第一次作业——结合三次小作业
作业①:
(1)UniversitiesRanking实验
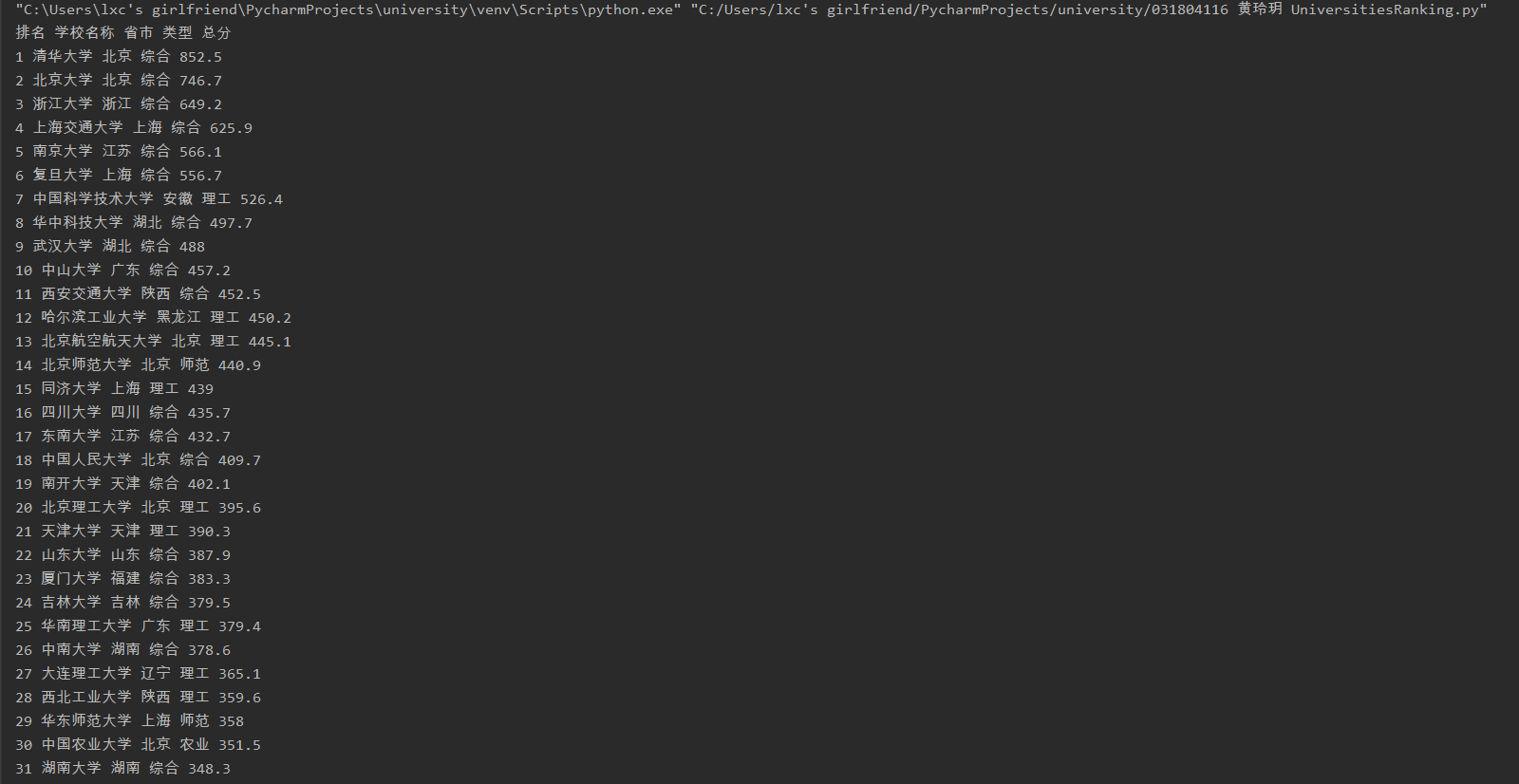
- 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
- 输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
try:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"}
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
trs1 = soup.select("thead[data-v-45ac69d8] tr") # 选择表中标题行
trs2 = soup.select("tbody[data-v-45ac69d8] tr") # 选择表格内容
# 打印标题行中各单元格的文字(除最后一列)
for tr1 in trs1:
try:
th1 = tr1.select('th')[0].text.strip()
th2 = tr1.select('th')[1].text.strip().replace('*','')
th3 = tr1.select('th')[2].text.strip()
th4 = tr1.select('th')[3].text.strip()
th5 = tr1.select('th')[4].text.strip()
print(th1,th2,th3,th4,th5)
except Exception as err:
print(err)
# 打印表格内容中的文字(除最后一列)
for tr2 in trs2:
try:
rank = tr2.select('td')[0].text.strip()
university = tr2.select('a')[0].text.strip()
city = tr2.select('td')[2].text.strip()
type = tr2.select('td')[3].text.strip()
score = tr2.select('td')[4].text.strip()
print(rank,university,city,type,score)
except Exception as err:
print(err)
except Exception as err:
print(err)
(2)心得体会
首先选中标题行,再将标题列表中元素一一打印出来。接下来再选中表格内容的每一行打印。总得来说比较简单。
作业②:
(1)GoodsPrices
- 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
- 输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
url = "http://www.ktown4u.cn/search?goodsTextSearch=%E4%B8%93%E8%BE%91¤tPage=1" # 爬取ktown4u网站下专辑的名称及价格信息
try:
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36"}
for i in range(1,3):
print("Page " + str(i)) #打印当前页
url = url.replace("currentPage=" + url[-1], "currentPage=" + str(i)) # 翻页
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
names = soup.find_all("span",attrs={"class":"btxt"}) # 选择商品名称
prices = soup.find_all("span",attrs={"class":"ctxt"}) # 选择价格(原价和现价)
p1 = []
n = []
i = 0
j = 0
# 将各商品名称加入列表n中
for name in names:
n.append("商品名称:"+name.text)
# 将价格加入列表p1中
for price in prices:
price = price.text.strip()
p = price.split('\n')
# 分离原价和现价
if (len(p) > 1):
p[0] = p[0].strip()
p[1] = p[1].strip()
p1.append("\t原价:" + p[0] + "\t现价:" + p[1])
else:
p1.append("\t现价:" + price)
p.clear()
j += 1
# 打印各商品名称及价格
for i in range(90):
print(n[i] + p1[i])
print()
print()
except Exception as err:
print(err)

(2)心得体会
本次实验重点在于实现翻页和原价现价的分离,翻页只需在url中改变currentPaged的值即可,而原价现价的分离则需要比较繁琐的步骤就不说明了。
ps.我爬的网站分原价现价,所以就可以不按格式输出了吧😚
作业③:
(1)JPGFileDownload实验
- 要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
- 输出信息:将自选网页内的所有jpg文件保存在一个文件夹中
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url,headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8"])
data = dammit.unicode_markup
soup = BeautifulSoup(data,"lxml")
images = soup.select("img") # 选择图像文件
for image in images:
try:
src = image["src"] # 图像文件的地址
url = urllib.request.urljoin(start_url,src)
if url not in urls:
if (url[len(url) - 3:] == "jpg"): # 选择JPG文件
print(url)
count = count + 1
# 创建线程
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4 :]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req,timeout=100)
data = data.read()
# 将下载的JPG文件写入本地文件夹
fobj = open("C:\\Users\\lxc's girlfriend\\Desktop\\images\\" + str(count) + ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url = "http://xcb.fzu.edu.cn"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"}
count = 0
threads = []
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
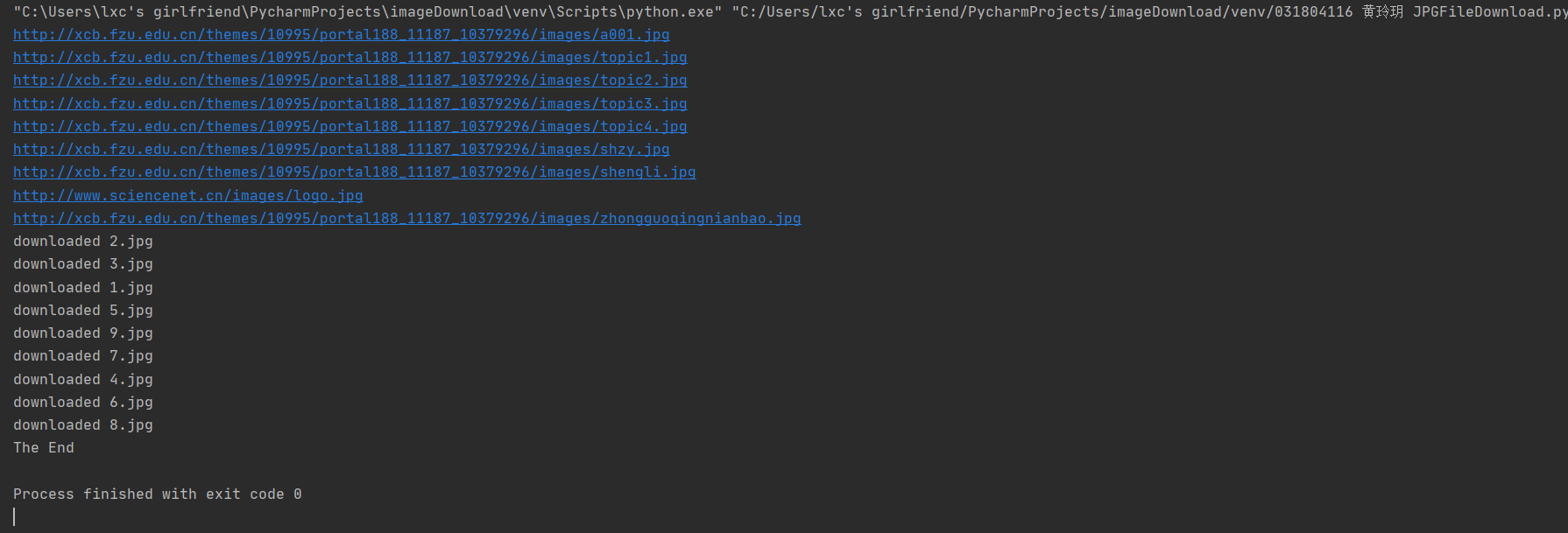
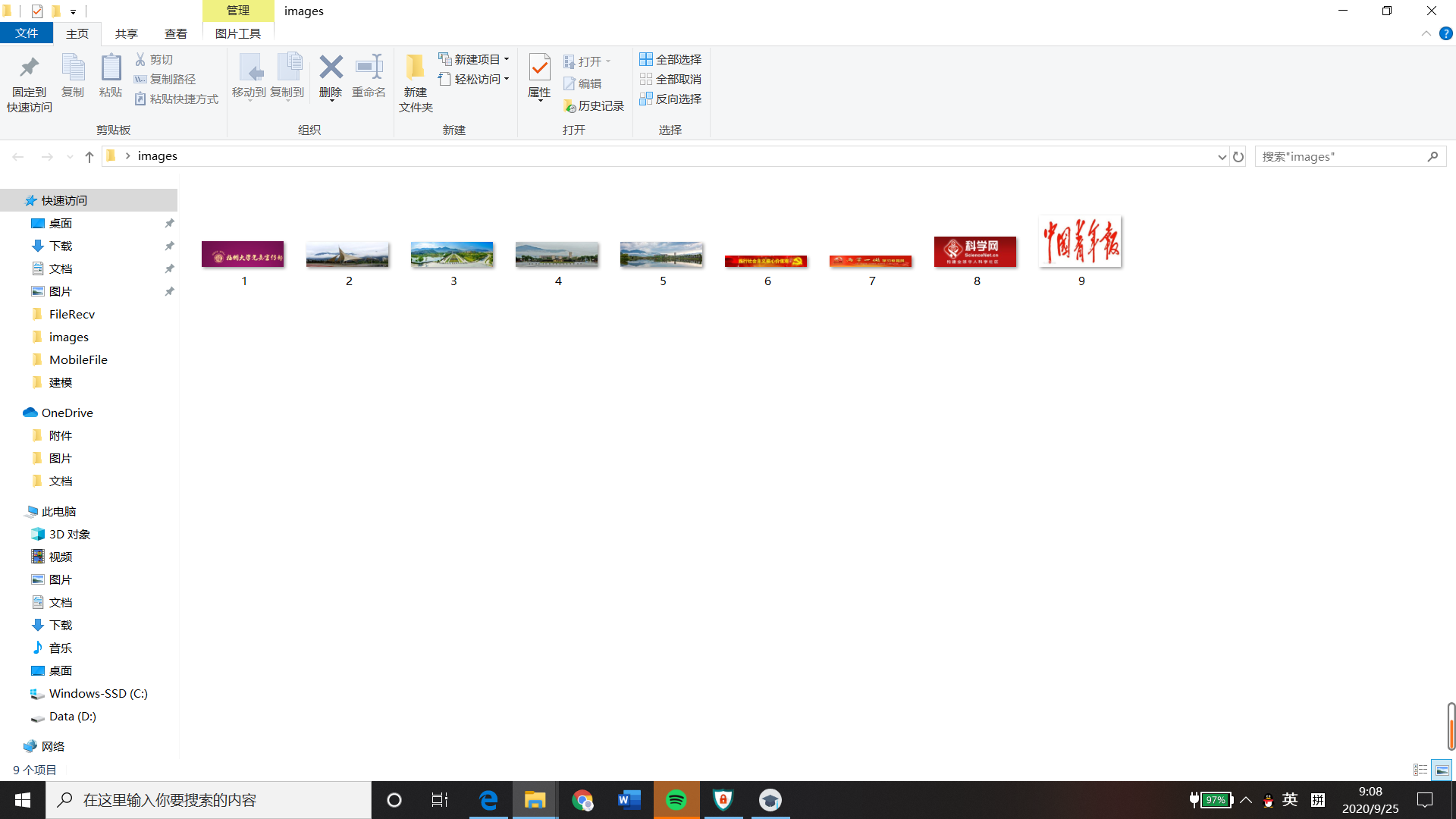
(2)心得体会
本次实验重点是在所有玩图像文件中选择JPG文件和多线程爬虫。选择JPG文件只需要判断地址最后三位是否为"jpg"即可,比较简单。爬取网站图像文件时可使用多线程的方法,它保证了多个文件的同时下载,且互不干扰,如果一个文件没有完成下载或者下载出现问题,也不会影响别的文件的下载,效率高,可靠性高,应该不会太复杂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号