

利用Python爬虫爬取京东商品的简要信息
一、前言
本文适合有一定Python基础的同学学习Python爬虫,无基础请点击:慕课网——Python入门
申明:实例的主体框架来自于慕课网——Python开发简单爬虫
语言:Python2
IDE:VScode
二、何为爬虫
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,然后下载队列中的URL地址对应的网页。解析后抓取网页内容,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。同时,它还会根据一定的搜索策略获取我们所需的信息并保存下来。最后为了展示我们爬到的数据,往往还会用HTML的表格或记事本保存我们所需要的数据。
简单来说,爬虫就是一门用来从互联网上自动获取我们所需数据的技术。
三、JD商品详情页的网页分析
入口URL选择为JD某商品详情页:https://item.jd.com/4224129.html
我们需要分析的内容主要有:
3.1详情页上指向的其他URL
我们打开https://item.jd.com/4224129.html,发现网页上还有很多指向其他商品的链接。


通过鼠标右键,查看元素,我们可以发现商品页面上的以上链接均为以下格式: //item.jd.com/数字.html

分析到此,我们就知道抓取网页内容时,从当前页面上抽取新的URL的方法了。
3.2商品名称、价格
同理,我们在商品名称和价格处点击鼠标右键查看元素


四、简单爬虫框架
1.爬虫总调度程序
即我们的main文件,以入口URL为参数爬取所有相关页面
2.URL管理器
维护待爬取和已爬取的URL列表
3.HTML下载器
主要功能是下载指定的url,这里用到了urllib2
4.HTML解析器
主要功能是获取网页上所需的URL和内容,用到BeautifulSoup
正则表达式的基础知识可以参见
另外安利一个网站,在写正则表达式的时候可以先测试,很实用
5.输出程序
将爬取到的数据写入HTML文件中,利用HTML的table展示
五、源码
1.爬虫总调度程序
import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.Html_DownloaDer() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() #爬虫调度程序 def craw(self, root_url): count = 1 #入口URL添加进URL管理器 self.urls.add_new_url(root_url) #启动循环,获取待扒取的URL,然后交给下载器下载页面,调用解析器解析页面 while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print 'craw',count, ':' ,new_url html_cont = self.downloader.download(new_url) #得到新的URL列表和内容 new_urls, new_data = self.parser.parse(new_url,html_cont) #新的URL存到URL管理器,同时进行数据的收集 self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 10: break count = count +1 except: print 'craw dailed' #调用output_html展示爬取到的数据 self.outputer.output_html() if __name__ == "__main__": #入口URL root_url = "https://item.jd.com/4224129.html" obj_spider = SpiderMain() #启动爬虫 obj_spider.craw(root_url)
2.URL管理器
class UrlManager(object): def __init__(self): #未爬取URL列表,已爬取URL列表 self.new_urls = set() self.old_urls = set() #判断管理器中是否有新的待扒取的URL def has_new_url(self): return len(self.new_urls) != 0 #获取一个新的待扒取的URL def get_new_url(self): #pop方法:获取列表中的一个URL并移除它 new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url #向管理器添加一个新的URL def add_new_url(self, url): if url is None: return #发现新的未添加的URL,则加入待扒取URL列表 if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) #向管理器添加批量个新的URL def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url)
3.HTML下载器
import urllib2 class Html_DownloaDer(): def download(self, url): if url is None: return None #调用urllib2库的urlopen方法获取 类文件对象(fd) response """ response = urllib2.urlopen(url)""" #调用urllib2库的Request方法创建request对象 request = urllib2.Request(url) #添加数据 request.add_data('a') #添加htp和header(伪装成浏览器) request.add_header('User-Agent','Mozilla/5.0') #发送请求获取结果 response = urllib2.urlopen(request) #获取状态码,200表示成功 if response.getcode() != 200: return None return response.read()
4.HTML解析器
from bs4 import BeautifulSoup import re import urlparse class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() #获取所有的链接 #格式如:<a target="_blank" title="华为(HUAWEI)..." href="//item.jd.com/12943624333.html"> links = soup.find_all('a',href = re.compile(r"//item.jd.com/\d+\.htm")) #遍历转化为完整的URL for link in links: new_url = link['href'] new_full_url = urlparse.urljoin(page_url,new_url) #将结果存到一个新的列表里 new_urls.add(new_full_url) return new_urls def _new_data(self, page_url, soup): res_data = {} #URL res_data['url'] = page_url #匹配标题 #<div class="sku-name">华为(HUAWEI) MateBook X 13英寸超轻薄微边框笔记本(i5-7200U 4G 256G 拓展坞 2K屏 指纹 背光 office)灰</div> title_node = soup.find('div',class_ = "sku-name") res_data['title'] = title_node.get_text() #匹配价格 #<div class="dd"> #<span class="p-price"><span>¥</span><span class="price J-p-7430495">4788.00</span></span> """下载的网页源码无价格信息<span class="price J-p-7430495"></span></span>!!!!!""" price_node = soup.find('span',class_ = re.compile(r"price\sJ\-p\-\d+")) res_data['price'] =price_node.get_text() return res_data def parse(self, page_url, html_cont): if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont,'html.parser') new_urls = self._get_new_urls(page_url,soup) _new_data = self._new_data(page_url,soup) return new_urls, _new_data
5.输出程序
class HtmlOutputer(object): def __init__(self): self.datas = [] def collect_data(self,data): if data is None: return self.datas.append(data) def output_html(self): fout = open('output.html','w') fout.write("<html>") fout.write("<head>") fout.write('<meta charset="UTF-8">') fout.write("<body>") fout.write("<table>") #python默认编码是ascii,中文可能会乱码,故加上encode('utf-8') for data in self.datas: fout.write("<tr>") fout.write("<td>%s</td>" % data['url']) fout.write("<td>%s</td>" % data['title'].encode('utf-8')) fout.write("<td>%s</td>" % data['price'].encode('utf-8')) fout.write("</tr>") fout.write("</table>") fout.write("</body>") fout.write("</head>") fout.write("</html>")
六、待解决问题
关于我爬取不到价格的问题...
调试中发现我已爬取到了对应的内容,唯独少了价格...一度扎心啊...
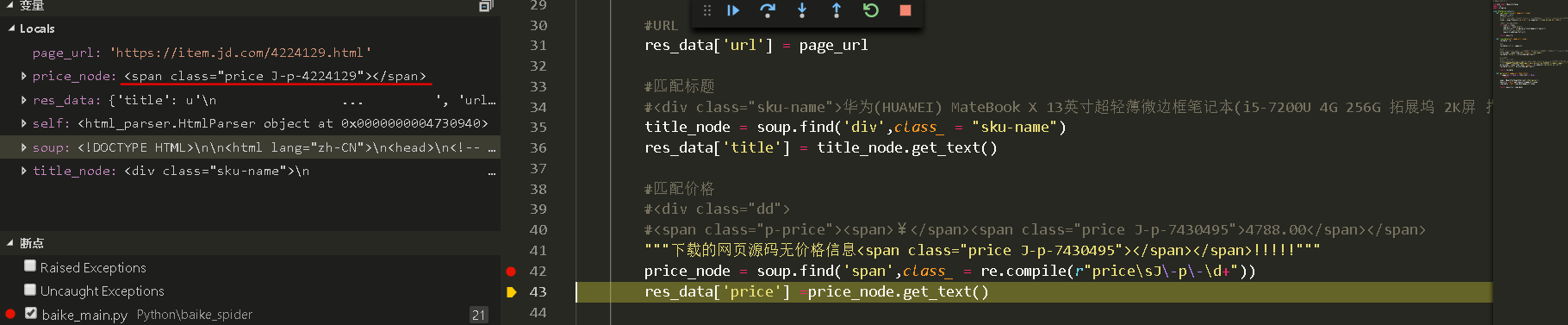
在 Python爬虫——实战一:爬取京东产品价格(逆向工程方法) - CSDN博客 上看到以下论述

但是...我查看源码的时候真的是有价格的啊...求大神解惑
ps:第一次写博客,思路不是很清晰,欢迎学习交流指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号