
selenium在scrapy中的应用
1
引入
- 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
今日详情
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
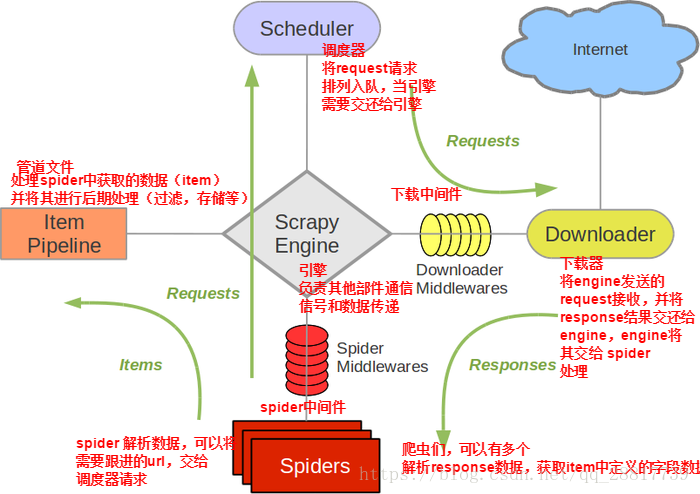
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.例子
在爬虫文件中
import scrapy from aip import AipNlp ''' 使用流程: 1.在爬虫文件中实例化一个浏览器对象 2.重写爬虫类父类一方法closed,在刚方法中关闭浏览器对象 3.在下载中间件中process_response中: a:获取爬虫文件中实例化好的浏览器对象 b:指定浏览器自动化的行为动作 c:实例化了一个新的响应对象,并且将浏览器获取的页面源码数据加载到了该对象中 d:返回这个新的响应对象 ''' from selenium import webdriver from wangyiNewsPro.items import WangyinewsproItem class WangyiSpider(scrapy.Spider): #百度AI APP_ID = '14790912' API_KEY = 'db9r8XomfKdhuWphvzWeWGCV' SECRET_KEY = 'gpROMOFW6v26WHzhYk2s7TuE2oYs1Il8' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) name = 'wangyi' # allowed_domains = ['www.xx.com'] start_urls = ['https://news.163.com/'] news_urls = [] #存储四个板块的url def __init__(self): #实例化一个浏览器对象 self.bro = webdriver.Chrome(executable_path=r'C:\Users\Administrator\Desktop\爬虫+数据\day04\chromedriver.exe') def closed(self,spider): self.bro.quit() def parse(self, response): #获取指定板块的连接(国内,国际,军事,航空) li_list = response.xpath('//div[@class="ns_area list"]/ul/li') indexs = [3,4,6,7] new_li_list = [] #四大板块 for index in indexs: new_li_list.append(li_list[index]) #将四大板块对应的li标签进行解析(详情页的超链接) for li in new_li_list: #四个板块对应的url new_url= li.xpath('./a/@href').extract_first() self.news_urls.append(new_url) yield scrapy.Request(url=new_url,callback=self.parseNews) def parseNews(self,response): div_list = response.xpath('//div[@class="ndi_main"]/div') for div in div_list: item = WangyinewsproItem() item['title'] = div.xpath('./a/img/@alt').extract_first() item['img_url'] = div.xpath('./a/img/@src').extract_first() detail_url = div.xpath('./a/@href').extract_first() yield scrapy.Request(url=detail_url,callback=self.parseDetail,meta={'item':item}) def parseDetail(self,response): item = response.meta['item'] content = response.xpath('//div[@id="endText"]//text()').extract() item['content'] = ''.join(content).strip(' \n\t') #调用百度AI接口,提取文章的类型和关键字 keys = self.client.keyword(item['title'].replace(u'\xa0',u''),item['content']) key_list = [] for dic in keys['items']: key_list.append(dic['tag']) item['keys'] = ''.join(key_list) kinds = self.client.topic(item['title'].replace(u'\xa0',u''),item['content']) item['kind'] = kinds['item']['lv1_tag_list'][0]['tag'] yield item
在中间件中
from time import sleep from scrapy.http import HtmlResponse class WangyinewsproDownloaderMiddleware(object): def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): #指定拦截的响应 if request.url in spider.news_urls: #处理响应对象: url = request.url bro = spider.bro #获取了在爬虫文件中创建好的浏览器对象 bro.get(url=url) sleep(2) js = 'window.scrollTo(0,document.body.scrollHeight)' bro.execute_script(js) sleep(1) bro.execute_script(js) sleep(1) bro.execute_script(js) sleep(1) a = bro.find_elements_by_xpath('/html/body/div/div[3]/div[4]/div[1]/div/div/a') if len(a) != 0: a[0].click() sleep(2) #我们需求中需要的数据源(携带了动态加载出来新闻数据的页面源码数据) page_text = bro.page_source #创建一个新的响应对象并且将上述获取的数据源加载到该响应对象中,然后响应对象返回 return HtmlResponse(url=bro.current_url,body=page_text,encoding='gb2312',request=request) return response
在管道文件中
import pymysql class WangyinewsproPipeline(object): conn = None cursor = None def open_spider(self,spider): self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='',db='spider') print(self.conn) def process_item(self, item, spider): print(item) self.cursor = self.conn.cursor() sql = 'insert into news values("%s","%s","%s","%s","%s")'%(item['title'],item['content'],item['img_url'],item['keys'],item['kind']) print(sql) try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() return item def close_spider(self,spider): self.cursor.close() self.conn.close()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号