

深入了解爬虫原理
HTTP/1.1方法
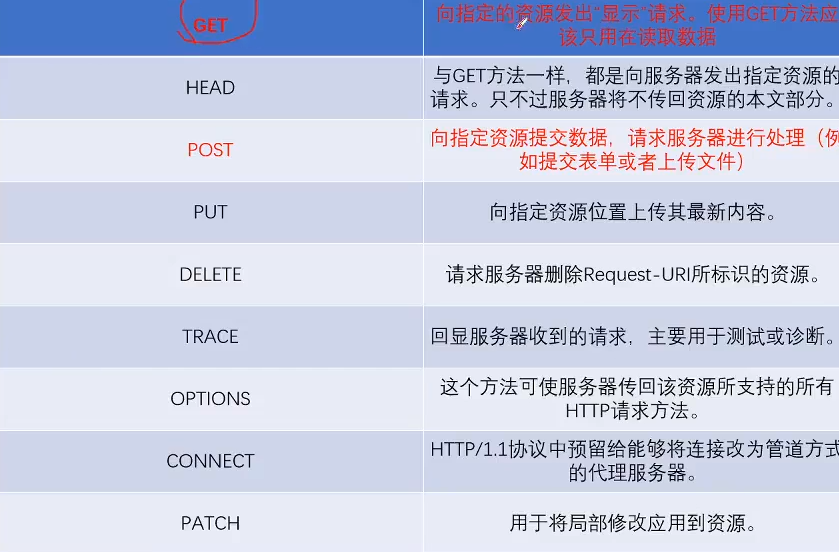
HTTP1.0中,只有GET和POST,没有其他方法,如果是新网站是可以获取内容
head命令只能返回头部部分,类似于Ping测试网址是否连通
put只能上传最新的内容,patch局部修改
主要是get和Post
HTTPS多实现一层S,五层中,最上面是应用层,然后是多出来的安全层SSL,然后是传输层,网络层,网络接口层
HTTPS可以加密传输,身份验证,需要去CA申请证书,要费用,需要消耗过量CPU,端口为443,HTTP端口为80

状态码系列
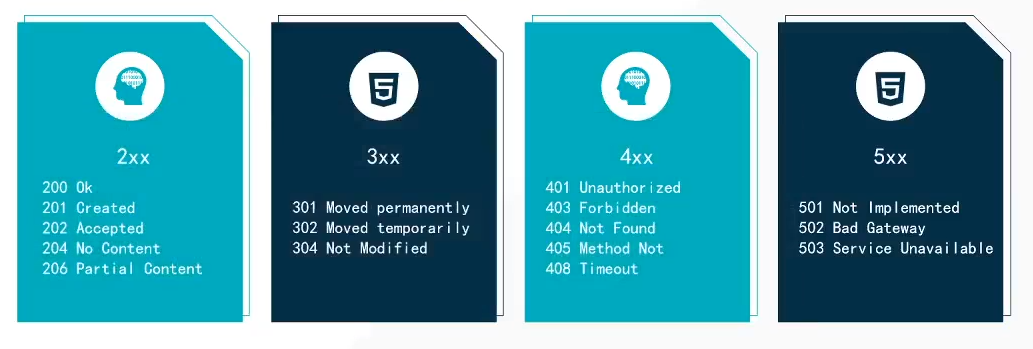
206:比如很多图片的,但是看起来小且模糊就是206,过一会高清了就是200
204:没有内容,成功请求
301:永久转移,302:暂时重定向,304:内容一样,缓存一样,不动
5XX:服务器崩了,与你没关系了
401:身份未验证,403:IP被封了,404:页面丢失,405:方法写错了,408:超时了
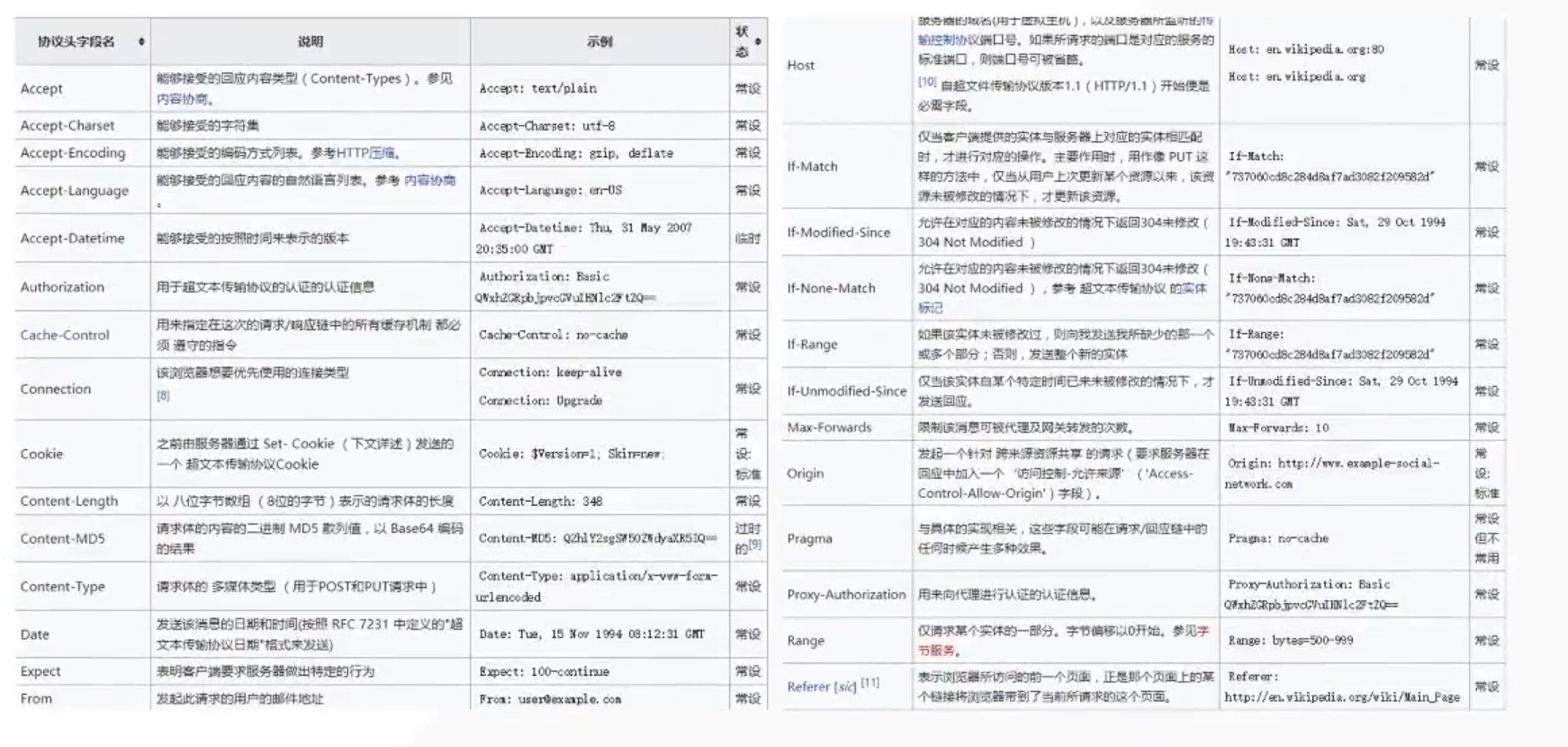
Cache_control,cookie,host,referer,user_agent
回应字段中
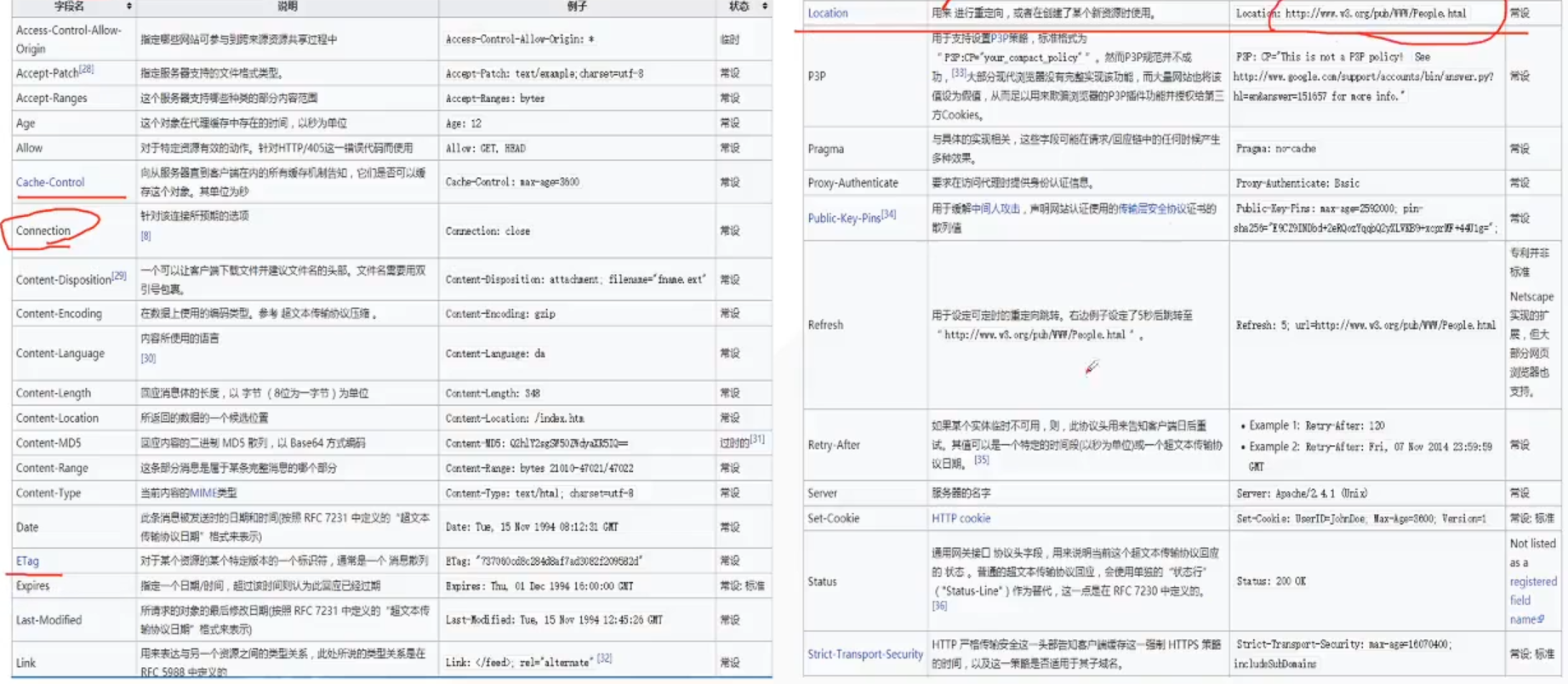
Cookies
是一个小型的文本文件
第一类硬盘型,在硬盘里可以找到,有过期时间检测,过期了就会删除,手动的话清理cookies
第二类内存型,关闭浏览器自动删除
cookies缺陷,附加在http请求里,增加了流量,因为明文传输不安全,大小限制在4KB,对于复杂需求来说不够用
拿人举例子,HTML相当于骨头,CSS相当于外表,JS代码相当于动作
Ajax交互

URL不变化不刷新,内容在刷新,就是AJAX
用get是请求不到内容的,要到XHR里找接口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号