redis入门(二)
[TOC]
redis入门(二)
目录
redis入门(一)
redis入门(二)
redis入门(三)
前言
在redis入门(一)简单介绍了redis的历史和安装部署,以及基本的数据结构和api,本节讲解redis持久化、高可用、redis集群和分布式相关的知识。
持久化
redis作为内存数据库,数据全部存储到内存中。但是若出现断电等原因会造成数据丢失。redis内置了2种持久化的方式,分别为RDB持久化和AOF持久化。
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程,换句话来说是将当前redis内存中的数据全部保存到硬盘。触发RDB持久化过程分为手动触发和自动触发。
手动触发
可以通过
save和bgsave两个命令手动执行保存RDB快照。
save命令:会阻塞当前redis主进程,直到RDB保存完成,save命令已经弃用,不建议生产环境使用。
bgsave命令:redis进程会执行fork操作创建进程执行保存RDB快照。只有在fork子进程才会短时间阻塞。建议大家都是用bgsave命令保存RDB快照。目前redis内部所有RDB操作都使用bgsave命令127.0.0.1:26379> save OK 127.0.0.1:26379> bgsave Background saving started自动触发
- 使用save相关配置,如
save m n。表示m秒内数据集存在n次修改时,自动触发bgsave。 - 若节点执行全量复制操作时,主节点自动执行
bgsave生成RDB文件并发给从节点。 - 执行
debug reload命令重新加载redis时,也会触发save操作。redis debug命令提供了几个非常实用的debug功能
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化功能且设置过rdb自动保存策略则会自动执行bgsave。
- 使用save相关配置,如
原理
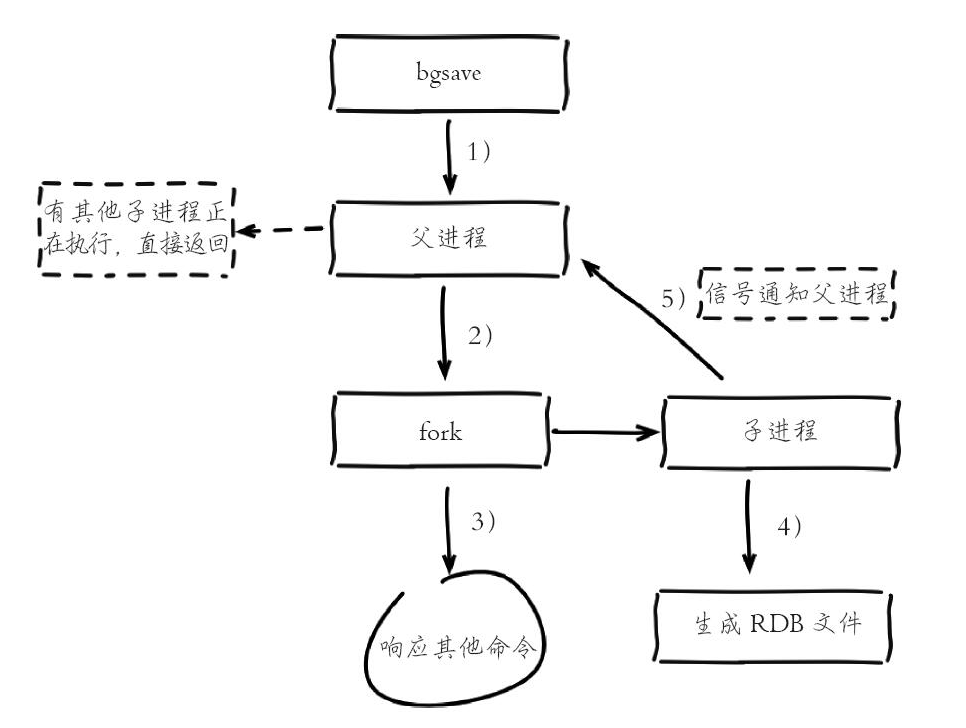
执行bgsave命令,Redis父进程判断当前是否存在正在执行的子进程,如RDB/AOF子进程,如果存在bgsave命令直接返回。
父进程执行fork操作创建子进程,fork操作过程中父进程会阻塞,通过
info stats命令查看latest_fork_usec选项,可以获取最近一个fork操作的耗时,单位为微秒。127.0.0.1:26379> info stats # Stats total_connections_received:1 ... latest_fork_usec:5391父进程fork完成后,
bgsave命令返回Background saving started信息并不再阻塞父进程,可以继续响应其他命令。子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行
lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。进程发送信号给父进程表示完成,父进程更新统计信息,具体见info Persistence下的rdb_*相关选项。O127.0.0.1:26379> lastsave (integer) 1572423635
常用配置
| 节点名 | 说明 |
|---|---|
| save | m秒有n次修改自动保存 |
| dbfilename | RDB保存文件名,会保存到dir配置的路径中 |
通过
config set dbfilename可以动态修改RDB保存文件名,下次运行RDB保存时会保存到新的文件名中。
经验
- RDB文件压缩保存可以大幅度降低文件大小
- 若磁盘损坏可以通过
config set命令动态修改redis根路径和RDB文件路径。 - RDB文件加载速度远快于AOF文件加载速度
- RDB方式保存没办法做到实时保存,因此不能用于存储不能丢失的数据。
- RDB方式保存每次都会将内存中的数据全量进行保存,因此不适用于内存数据较大且需要频繁保存的场景。
AOF
AOF(appendonlyfile)持久化:以独立日志的方式记录每次写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。AOF保存的不是数据,而是每次执行的命令,因此AOF文件会比RDB文件大的多。
原理
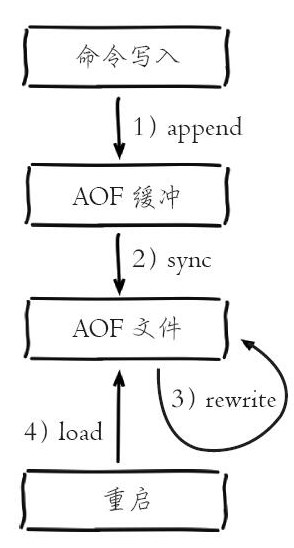
- 所有的写入命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做缓冲区文件操作。
AOF有三种缓冲区文件同步策略
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务器重启时,可以加载AOF文件进行数据恢复。
缓冲区同步策略
- 实时同步
通过配置appendfsync always,命令写入缓存后,调用系统fsync同步文件操作。 - 每秒同步
通过配置appendfsync ecerysec,命令写入缓存后,调用系统write操作。一个专门的线程每秒调用一次fsync同步文件操作。 - 操作系统决定何时同步
通过配置appendfsync no,命令写入缓存后,不做fsync同步文件操作,同步操作由操作系统负责,通常同步周期最长30秒
- write操作会触发延迟写(delayedwrite)机制。Linux在内核提供页缓冲区用来提高硬盘IO性能。write操作在写入系统缓冲区后直接返回。同步硬盘操作依赖于系统调度机制,例如:缓冲区页空间写满或达到特定时间周期。同步文件之前,如果此时系统故障宕机,缓冲区内数据将丢失。
- fsync针对单个文件操作(比如AOF文件),做强制硬盘同步,fsync将阻塞直到写入硬盘完成后返回,保证了数据持久化。
重写机制
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制优化命令。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。定时AOF重写不但可以减小硬盘文件占用,同时可以在redis重启时更快的加载AOF文件。
AOF重写会重写以下内容,AOF重写可以删除已经超时的数据,旧的AOF无效命令(先新增后删除),多条写命令合并为一个(多条插入集合可以合并为一条插入命令)
- 手动触发:直接调用
bgrewriteaof命令。127.0.0.1:26379> bgrewriteaof Background append only file rewriting started - 自动触发:根据
auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。

- 执行AOF重写请求。当需要执行AOF重写时,当前进程正在执行bgsave操作,重写命令延迟到bgsave完成之后再执行。
- 父进程执行fork创建子进程,开销等同于bgsave过程。
- 主进程fork操作完成后,继续响应其他命令。所有修改命令依然写入AOF缓冲区并根据appendfsync策略同步到硬盘,保证原有AOF机制正确性。
由于fork操作运用写时复制技术,子进程只能共享fork操作时的内存数据。 - 子进程根据内存快照,按照命令合并规则写入到新的AOF文件。每次批量写入硬盘数据量由配置
aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞。 - 新AOF文件写入完成后,子进程发送信号给父进程。
- 由于父进程依然响应命令,Redis使用“AOF重写缓冲区”保存这部分新数据,防止新AOF文件生成期间丢失这部分数据。
- 父进程更新统计信息,具体见
info persistence下的aof_*相关统计。
持久化文件加载
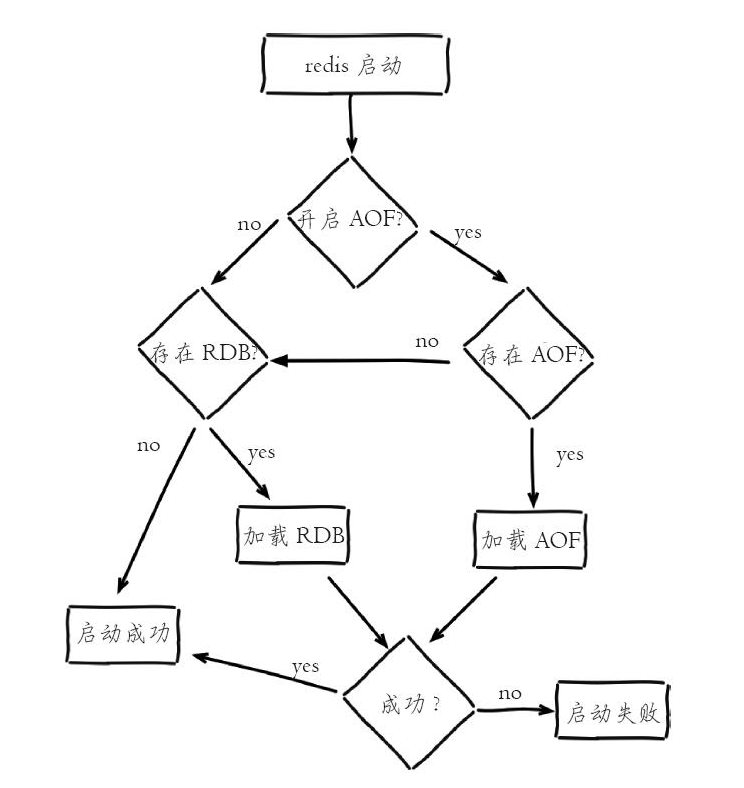
- AOF持久化开启且存在AOF文件时,优先加载AOF文件
- AOF关闭或者AOF文件不存在时,加载RDB文件
- 加载AOF/RDB文件成功后,Redis启动成功。
- AOF/RDB文件存在错误时,Redis启动失败并打印错误信息。
高可用
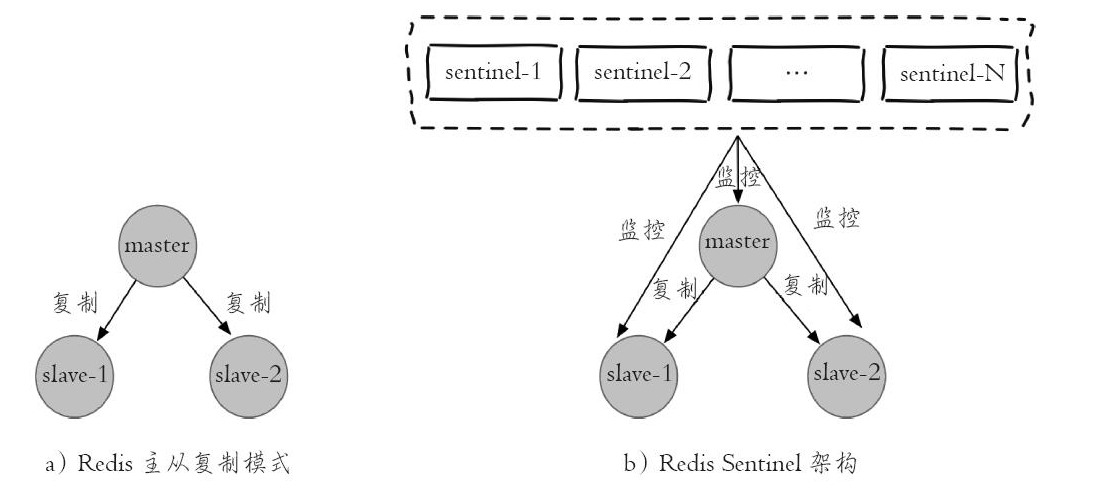
Redis支持主从复制,但是当发生故障的时候必须人工进行故障转移,人工故障转移实际就不是服务高可用。
- 2.8 版本之前 Redis 复制采用 sync 命令,无论是第一次主从复制还是断线重连后再进行复制都采用全量同步,成本太高
- 2.8 ~ 4.0 之间复制采用 psync 命令,这一特性主要添加了 Redis 在断线重连时候可通过 offset 信息使用部分同步
- 4.0 版本之后也采用 psync,相比于 2.8 版本的 psync 优化了增量复制,这里我们称为 psync2.0,2.8 版本的 psync 可以称为 psync
主从复制详细流程可以看Redis 主从复制 psync1 和 psync2 的区别
哨兵
Redis Sentinel包含若干个Sentinel节点和Redis数据节点,每个Sentinel节点会对Redis节点和其余Sentinel节点进行监控,当它发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它还会和其他Sentinel节点进行“协商”,当大多数Sentinel节点都认为主节点不可达时,它们会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给Redis应用方。整个过程完全是自动的,不需要人工来介入,所以这套方案很有效地解决了Redis的高可用问题。
哨兵仅仅时在主从复制之上做了额外的监控处理,因此实际架构并没有发生改变。
Redis2.8版本的哨兵成为Redis Sentinel 2,对初始Sentinel实现的重写,使用更强大、更简单的预测算法。Redis Sentinel 1是 Redis 2.6版本出厂的,已经弃用。
流程
- 哨兵定时监控主节点。
- 主节点发生故障时,若个哨兵对主节点发生故障情况达成一致,哨兵会选举出一个哨兵节点作为领导者负责故障转移。
- 哨兵从从节点选举出一个新的节点作为主节点。执行
slaveof no one命令,将其设置为主节点。 - 哨兵将其余节点设置为新的主节点的从节点。执行
slaveof masterip masterport - 从节点从主节点全量复制
redis4.0版本以后可以避免主从切换的全量复制问题。
安装部署
关于哨兵的服务搭建可以查看我的另一篇博客《Windows版本redis高可用方案探究》,介绍了在windows版本的哨兵搭建,linux下也是大同小异的。
redis服务配置
| 配置名 | 配置说明 |
|---|---|
| slaveof | 主节点的ip和端口 |
| requirepass | 当前节点的密码 |
| masterauth | 主节点的密码 |
当主从设置密码时,必须要设置为一样的,否则可能出现主从切换时,密码发生变化导致从无法连接上主。
哨兵配置
一个完整哨兵配置如下
port 26379
daemonize yes
logfile "26379.log"
dir "/opt/soft/redis/data"
sentinel myid 5511e27289c117b38f42d2b8edb1d5446a3edf68
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds master 5000
sentinel failover-timeout master 10000
sentinel auth-pass mymaster test1
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
#发现两个slave节点
sentinel known-slave mymaster 127.0.0.1 6380
sentinel known-slave mymaster 127.0.0.1 6381
#发现两个sentinel节点
sentinel known-sentinel mymaster 127.0.0.1 26380 282a70ff56c36ed56e8f7ee6ada741 24140d6f53
sentinel known-sentinel mymaster 127.0.0.1 26381 f714470d30a61a8e39ae031192f1fe ae7eb5b2be
sentinel current-epoch 0
主redis配置
sentinel monitor <master-name> <ip> <port> <quorum>- master-name:是主节点的别名
- ip和port:主节点的ip和端口
- quorum:代表要判定主节点最终不可达所需要的票数。
同一个哨兵可以监控多个主节点,只需要将不同主节点设置为不同的别名即可。
哨兵id
sentinel myid ID
哨兵首次启动会生成一个40位的唯一id,并会将id写入到配置文件中:其他哨兵可选配置
sentinel <option_name> <master_name> <option_value>
其他配置结构都是以sentinel开头,后面根据一个配置名 然后是redis别名和配置值- down-after-milliseconds:每个哨兵节点都要定期发送
ping命令从而判断Redis和其余哨兵系欸点是否可达,若超过了配置的时间没有恢复,则认为不可达,也被称之为主观下线。 配置格式为sentinel down-after-milliseconds <master-name> <times>,times为超时时间,单位为毫秒 - parallel-syncs:当哨兵集合对主节点故障达成一致时,哨兵领导者节点会左故障转移操作,选出新的主节点。而从节点则会向新的主节点进行数据复制操作。若有大量的从节点同时复制,对网络带宽会占用一定影响,尤其时Redis4.0以前每次主从切换都需要继续全量数据同步。配置格式为
sentinel parallel-syncs <master-name> <nums>,nums为并行同步的数量,配置为1时,从节点则会轮询同步。 - failover-timeout:当故障转移失败时,过一点时间后再尝试故障转移。配置格式为
sentinel failover-timeout <master-name> <times>,times为故障转移失败重试的时间间隔,单位为毫秒。 - auth-pass:若redis节点配置了密码,则哨兵节点也需要配置redis的密码。需要注意的是,若redis配置密码,则主从Redis以及哨兵都需要配置相同的密码。
- notification-script:当发生故障转移期间,当一些警告级别的Sentinel事件发生时(例如-sdown:客观下线和、-odown:主观下线),会触发配置路径的脚本,并转递事件参数,可以通过脚本通过右键、短信或其他方式进行通知预警。配置格式为
sentinel notification-script <master-name> <script-path>,script-path为脚本路径。客观下线:哨兵每隔1秒对主节点、从节点和其他哨兵节点发送
ping命令做心跳检测,当超过down-after-milliseconds未响应,则认为节点不可达,即为主观下线。
主观下线:当哨兵监控的主节点主观下线时,哨兵节点会通过通过 sentinel is-master-down-by-addr命令向其他哨兵节点确认主节点是否下线。当有quorum个哨兵认为主节点不可达(主观下线)时,则认为主节点客观下线(大部分哨兵都同意主节点下线,即为客观),即当主节点客观下线时哨兵领导者就会开始主节点的故障转移。
* client-reconfig-script:当发生发生故障转移发生主从切换时,可以调用特定脚本执行指定的任务以通知新主节点的位置。sentinel client-reconfig-script <master-name> <script-path>。
- down-after-milliseconds:每个哨兵节点都要定期发送
动态修改配置
哨兵也和redis节点类似,支持动态修改配置,通过
sentinel set <master_name> <option_name> <option_value>,修改当前哨兵的指定主节点的哨兵配置。
配置技巧
- 多个哨兵节点不应该部署在同一台物理机上。
- 至少部署三个且为奇数个的哨兵。因为哨兵领导者至少需要一半加一个哨兵节点投票选举。
集群
Redis Cluster是官方提供的Redis分布式解决方案,在3.0版本正式推出。
原理
Redis集群通过分片的方式来保存数据库中的键值对。一般有Hash分区和顺序分区两种方式分片,Redis使用Hash分区的方式将数据进行平均分布。Redis内部分为0~16383个虚拟槽,将虚拟槽分发给各个Redis节点。集群上线前需要先将所有虚拟槽分发完成。
当一个Redis节点设置了虚拟槽时,它通过消息通知其他的节点自己所处的虚拟槽,这样所有的Redis节点都会更新并保存槽信息。
集群命令执行
当客户端向集群某个Redis发送了一个命令时,该节点会计算要处理的数据键属于哪个槽,若属于自己的槽则直接执行命令,若属于其他节点,则发送一个MOVED错误执行请求重定向,客户端接受到MOVE重定向请求则会将命令发送到重定向后的节点执行。
重新分片
当Redis集群重新分片时,则将重新分配的虚拟槽的数据转移到目标节点,这个转移操作并不会影响新的命令请求。
ASK错误
当在分片期间执行命令时,可能出现部分数据被迁移到新的节点中,部分数据还在老的节点中未迁移,Redis集群也能够从容的应对该种情况,通过ASK错误执行ASK重定向将客户端转向正在迁移的目标节点,客户端则到新的节点重新执行命令。
集群搭建
- 准备配置
- 启动所有Redis节点
- Redis节点握手,发现集群
- 分配虚拟槽
- 集群上线
- 搭建集群主从
搭建由3个Redis节点组成的集群。将data目录设置为redis根目录,所有的RDB文件,AOP文件,日志和配置都存放到data目录中。
准备配置
准备三个配置文件,以
redis-{port}.config命名。
比如7379端口的redis节点配置如下,7380和7381配置类似。port 7379 pidfile /var/run/redis_7379.pid logfile "log/redis-7379.txt" dbfilename dump-7379.rdb dir ./data/ appendfilename "appendonly-7379.aof" # 开启集群模式 cluster-enabled yes # 节点超时时间,单位毫秒 cluster-node-timeout 15000 # 集群内部配置文件 cluster-config-file "nodes-7379.conf"启动节点
启动三个redis节点
jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-server data/redis-7379.config jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-server data/redis-7380.config jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-server data/redis-7381.config启动完成由于没有集群配置,默认会先创建集群配置nodes-.conf
jake@Jake-PC:~/tool/demo/redis-cluster/redis/data$ ls appendonly-7379.aof appendonly-7381.aof nodes-7380.conf redis-7379.config redis-7380.config redis-7381.config appendonly-7380.aof nodes-7379.conf nodes-7381.conf redis-7379.txt redis-7380.txt redis-7381.txt启动成功后会显示
Running in cluster mode表示以集群模式运行节点握手
节点握手是指集群节点通过Gossip协议彼此通信,达到感知对方的过程。只需要在客户端发起
cluster meet {ip} {port}命令。127.0.0.1:7379> cluster meet 127.0.0.1 7380 127.0.0.1:7379> cluster meet 127.0.0.1 7381握手完毕后可以通过
cluster nodes查看当前的集群节点127.0.0.1:7379> cluster nodes ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 myself,master - 0 1572506163000 0 connected 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 master - 0 1572506162658 2 connected 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 master - 0 1572506163689 1 connected通过
cluster info查看当前集群状态127.0.0.1:7379> cluster info cluster_state:fail cluster_slots_assigned:0 cluster_slots_ok:0 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:3 cluster_size:0 cluster_current_epoch:2 cluster_my_epoch:0 cluster_stats_messages_ping_sent:84 cluster_stats_messages_pong_sent:88 cluster_stats_messages_meet_sent:2 cluster_stats_messages_sent:174 cluster_stats_messages_ping_received:88 cluster_stats_messages_pong_received:86 cluster_stats_messages_received:174若此时读写数据会返回错误
127.0.0.1:7379> set hello redis-cluster (error) CLUSTERDOWN Hash slot not served 127.0.0.1:7379> get hello (error) CLUSTERDOWN Hash slot not served由于前面我们提到了集群搭建完成后必须先分配虚拟槽。
cluster_ slots_ assigned是已分配的虚拟槽,目前是0,因此我们需要将虚拟槽进行分配。分配虚拟槽
通过命令
CLUSTER ADDSLOTS <slot> [slot ...]分配虚拟槽,但是redis原生命令只能一个个分配或者一次分配多个,没办法直接分配一个区间的虚拟槽,因此需要自己修改redis源码支持,或者可以写一个脚本批量分配。批量分配槽
在linux上可以通过shell 脚本,在windows上可以通过powershell,且powershell脚本原生支持m..n生成m到n的一维数组,比较方便。
我个人对linux上的shell脚本不是很了解,查找了下资料也没有像powershell或者python类似的初始化一维数组的语法。
目前已经发布的powershell core(powershell 6.0)支持跨平台,下面我们通过powershell脚本实现批量分配槽。再次之前我先要在linux上安装powershell
我本机安装的是Ubuntu 18.04,以超级用户身份注册 Microsoft 存储库一次。 注册后,可以通过
sudo apt-get upgrade powershell更新PowerShell。# Download the Microsoft repository GPG keys wget -q https://packages.microsoft.com/config/ubuntu/18.04/packages-microsoft-prod.deb # Register the Microsoft repository GPG keys sudo dpkg -i packages-microsoft-prod.deb # Update the list of products sudo apt-get update # Enable the "universe" repositories sudo add-apt-repository universe # Install PowerShell sudo apt-get install -y powershell # Start PowerShell pwsh下载并安装完成后,通过
pwsh可以启用powershell,就可以执行powershell脚本了。我们可以通过
redis-cli -p port CLUSTER ADDSLOTS <slot> [slot ...]直接执行脚本设置虚拟槽。
在powershell中分配0到5的一维数组PS C:\Users\Dm_ca> 0..5 0 1 2 3 4 5通过
redis-cli -p 7379 CLUSTER ADDSLOTS (0..5000)分配0~5000的槽给7379端口PS /home/jake/tool/demo/redis-cluster/redis> ./src/redis-cli -p 7379 CLUSTER ADDSLOTS (0..5000) OK同样分配其他的从给其他redis节点
PS /home/jake/tool/demo/redis-cluster/redis> ./src/redis-cli -p 7380 CLUSTER ADDSLOTS (5001..10000) OK PS /home/jake/tool/demo/redis-cluster/redis> ./src/redis-cli -p 7381 CLUSTER ADDSLOTS (10001..16383) OK再次查看redis集群状态,可以看到状态已经从fail变为ok,且cluster_slots_ok分配了16384个槽。
127.0.0.1:7379> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:3 cluster_size:3 cluster_current_epoch:2 cluster_my_epoch:0 cluster_stats_messages_ping_sent:3734 cluster_stats_messages_pong_sent:3677 cluster_stats_messages_meet_sent:2 cluster_stats_messages_sent:7413 cluster_stats_messages_ping_received:3677 cluster_stats_messages_pong_received:3736 cluster_stats_messages_received:7413查看集群节点情况,可以看到每个节点后分配的槽的范围
127.0.0.1:7379> cluster nodes ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 myself,master - 0 1572510104000 0 connected 0-5000 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 master - 0 1572510106000 2 connected 10001-16383 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 master - 0 1572510106756 1 connected 5001-10000搭建集群主从
目前我们分配了3个主节点形成另一个redis集群。但是若一个节点挂了,则整个集群又会变为不可用状态。
将7379节点关闭,然后查看集群状态
127.0.0.1:7380> cluster nodes 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 myself,master - 0 1572510227000 1 connected 5001-10000 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 master - 0 1572510230245 2 connected 10001-16383 ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 master,fail - 1572510210543 1572510209905 0 disconnected 0-5000 127.0.0.1:7380> cluster info cluster_state:fail cluster_slots_assigned:16384 cluster_slots_ok:11383 cluster_slots_pfail:0 cluster_slots_fail:5001 cluster_known_nodes:3 cluster_size:3 cluster_current_epoch:2 cluster_my_epoch:1 ...因此我们需要实现集群高可用,为每个redis主节点加入从节点。
准备三个配置文件端口分别设置为7479、7480和7481,分别对应7379、7380和7381的从库。启动三个redis节点
jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-server data/redis-7479.config jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-server data/redis-7480.config jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-server data/redis-7481.config jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7479 cluster meet 127.0.0.1 7379 OK jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7480 cluster meet 127.0.0.1 7380 OK jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7481 cluster meet 127.0.0.1 7379 OK再次查看集群节点
jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7481 cluster nodes 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 master - 0 1572514591000 1 connected 5001-10000 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 master - 0 1572514593720 2 connected 10001-16383 44b31c845115b8e20ad07c50ef1fa035a8f77574 127.0.0.1:7479@17479 master - 0 1572514592000 3 connected 57dd93502af7600b074ed1a021f4f64fbb56c3f4 127.0.0.1:7481@17481 myself,master - 0 1572514591000 5 connected 0e0899d1c692fa3106073880d974acd93c426011 127.0.0.1:7480@17480 master - 0 1572514592713 4 connected ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 master - 0 1572514592000 0 connected 0-5000通过
cluster replicate {nodeId}命令将当前节点设置为集群主节点的从节点。jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7479 cluster replicate ffff2fe734c1ae5be4f66d574484a89f8bd303f3 OK jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7480 cluster replicate 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 OK jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7481 cluster replicate 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 OK再次查看节点状态,可以看到三个新增节点已经变为从库
jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7481 cluster nodes 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 master - 0 1572514841965 1 connected 5001-10000 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 master - 0 1572514842981 2 connected 10001-16383 44b31c845115b8e20ad07c50ef1fa035a8f77574 127.0.0.1:7479@17479 slave ffff2fe734c1ae5be4f66d574484a89f8bd303f3 0 1572514842000 3 connected 57dd93502af7600b074ed1a021f4f64fbb56c3f4 127.0.0.1:7481@17481 myself,slave 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 0 1572514841000 5 connected 0e0899d1c692fa3106073880d974acd93c426011 127.0.0.1:7480@17480 slave 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 0 1572514841000 4 connected ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 master - 0 1572514840000 0 connected 0-5000把7381的主库断开,后7481自动变为主。
jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7381 shutdown 127.0.0.1:7481> cluster nodes 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 master - 0 1572515223688 1 connected 5001-10000 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 master,fail - 1572515116020 1572515114203 2 disconnected 44b31c845115b8e20ad07c50ef1fa035a8f77574 127.0.0.1:7479@17479 slave ffff2fe734c1ae5be4f66d574484a89f8bd303f3 0 1572515221634 3 connected 57dd93502af7600b074ed1a021f4f64fbb56c3f4 127.0.0.1:7481@17481 myself,master - 0 1572515220000 6 connected 10001-16383 0e0899d1c692fa3106073880d974acd93c426011 127.0.0.1:7480@17480 slave 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 0 1572515221000 4 connected ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 master - 0 1572515222656 0 connected 0-5000最后将7381恢复,7381变为7481的从库
jake@Jake-PC:~/tool/demo/redis-cluster/redis$ src/redis-cli -p 7381 cluster nodes 57dd93502af7600b074ed1a021f4f64fbb56c3f4 127.0.0.1:7481@17481 master - 0 1572515324842 6 connected 10001-16383 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 127.0.0.1:7380@17380 master - 0 1572515325852 1 connected 5001-10000 44b31c845115b8e20ad07c50ef1fa035a8f77574 127.0.0.1:7479@17479 slave ffff2fe734c1ae5be4f66d574484a89f8bd303f3 0 1572515322000 3 connected 1d3f7bd0d705ce2926ccc847b4323fcfbfe29f53 127.0.0.1:7381@17381 myself,slave 57dd93502af7600b074ed1a021f4f64fbb56c3f4 0 1572515324000 2 connected 0e0899d1c692fa3106073880d974acd93c426011 127.0.0.1:7480@17480 slave 36f26b6c6a87202a4a29eba4daf7bf2ff47e2914 0 1572515324000 4 connected ffff2fe734c1ae5be4f66d574484a89f8bd303f3 127.0.0.1:7379@17379 master - 0 1572515323837 0 connected 0-5000
参考文档
- redis
- redis开发与运维
- redis配置文件详解
- redis debug命令详解
- Redis 主从复制 psync1 和 psync2 的区别
- 在 Linux 上安装 PowerShell Core
微信扫一扫二维码关注订阅号杰哥技术分享
本文地址:https://www.cnblogs.com/Jack-Blog/p/11781421.html
作者博客:杰哥很忙
欢迎转载,请在明显位置给出出处及链接


 浙公网安备 33010602011771号
浙公网安备 33010602011771号