python数据分析学习(5)pandas描述性统计的概述与计算
pandas对象有一个常用数学,统计学方法的集合。大部分属于归纳或汇总统计。这些方法从DataFrame的行或列中抽取一个Series或一系列的值。
pandas的描述性统计的方法和NumPy的方法相比,内建了处理缺失值的功能,很好地针对于每一个我们需要处理的数据。
一:一些基本方法
1.归约方法
sum方法返回一个包含列上加和的Series。 若传入axis = 'columns'或axis = 1,将会把一行上各个列的值相加。会把缺失值自动排除,可以通过skipna = False设置禁用skipna来实现不排除缺失值。
可用idxmin和idxmax,返回间接统计信息,比如最小值或最大值的索引值。
2.积累型方法
有些方法是积累型方法,比如cumsum是返回积累值。
3.其他方法
还有一些不是归约方法和积累型的方法,比如describe方法,一次性产生多个汇总统计值。
二:相关性和协方差
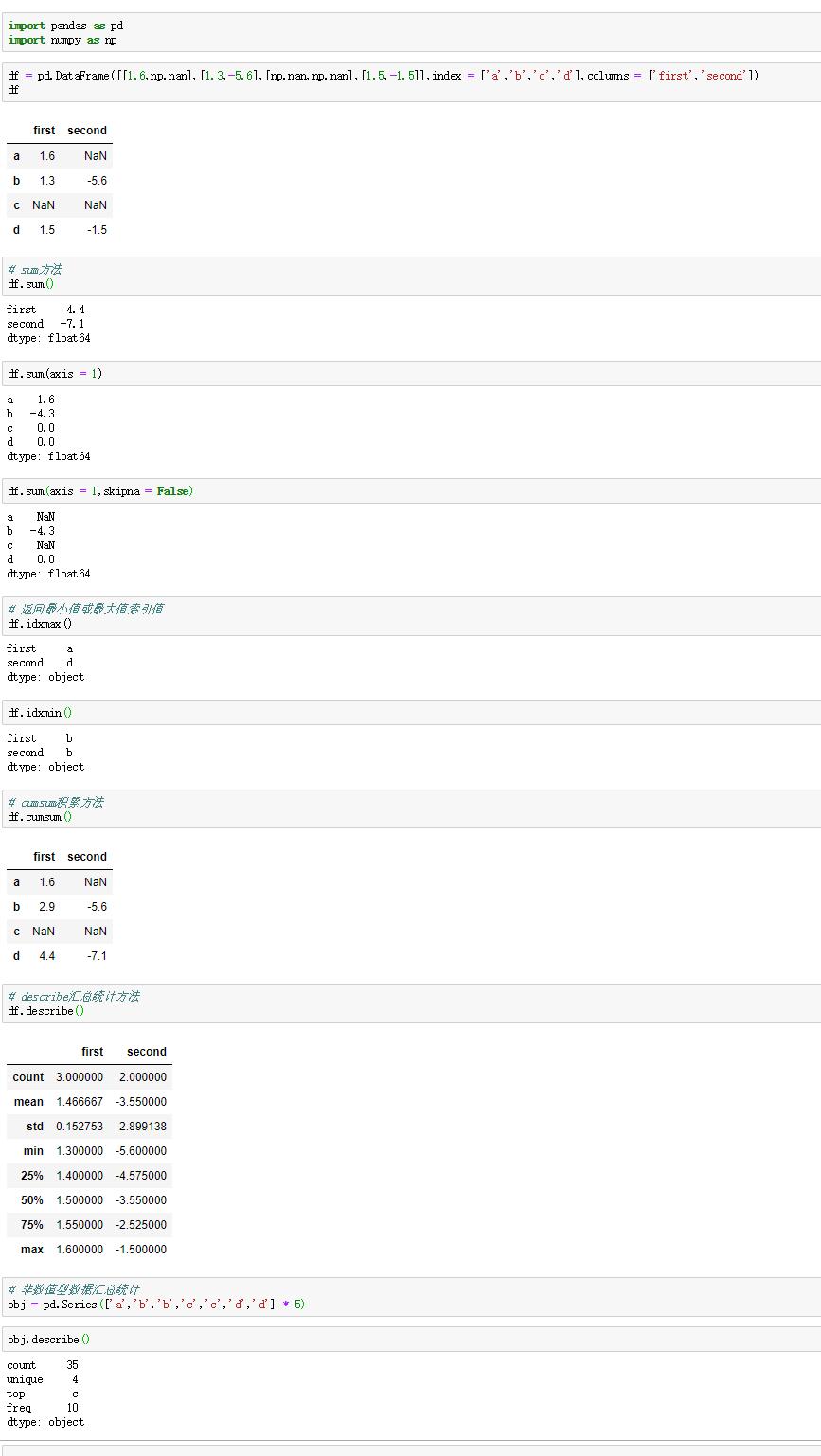
一些汇总统计,是由多个参数计算出的。与之相关的是一个附加库,是 pandas-datareader ,可以从Yahoo!Finance上获取股价和交易量的二维DataFrame数据。
用pct_change和tail获得股价的百分比。
函数corr方法是计算两个对象重叠的,非NA的,按索引对其的值的相关性。相应地,cov计算的是协方差。
用DataFrame的corrwith方法,可以计算出DataFrame中的行或列与另一个序列或DataFrame的相关性。 这个方法是一个归约方法 ,传入axis = 'columns'或者axis = 1则会对逐行进行操作。
三:唯一值,计数和成员属性
有些方法可以从数据中提取信息,如下:
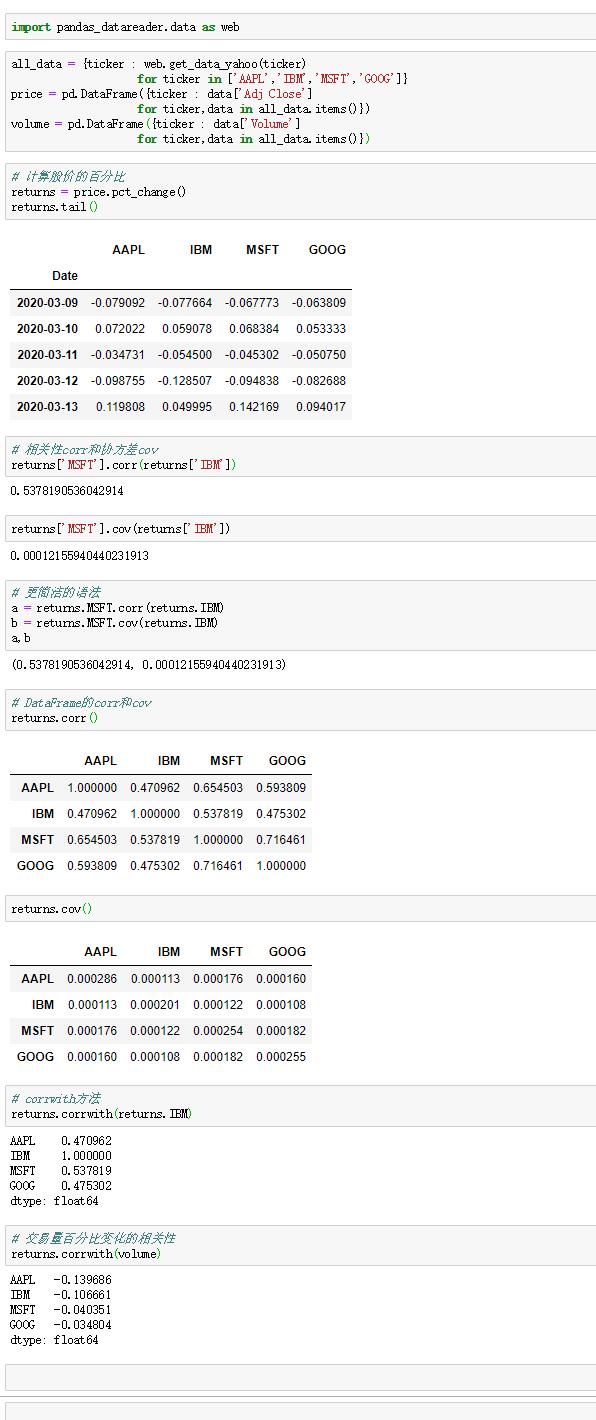
函数unique会给出唯一值,可以用uniques.sort()进行排序。
函数value_counts会计算数据中包含值的个数,默认会按照数量降序排列,可以通过设置sort = False不进行降序排列。
函数isin可以检查数据成员是否和参数匹配,并进行过滤,即去除未匹配的数据。
而与之相关的Index.get_indexer方法,可以提供一个索引数组,将可能非唯一数组转换为另一个唯一值数组。
函数pandas.value_counts可以计算DataFrame多个相关列的直方图,得到的直方图的行标签是所有列出现的不同值,数值是不同值在每个列中出现的次数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号