爬虫第六次作业
作业①:
(1)DoubanMoviesTop250
-
要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
-
候选网站:豆瓣电影:https://movie.douban.com/top250
-
输出信息:
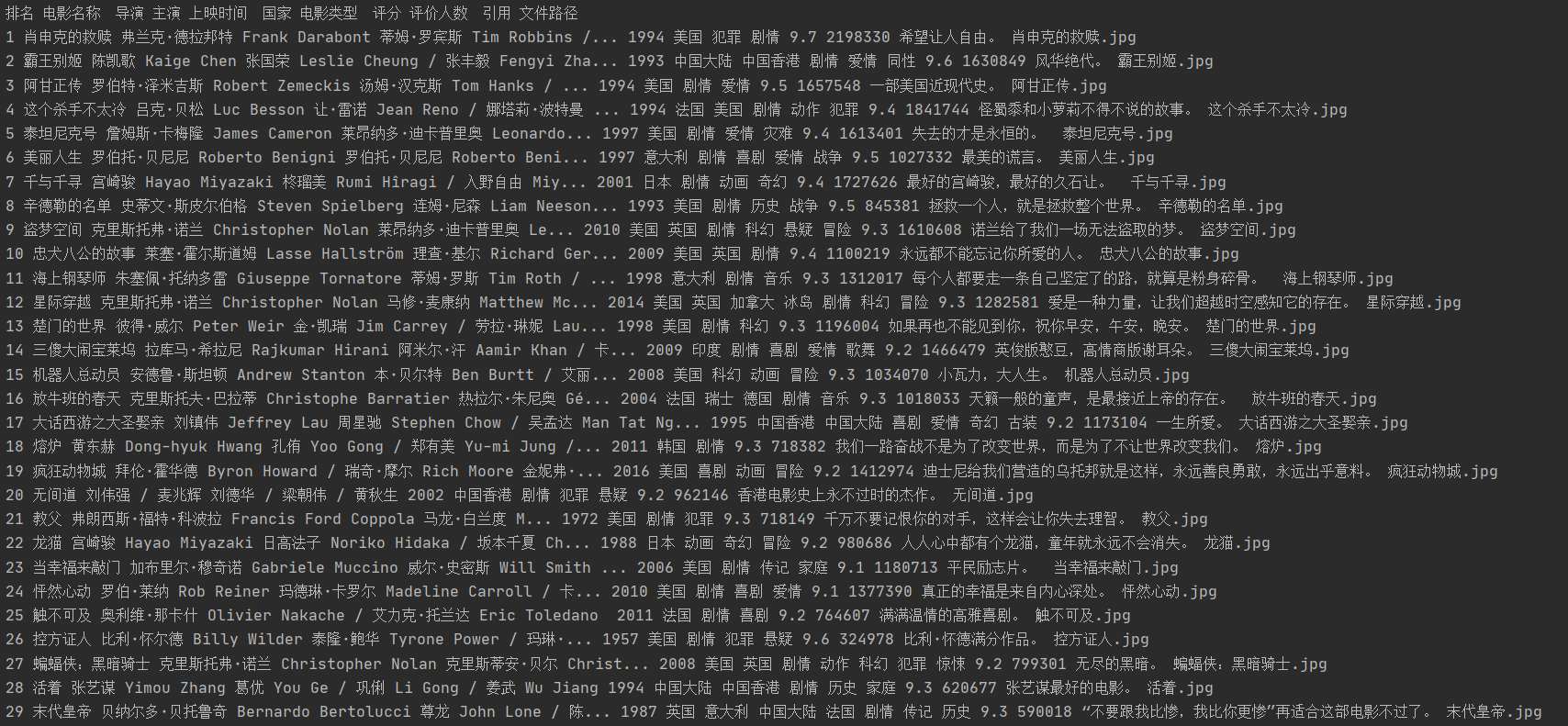
排名 电影名称 导演 主演 上映时间 国家 电影类型 评分 评价人数 引用 文件路径 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 1994 美国 犯罪 剧情 9.7 2192734 希望让人自由。 肖申克的救赎.jpg 2......
代码
import re
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def download(url, name):
try:
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req,timeout=100)
data = data.read()
# 将下载的图像文件写入本地文件夹
fobj = open("C:\\Users\\lxc's girlfriend\\Desktop\\images\\" + name,"wb")
fobj.write(data)
fobj.close()
except Exception as err:
print(err)
def MySpider(start_url):
global headers
global threads
try:
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ol[class='grid_view'] li")
lines = []
urls = []
for li in lis:
# 获取需要爬取的信息
try:
rank = li.select("div[class='pic'] em")[0].text
except:
rank = ""
try:
name = li.select("span[class='title']")[0].text
except:
name = ""
try:
info = li.select("div[class='bd'] p")[0].text
except:
info = ""
lines = info.split("\n") # 分行
try:
directors = re.compile(r"导演: .*\s\s\s").findall(lines[1])[0].strip()[4:]
except:
directors = lines[1].strip()[4:]
try:
stars = re.compile(r"主演: .*").findall(lines[1])[0][4:]
except:
stars = ""
try:
year = re.compile(r"[0-9]+").findall(lines[2])
years = "、".join(year)
except:
years = ""
try:
countries = re.compile(r"[\s\u4e00-\u9fa5]+").findall(lines[2])[-2].strip()
except:
countries = ""
try:
types = re.compile(r"[\s\u4e00-\u9fa5]+").findall(lines[2])[-1].strip()
except:
types = ""
try:
rating_num = li.select("span[class='rating_num']")[0].text
except:
rating_num = ""
try:
rating_people = li.select("div[class='star'] span")[3].text
rating_people = re.compile(r"[0-9]+").findall(rating_people)[0]
except:
rating_people = ""
try:
qoute = li.select("span[class='inq']")[0].text
except:
qoute = ""
try:
src = li.select("img")[0]["src"]
except:
src = ""
# 多线程爬取电影封面
url = urllib.request.urljoin(start_url, src)
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
image = name + ext
if url not in urls:
urls.append(url)
T = threading.Thread(target=download, args=(url, image))
T.setDaemon(False)
T.start()
threads.append(T)
print(rank, name , directors, stars, years, countries, types, rating_num, rating_people, qoute, image)
except Exception as err:
print(err)
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"}
threads = []
print("排名\t电影名称\t导演\t主演\t上映时间\t国家\t电影类型\t评分\t评价人数\t引用\t文件路径")
# 翻页
for i in range(0, 251, 25):
url = "https://movie.douban.com/top250?start=" + str(i) + "&filter="
MySpider(url)
for t in threads:
t.join()
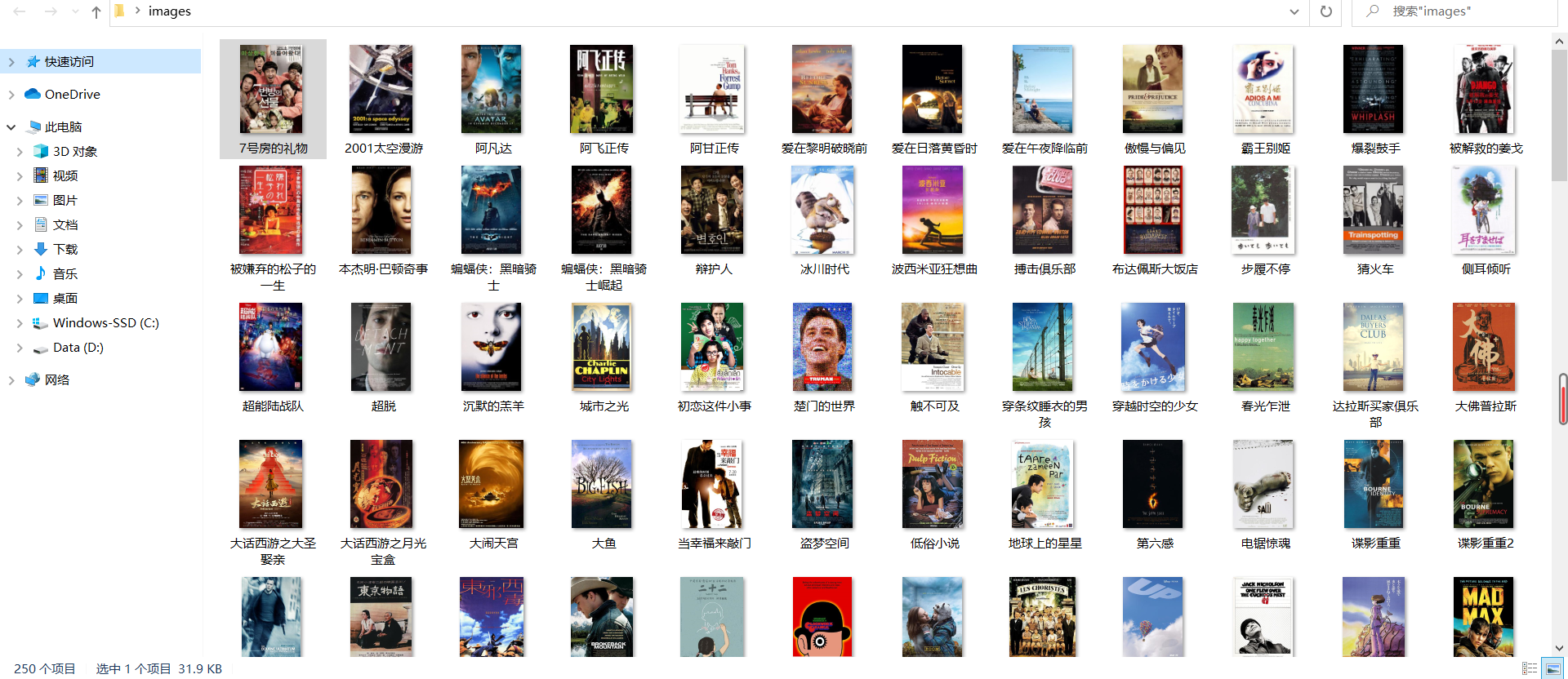
运行结果
(2)心得体会
本次实验重点在灵活运用正则表达式,整体来说不算太难。
作业②:
(1)UniversitiesRanking实验
-
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下

代码
items.py
import scrapy
class UniversityItem(scrapy.Item):
rank = scrapy.Field()
name = scrapy.Field()
province = scrapy.Field()
official_url = scrapy.Field()
intro = scrapy.Field()
src = scrapy.Field()
pass
pipelines.py
import pymysql
import urllib.request
import threading
class UniversityPipeline:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"}
srcs = []
threads = []
# 连接数据库
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
try:
# 如果有表就删除
self.cursor.execute("drop table university")
except:
pass
try:
# 建立新的表
sql = "create table university (Srank varchar(32), Sname varchar(256) primary key, Sprovince varchar(256), Sofficial_url varchar(256), Sintro varchar(1024), Slogo varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
self.opened = False
# 关闭数据库
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def download(self, url, name):
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
# 将下载的图像文件写入本地文件夹
fobj = open("C:\\Users\\lxc's girlfriend\\Desktop\\images\\" + name, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + name)
except Exception as err:
print(err)
def process_item(self, item, spider):
try:
no = item["rank"]
src = item["src"]
# 下载学校logo
while len(no) < 3:
no = "0" + no
if (src[len(src) - 4] == "."):
ext = src[len(src) - 4:]
else:
ext = ""
logo = item["name"] + ext
if src not in self.srcs:
self.srcs.append(src)
T = threading.Thread(target=self.download, args=(src, logo))
T.setDaemon(False)
T.start()
self.threads.append(T)
print(item["rank"], item["name"], item["province"], item["official_url"], logo)
# 将数据插入数据库的表中
if self.opened:
self.cursor.execute("insert into university (Srank, Sname, Sprovince, Sofficial_url, Sintro, Slogo) values (%s, %s, %s, %s, %s, %s)",
(no, item["name"], item["province"], item["official_url"], item["intro"], logo))
except Exception as err:
print(err)
return item
for t in threads:
t.join()
settings.py
BOT_NAME = 'university'
SPIDER_MODULES = ['university.spiders']
NEWSPIDER_MODULE = 'university.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'university.pipelines.UniversityPipeline': 300,
}
mySpider.py
import scrapy
from ..items import UniversityItem
class MySpider(scrapy.Spider):
name = "mySpider"
start_urls = ["https://www.shanghairanking.cn/rankings/bcur/2020"]
def parse_detail(self, response):
try:
item = response.meta['item'] # 接收上级已爬取的数据
# 爬取内页信息
official_url = response.xpath("//div[@class='univ-website']/a/text()").extract_first()
intro = response.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
src = response.xpath("//td[@class='univ-logo']/img/@src").extract_first()
item["official_url"] = official_url
item["intro"] = intro
item["src"] = src
yield item
except Exception as err:
print(err)
def parse(self, response):
try:
# 爬取基础信息
trs = response.xpath("//tbody/tr")
for tr in trs:
rank = tr.xpath("./td[position()=1]/text()").extract_first().strip()
name = tr.xpath("./td[position()=2]/a/text()").extract_first()
province = tr.xpath("./td[position()=3]/text()").extract_first().strip()
link = tr.xpath("./td[position()=2]/a/@href").extract_first()
item = UniversityItem()
item["rank"] = rank
item["name"] = name
item["province"] = province
# 进入下一级页面
url = "https://www.shanghairanking.cn/" + link
yield scrapy.Request(url, meta={'item': item}, callback=self.parse_detail)
except Exception as err:
print(err)
运行结果


(2)心得体会
本次实验重点在通过Scrapy实现多级爬取,meta={'item': item}能获取到上级所爬取到的信息,超方便!
作业③:
(1)MoocMyCourses实验
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
-
候选网站: 中国mooc网:https://www.icourse163.org
-
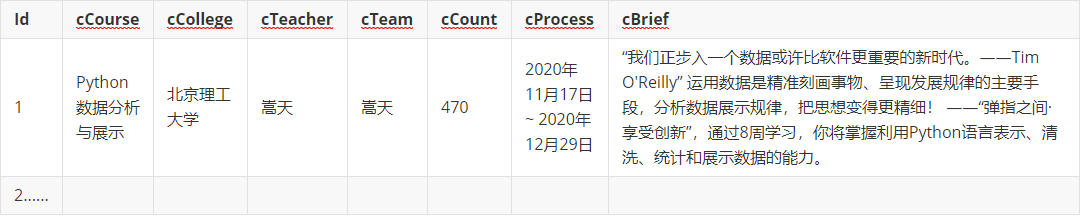
输出信息:MYSQL数据库存储和输出格式如下
代码
import pymysql
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ActionChains
import time
import re
import datetime
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
class mySpider:
def startUp(self, url):
# 初始化谷歌浏览器
chrome_options = Options()
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver.maximize_window()
self.driver.get(url)
# 初始化变量
self.No = 0
# 初始化数据库
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
try:
# 如果有表就删除
self.cursor.execute("drop table mycourses")
except:
pass
try:
# 建立新的表
sql = "create table mycourses (mNo varchar(256) primary key, mName varchar(256), mSchool varchar(256), mTeachers varchar(256), mCount varchar(256), mTerm varchar(256), mIntro varchar(1024))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
def closeUp(self):
try:
# 关闭数据库、断开与谷歌浏览器连接
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err)
def insertDB(self, no, name, school, teachers, count, term, intro):
try:
sql = "insert into mycourses (mNo, mName, mSchool, mTeachers, mCount, mTerm, mIntro) values (%s, %s, %s, %s, %s, %s, %s)"
self.cursor.execute(sql, (no, name, school, teachers, count, term, intro))
except Exception as err:
print(err)
def teacherJoin(self, result):
teachers = self.driver.find_elements_by_xpath("//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")
# 将老师添加到列表中
for teacher in teachers:
result.append(teacher.text)
# 划到下一页
try:
slider_next = self.driver.find_element_by_xpath("//span[@class='u-icon-arrow-right-thin f-ib f-pa']")
slider_next.click()
self.teacherJoin(result)
except:
pass
return result
def getData(self):
try:
name = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
except:
name = ""
try:
school = self.driver.find_element_by_class_name('u-img').get_attribute('alt')
except:
school = ""
try:
result = []
result = self.teacherJoin(result)
teachers = '、'.join(result) # 每个老师用'、'分隔开
except:
teachers = ""
try:
count = self.driver.find_element_by_class_name(
'course-enroll-info_course-enroll_price-enroll_enroll-count').text
count = re.compile(r"[0-9]*").findall(count)[3]
except:
count = ""
try:
term = self.driver.find_element_by_xpath(
"//div[@class='course-enroll-info_course-info_term-info_term-time']/span[position()=2]").text
except:
term = ""
try:
intro = self.driver.find_element_by_class_name('course-heading-intro_intro').text
except:
intro = ""
self.No += 1
no = str(self.No)
while len(no) < 4:
no = "0" + no
print(no, name, school, teachers, count)
self.insertDB(no, name, school, teachers, count, term, intro) # 将爬取到的数据写入数据库
def processSpider(self):
try:
# 点击 "登录 | 注册"
login_button = self.driver.find_element_by_class_name("_3uWA6")
login_button.click()
# 点击 "其他登录方式"
otherlogin = self.driver.find_element_by_class_name("ux-login-set-scan-code_ft_back")
otherlogin.click()
# 点击 "手机号登录"
login_with_tel = self.driver.find_element_by_xpath("//li[contains(text(), '手机号登录')]")
login_with_tel.click()
# 切换到登录的嵌套页面
temp_iframe = self.driver.find_elements_by_tag_name('iframe')[1]
self.driver.switch_to_frame(temp_iframe)
# 输入手机号和密码
telInput = self.driver.find_element_by_xpath("//input[@type='tel']")
telInput.send_keys('****')
passwordInput = self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']")
passwordInput.send_keys('****')
time.sleep(1)
# 点击 "登录"
submmit_button = self.driver.find_element_by_xpath("//a[@id='submitBtn']")
submmit_button.click()
# 点击头像进入我的课程页面
WebDriverWait(self.driver, 1000).until(EC.presence_of_element_located((By.CLASS_NAME, "_2EyS_")))
myCourses_button = self.driver.find_element_by_class_name("_2EyS_")
myCourses_button.click()
myCourses_handle = self.driver.current_window_handle # 获取我的课程页面窗口
divs = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']/div") # 定位我的课程列表
for div in divs:
# 鼠标移到课程图片右上角
hiddenArea = div.find_element_by_class_name("menu-btn-hover-area")
ActionChains(self.driver).move_to_element(hiddenArea).perform()
# 点击查看课程介绍
courseHomePage_button = div.find_element_by_xpath(".//div[@class='menu']/div[position()=1]/a")
courseHomePage_button.click()
# 将当前窗口切换为该课程信息窗口
handles = self.driver.window_handles
self.driver.switch_to_window(handles[1])
# 获取需要爬取的信息
self.getData()
# 关闭当前窗口并切回我的课程窗口
self.driver.close()
self.driver.switch_to_window(myCourses_handle)
except Exception as err:
print(err)
def executespider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds # 计算爬虫耗时
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/"
spider = mySpider()
while True:
print("1.爬取")
print("2.退出")
s = input("请选择(1,2):")
if s == "1":
spider.executespider(url) # 爬取我的课程信息
continue
elif s == "2":
break
运行结果
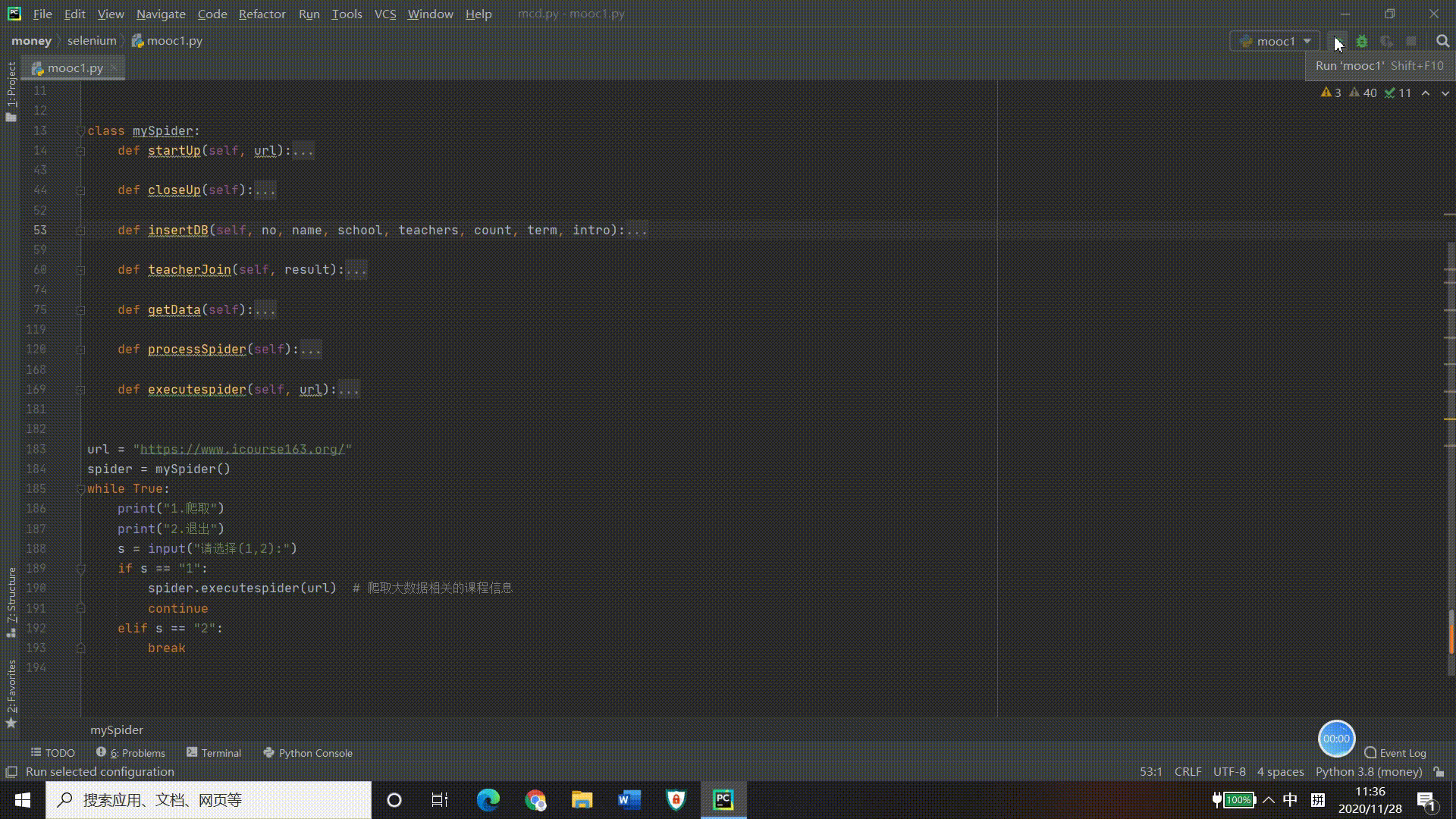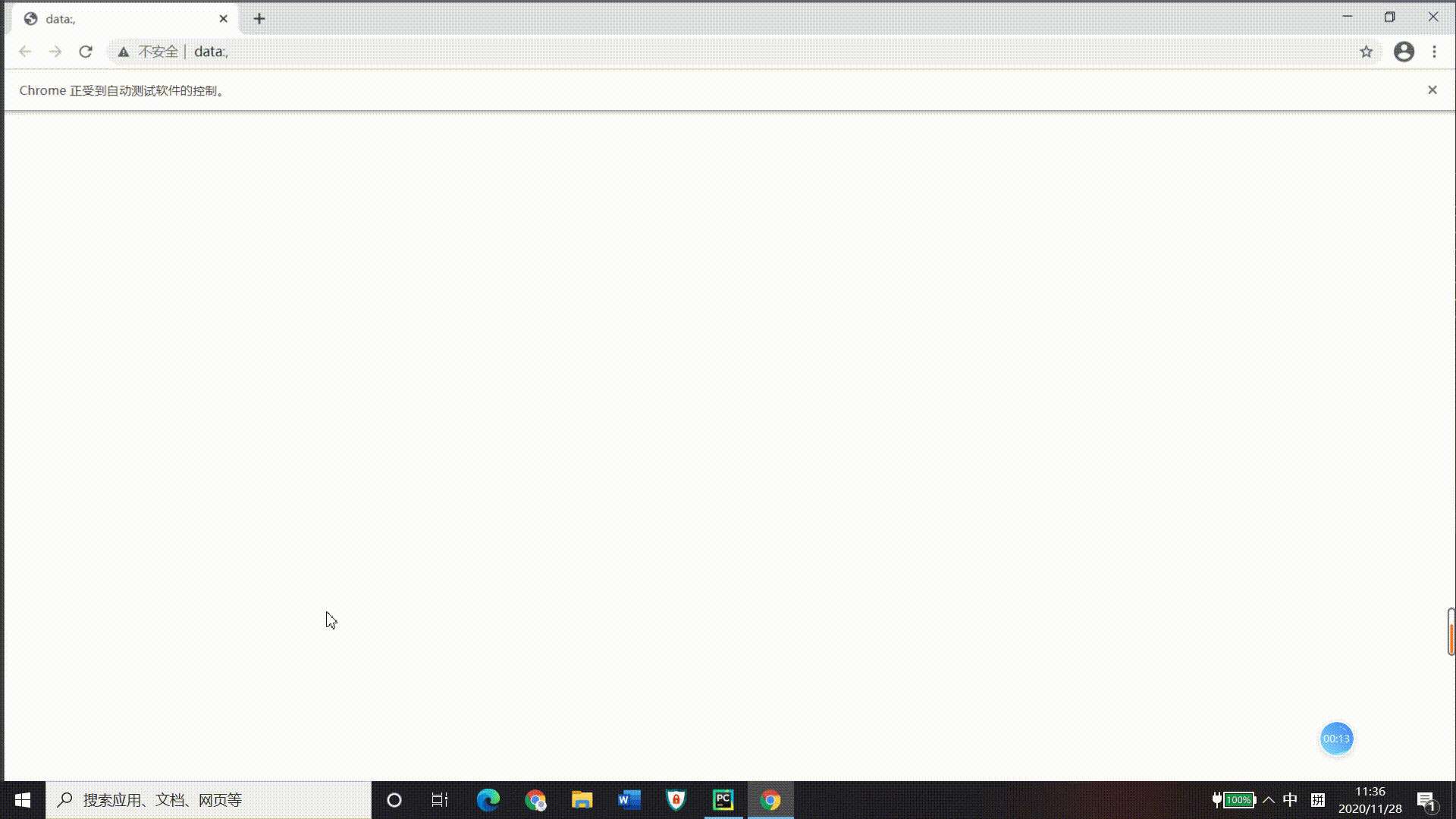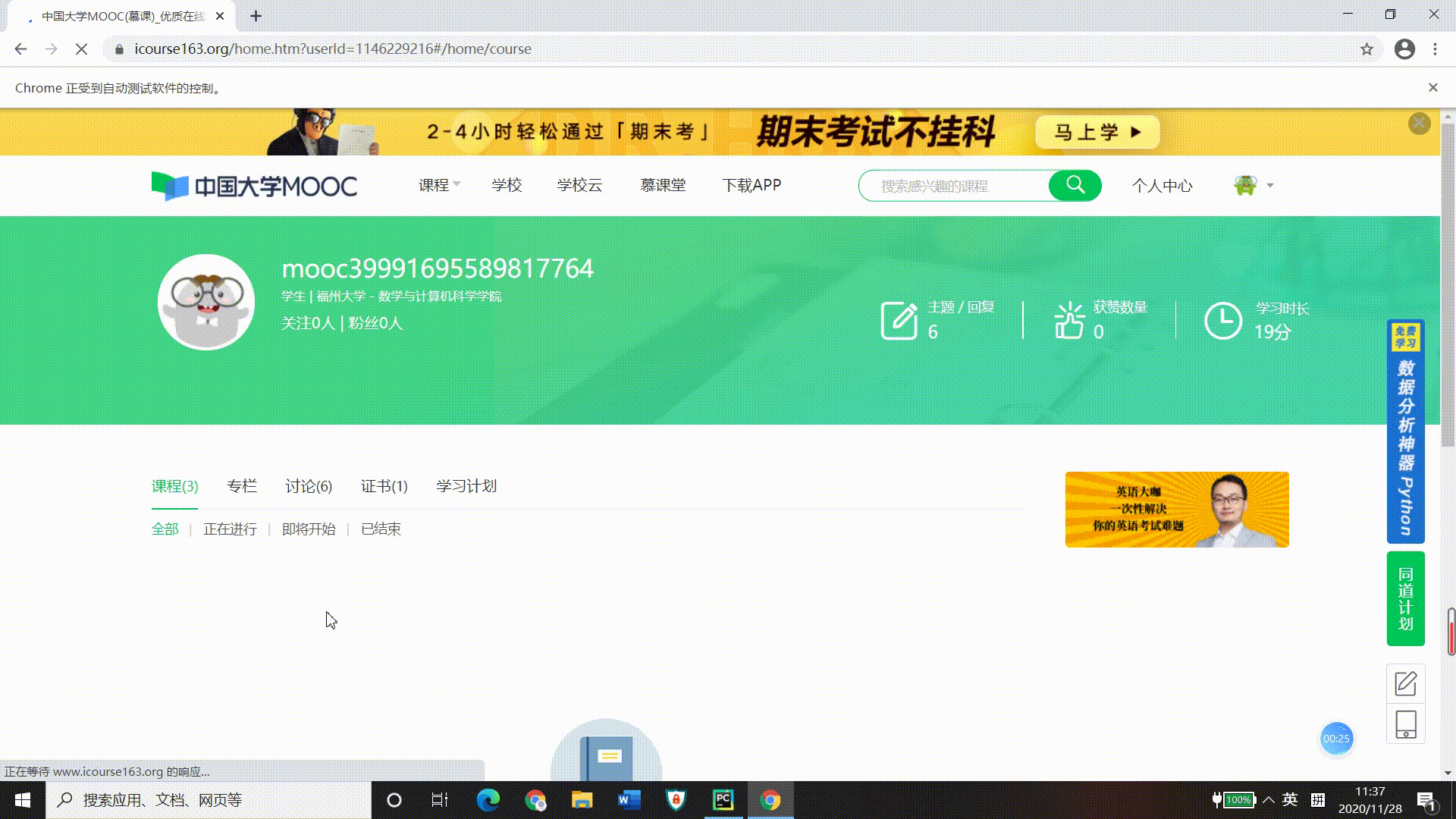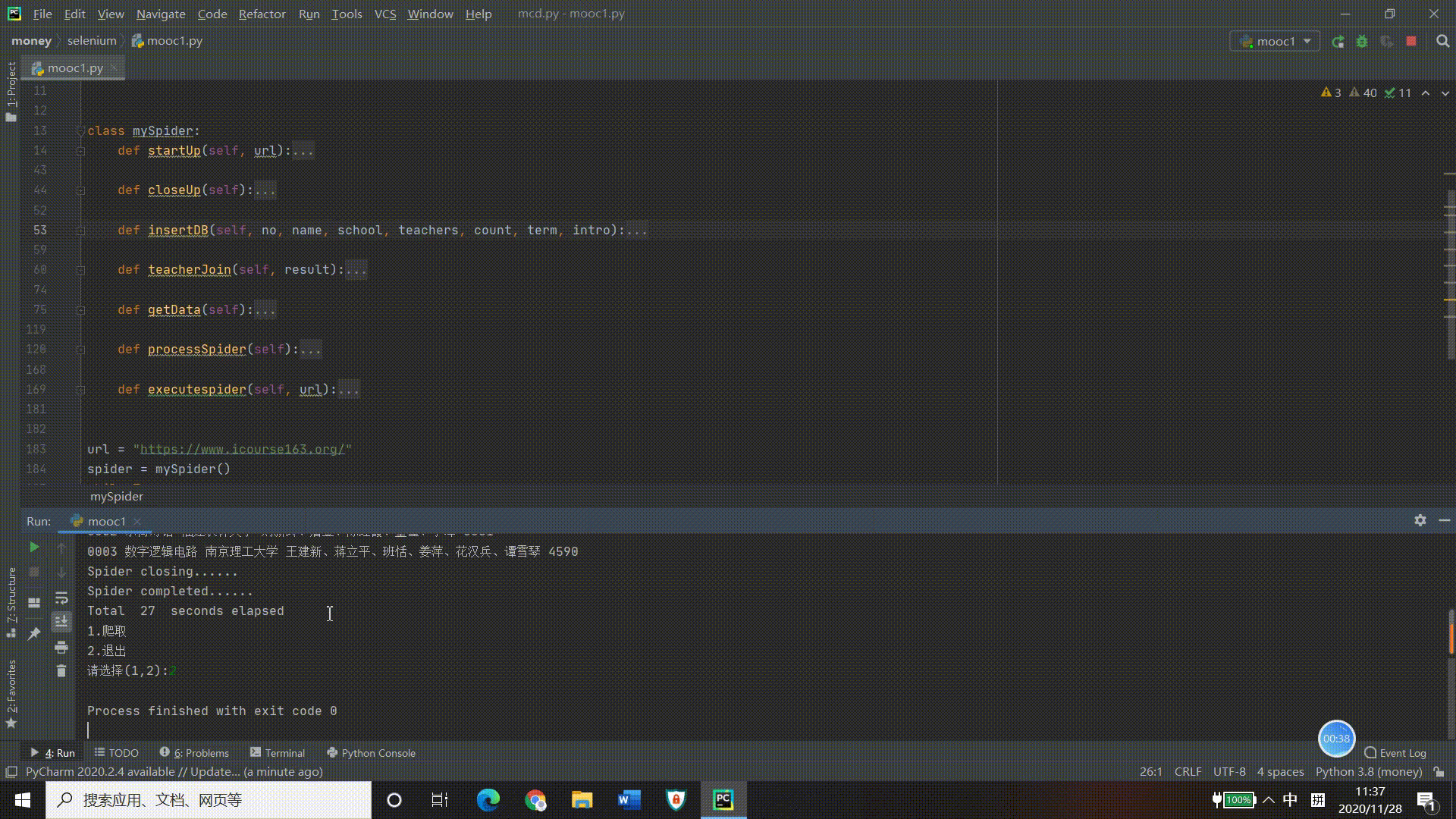

(2)心得体会
慕课登录界面储存在iframe嵌套页面中,必须把当前页面切换到iframe中才能登录,并且输入账号密码后应等待几秒钟,以防被认为是机器人。

