
作业三 MNIST,CIFAR10,VGG16
视频学习心得及问题总结
学习心得
数学基础
依然是数学废走马观花的环节,仅仅做了一些笔记。
数据降维:
较大奇异值包含了矩阵的主要信息
只保留前r个较大其奇异值及其对应的特征向量(一般r=d/10)可实现数据从nd降维到(nr+ rr + rd)。
矩阵线性变换:
矩阵相乘对原始变量同时施加方向变化和尺度变化;
对于特殊向量(特征向量),矩阵只作用尺度变化(特征值)没有方向变化。
矩阵秩:度量矩阵行列之间的相关性。
矩阵的各行或列之间是线性无关的---矩阵满秩(秩等于行数)。
数据点分布:表示数据需要的最小的基的数量:
数据分布模式容易捕捉;
数据冗余度;
结构化信息(各行之间相关性,一般是低秩的)。
卷积神经网络
卷积和池化是卷积神经网络的两大特质。
然后记录了一些速查短语:
input:输入
kernel/filter:卷积核/滤波器
weights:权重
receptive field:感受野
activation map 或者=feature map:特征图
padding
depth/channel:深度
output::输出
stride:步长
问题总结
光看视频课程对于滤波器实在是云里雾里,在代码实践里面逐渐明朗。许多概念还是要在经典代码里面学习更有效果。
代码练习
1.MNIST
结果展示
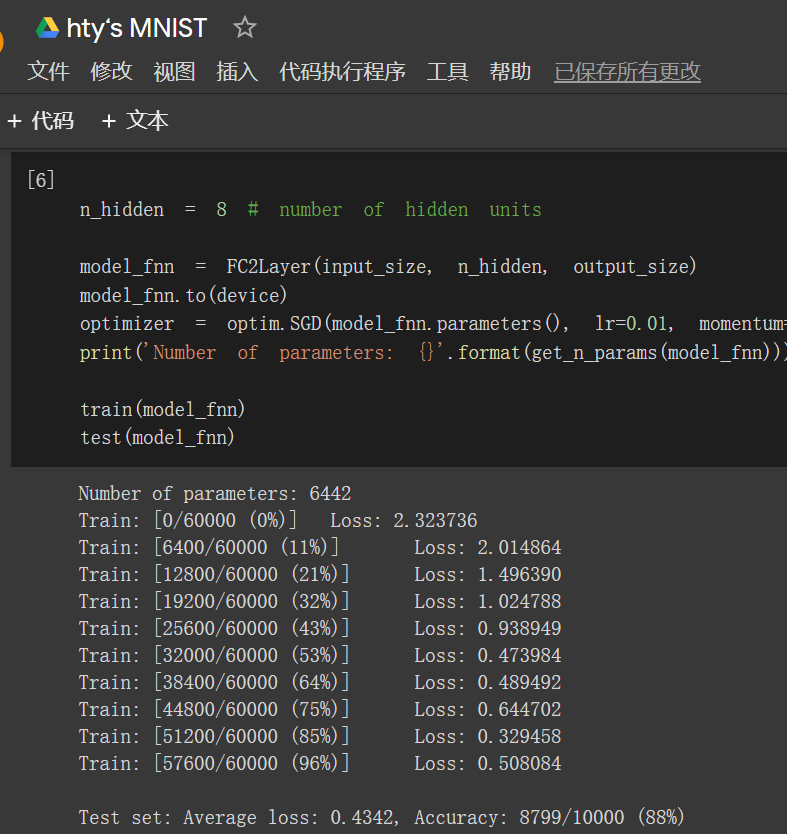
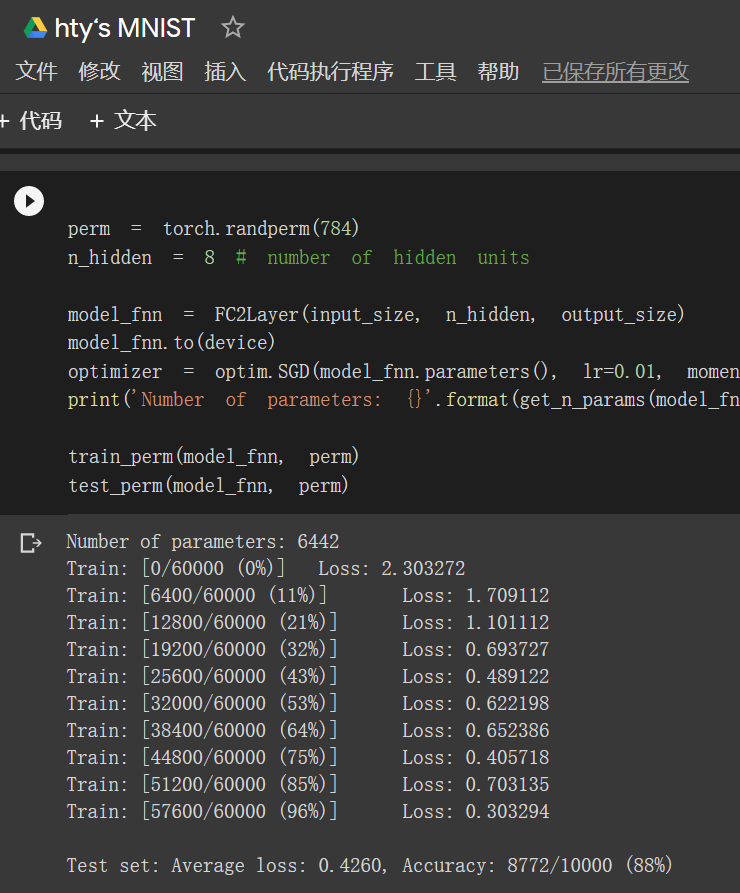
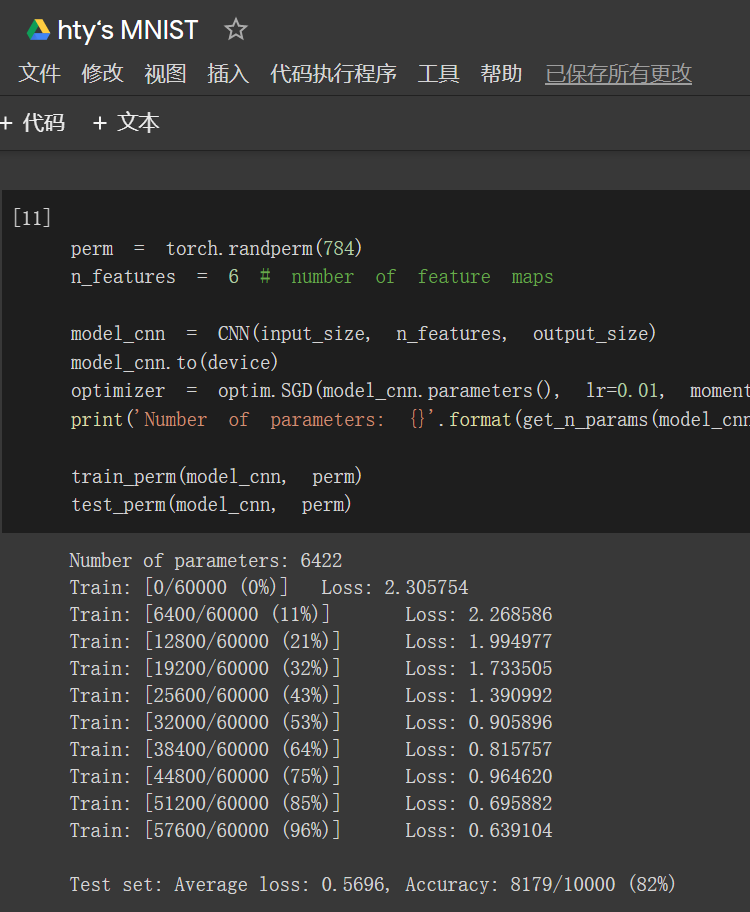
未打乱像素顺序:在小型全连接网络上训练:88%
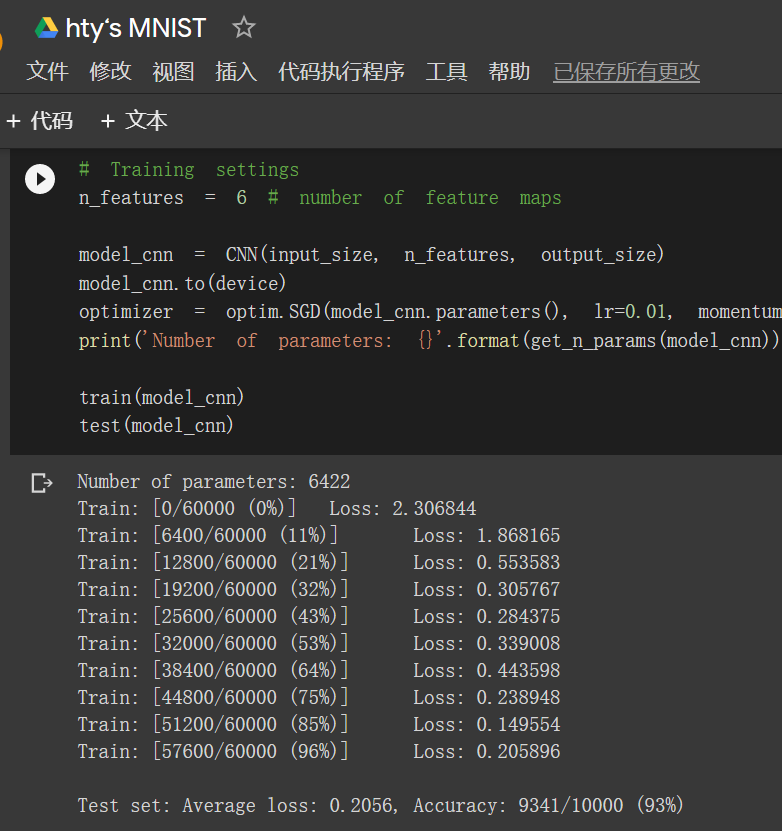
在卷积神经网络上训练:93%
打乱像素顺序再次在两个网络上训练与测试:在小型全连接网络上训练:88%
在卷积神经网络上训练:82%
结果总结:
(以下仅代表个人分析)
MNIST识别手写数字是老朋友了,新手的经典第一步。含有相同参数的卷积神经网络效果要明显优于小型全连接网络,是因为“卷积”和“池化”两个手段。
卷积:一般是用滤波器去乘灰度值然后得到一个新的矩阵,这样从0到255之间的不同数值体现了黑白反差,能快速找到边缘在哪里。这也是为什么在打乱像素顺序之后,卷积的优势无法体现出来。
池化:本质是采样,最常用的也是本代码中用的是最大池化(Max Pooling)。在每一个小区域选择最大的取值作为这个区域的取值,然后损失一部分信息对计算性能进行了妥协。
关键代码截图:
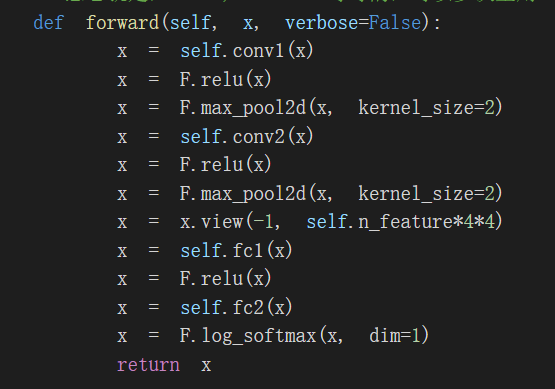
2.CIFAR10
结果展示
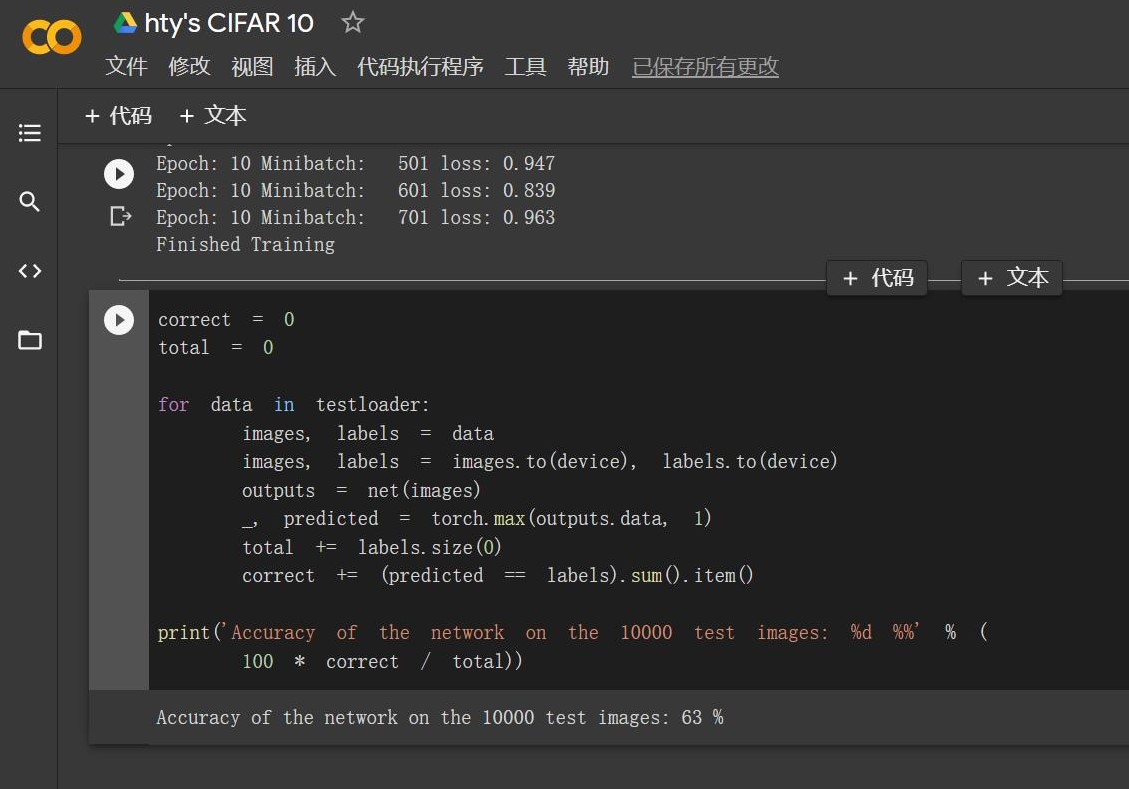
直接采用老师的代码:Accuracy of the network on the 10000 test images: 63 %
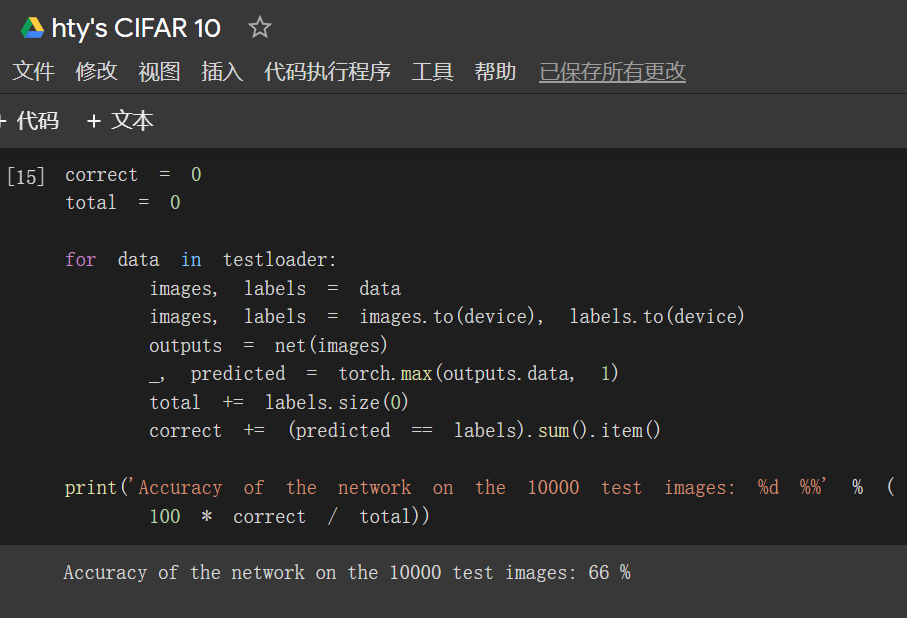
自己进行了小小的优化:Accuracy of the network on the 10000 test images: 66 %
结果总结:
(以下仅代表个人分析)
该实验最大的好处是能实践学习torchvision包。其中CIFAR包含十大类的图片,训练测试还可以分别import。
CIFAR的优化:
a.将激活函数从ReLU换成CELU,亲测有效。
(参考自myrtle.ai 研究科学家 David Page 的推特,获得了 Jeff Dean 的点赞。悲哀的是我只能暂时看懂其中的零星方法,而且碍于篇幅就不写预处理、批归一化和patch白化的内容了,还有的正在长期学习中,如果研究有结果会写博客的。)
(colab地址:https://colab.research.google.com/github/davidcpage/cifar10-fast/blob/master/bag_of_tricks.ipynb )
b.另外我发现,老师提供的代码已经使用了AdamOptimizer,而官网pytorch的官方tutorial使用的是SGDOptimizer
比较一下代码:
老师提供:optimizer = optim.Adam(net.parameters(), lr=0.001)
官网:optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
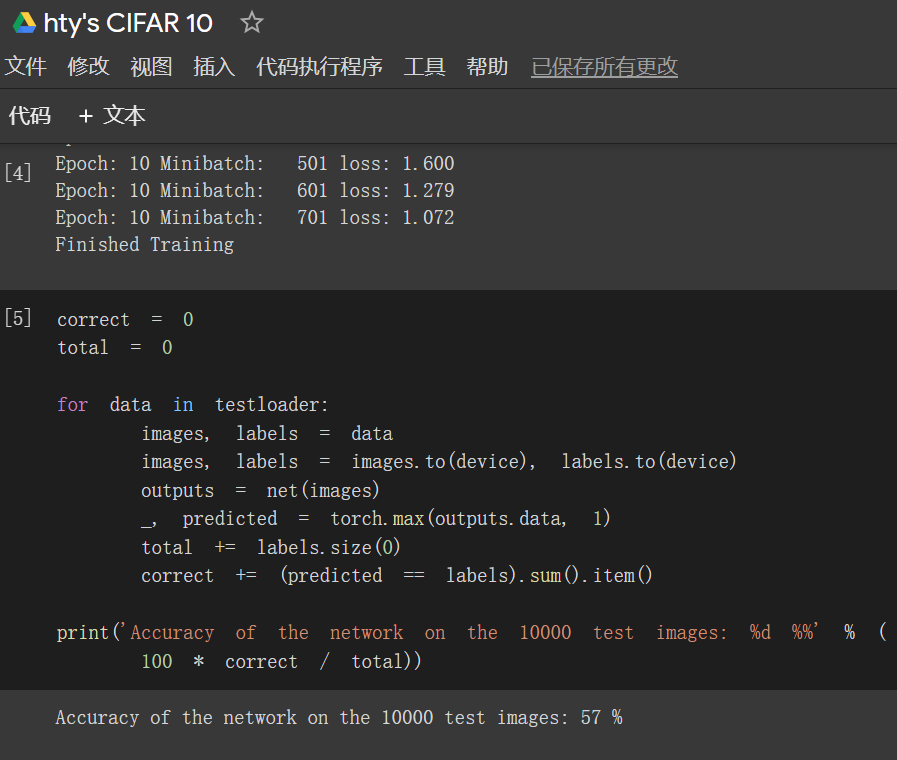
于是我开始替换实践,结局是虽然感觉速度有所提升,但是Accuracy of the network on the 10000 test images: 57 %.
我泪洒六区,并且称赞老师已然选择较好的优化器了!
3.VGG16
结果展示
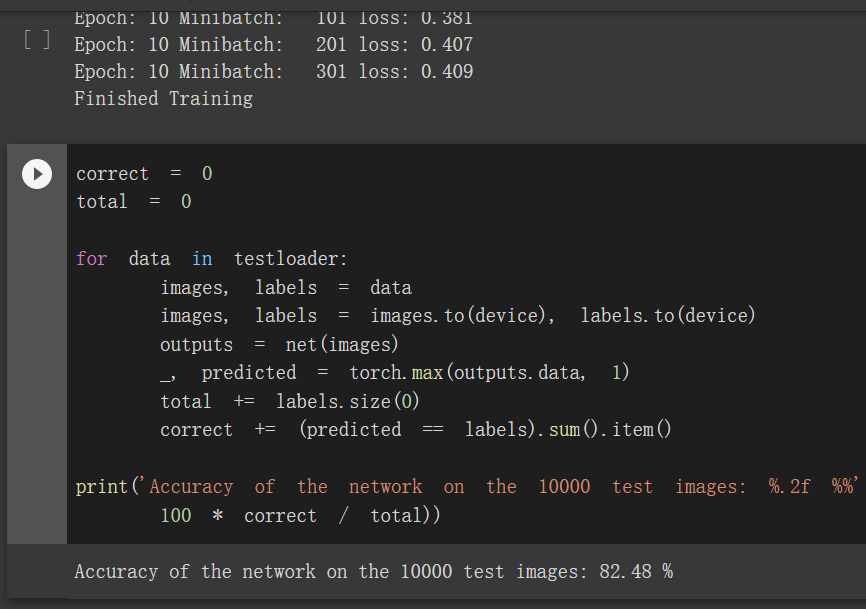
Accuracy of the network on the 10000 test images: 82.48 %
结果总结:
(以下仅代表个人分析)
定义transform,dataloader 的改进:
关键代码截图:

a.transform变换里面更加丰富,在原有的两步骤:将PIL[0,1]转换为Tensor[-1,1],对RGB 图像做归一化的基础上,还增加了随机裁剪(设置4个多少个pixel)和依概率p水平翻转(这里默认值0.5)。我曾经看到过一种观点:在预处理时间浪费的小小几秒,会在后续的速度上面补上。虽然该例子没有很明显的特别联系,但是我莫名对这句话有了更深的感觉。
b.dataloader里面扩容了batch_size,下载的时候从64、8均变为128,单次迭代占用内存增大,建议使用colab的时候终止其他的笔记本。
c.看到有同学提问batch_size具体的选取方法和相关概念,结合我自己的理解和兴趣,我也简单写好了一篇博客《用愚公移山的原理解释概念--深度学习pytorch常见的参数batch_size,batch_idx,epoch》,后续会发出来。(仅仅是概念!)
至于VGG神经网络的结构相比于之前完全升级了,就不赘述了。
4.结果截图汇总
a.MNIST
b.CIFAR10
小优化前:
小优化后:
SGD优化器:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号