


Map结构学习
1.map的基本概念
1.Map概述 (1)Map 是一种把键对象和值对象映射的集合, 它的每一个元素都包含一对键对象和值对象。 (2)Map没有继承于Collection接口 从Map集合中检索元素时, 只要给出键对象,就会返回对应的值对象。 (3)Map是接口。 2.Map的具体实现类 (1)HashMap: Map基于散列表的实现。 插入和查询“键值对”的开销是固定的。 可以通过构造器设置容量capacity和负载因子load factor, 以调整容器的性能。 (2)LinkedHashMap 类似于HashMap,但是迭代遍历它时,取得“键值对”的顺序是其插入次序,
或者是最近最少使用(LRU)的次序。只比HashMap慢一点。
而在迭代访问时发而更快,因为它使用链表维护内部次序。
(3)TreeMap:
底层是二叉树数据结构,线程不同步,可用于给Map集合中的键进行排序。
(4)HashTable:
HashMap是Hashtable的轻量级实现,非线程安全的实现他们都实现了map接口,
主要区别是HashMap键值可以为空null,效率可以高于Hashtable。
(5)ConcurrentHashMap:
ConcurrentHashMap通常只被看做并发效率更高的Map,
用来替换其他线程安全的Map容器,比如Hashtable和Collections.synchronizedMap。
(6)WeakHashMap
弱键(weak key)Map,Map中使用的对象也被允许释放:
这是为解决特殊问题设计的。如果没有map之外的引用指向某个“键”,则此“键”可以被垃圾收集器回收。
(7)IdentifyHashMap
使用==代替equals()对“键”作比较的hash map
(8)ArrayMap
ArrayMap是一个映射的数据结构,它设计上更多的是考虑内存的优化,内部是使用两个数组进行数据存储,
void putAll(Map t): 将来自特定映像的所有元素添加给该映像
void clear():从映像中删除所有映射
这里以最常用的HashMap为例
Iterator> entries = hashMap.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry entry = entries.next();
Integer key=entry.getKey();
String value=entry.getValue();
}
键找值遍历:
for (Integer key : hashMap.keySet()) {
String value = hashMap.get(key);
}
keySet迭代器遍历:
Iterator iterator=hashMap.keySet().iterator();
while (iterator.hasNext()) {
Integer key=iterator.next();
String value=hashMap.get(key);
}
2.HashMap源码分析
1.HashMap简介 HashMap基于哈希表的Map接口实现,是以key-value存储形式存在。 (除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。) HashMap 的实现不是同步的,这意味着它不是线程安全的。 它的key、value都可以为null。此外,HashMap中的映射不是有序的。 在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成, 新增了红黑树作为底层数据结构,结构变得复杂了,但是效率也变的更高效。 2.HashMap数据结构 在 JDK1.8 中,HashMap 是由 数组+链表+红黑树构成, 新增了红黑树作为底层数据结构,结构变得复杂了,但是效率也变的更高效。 当一个值中要存储到Map的时候会根据Key的值来计算出他的
hash,通过哈希来确认到数组的位置,如果发生哈希碰撞就以链表的形式存储
在Object源码分析中解释过,但是这样如果链表过长来的话,HashMap会把这个链表转换成红黑树来存储。
如下图:HashMap的存储结构
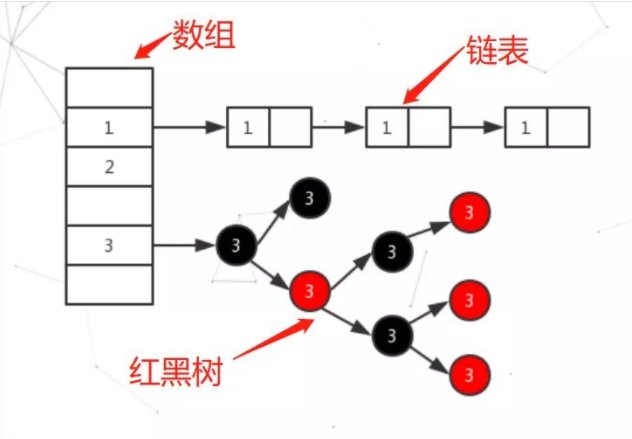
3.使用红黑树存储的好处
因为Map中桶的元素初始化是链表保存的,其查找性能是O(n),而树结构能将查找性能提升到O(log(n))。
当链表长度很小的时候,即使遍历,速度也非常快,但是当链表长度不断变长,
肯定会对查询性能有一定的影响,所以才需要转成树。
至于为什么阈值是8,我想,去源码中找寻答案应该是最可靠的途径。
参考地址:https://dwz.cn/nPFXmXwJ
4.类结构
图:
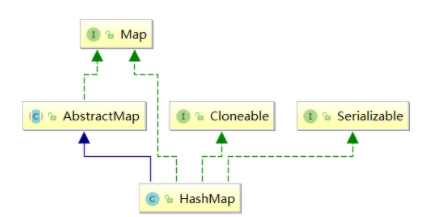
说明:
Cloneable 空接口,表示可以克隆
Serializable 序列化
AbstractMap 提供Map实现接口
问题:
HashMap已经继承了AbstractMap而AbstractMap类实现了Map接口,
那为什么HashMap还要在实现Map接口呢?同样在ArrayList中LinkedList中都是这种结构
原因:
据java集合框架的创始人Josh Bloch描述,这样的写法是一个失误。
在java集合框架中,类似这样的写法很多,最开始写java集合框架的时候,
他认为这样写,在某些地方可能是有价值的,直到他意识到错了。
显然的,JDK的维护者,后来不认为这个小小的失误值得去修改,所以就这样存在下来了。
5.属性
初始化容量(必须是二的n次幂)

集合最大容量(必须是二的幂)

负载因子,默认的0.75

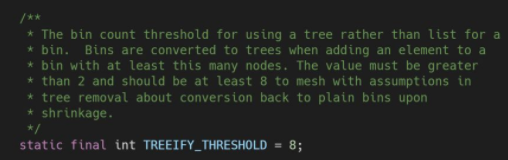
当链表的值超过8则会转红黑树(1.8新增)
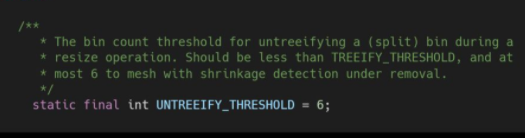
当链表的值小于6则会从红黑树转回链表
当Map里面的数量超过这个值时,表中的桶才能进行树形化 ,
否则桶内元素太多时会扩容,而不是树形化 为了避免进行扩容、
树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
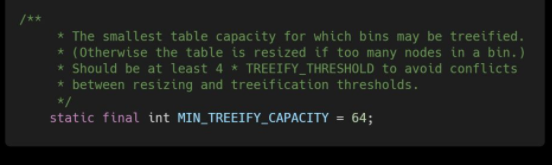
table用来初始化(必须是二的n次幂)
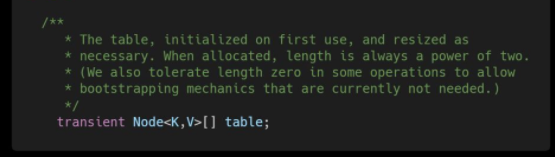
用来存放缓存

HashMap中存储的数量

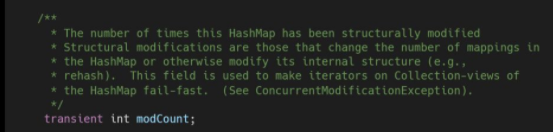
用来记录HashMap的修改次数
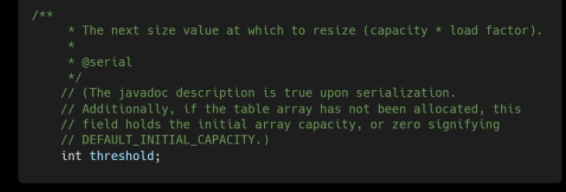
用来调整大小下一个容量的值计算方式为(容量*负载因子)
哈希表的加载因子
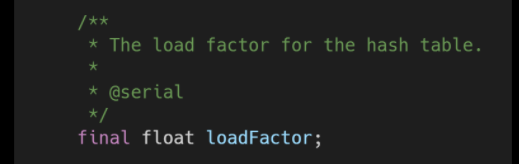
重点属性:
(1)table在JDK1.8中我们了解到HashMap是由数组加链表加红黑树来组成的结构其中table就是HashMap中的数组
(2)size为HashMap中K-V的实时数量
(3)loadFactor加载因子,是用来衡量 HashMap 满的程度,计算HashMap的实时加载因子的方法为:size/capacity,
而不是占用桶的数量去除以capacity。capacity 是桶的数量,也就是 table 的长度length。
(4)threshold计算公式:capacity * loadFactor。这个值是当前已占用数组长度的最大值。
过这个数目就重新resize(扩容),扩容后的 HashMap 容量是之前容量的两倍
6.构造方法
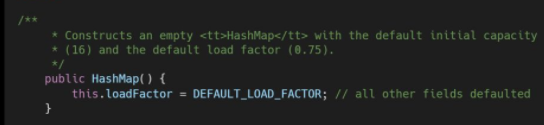
1.构造一个空的 HashMap,默认初始容量(16)和默认负载因子(0.75)
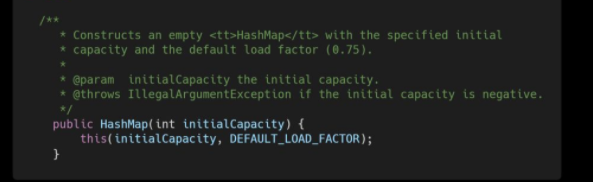
构造方法有: HashMap,HashMap(int initialCapacity),HashMap(int initialCapacity, float loadFactor)

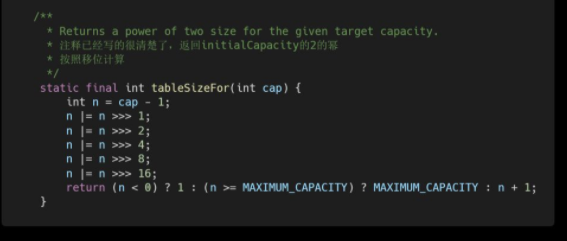
tableSizeFor实现
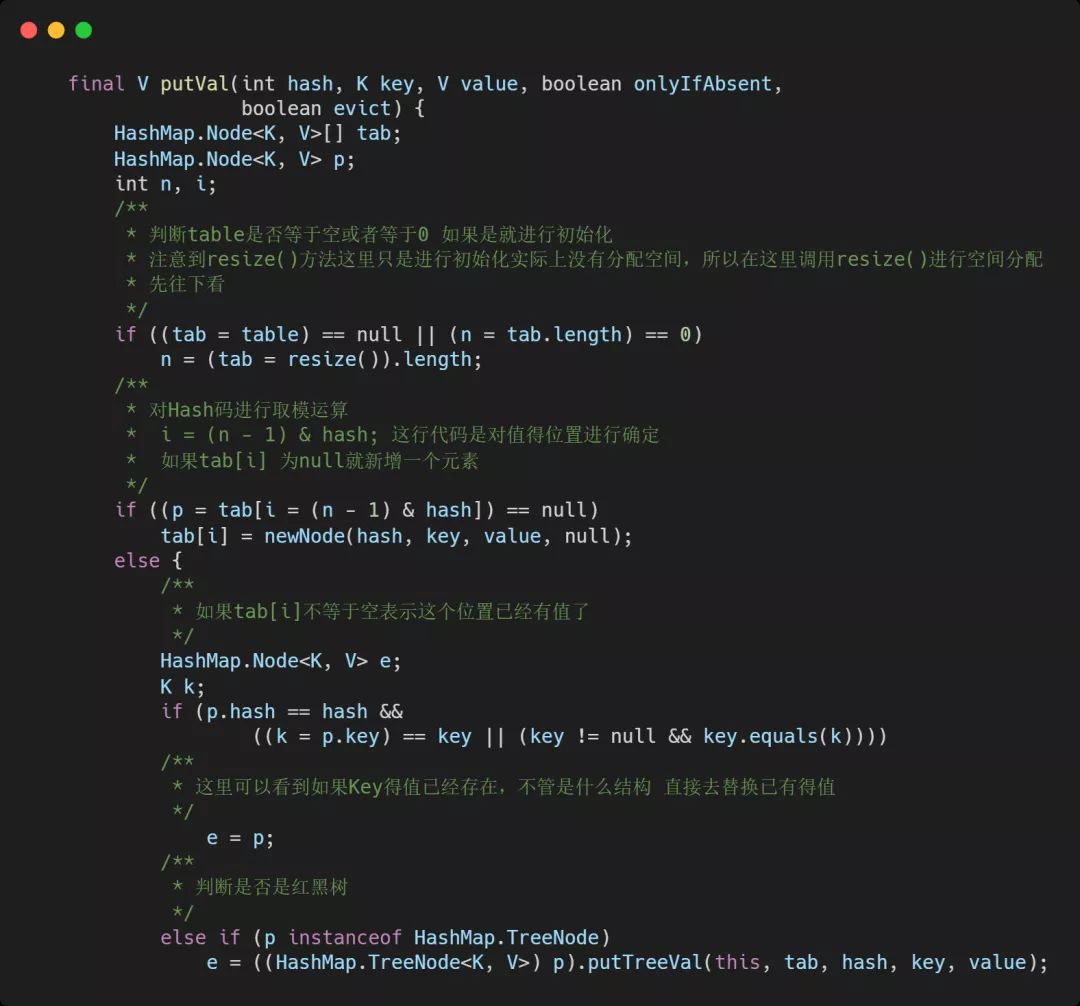
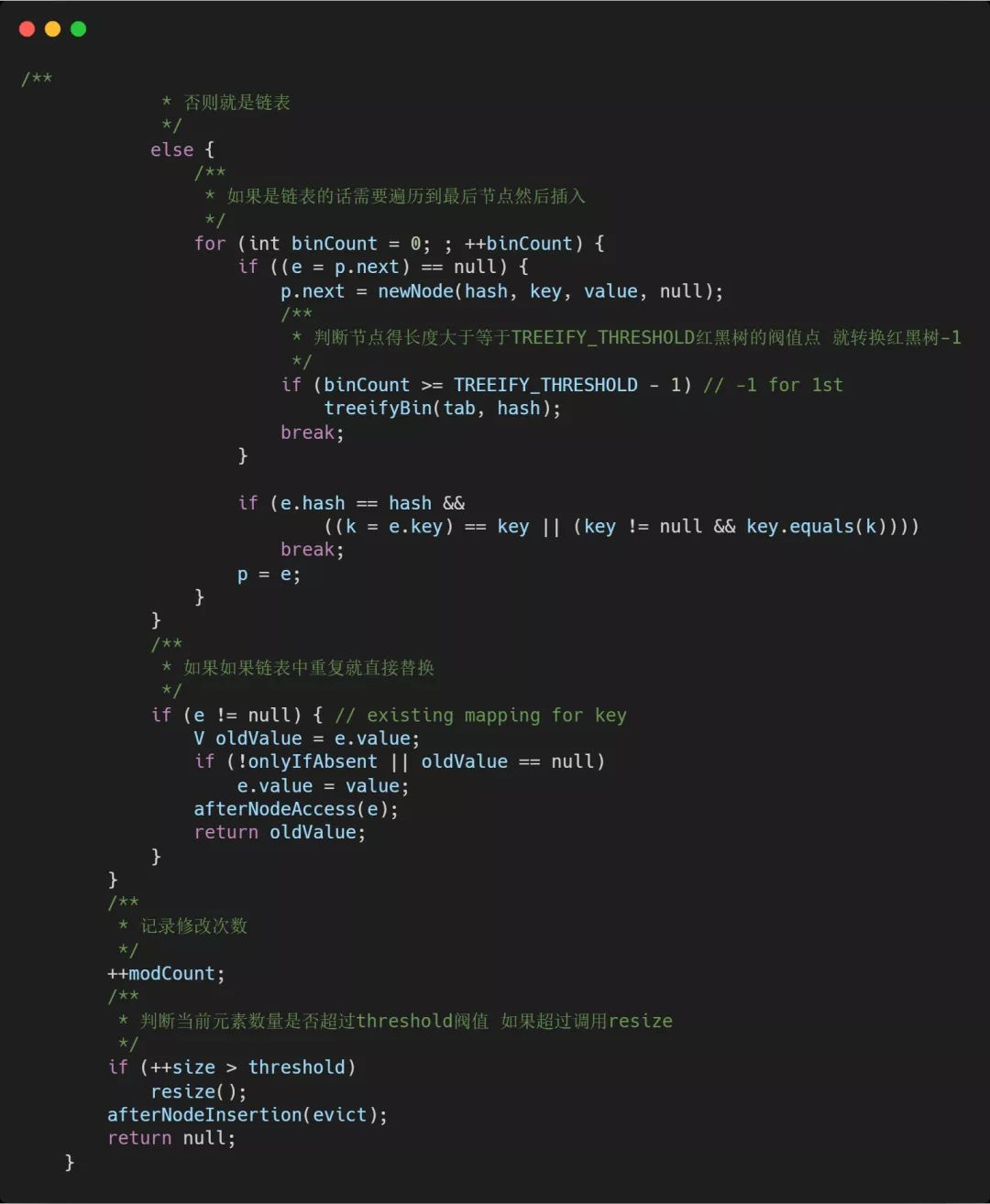
2.添加(put方法)

可以看到put调用的是putVal来进行数据插入,但是要注意到key在这里执行了一下hash方法,来看一下Hash方法是如何实现的。

总结:从上面可以得知HashMap是支持Key为空的,
而HashTable是直接用过Key来获取HashCode所以key为空会抛异常其实
上面就已经解释了为什么HashMap的长度为什么要是2的幂因为HashMap 使用的方法很巧妙,
它通过 hash & (table.length -1)来得到该对象的保存位,
前面说过 HashMap 底层数组的长度总是2的n次方,这是HashMap在速度上的优化。
当 length 总是2的n次方时,hash & (length-1)运算等价于对 length 取模,
也就是 hash%length,但是&比%具有更高的效率。比如 n % 32 = n & (32 -1)。
主要参数:
hash key的hash值
key 原始Key
value 要存放的值
onlyIfAbsent 如果true代表不更改现有的值
evict 如果为false表示table为创建状态
源码片段:
学习来源:
//Java 数据结构之 Map 学习总结
https://www.jianshu.com/p/97981f54271d
//HashMap源码分析
https://www.sohu.com/a/327165642_753508
//哈希表(散列表)原理详解


 浙公网安备 33010602011771号
浙公网安备 33010602011771号