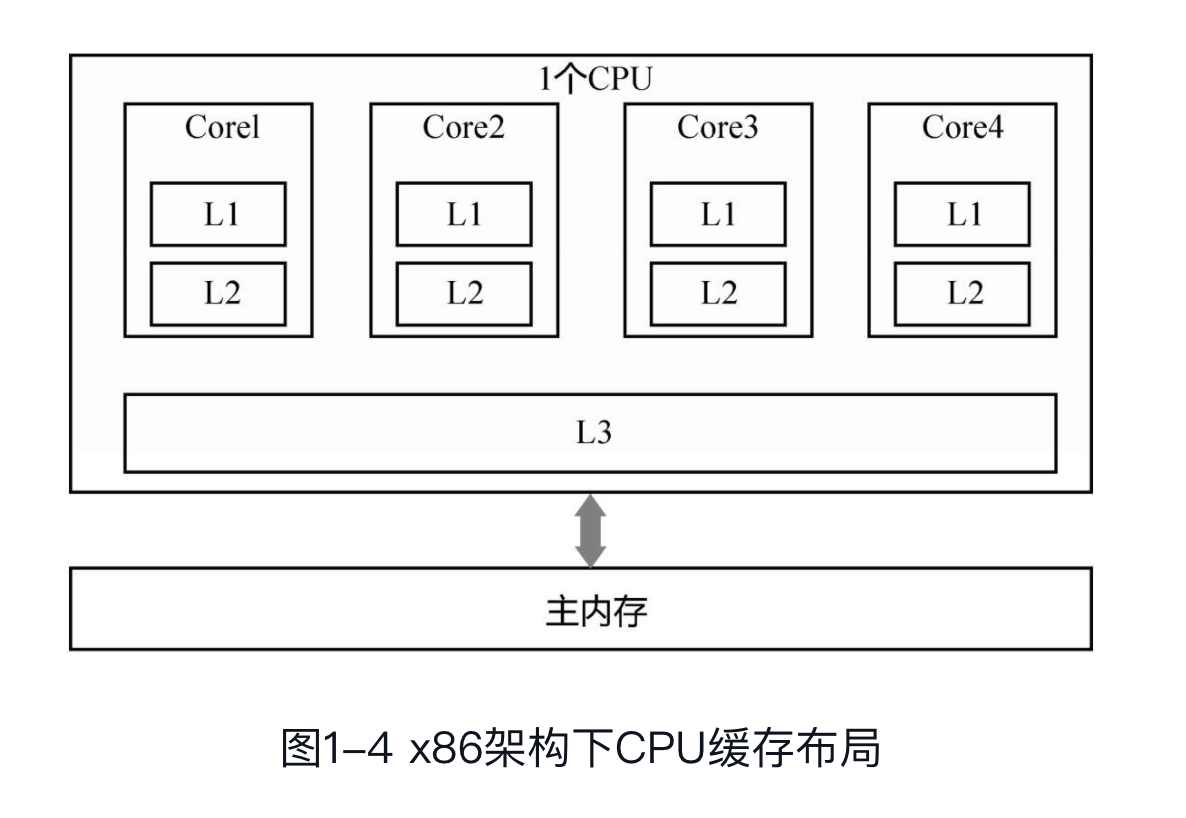
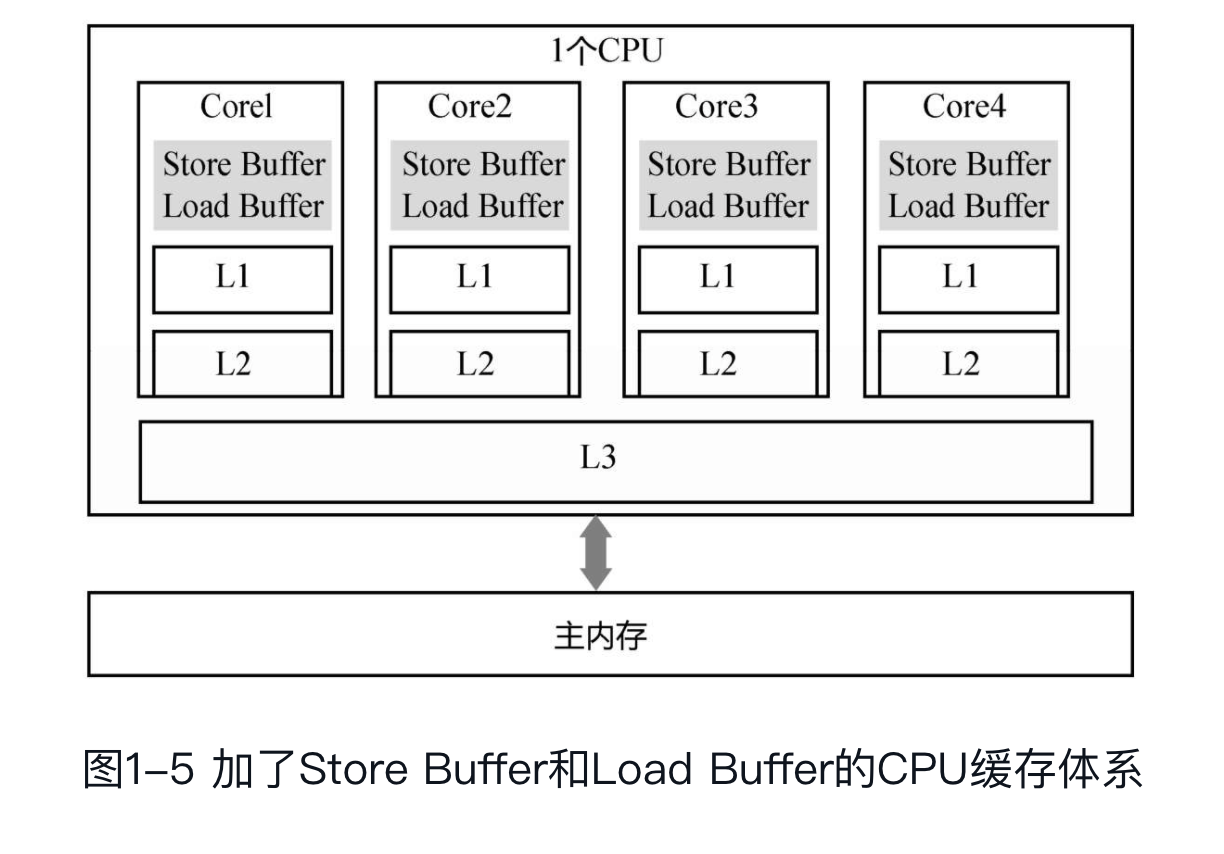
但是,缓存一致性协议对性能有很大损耗。所以,为了解决这个问题,CPU设计者又加了很多优化,比如加入了:Store Buffer 、Load Buffer(还有其他Buffer)。L1,L2,L3和主内存是同步的,但是Store Buffer、Load Buffer跟L1之间是异步的,内存可见性问题主要是在这里出现的。
内存可见性,指的不是内存一直不可见,而是稍后可见。
MESI中每个缓存行都有四个状态,分别是E(exclusive)、M(modified)、S(shared)、I(invalid)。
M:代表该缓存行中的内容被修改了,并且该缓存行只被缓存在该CPU中。这个状态的缓存行中的数据和内存中的不一样,在未来的某个时刻它会被写入到内存中(当其他CPU要读取该缓存行的内容时。或者其他CPU要修改该缓存对应的内存中的内容时(个人理解CPU要修改该内存时先要读取到缓存中再进行修改),这样的话和读取缓存中的内容其实是一个道理)。
E:代表该缓存行对应内存中的内容只被该CPU缓存,其他CPU没有缓存该缓存对应内存行中的内容。这个状态的缓存行中的内容和内存中的内容一致。该缓存可以在任何其他CPU读取该缓存对应内存中的内容时变成S状态。或者本地处理器写该缓存就会变成M状态。
S:该状态意味着数据不止存在本地CPU缓存中,还存在别的CPU的缓存中。这个状态的数据和内存中的数据是一致的。当有一个CPU修改该缓存行对应的内存的内容时会使该缓存行变成 I 状态。
I:代表该缓存行中的内容时无效的。
2. 重排序
Store Buffer的延迟写入是重排序的一种,称为内存重排序(Memory Ordering)。
除此之外,还有编译器和CPU的指令重排序。下面对重排序做一个分类:
- (1)编译器重排序。对于没有先后依赖关系的语句,编译器可以重新调整语句的执行顺序。
- (2)CPU指令重排序。在指令级别,让没有依赖关系的多条指令并行。
- (3)CPU内存重排序。CPU有自己的缓存,指令的执行顺序和写入主内存的顺序不完全一致。
在三种重排序中,第三类就是造成“内存可见性”问题的主因。
构造函数溢出问题:

答案是:a,b未必一定等于1,2。和DCL(double check lock)的例子类似,也就是构造函数溢出问题。
obj=new Example() 这行代码,分解成三个操作:
① 分配一块内存;
② 在内存上初始化 i=1,j=2;
③ 把obj指向这块内存。
操作②和操作③可能重排序,因此线程B可能看到未正确初始化的值。
对于构造函数溢出,通俗来讲,就是一个对象的构造并不是“原子的”,当一个线程正在构造对象时,另外一个线程却可以读到未构造好的“一半对象”。
3. as-if-serial 语义(像串行一样执行)
对开发者而言,当然不希望有任何的重排序,指令执行顺序与代码保持一致,这样更容易理解。
对编译器、CPU的角度来看,希望尽最大可能进行重排序,提升运行效率。
于是,问题就来了,重排序的原则是什么?什么场景下可以重排序,什么场景下不能重排序呢
- a. 单线程重排序规则:不管如何重排序,单线程程序的执行结果不能改变。
- b. 多线程 重排序规则:多线程之间的数据依赖过于复杂,编译器、CPU无法处理,所以,编译器、CPU只保证各个线程的
as-if-serial。
线程之间的数据依赖和相互影响,需要编译器和CPU的上层来确定。上层要告知编译器和CPU在多线程场景下什么时候可以重排序,什么时候不能重排序。
如:volatile
4. happen-before是什么?
1)如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2)两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法(也就是说,JMM允许这种重排序)。
happen-before跟as-if-serial 本质是相同的:
as-if-serial语义保证单线程内程序的执行结果不被改变,happens-before关系保证正确同步的多线程程序的执行结果不被改变。as-if-serial语义给编写单线程程序的程序员创造了一个幻境:单线程程序是按程序的顺序来执行的。
happens-before关系给编写正确同步的多线程程序的程序员创造了一个幻境:正确同步的多线程程序是按happens-before指定的顺序来执行的。
5. JSR-133对volatile语义的增强
Java中的volatile关键字不仅具有内存可见性,还会禁止volatile变量写入和非volatile变量写入的重排序,但C++中的volatile关键字不会禁止这种重排序。
Java的volatile比C++多出的这点特性,正是JSR-133对volatile语义的增强。
下面这段话摘自JSR-133的原文:
What was wrong with the old memory model?The old memory model allowed for volatile writes to be reordered withnonvolatile reads and writes,which was not consistent with most developersintuitions about volatile and therefore caused confusion.
也就是说,在旧的JMM模型中,volatile变量的写入会和非volatile变量的读取或写入重排序,正如C++中所做的。但新的模型不会,这也正体现了Java对happen-before规则的严格遵守。
6. happen-before规则总结
(1)单线程中的每个操作,happen-before于该线程中任意后续操作。
(2)对volatile变量的写,happen-before于后续对这个变量的读。
(3)对synchronized的解锁,happen-before于后续对这个锁的加锁。
(4)对final变量的写,happen-before于final域对象的读,happen-before于后续对final变量的读。
四个基本规则再加上happen-before的传递性,就构成JMM对开发者的整个承诺。
在这个承诺以外的部分,程序都可能被重排序,都需要开发者小心地处理内存可见性问题。
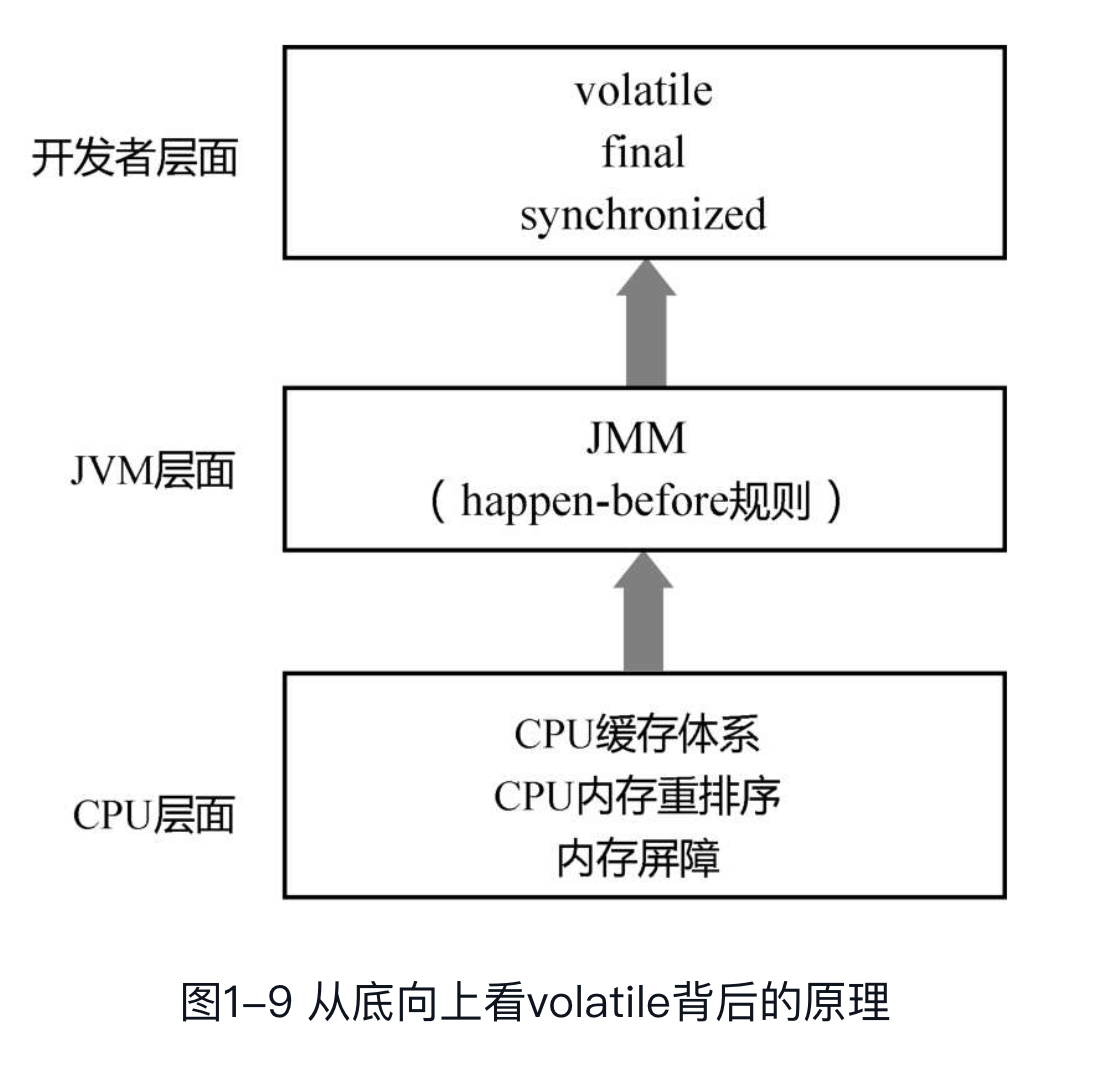
个人理解:
JMM(java内存模型)主要是为了解决线程之间的内存可见性问题,内存可见性问题中主要是由于内存重排序导致的。
为什么需要内存重排序呢?
因为CPU架构的原因(Load Buffer、Store Buffer异步刷新主内存),CPU为了提高性能所做的优化;但是重排序会导致指令执行顺序的改变,最终导致执行结果错误。
为了兼容编译器、CPU重排序提高性能,又为了兼容开发者更好的理解程序的执行过程,写出更简单理解的代码。
JMM制定了一些规则,如:
as-if-serial、happen-before,这些规则规定了编译器、CPU可以对哪些操作进行重排序,而哪些操作禁止重排序。
三、内存屏障
为了禁止编译器重排序和CPU 重排序,在编译器和CPU 层面都有对应的指令,也就是内存屏障(Memory Barrier)。这也正是JMM和happen-before规则的底层实现原理。
编译器的内存屏障,只是为了告诉编译器不要对指令进行重排序。当编译完成之后,这种内存屏障就消失了,CPU并不会感知到编译器中内存屏障的存在。
而CPU的内存屏障是CPU提供的指令,可以由开发者显示调用。下面主要讲CPU的内存屏障。
在理论层面,可以把基本的CPU内存屏障分成四种:
(1)LoadLoad:禁止读和读的重排序。
(2)StoreStore:禁止写和写的重排序。
(3)LoadStore:禁止读和写的重排序。
(4)StoreLoad:禁止写和读的重排序。
参考资料:《Java并发实现原理:JDK源码剖析》、《Java并发编程的艺术》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号