内核链表
内核链表
一、普通链表弊端
普通链表概念简单,操作方便,但存在有致命的缺陷,即:每一条链表都是特殊的,不具有通用性。因为对每一种不同的数据,所构建出来的链表都是跟这些数据相关的,所有的操作函数也都是数据密切相关的,换一种数据节点,则所有的操作函数都需要一一重写编写,这种缺陷对于一个具有成千上万种数据节点的工程来说是灾难性的。
1.问题分析
比如下面的操作函数,函数只能操作指定的参数类型:
// 普通链表的插入函数,与数据节点node密切相关
// 换一种数据节点,该函数就无法使用了
void insert(node *head, node *new)
{
// ... 存粹的指针操作,但是传入的参数 node * 与具体数据相关
}
// 普通链表的删除函数,与数据节点node密切相关
// 换一种数据节点,该函数就无法使用了
node * remove(node *head)
{
// ...
}
形态各异的普通链表
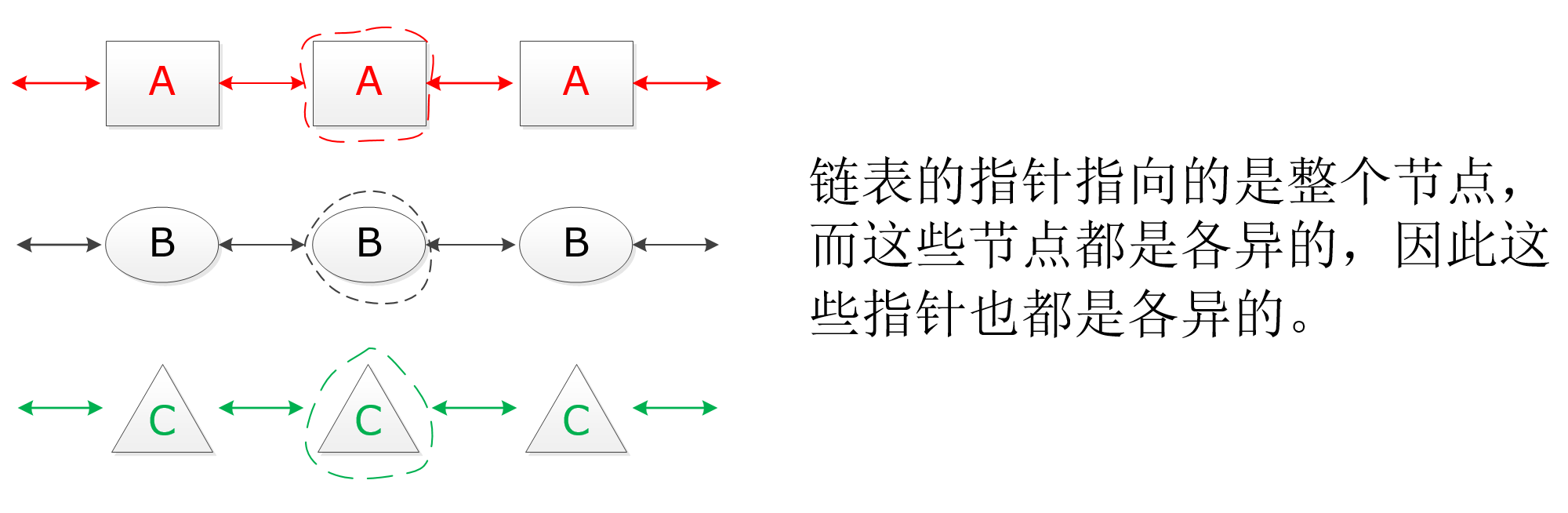
在普通链表的节点设计中,不同的链表所使用的指针不同,就直接导致操作函数的参数不同,在C语言的环境下,无法统一这些所有的操作,这给编程开发带来了很大的麻烦,尤其在节点种类众多的场合。
2. 原因分析
分析上述问题,其产生的根本原因是链表节点的设计,没有把数据和逻辑分开,也就是将具体的数据与组织这些数据的链表揉在一起,导致链表的操作不得已绑定了某个固定类型的数据。
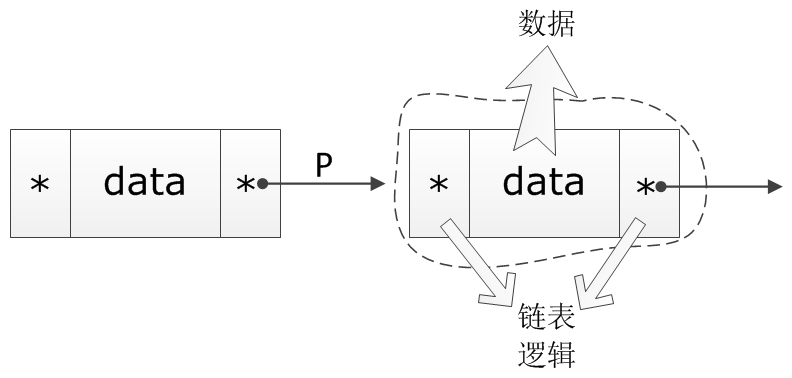
3. 解决思路
既然是因为数据和链表指针混在一起导致了通用性问题,那么解决的思路就是将它们分开。将链表逻辑单独抽出来,去掉节点内的具体数据,让节点只包含双向指针。这样的节点连接起来形成一条单纯的链表如下所示:

接着,将这样的不含任何数据的链表,镶嵌在具体要用串起来的数据节点之中,这样一来,就可以将任何节点的链表操作完全统一了。
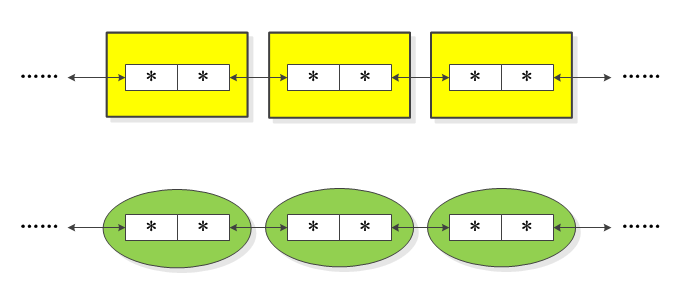
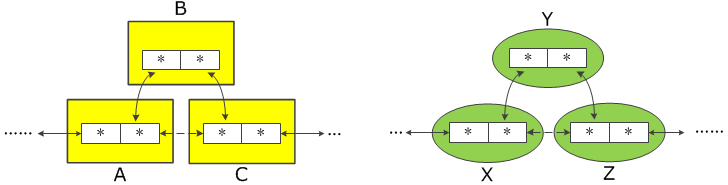
如上图所示,不管用户节点是什么类型的节点,也不管它里面包含什么数据,都跟链表本身没有关系。如下图所示,在 A 和 C 中插入 B 节点,和在 X 与 Z 中插入 Y 节点,完全可以用相同的函数来达到。此时,就已经成功地将数据与组织这些数据的逻辑分开了。这就是内核链表的基本思路。
二、内核链表
如前所述,内核链表解决通用性问题,大概分两步:
1.设计标准节点(设计了一个只有链表指针而不带任何具体数据的节点)
2.针对标准节点,设计由标准节点构成的标准链表的所有操作
内核链表的标准节点及其所有操作,都被封装在内核源码中,具体来讲都被封装在一个名为
list.h的文件中,该文件在内核中的位置是:
kernel/linux/include/list.h
内核中的源码文件 list.h 实际上包含了两部分内容,一是内核链表,二是哈希链表。经过整理的、仅包含内核链表的文件:kernel_list.h
三、基础操作
1.节点设计(数据节点)
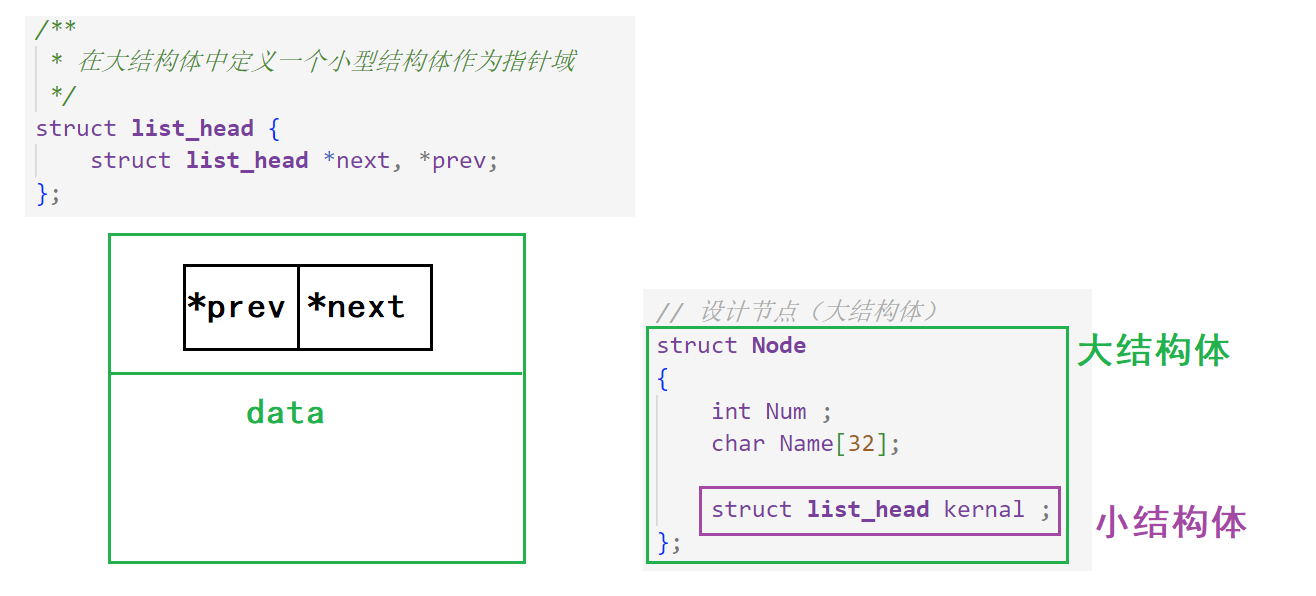
2.初始化
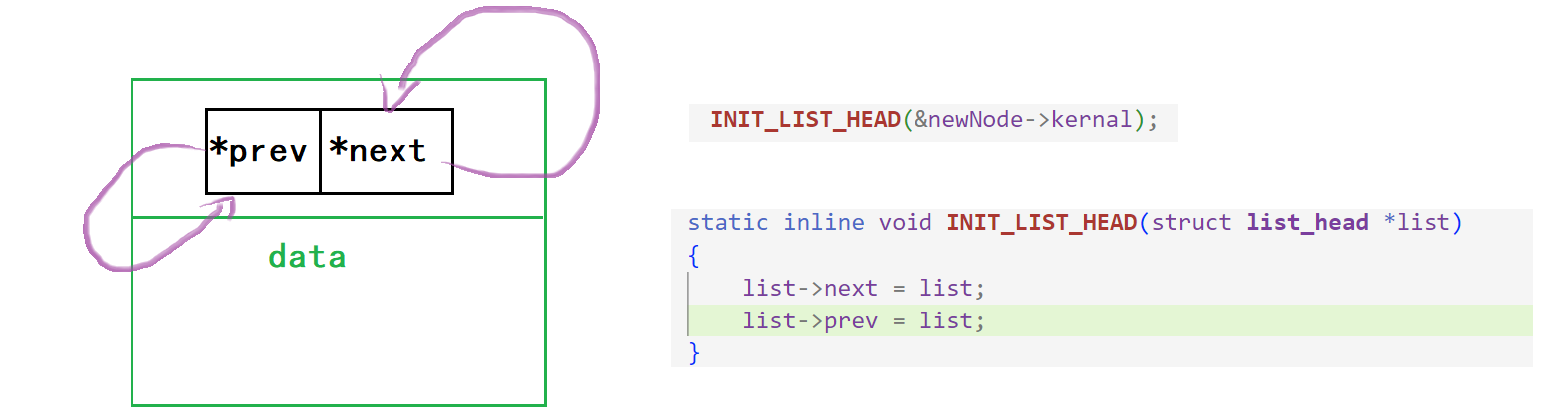
实际上我们只需要处理好数据部分的初始化即可,对于标准的节点初始化内核链表准备了多个方案,以下为其中一个【推荐】:
/**
* 节点初始化
*
* inline用于修饰函数INIT_LIST_HEAD(struct list_head *list)为内联函数,
* 因此必须用static修饰将函数固定在本文件,如此可实现内联函数用空间换取效率的功能
* 函数INIT_LIST_HEAD(struct list_head *list)用于将内核链表节点的指针域中的指针指向自己本身,
* 起到节点初始化的作用
*/
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}
示例代码:
P_Node_t InitNewNode( DataType * NewData )
{
// 申请堆内存
P_Node_t newNode = calloc( 1, sizeof(Node_t) );
// 数据域初始化
if (NewData != NULL)
{
newNode->Data = *NewData ;
}
// 指针域(小结构体、标准结构体)
// newNode->kernal.next = newNode->kernal.prev = &newNode->kernal ;
INIT_LIST_HEAD(&newNode->kernal);
return newNode ;
}
3.插入
插入操作对于一个已经成型的链表节点而言,用户完全可以交给内核链表的函数来实现,不需要我们做任何有关指针的操作,专注于数据即可。
以下内核链表中提供了头插和尾插的方案:

示例代码:
// 获得新数据
DataType NewData = getNewData( );
// 获得新节点
P_Node_t NewNode = InitNewNode( &NewData );
// 把新节点插入
list_add( &NewNode->kernal , &head->kernal );
4. 遍历显示
由于内核链表在遍历时,只对小结构这个标准节点进行遍历,因此需要了解以下他具体是如何通过这个小结构体的地址来计算得到实际大结构的入口地址的:
#define list_entry(ptr, type, member) \
((type*)((char *)(ptr) - (unsigned long)(&((type *)0)->member)))

遍历链表操作内核链表也提供了多个不同版本的方案:
正向遍历链表
/**
* 正向遍历整个链表
*
* list_for_each - iterate over a list
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); \
pos = pos->next)
反向遍历链表
/**
* 反向遍历整个链表
*
* list_for_each_prev - iterate over a list backwards
* @pos: the &struct list_head to use as a loop cursor.
* @head: the head for your list.
*/
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); \
pos = pos->prev)
正向遍历链表的安全版本
/**
* 正向链表遍历且删除小结构体(指针域)
*
* 相较于函数list_for_each,此函数设置了双重保险,用于检测链表遍历是否到头
* 值得关注的是,当链表读到的节点被删除时,pos = pos->next是无法使用的,因此需要用第二重保险 n 来解决问题,故删除节点遍历是需要此函数
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
正向遍历链表并计算大结构地址
/**
* 正向遍历给定类型链表的同时寻找各链表入口地址
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))// 效果相当于在函数list_for_each基础上,加上函数
反向遍历链表并计算大结构入口
/**
* 反向遍历链表的同时寻找各链表入口地址
* list_for_each_entry_reverse - iterate backwards over list of given type.
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_reverse(pos, head, member) \
for (pos = list_entry((head)->prev, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.prev, typeof(*pos), member))
5. 查找
查找操作与前面的普通链表一样,无非就是在遍历的过程中增加判断数据而已:
P_Node_t find4List( P_Node_t head , int Num )
{
P_Node_t pos = NULL ;
list_for_each_entry(pos , &head->kernal , kernal)
{
if (pos->Data.Num == Num)
{
printf("%d -%s\n" , pos->Data.Num , pos->Data.Name );
return pos ;
}
}
printf("没有找到目标..\n");
return NULL ;
}
6. 删除
删除操作内核链表已经有现成的剔除节点的操作,因此只需要配合查找函数即可。

P_Node_t find = find4List( head , Num );
if (find != NULL)
{
// 把find 从链表中剔除
list_del( &find->kernal );
}
当我们需要删除链表中所有符合某个条件的操作时,就需要一边遍历一遍删除,因此普通的list_for_each_entry( ) 是无法支撑的,因为在删除掉pos后,无法再通过pos继续遍历链表了,因此我们需要另外一个版本的遍历操作 list_for_each_entry_safe(pos , n , &head->kernal , kernal ) :
/**
* 正向链表遍历且删除大结构体
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))// 具体可参考list_for_each_safe函数
示例代码:
int DelAll4List( P_Node_t head , int Num )
{
P_Node_t pos = NULL ; // 用于记录当前节点
P_Node_t n = NULL ; // 用于记录当前节点的下一个节点位置
// _safe 版本多了n 因此在遍历的过程中可以对Pos进行删除操作
list_for_each_entry_safe(pos , n , &head->kernal , kernal )
{
if (pos->Data.Num == Num)
{
printf("%d -%s\n" , pos->Data.Num , pos->Data.Name );
list_del(&pos->kernal) ;
free(pos);
}
}
}
7. 修改
修改操作通常涉及查找和更新两个步骤。在内核链表中,修改操作主要关注数据域的更新,链表结构本身保持不变。
修改单个节点
/**
* 修改指定节点的数据
* @param head: 链表头节点
* @param targetNum: 要修改的目标节点编号
* @param newData: 新的数据
* @return: 成功返回0,失败返回-1
*/
int ModifyNode(P_Node_t head, int targetNum, DataType *newData)
{
if (head == NULL || newData == NULL) {
printf("参数错误..\n");
return -1;
}
// 查找目标节点
P_Node_t targetNode = find4List(head, targetNum);
if (targetNode == NULL) {
printf("找不到目标节点 %d..\n", targetNum);
return -1;
}
// 更新数据
targetNode->Data = *newData;
printf("节点 %d 修改成功\n", targetNum);
return 0;
}
批量修改符合条件的节点
/**
* 批量修改符合条件的节点
* @param head: 链表头节点
* @param conditionNum: 条件编号
* @param newData: 新的数据
* @return: 修改的节点数量
*/
int ModifyAllNodes(P_Node_t head, int conditionNum, DataType *newData)
{
if (head == NULL || newData == NULL) {
printf("参数错误..\n");
return 0;
}
P_Node_t pos = NULL;
P_Node_t n = NULL;
int modifiedCount = 0;
// 使用安全版本遍历,支持在遍历过程中修改
list_for_each_entry_safe(pos, n, &head->kernal, kernal)
{
if (pos->Data.Num == conditionNum) {
// 保存旧数据(可选)
DataType oldData = pos->Data;
// 更新数据
pos->Data = *newData;
modifiedCount++;
printf("修改节点: %d-%s -> %d-%s\n",
oldData.Num, oldData.Name,
pos->Data.Num, pos->Data.Name);
}
}
printf("共修改了 %d 个节点\n", modifiedCount);
return modifiedCount;
}
条件修改回调函数版本
/**
* 修改条件回调函数类型
* @param data: 节点数据
* @param userData: 用户自定义数据
* @return: 符合条件返回1,否则返回0
*/
typedef int (*ModifyConditionCallback)(DataType *data, void *userData);
/**
* 使用回调函数进行条件修改
* @param head: 链表头节点
* @param conditionCallback: 条件判断回调函数
* @param newData: 新的数据
* @param userData: 传递给回调函数的用户数据
* @return: 修改的节点数量
*/
int ModifyWithCallback(P_Node_t head,
ModifyConditionCallback conditionCallback,
DataType *newData,
void *userData)
{
if (head == NULL || conditionCallback == NULL || newData == NULL) {
printf("参数错误..\n");
return 0;
}
P_Node_t pos = NULL;
P_Node_t n = NULL;
int modifiedCount = 0;
list_for_each_entry_safe(pos, n, &head->kernal, kernal)
{
if (conditionCallback(&pos->Data, userData)) {
// 保存旧数据用于日志(可选)
DataType oldData = pos->Data;
// 更新数据
pos->Data = *newData;
modifiedCount++;
printf("修改节点: %d-%s -> %d-%s\n",
oldData.Num, oldData.Name,
pos->Data.Num, pos->Data.Name);
}
}
printf("共修改了 %d 个节点\n", modifiedCount);
return modifiedCount;
}
8.销毁
销毁操作需要安全地遍历整个链表并释放所有节点的内存。
销毁整个链表
/**
* 销毁整个链表
* @param head: 链表头节点指针的地址
* @return: 无
*/
void DestroyList(P_Node_t *head)
{
if (head == NULL || *head == NULL) {
printf("链表已为空或参数错误..\n");
return;
}
P_Node_t pos = NULL;
P_Node_t n = NULL;
int destroyedCount = 0;
printf("开始销毁链表...\n");
// 使用安全版本遍历所有节点并释放内存
list_for_each_entry_safe(pos, n, &(*head)->kernal, kernal)
{
// 从链表中删除节点
list_del(&pos->kernal);
printf("销毁节点: %d-%s\n", pos->Data.Num, pos->Data.Name);
// 释放节点内存
free(pos);
destroyedCount++;
}
// 释放头节点
printf("销毁头节点\n");
free(*head);
*head = NULL;
printf("链表销毁完成,共销毁 %d 个节点\n", destroyedCount + 1);
}
条件销毁
/**
* 条件销毁回调函数类型
* @param data: 节点数据
* @param userData: 用户自定义数据
* @return: 符合销毁条件返回1,否则返回0
*/
typedef int (*DestroyConditionCallback)(DataType *data, void *userData);
/**
* 条件销毁链表节点
* @param head: 链表头节点
* @param conditionCallback: 条件判断回调函数
* @param userData: 传递给回调函数的用户数据
* @return: 销毁的节点数量
*/
int ConditionalDestroy(P_Node_t head,
DestroyConditionCallback conditionCallback,
void *userData)
{
if (head == NULL || conditionCallback == NULL) {
printf("参数错误..\n");
return 0;
}
P_Node_t pos = NULL;
P_Node_t n = NULL;
int destroyedCount = 0;
printf("开始条件销毁...\n");
list_for_each_entry_safe(pos, n, &head->kernal, kernal)
{
if (conditionCallback(&pos->Data, userData)) {
// 从链表中删除节点
list_del(&pos->kernal);
printf("销毁节点: %d-%s\n", pos->Data.Num, pos->Data.Name);
// 释放节点内存
free(pos);
destroyedCount++;
}
}
printf("条件销毁完成,共销毁 %d 个节点\n", destroyedCount);
return destroyedCount;
}
销毁回调函数示例
/**
* 示例:销毁所有编号大于指定值的节点
*/
int DestroyGreaterThanCallback(DataType *data, void *userData)
{
int *threshold = (int *)userData;
return (data->Num > *threshold) ? 1 : 0;
}
/**
* 示例:销毁所有名称包含指定字符串的节点
*/
int DestroyNameContainsCallback(DataType *data, void *userData)
{
char *keyword = (char *)userData;
return (strstr(data->Name, keyword) != NULL) ? 1 : 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号