


本次主要对综合案例进行了学习
案例1:求TOP值
任务描述:orderid,userid,payment,productid
file1.txt
1,1768,50,155 2,1218,600,211 3,2239,788,242 4,3101,28,599 5,4899,290,129 6,3110,54,1201 7,4436,259,877 8,2369,7890,27
file2.txt
100,4287,226,233 101,6562,489,124 102,1124,33,17 103,3267,159,179 104,4569,57,125 105,1438,37,116
求Top N个payment值?
首先:启动集群,创建一个临时文件进行存储
[atguigu@hadoop102 ~]$ cd /usr/local/spark/ [atguigu@hadoop102 spark]$ cd mycode/ drwxrwxr-x. 6 atguigu atguigu 97 1月 21 21:09 wordcount [atguigu@hadoop102 mycode]$ mkdir rdd
进行创建
[atguigu@hadoop102 rdd]$ vim file1.txt
[atguigu@hadoop102 rdd]$ vim file2.txt
创建一个hdfs文件夹
[atguigu@hadoop102 mycode]$ cd /opt/module/hadoop-3.1.3/ [atguigu@hadoop102 hadoop-3.1.3]$ cd bin/ [atguigu@hadoop102 bin]$ ll 总用量 996 -rwxr-xr-x. 1 atguigu atguigu 441936 9月 12 2019 container-executor -rwxr-xr-x. 1 atguigu atguigu 8707 9月 12 2019 hadoop -rwxr-xr-x. 1 atguigu atguigu 11265 9月 12 2019 hadoop.cmd -rwxr-xr-x. 1 atguigu atguigu 11026 9月 12 2019 hdfs -rwxr-xr-x. 1 atguigu atguigu 8081 9月 12 2019 hdfs.cmd -rwxr-xr-x. 1 atguigu atguigu 6237 9月 12 2019 mapred -rwxr-xr-x. 1 atguigu atguigu 6311 9月 12 2019 mapred.cmd -rwxr-xr-x. 1 atguigu atguigu 483728 9月 12 2019 test-container-executor -rwxr-xr-x. 1 atguigu atguigu 11888 9月 12 2019 yarn -rwxr-xr-x. 1 atguigu atguigu 12840 9月 12 2019 yarn.cmd [atguigu@hadoop102 bin]$ hdfs dfs -mkdir -p /user/hadoop/spark/mycode/rdd/examples
上传
[atguigu@hadoop102 bin]$ hdfs dfs -put /usr/local/spark/mycode/rdd/file1.txt /user/hadoop/spark/mycode/rdd/examples 2024-01-22 18:16:10,917 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false [atguigu@hadoop102 bin]$ hdfs dfs -put /usr/local/spark/mycode/rdd/file2.txt /user/hadoop/spark/mycode/rdd/examples 2024-01-22 18:16:17,260 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
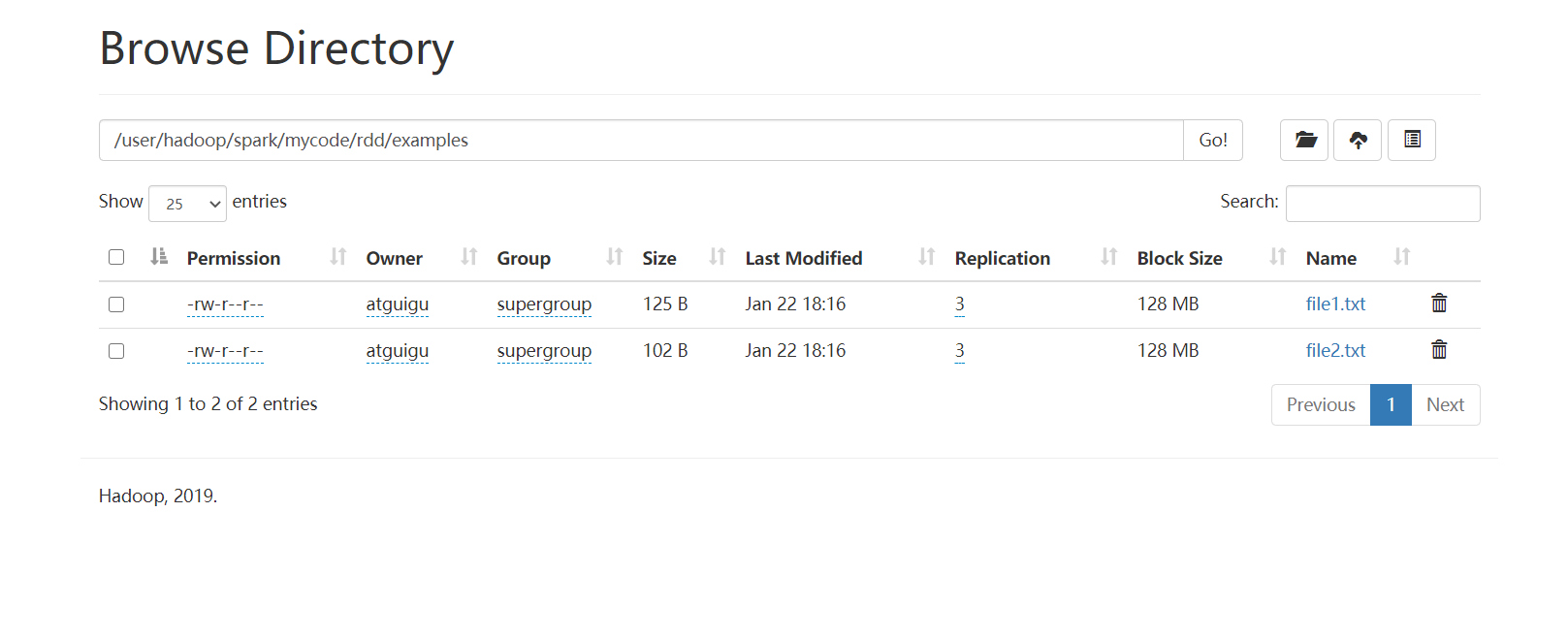
查看:
[atguigu@hadoop102 bin]$ hdfs dfs -ls /user/hadoop/spark/mycode/rdd/examples Found 2 items -rw-r--r-- 3 atguigu supergroup 125 2024-01-22 18:16 /user/hadoop/spark/mycode/rdd/examples/file1.txt -rw-r--r-- 3 atguigu supergroup 102 2024-01-22 18:16 /user/hadoop/spark/mycode/rdd/examples/file2.txt
可视化查看:
name := "Simple Project" version := "1.0" scalaVersion := "2.12.15" libraryDependencies += "org.apache.spark" %% "spark-core" % "3.2.0"
目录结构:
[atguigu@hadoop102 topscala]$ find . . ./src ./src/main ./src/main/scala ./src/main/scala/SimpleApp.scala ./simple.sbt
进行打包
[atguigu@hadoop102 topscala]$ /usr/local/sbt/sbt package
运行:
[atguigu@hadoop102 spark]$ ./bin/spark-submit --class "TopN" /usr/local/spark/mycode/topscala/target/scala-2.12/simple-project_2.12-1.0.jar
结果:

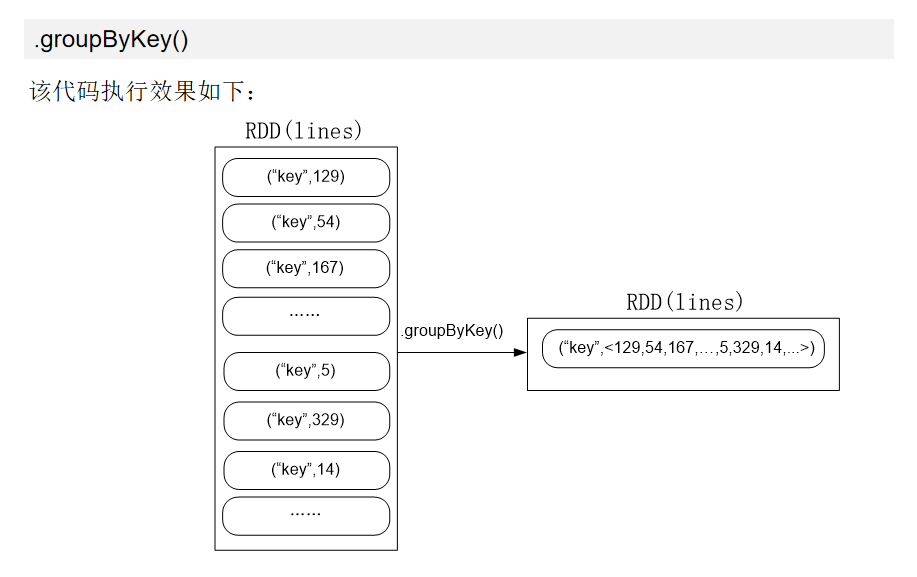
代码分析:

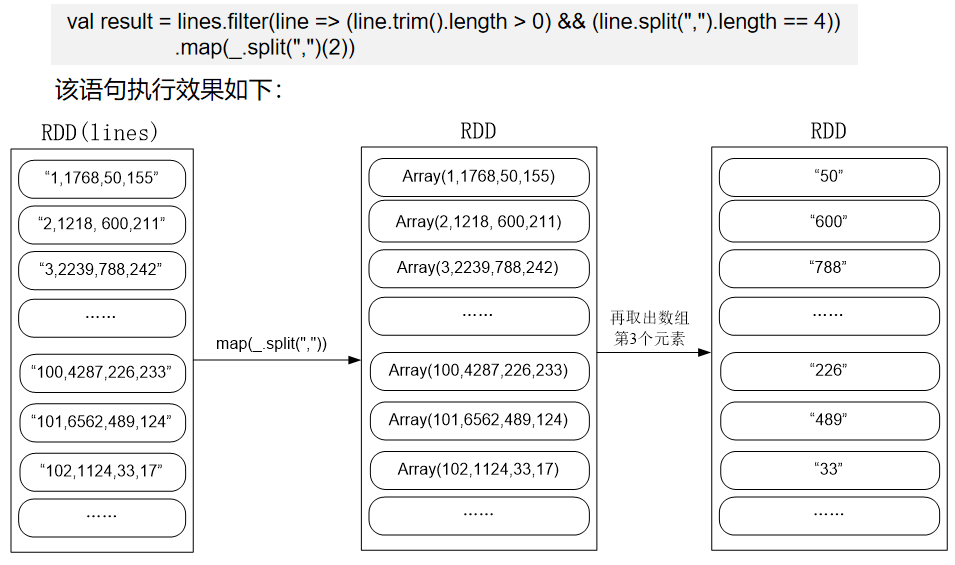
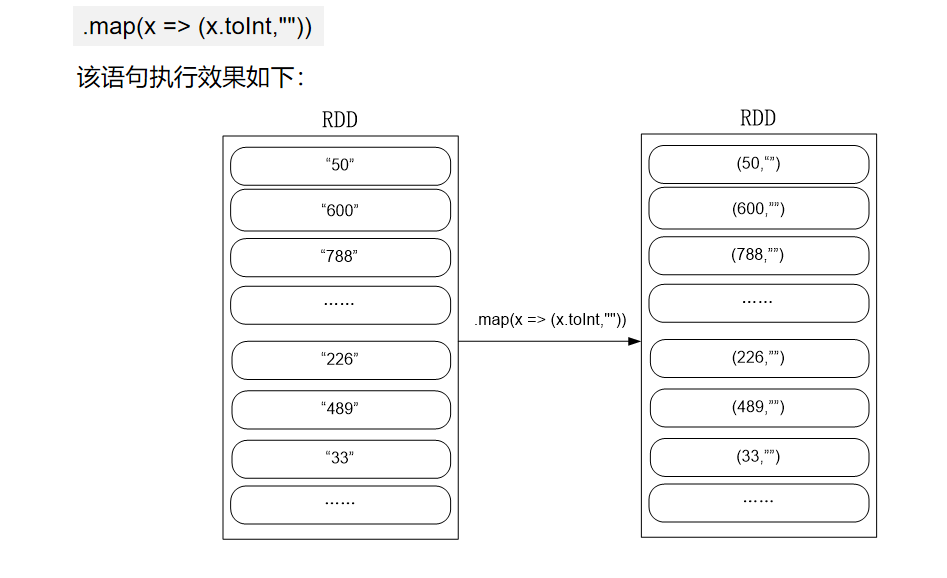
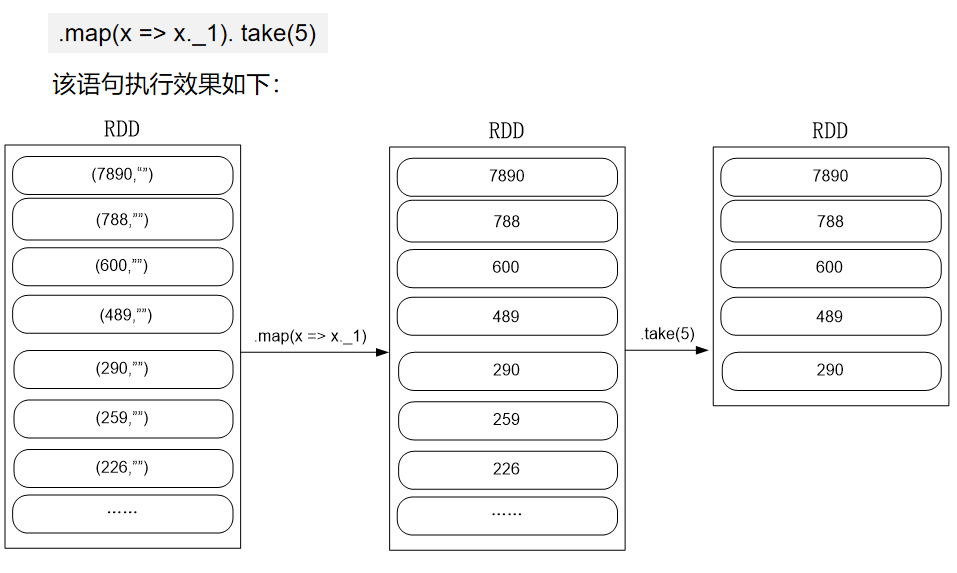
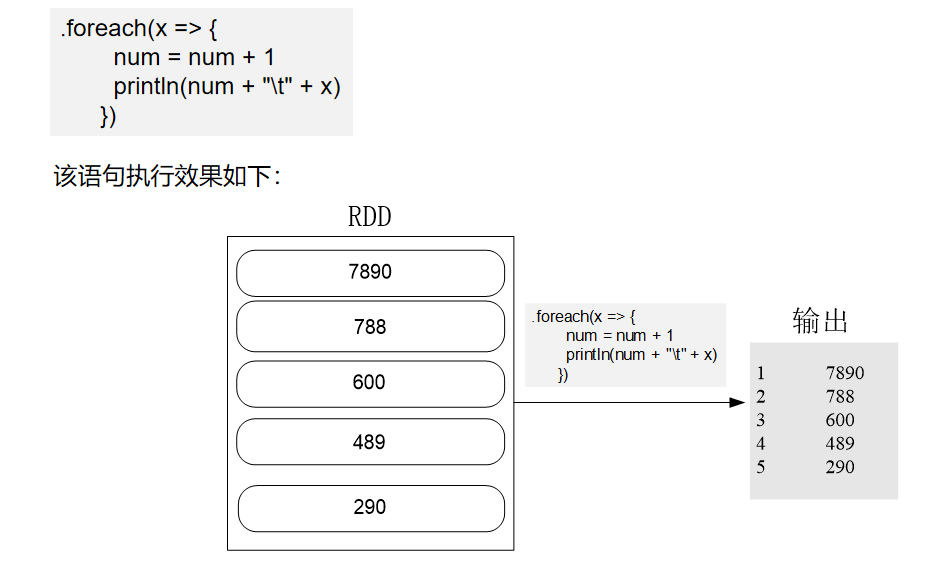
import org.apache.spark.{SparkConf, SparkContext} object MaxAndMin { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("MaxAndMin").setMaster("local") val sc = new SparkContext(conf) sc.setLogLevel("ERROR") val lines = sc.textFile("hdfs://localhost:9000/user/hadoop/spark/chapter5", 2) val result = lines.filter(_.trim().length>0).map(line => ("key",line.trim.toInt)).groupByKey().map(x => { var min = Integer.MAX_VALUE var max = Integer.MIN_VALUE for(num <- x._2){ if(num>max){ max = num } if(num<min){ min = num } } (max,min) }).collect.foreach(x => { println("max\t"+x._1) println("min\t"+x._2) }) } }
进行打包执行
[atguigu@hadoop102 scala]$ cd .. [atguigu@hadoop102 main]$ cd .. [atguigu@hadoop102 src]$ cd .. [atguigu@hadoop102 MaxAndMin]$ vim simple.sbt [atguigu@hadoop102 MaxAndMin]$ find . . ./src ./src/main ./src/main/scala ./src/main/scala/SimpleApp.scala ./simple.sbt [atguigu@hadoop102 MaxAndMin]$ /usr/local/sbt/sbt package Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0 [info] Loading project definition from /usr/local/spark/mycode/MaxAndMin/MaxAndMin/project [info] Loading settings for project maxandmin from simple.sbt ... [info] Set current project to Simple Project (in build file:/usr/local/spark/mycode/MaxAndMin/MaxAndMin/) [info] Compiling 1 Scala source to /usr/local/spark/mycode/MaxAndMin/MaxAndMin/target/scala-2.12/classes ... [success] Total time: 4 s, completed 2024-1-22 21:35:51 [atguigu@hadoop102 MaxAndMin]$ ll 总用量 4 drwxrwxr-x. 3 atguigu atguigu 44 1月 22 21:33 project -rw-rw-r--. 1 atguigu atguigu 141 1月 22 21:33 simple.sbt drwxrwxr-x. 3 atguigu atguigu 18 1月 22 21:27 src drwxrwxr-x. 4 atguigu atguigu 39 1月 22 21:34 target [atguigu@hadoop102 MaxAndMin]$ cd target/ [atguigu@hadoop102 target]$ ll 总用量 0 drwxrwxr-x. 4 atguigu atguigu 70 1月 22 21:35 scala-2.12 drwxrwxr-x. 4 atguigu atguigu 36 1月 22 21:34 streams [atguigu@hadoop102 target]$ cd scala-2.12/ [atguigu@hadoop102 scala-2.12]$ ll 总用量 4 drwxrwxr-x. 2 atguigu atguigu 53 1月 22 21:35 classes -rw-rw-r--. 1 atguigu atguigu 3776 1月 22 21:35 simple-project_2.12-1.0.jar drwxrwxr-x. 3 atguigu atguigu 31 1月 22 21:34 update [atguigu@hadoop102 scala-2.12]$ pwd /usr/local/spark/mycode/MaxAndMin/MaxAndMin/target/scala-2.12 [atguigu@hadoop102 scala-2.12]$ cd .. [atguigu@hadoop102 target]$ cd .. [atguigu@hadoop102 MaxAndMin]$ cd .. [atguigu@hadoop102 MaxAndMin]$ cd .. [atguigu@hadoop102 mycode]$ cd .. [atguigu@hadoop102 spark]$ ./bin/spark-submit --class "MaxAndMin" /usr/local/spark/mycode/MaxAndMin/MaxAndMin/target/scala-2.12/simple-project_2.12-1.0.jar
执行结果:
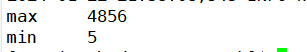
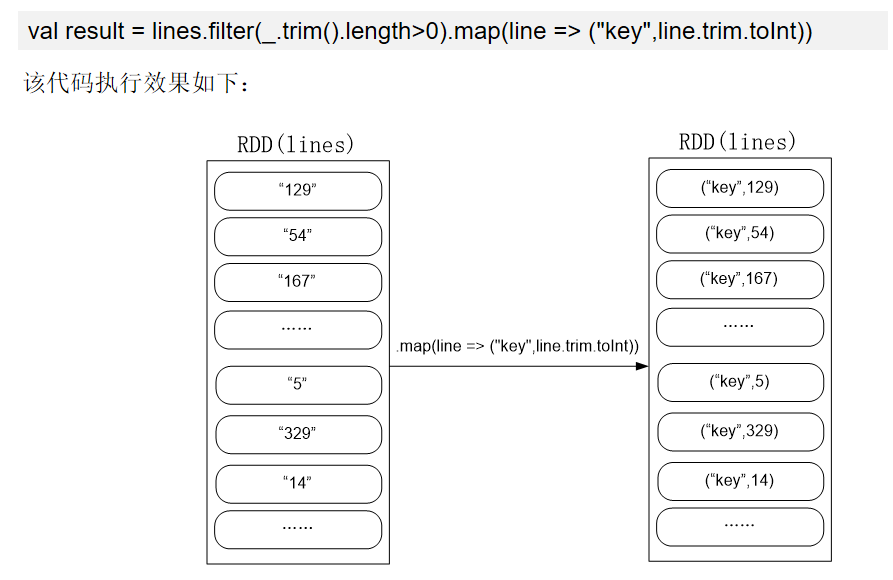
代码分析:

file3.txt
1 45 25
程序:
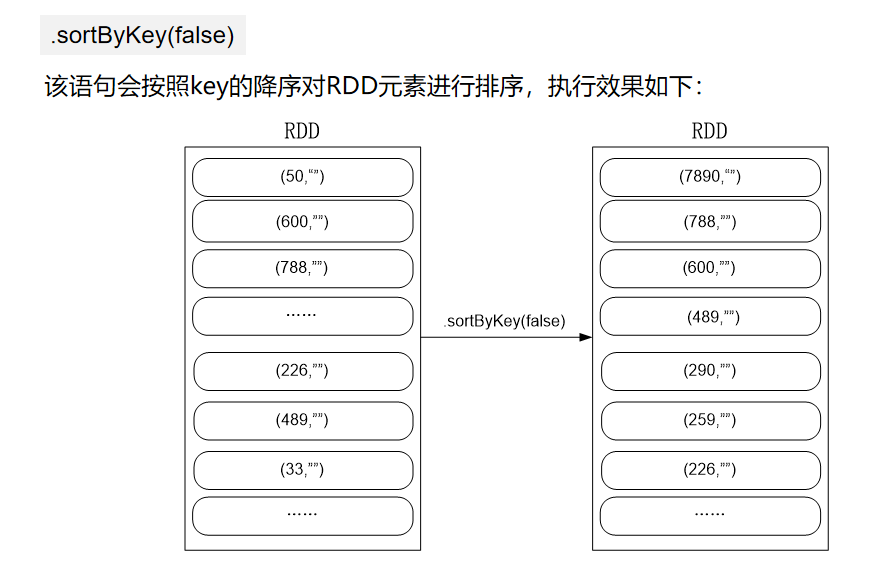
import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.spark.HashPartitioner object FileSort { def main(args: Array[String]) { val conf = new SparkConf().setAppName("FileSort") val sc = new SparkContext(conf) val dataFile = "file:///usr/local/spark/mycode/rdd/data/*" val lines = sc.textFile(dataFile, 3) var index = 0 val result = lines.filter(_.trim().length > 0).map(n => (n.trim.toInt, "")).partitionBy(new HashPartitioner(1)).sortByKey().map(t => { index += 1 (index, t._1) }) result.saveAsTextFile("file:///usr/local/spark/mycode/rdd/data/result") } }
执行过程
[atguigu@hadoop102 spark]$ cd mycode/rdd [atguigu@hadoop102 rdd]$ ll 总用量 8 -rw-rw-r--. 1 atguigu atguigu 124 1月 22 18:37 file1.txt -rw-rw-r--. 1 atguigu atguigu 102 1月 22 18:08 file2.txt [atguigu@hadoop102 rdd]$ mkdir data [atguigu@hadoop102 rdd]$ vim file1.txt [atguigu@hadoop102 rdd]$ cd data/ [atguigu@hadoop102 data]$ vim file1.txt [atguigu@hadoop102 data]$ vim file2.txt [atguigu@hadoop102 data]$ vim file3.txt [atguigu@hadoop102 data]$ cd ..cd -bash: cd: ..cd: 没有那个文件或目录 [atguigu@hadoop102 data]$ cd .. [atguigu@hadoop102 rdd]$ cd .. [atguigu@hadoop102 mycode]$ mkdir -p filesort/src/main/scala [atguigu@hadoop102 mycode]$ cd /s sbin/ software/ srv/ sys/ [atguigu@hadoop102 mycode]$ cd filesort/src/main/scala/ [atguigu@hadoop102 scala]$ vim SimpleApp.scala [atguigu@hadoop102 scala]$ cd .. [atguigu@hadoop102 main]$ cd .. [atguigu@hadoop102 src]$ cd .. [atguigu@hadoop102 filesort]$ vim simple.sbt [atguigu@hadoop102 filesort]$ find . . ./src ./src/main ./src/main/scala ./src/main/scala/SimpleApp.scala ./simple.sbt [atguigu@hadoop102 filesort]$ /usr/local/sbt/sbt package Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=256M; support was removed in 8.0 [info] Loading project definition from /usr/local/spark/mycode/filesort/project [info] Loading settings for project filesort from simple.sbt ... [info] Set current project to Simple Project (in build file:/usr/local/spark/mycode/filesort/) [info] Compiling 1 Scala source to /usr/local/spark/mycode/filesort/target/scala-2.12/classes ... [success] Total time: 4 s, completed 2024-1-22 22:14:06 [atguigu@hadoop102 filesort]$
运行过程报错太多,后面流程一样
主要原因:读取本地文件夹要加/*
val dataFile = "file:///usr/local/spark/mycode/rdd/data/*"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号