多元线性回归—波士顿房价预测(改进版本)
版本二:可视化训练过程中的损失值
修改版本一中训练过程代码(只增加了第1行、第13行代码):
1 loss_list = [] #用于保存loss的列表 2 for epoch in range (train_epochs): 3 loss_sum = 0.0 4 for xs, ys in zip(x_data,y_data): # 每次各取一行数据(一维) 5 xs = xs.reshape(1,12) # feed数据必须和placeholder的shape一致 6 ys = ys.reshape(1,1) 7 _, loss = sess.run([optimizer,loss_function],feed_dict={x: xs, y: ys}) #下划线表示只接收但之后并不会去用,返回值对我们没有用 8 loss_sum= loss_sum + loss 9 xvalues,yvalues = shuffle(x_data,y_data) #每训练一轮(506个数据),打乱数据顺序 10 b0temp = b.eval(session=sess) 11 wOtemp = w.eval(session=sess) 12 loss_average =loss_sum/len(y_data) 13 loss_list.append(loss_average) #每轮训练后添加一个这一轮的loss平均值 14 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",wOtemp)
可视化损失值
plt.plot(loss_list)
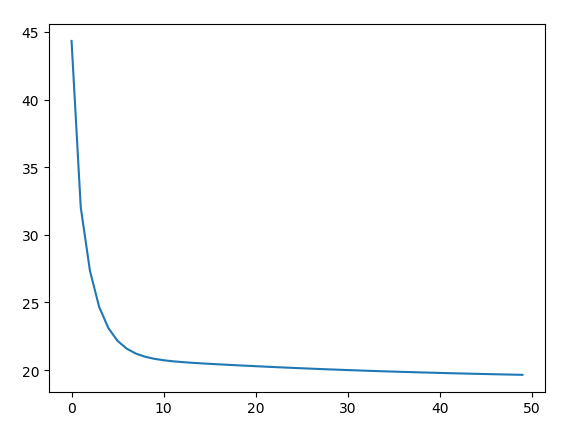
Note:观察该图像,可以再增加几轮训练轮次,比如把50轮 ->100轮 -> 200轮
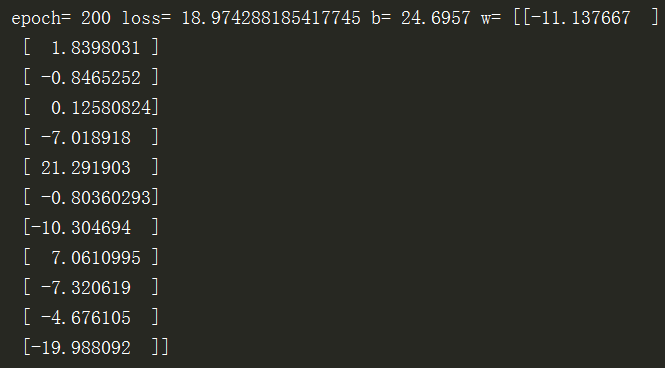
当迭代轮数增加到200轮时,运行结果为:
仍选取版本一测试时取的第348位置,其结果为:
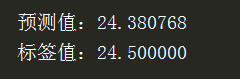
结果要好于版本一的预测结果~~(但需要注意的是训练结果好不代表泛化能力好,容易导致过拟合)
完整代码为:


import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.utils import shuffle #打乱样本 # pd.set_option('display.max_columns',1000) # pd.set_option('display.width',1000) # pd.set_option('display.max_colwidth',1000) df = pd.read_csv("data/boston.csv", header=0) # print(df.describe()) #线束数据摘要描述信息(数量、平均值、标准值、最大最小值等) df = df.values #获取df的值 df = np.array(df) #把df转换为np的数组格式 # print(df) #对特证数据【0-11】列归一化 for i in range(12): df[:,i]=df[:,i]/(df[:,i].max() - df[:,i].min()) x_data = df[:,:12] #xdata为归一化后的前12列特征数据 y_data = df[:,12] #ydata 为最后1列标签数据 # print(x_data,'\n shape=',x_data.shape) # print(y_data,'\n shape=',y_data.shape) x = tf.placeholder(tf.float32,[None,12],name ="X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name ="Y") #1个标签数据(1列) #定义了一个命名空间,对以下语句的节点打包在一起,使计算图看上去更简洁 with tf.name_scope("Model"): # w 初始化值为shape=(12,1)的随机数,标准差为0.01 w = tf.Variable(tf.random_normal([12,1],stddev=0.01),name="W") b = tf.Variable(1.0, name="b") # b 初始化值为1.0 def model(x, w, b): # w 和 b 四矩阵相乘,用matmul,不能用mutiply或者* return tf.matmul(x,w) + b pred = model(x, w, b) #预测计算操作,前向计算节点 train_epochs = 200 #迭代次数(训练轮数) learning_rate = 0.01 #学习率,设置为经验值。 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y-pred,2)) #均方误差 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #创建优化器 sess = tf.Session() init = tf.global_variables_initializer() sess.run(init) loss_list = [] #用于保存loss的列表 for epoch in range (train_epochs): loss_sum = 0.0 for xs, ys in zip(x_data,y_data): # 每次各取一行数据(一维) xs = xs.reshape(1,12) # feed数据必须和placeholder的shape一致 ys = ys.reshape(1,1) _, loss = sess.run([optimizer,loss_function],feed_dict={x: xs, y: ys}) #下划线表示只接收但之后并不会去用,返回值对我们没有用 loss_sum= loss_sum + loss xvalues,yvalues = shuffle(x_data,y_data) #每训练一轮(506个数据),打乱数据顺序 b0temp = b.eval(session=sess) wOtemp = w.eval(session=sess) loss_average =loss_sum/len(y_data) loss_list.append(loss_average) #每轮训练后添加一个这一轮的loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",wOtemp) plt.plot(loss_list) plt.show() n=348 #指定一条来看看效果 # n=np.random.randint(506) #随机确定一条来看看效果 # print(n) x_test = x_data[n] x_test = x_test.reshape(1,12) predict = sess.run(pred, feed_dict={x:x_test}) print("预测值:%f" % predict) target = y_data[n] print("标签值:%f" % target)
版本三:加上TensorBoard可视化代码
修改部分代码
3.1声明会话
sess = tf.Session()
init = tf.global_variables_initializer()
3.2为TensorBoard可视化准备数据
logdir = 'F:/log' #设置日志存储目录
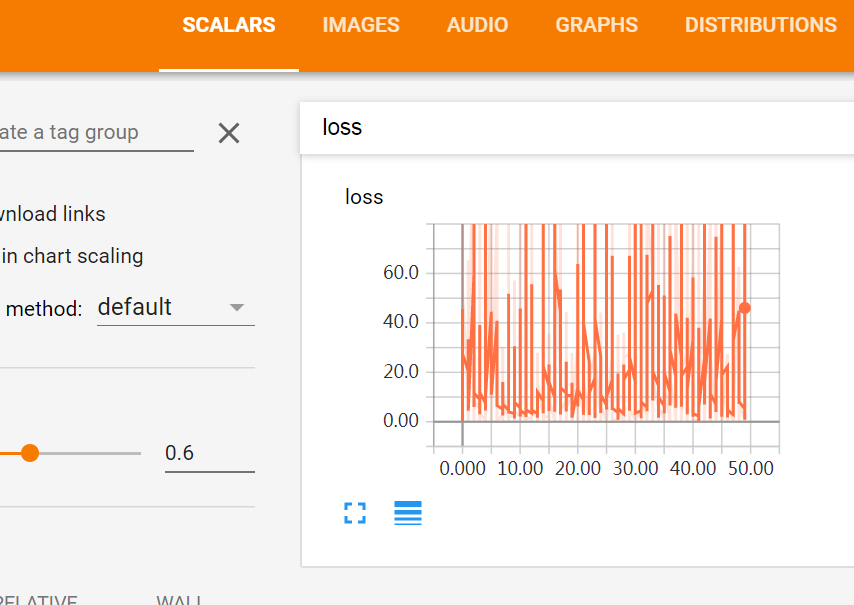
sum_loss_op = tf.summary.scalar('loss', loss_function) #创建一个操作,记录损失值loss,后面在TensorBoard中SCALARS栏可见
merged = tf.summary.merge_all() #把所有需要记录摘要日志文件的合并,方便一次性写入
3.3启动会话
sess.run(init)
3.4创建摘要的文件写入器(FileWriter)
writer = tf.summary.FileWriter(logdir, sess.graph) #创建摘要writer,将计算图写入摘要文件,后面在TensorBoard中GRAPHS栏可见
3.5训练过程修改
1 for epoch in range (train_epochs): 2 loss_sum = 0.0 3 for xs, ys in zip(x_data,y_data): # 每次各取一行数据(一维) 4 xs = xs.reshape(1,12) # feed数据必须和placeholder的shape一致 5 ys = ys.reshape(1,1) 6 _,summary_str ,loss = sess.run([optimizer,sum_loss_op,loss_function],feed_dict={x: xs, y: ys}) 7 writer.add_summary(summary_str, epoch) 8 loss_sum= loss_sum + loss 9 xvalues,yvalues = shuffle(x_data,y_data) #每训练一轮(506个数据),打乱数据顺序 10 b0temp = b.eval(session=sess) 11 wOtemp = w.eval(session=sess) 12 loss_average =loss_sum/len(y_data) 13 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",wOtemp)
比版本一代码修改了第6-7行
完整代码为:
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.utils import shuffle #打乱样本 # pd.set_option('display.max_columns',1000) # pd.set_option('display.width',1000) # pd.set_option('display.max_colwidth',1000) df = pd.read_csv("data/boston.csv", header=0) # print(df.describe()) #线束数据摘要描述信息(数量、平均值、标准值、最大最小值等) df = df.values #获取df的值 df = np.array(df) #把df转换为np的数组格式 # print(df) #对特证数据【0-11】列归一化 for i in range(12): df[:,i]=df[:,i]/(df[:,i].max() - df[:,i].min()) x_data = df[:,:12] #xdata为归一化后的前12列特征数据 y_data = df[:,12] #ydata 为最后1列标签数据 # print(x_data,'\n shape=',x_data.shape) # print(y_data,'\n shape=',y_data.shape) x = tf.placeholder(tf.float32,[None,12],name ="X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name ="Y") #1个标签数据(1列) #定义了一个命名空间,对以下语句的节点打包在一起,使计算图看上去更简洁 with tf.name_scope("Model"): # w 初始化值为shape=(12,1)的随机数,标准差为0.01 w = tf.Variable(tf.random_normal([12,1],stddev=0.01),name="W") b = tf.Variable(1.0, name="b") # b 初始化值为1.0 def model(x, w, b): # w 和 b 四矩阵相乘,用matmul,不能用mutiply或者* return tf.matmul(x,w) + b pred = model(x, w, b) #预测计算操作,前向计算节点 train_epochs = 50 #迭代次数(训练轮数) learning_rate = 0.01 #学习率,设置为经验值。 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y-pred,2)) #均方误差 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #创建优化器 sess = tf.Session() init = tf.global_variables_initializer() logdir = 'F:/log' #设置日志存储目录 sum_loss_op = tf.summary.scalar('loss', loss_function) #创建一个操作,记录损失值loss,后面在TensorBoard中SCALARS栏可见 merged = tf.summary.merge_all() #把所有需要记录摘要日志文件的合并,方便一次性写入 sess.run(init) #启动会话 writer = tf.summary.FileWriter(logdir, sess.graph) #创建摘要writer,将计算图写入摘要文件,后面在TensorBoard中GRAPHS栏可见 # loss_list = [] #用于保存loss的列表 for epoch in range (train_epochs): loss_sum = 0.0 for xs, ys in zip(x_data,y_data): # 每次各取一行数据(一维) xs = xs.reshape(1,12) # feed数据必须和placeholder的shape一致 ys = ys.reshape(1,1) _,summary_str ,loss = sess.run([optimizer,sum_loss_op,loss_function],feed_dict={x: xs, y: ys}) writer.add_summary(summary_str, epoch) loss_sum= loss_sum + loss xvalues,yvalues = shuffle(x_data,y_data) #每训练一轮(506个数据),打乱数据顺序 b0temp = b.eval(session=sess) wOtemp = w.eval(session=sess) loss_average =loss_sum/len(y_data) # loss_list.append(loss_average) #每轮训练后添加一个这一轮的loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",wOtemp) sess.close()
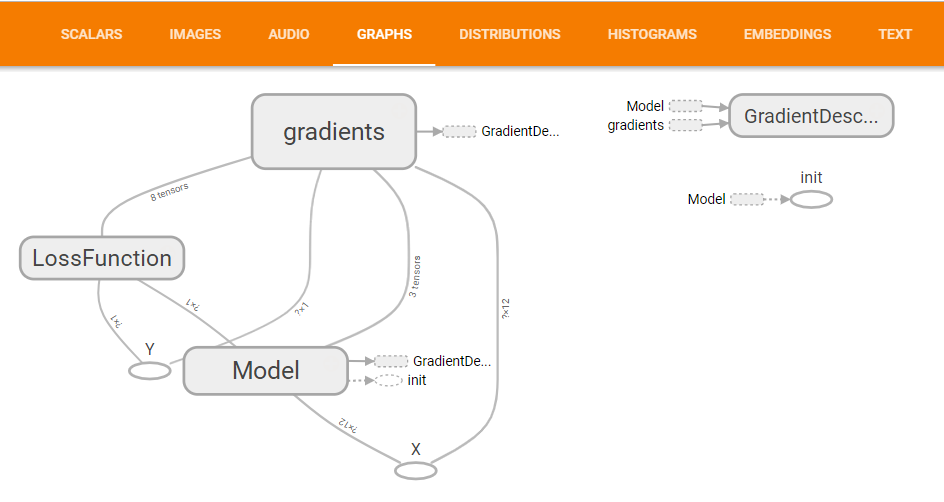
运行后,可以在TensorBoard中查看SCALARS和GRAPHS,具体方法见“TensorFlow可视化初步”https://www.cnblogs.com/HuangYJ/p/11623507.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号