
CH-12 Flink CEP
CH12 Flink CEP
12.1 基本概念
CEP:复杂事件处理(Complex Event Processing)
复杂事件处理就是在事件流里,检测以特定顺序先后发生的一组事件,进行统计或报警提示,比如“连续登录失败”,或者“订单支付超时”等。
总结起来,复杂事件处理的流程可以分成三个步骤:
- 定义一个匹配规则。
- 将匹配规则应用到事件流上,检测满足规则的复杂事件。
- 对检测到的复杂事件进行处理,得到结果进行输出。
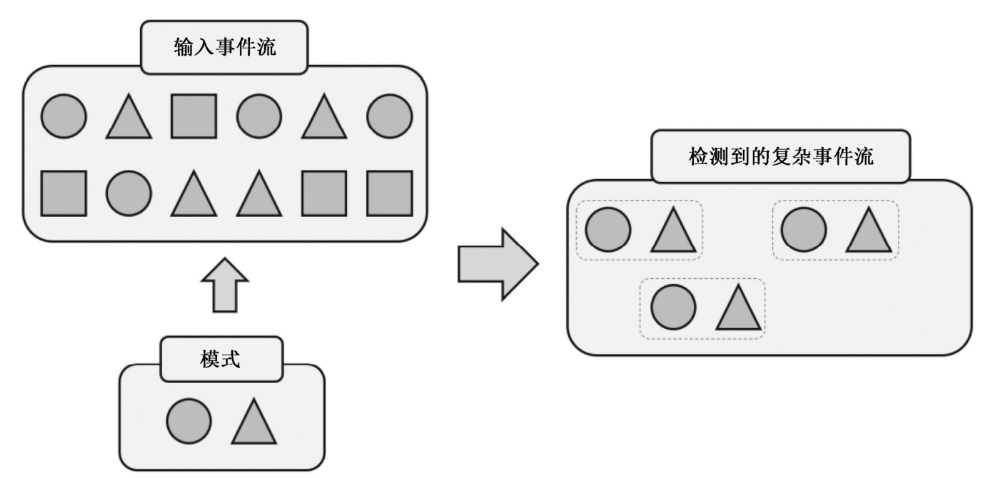
下图流中元素是不同形状的图形,定义匹配规则:圆形后面紧跟着三角形。匹配到三组结果。它们构成了一个复杂事件流,流中的每组都包含了一个圆形和一个三角形。接下来就可以对复杂事件流进行处理,输出提示或报警信息。
12.2 快速入门
引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
案例
连续登录三次失败就输出告警
12.3 模式API
1. 个体模式
-
形式
val pattern = Pattern .begin[LoginEvent]("first") .where(_.eventType.equals("fail")) .next("second") .where(_.eventType.equals("fail")) .next("third") .where(_.eventType.equals("fail"))其中的
.begin[LoginEvent]("first") .where(_.eventType.equals("fail"))就是一个简单事件,事件是模式的最小组成单位,
个体模式:以
连接词开始,如begin、next等,之后传入String参数作为名字,比如这里的first、second。还需要传入过滤条件,指定匹配规则,一般用where()实现 -
多次匹配
默认情况下,个体模式只匹配一次,但是可以为其添加量词,变成循环模式,匹配接收多个事件。
常见量词
-
oneOrMore匹配一次或多次
-
times(times)匹配特定次数,例如a.times(3)表示aaa。
-
times(fromTimes, toTimes)指定匹配次数范围,最小次数为
fromTimes,最大次数为toTimes。例如a.times(2,4)可以匹配aa,aaa和aaaa。
-
greedy贪心模式,尽可能多的匹配。
-
optional使当前模式成为可选的,可以满足这个匹配条件,也可以不满足。
案例
// 出现2~4次,并且尽可能多地匹配 pattern.times(2, 4).greedy // 出现2~4次,或者不出现 pattern.times(2, 4).optional // 出现2~4次, 或者不出现, 并且尽可能多地匹配 pattern.times(2, 4).optional.greedy // 出现1次或多次,并且尽可能多地匹配 pattern.oneOrMore.greedy // 出现1次或多次, 或者不出现, 并且尽可能多地匹配 pattern.oneOrMore.optional.greedy -
-
条件
主要通过调用Pattern对象的
where()方法来定义条件,分为简单条件、迭代条件、组合条件、终止条件几种类型。-
限定子类型
pattern.subtype(classOf[SubEvent])只有当事件是SubEvent类型时,才可以满足当前pattern的匹配条件。
-
简单条件
.where(_.eventType.equals("fail"))通过where传入简单条件
-
迭代条件
简单条件只能基于当前事件做判断。实际应用中,有时需要将当前事件跟之前事件做对比。这种依靠之前事件做判断的条件,就叫作迭代条件。
向where传入
IterativeCondition抽象类,这个类中有一个filter()方法,两个参数:当前事件上下文Context。通过Context就可以拿到之前匹配到的数据。也可以通过Context获取时间相关的信息,比如事件的时间戳和当前处理时间。 -
组合条件
将多个简单条件连接起来,使用
where()或or()// 相当于timestamp=1000L OR (timestamp=2000L AND timestamp=3000L) val pattern = Pattern .begin[LoginEvent]("first") .where(_.timestamp.equals(1000L)) .or(_.timestamp.equals(3000L)) .where(_.timestamp.equals(2000L)) // 相当于(timestamp=1000L AND timestamp=2000L) OR timestamp=3000L val pattern = Pattern .begin[LoginEvent]("first") .where(_.timestamp.equals(1000L)) .where(_.timestamp.equals(2000L)) .or(_.timestamp.equals(3000L)) -
终止条件
对于循环模式,可以指定
终止条件,表示遇到某个事件时就不再继续匹配。until()同样传入一个IterativeCondition作为参数。
需要注意,终止条件只能与oneOrMore或oneOrMore.optional结合使用。
-
2.组合模式
将个体模式按一定的顺序连接起来,就组成了一个完整的复杂事件匹配规则。即组合模式,为了与个体模式区分,有时也叫作模式序列。
-
初始模式
Pattern.begin[LoginEvent]("first")两个泛型参数:
- 检测事件的基本类型Event,与begin指定的类型一致
- 当前模式里事件的子类型,由子类型限制条件指定
-
连接条件
-
严格近邻(Strict Contiguity)
.next()下一个必须匹配上
-
宽松近邻(Relaxed Contiguity)
.followedBy()宽松近邻只关心事件发生的顺序,匹配事件之间可以有不匹配事件。
-
非确定性宽松近邻(Non-Deterministic Relaxed Contiguity)
非确定性指可以重复使用之前已经匹配过的事件。这种近邻条件下匹配到的不同复杂事件,可以以同一个事件作为开始。
举例说明
比如匹配规则是A后面接B,数据流如下
ABCADB宽松紧邻
A B C A D B [A B] [A B]非确定性宽松近邻
A B C A D B [A B] [A B] [A B] -
-
其他限制条件
还可以用否定的“连接词”来组合个体模式。主要包括以下两种:
-
notNext()
前一个模式匹配到的事件后面,不能紧跟某个事件
-
notFollowedBy()
前一个模式匹配到的事件后面,不会出现某种事件。
需要注意,由于notFollowedBy()是没有严格限定的;流数据不停到来,我们永远不能保证之后“不会出现某种事件”。所以模式序列不能以
notFollowedBy()结尾,这个限定条件主要用来表示“两个事件中间不会出现某种事件”。 -
.within()为模式指定时间限制,多次调用会以最小的时间间隔为准。
Pattern .begin[LoginEvent]("first") .where(_.eventType.equals("fail")) .within(Duration.ofSeconds(10))
-
-
循环模式中的近邻条件
在循环模式中,近邻关系同样有三种:
严格近邻、宽松近邻以及非确定性宽松近邻。对于定义了量词(如oneOrMore、times())的循环模式,默认采用宽松近邻。-
consecutive()严格近邻,保证匹配事件是严格连续的。
val pattern = Pattern .begin[LoginEvent]("failEvent") .where(_.eventType.equals("fail")) .times(3) .consecutive() -
allowCombinations()非确定性宽松近邻,可以重复使用已经匹配的事件。
-
3.模式组
对模式序列进行二次组合
val start = Pattern.begin(
Pattern.begin[LoginEvent]("first")
.where(_.timestamp.equals(1000L))
)
val strict = start.next(
Pattern.begin[LoginEvent]("first")
.where(_.timestamp.equals(1000L))
).times(2)
4. 匹配后的跳过策略
精准控制匹配策略
比如有如下输入
aaab
为区分前后不同的a事件,记作
a1, a2, a3, b
模式如下
Pattern.begin[Event]("a").where(_.user.equals("a")).oneOrMore
.followedBy("b").where(_.user.equals("b"))
匹配结果如下
a1,a2,a3,b
a1,a2,b
a1,b
a2,a3,b
a2,b
a3,b
-
noSkip默认策略,所有匹配结果都会输出
输出结果:
a1,a2,a3,b a1,a2,b a1,b a2,a3,b a2,b a3,b -
skipToNexta1匹配完成后,跳过a1开始的所有其他匹配,从a2开始匹配,a2也跳过
a1,a2,a3,b a2,a3,b a3,b -
skipPastLastEventa1匹配完成后,跳过所有
a开头的子匹配a1,a2,a3,b -
skipToFirst传入一个参数,指明跳至哪个模式的第一个匹配事件。
AfterMatchSkipStrategy.skipToFirst("a")这里传入a,意思是每次匹配完成后,跳到第一个a
(即a1)为开始的匹配,相当于只留下a1开始的匹配。a1,a2,a3,b a1,a2,b a1,b -
skipToLast传入一个参数,指明跳至哪个模式的第一个匹配事件。
AfterMatchSkipStrategy.skipToLast("a")这里传入a,意思是每次匹配完成后,跳到最后一个a
(即a3)为开始的匹配a1,a2,a3,b a3,b
12.4 模式的检测处理
1.将模式应用到流上
CEP.pattern(stream, pattern)
CEP.pattern(stream, pattern, comparator)
支持DataStream和KeyedDataStream,
支持传入comparator对数据进行排序,默认使用时间戳排序
2.处理匹配事件
选择操作使用 PatternSelectFunction
处理操作使用 PatternProcessFunction。
-
PatternSelectFunction之前使用过
val patternStream = CEP.pattern(loginEventStream, pattern) patternStream .select(new PatternSelectFunction[LoginEvent, String] { override def select(matches: util.Map[String, util.List[LoginEvent]]): String = { val failEvent = matches.get("failEvent") val first = failEvent.get(0) val second = failEvent.get(1) s"$first ,$second" } }) .print() -
PatternFlatSelectFunction和上一个功能基本相同,需要实现
flatSelect(),与之前select()的区别在于没有返回值,而是多了一个收集器out,通过调用out.collet()实现多次输出数据。val patternStream = CEP.pattern(loginEventStream, pattern) patternStream .flatSelect(new PatternFlatSelectFunction[LoginEvent, String] { override def flatSelect(matches: util.Map[String, util.List[LoginEvent]], out: Collector[String]): Unit = { val failEvent = matches.get("failEvent") val first = failEvent.get(0) val second = failEvent.get(1) out.collect(first.toString) out.collect(second.toString) } }) .print() -
PatternProcessFunction和前两个相比,可以访问上下文,进行更多操作,可以完全覆盖其他接口,是目前官方推荐的处理方式。事实上,
PatternSelectFunction和PatternFlatSelectFunction在CEP内部执行时会被转换成PatternProcessFunction。需要实现
processMatch(),这个方法和flatSelect()类似,只是多了一个上下文参数。通过上下文可以获取时间信息,比如事件的时间戳或者处理时间,还可以调用output()将数据输出到侧输出流。val patternStream = CEP.pattern(loginEventStream, pattern) patternStream .process(new PatternProcessFunction[LoginEvent, String] { override def processMatch(matched: util.Map[String, util.List[LoginEvent]], ctx: PatternProcessFunction.Context, out: Collector[String]): Unit = { } }) .print()
3.处理超时事件
当我们用.within()指定模式检测的时间间隔,超出时间检测就应该失败了。然而这种超时失败跟真正的匹配失败不同,它其实是一种部分成功匹配。因为已经正确匹配了开始的部分数据,只是没有等到后续的匹配事件。所以往往不应该直接丢弃,而是要输出一个提示或报警信息。
Flink CEP提供了一个捕捉超时的部分匹配事件的接口,叫作TimedOutPartialMatchHandler。这个接口需要实现processTimedOutMatch(),
参数1:将超时的、已检测到的部分匹配事件
参数2:PatternProcessFunction的上下文Context。所以这个接口必须与PatternProcessFunction结合使用,对处理结果的输出则需要利用侧输出流来进行。
class MyPatternProcessFunction extends PatternProcessFunction[Event, String] with TimedOutPartialMatchHandler[Event] {
override def processMatch(matches: util.Map[String, util.List[Event]], ctx: PatternProcessFunction.Context, out: Collector[String]): Unit = {
// 正常匹配事件的处理
}
override def processTimedOutMatch(matches: util.Map[String, util.List[Event]], ctx: PatternProcessFunction.Context): Unit = {
// 处理部分匹配数据
val event = matches.get("start").get(0)
val outputTag = new OutputTag[Event]("time-out")
ctx.output(outputTag, event)
}
}
案例:对用户订单流进行监控,对超过15分钟未支付的订单输出提醒
4.处理迟到数据
对于乱序流,Flink CEP使用通过水位线延迟处理乱序数据的做法。当事件到来时,并不会立即做检测匹配处理,而是先放入缓冲区。数据按照时间戳由小到大排序;水位线到来时,将缓冲区中所有时间戳小于水位线的事件取出,进行检测匹配。这里水位线的延迟时间,也就是事件在缓冲区等待的最大时间。
但是即便如此,还是会有迟到数据,即水位线早已超过它的时间戳,这时可以使用侧输出流输出迟到数据
val laterTag = new OutputTag[OrderEvent]("later")
val payedStream = CEP.pattern(orderStream, pattern)
.sideOutputLateData(laterTag)
.process(new MyPatternProcessFunction)
payedStream.getSideOutput(laterTag)
12.5 CEP的状态机实现
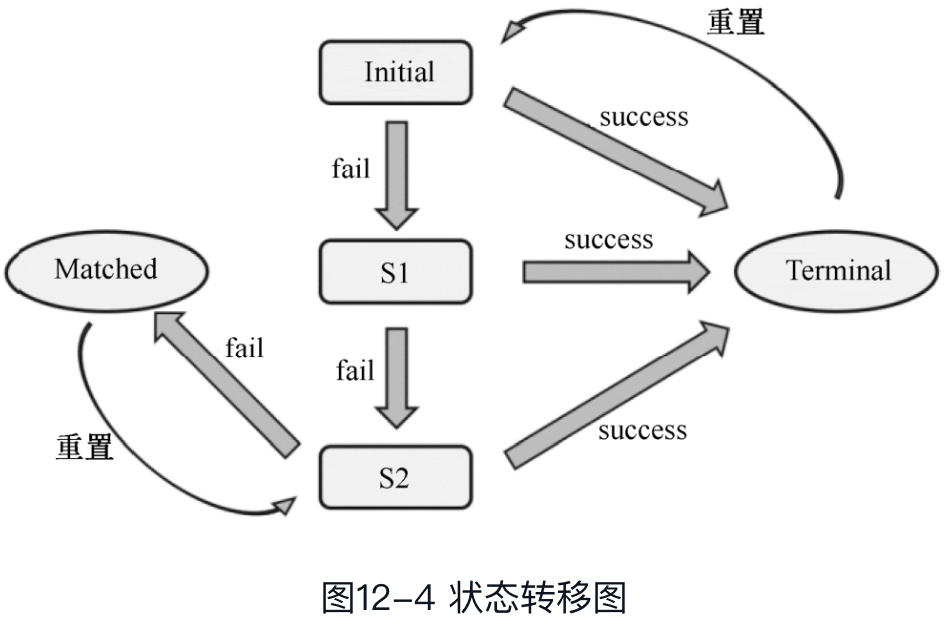
CEP的底层就是一个状态机,我们以之前的连续三次登录fail为例说明,
开始状态为Initial,登录失败一次状态变为s1,失败两次为s2,失败三次为matched,输出结果,同时将当前状态置为s2,等待下次检测。
中间任意一个状态匹配到success,状态就变为terminal,同时将状态重置为Initial

 浙公网安备 33010602011771号
浙公网安备 33010602011771号