redis - 9 主从复制
1. 主从复制的理解
1. 一个主库用来写,多个从库用来读,实现读写分离,数据冗余 2. 两者之间是一对多的关系,从库也可以有自己的从库 3. 当主库死了,临时推出一个从库作为新的主库
2. 主从复制的过程
大致可分为三个阶段 1. 建立连接,从库向主库建立连接
使用命令或者配置项去连接主库 2. 数据同步阶段
a. master的数据量巨大时,应该避开业务繁忙时间,否则会容易在执行的过程中造成阻塞,影响正常业务
b. 缓冲区应该设置一定的大小,防止从库全量复制的时候,缓冲区溢出,导致从库无法全量同步,从而从库重新全量同步
c. 从库复制数据期间应该停止从库的对外服务
d. 尽量不要多个从库同时同步master数据
e. 当从库较多的情况下,建议开启多层次的结构,但是数据一致性会变差,需要自行斟酌去,取舍 3. 命令传播阶段
三个核心要素
a. 服务器运行id,40位,用于主从之间的身份识别
b. 复制缓冲区
是一个先进先出的队列,所有的命令被拆成偏移量加字节的形式,
master记录每个slave的偏移量(即每个slave同步到哪个字节值了)
slave也会记录自己的偏移量,当与master不同时,就会开始复制
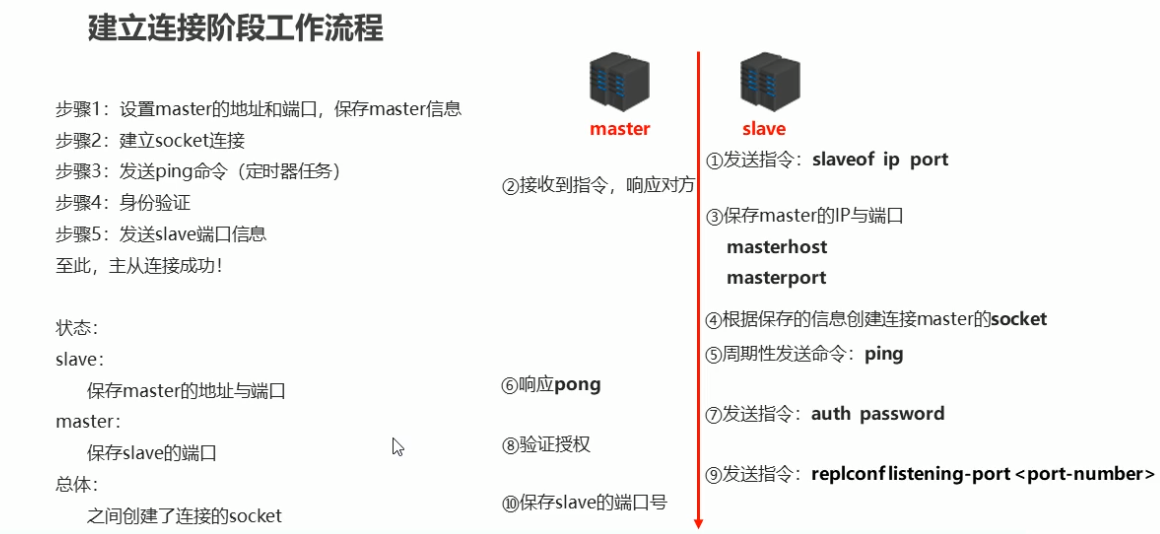
1.1 建立连接流程
2.1 数据同步流程

3.1 主从复制详细版

3. 心跳机制
1. master每10秒ping一次slave,判断slave是否在线 2. master可以设置,如果slave连接数量小于一定时间,就停止写的功能,直到slave数量恢复 3. master也可以设置,如果slave在被ping的时候响应时间过长,停止写的功能 4. slave每1秒ping一次master,判断主机是否在线,并获取最新数据
4. 数据不一致问题
1. 主从复制一定会存在数据不一致的问题 2. 从硬件着手,减少主从复制之间的时间间隔 3. 当一个slave与master之间的连接不是特别稳定通畅时,master暂时屏蔽该slave

 浙公网安备 33010602011771号
浙公网安备 33010602011771号