Java多线程:线程池
一、 背景
二、线程池的架构
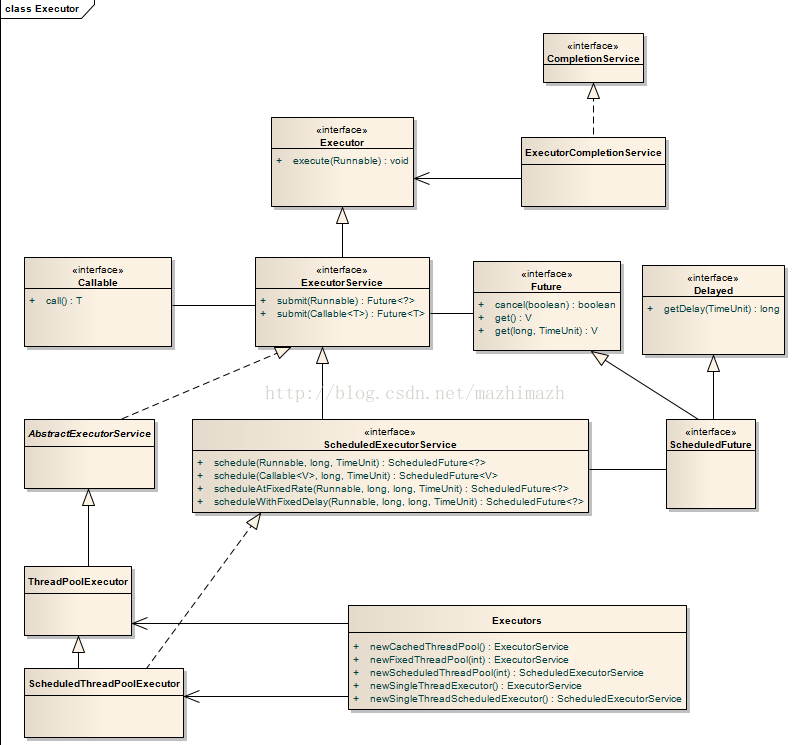
三、Executors
newFixedThreadPool(固定大小线程池)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
newCachedThreadPool(无界线程池,可以进行自动线程回收)
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
newSingleThreadExecutor(单个后台线程)
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
newScheduledThreadPool
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
四、ExecutorService任务周期管理接口
public interface ExecutorService extends Executor {
void shutdown();
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
// 省略部分方法
}
submit() 与execute()区别
1、接收的参数不一样
submit()可以接受runnable无返回值和callable有返回值
execute()接受runnable 无返回值
2、submit有返回值,而execute没有
Method submit extends base method Executor.execute by creating and returning a Future that can be used to cancel execution and/or wait for completion.
用到返回值的例子,比如说我有很多个做validation的task,我希望所有的task执行完,然后每个task告诉我它的执行结果,是成功还是失败,如果是失败,原因是什么。
3、submit方便Exception处理
There is a difference when looking at exception handling. If your tasks throws an exception and if it was submitted with execute this exception will go to the uncaught exception handler (when you don’t have provided one explicitly, the default one will just print the stack trace to System.err). If you submitted the task with submit any thrown exception, checked or not, is then part of the task’s return status. For a task that was submitted with submit and that terminates with an exception, the Future.get will rethrow this exception, wrapped in an ExecutionException.
意思就是如果你在你的task里会抛出checked或者unchecked exception,而你又希望外面的调用者能够感知这些exception并做出及时的处理,那么就需要用到submit,通过捕获Future.get抛出的异常。
public class ExecutorServiceTest { public static void main(String[] args) { ExecutorService executorService = Executors.newCachedThreadPool(); List<Future<String>> resultList = new ArrayList<Future<String>>(); // 创建10个任务并执行 for (int i = 0; i < 10; i++) { // 使用ExecutorService执行Callable类型的任务,并将结果保存在future变量中 Future<String> future = executorService.submit(new TaskWithResult(i)); // 将任务执行结果存储到List中 resultList.add(future); } executorService.shutdown(); // 遍历任务的结果 for (Future<String> fs : resultList) { try { System.out.println(fs.get()); // 打印各个线程(任务)执行的结果 } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } finally {
executorService.shutdownNow();
} } } } class TaskWithResult implements Callable<String> { private int id; public TaskWithResult(int id) { this.id = id; } /** * 任务的具体过程,一旦任务传给ExecutorService的submit方法,则该方法自动在一个线程上执行。 * * @return * @throws Exception */ public String call() throws Exception { System.out.println("call()方法被自动调用,干活!!! " + Thread.currentThread().getName()); if (new Random().nextBoolean()) throw new TaskException("Meet error in task." + Thread.currentThread().getName()); // 一个模拟耗时的操作 for (int i = 999999999; i > 0; i--) ; return "call()方法被自动调用,任务的结果是:" + id + " " + Thread.currentThread().getName(); } } class TaskException extends Exception { public TaskException(String message) { super(message); } }
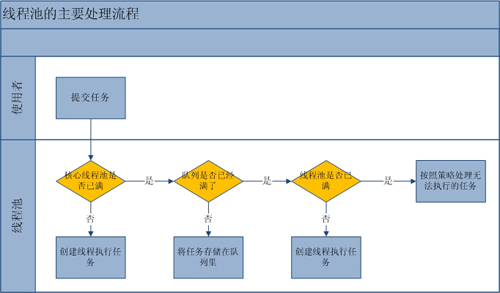
五、ThreadPoolExecutor提交任务流程
1. private final BlockingQueue<Runnable> workQueue; // 阻塞队列
2. private final ReentrantLock mainLock = new ReentrantLock(); // 互斥锁
3. private final HashSet<Worker> workers = new HashSet<Worker>();// 线程集合.一个Worker对应一个线程
4. private final Condition termination = mainLock.newCondition();// 终止条件
5. private int largestPoolSize; // 线程池中线程数量曾经达到过的最大值。
6. private long completedTaskCount; // 已完成任务数量
7. private volatile ThreadFactory threadFactory; // ThreadFactory对象,用于创建线程。
8. private volatile RejectedExecutionHandler handler;// 拒绝策略的处理句柄
9. private volatile long keepAliveTime; // 线程池维护线程所允许的空闲时间
10. private volatile boolean allowCoreThreadTimeOut;
11. private volatile int corePoolSize; // 线程池维护线程的最小数量,哪怕是空闲的
12. private volatile int maximumPoolSize; // 线程池维护的最大线程数量
1、 corePoolSize与maximumPoolSize
- 如果当前线程池中的线程数目<corePoolSize,则每来一个任务,就会创建一个线程去执行这个任务;
- 如果当前线程池中的线程数目>=corePoolSize,则每来一个任务,会尝试将其添加到任务缓存队列当中,若添加成功,则该任务会等待空闲线程将其取出去执行;当队列满时才创建新线程去处理请求;
- 如果当前线程池中的线程数目达到maximumPoolSize,即队列已经满了,则通过handler所指定的任务拒绝策略来处理新请求;
- 如果线程池中的线程数量大于corePoolSize时,并且某线程空闲时间超过keepAliveTime,线程将被终止,直至线程池中的线程数目不大于corePoolSize;
- 1. 核心线程corePoolSize > 任务队列workQueue > 最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务。
- 2. 当池中的线程数大于corePoolSize的时候,多余的线程会等待keepAliveTime长的时间,如果无请求可处理就自行销毁。
2、 workQueue
3、ThreadFactory
public interface ThreadFactory { Thread newThread(Runnable r); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号