模型融合之blending和stacking
1. blending
- 需要得到各个模型结果集的权重,然后再线性组合。
"""Kaggle competition: Predicting a Biological Response.
Blending {RandomForests, ExtraTrees, GradientBoosting} + stretching to
[0,1]. The blending scheme is related to the idea Jose H. Solorzano
presented here:
http://www.kaggle.com/c/bioresponse/forums/t/1889/question-about-the-process-of-ensemble-learning/10950#post10950
'''You can try this: In one of the 5 folds, train the models, then use
the results of the models as 'variables' in logistic regression over
the validation data of that fold'''. Or at least this is the
implementation of my understanding of that idea :-)
The predictions are saved in test.csv. The code below created my best
submission to the competition:
- public score (25%): 0.43464
- private score (75%): 0.37751
- final rank on the private leaderboard: 17th over 711 teams :-)
Note: if you increase the number of estimators of the classifiers,
e.g. n_estimators=1000, you get a better score/rank on the private
test set.
Copyright 2012, Emanuele Olivetti.
BSD license, 3 clauses.
"""
from __future__ import division
import numpy as np
import load_data
from sklearn.cross_validation import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
def logloss(attempt, actual, epsilon=1.0e-15):
"""Logloss, i.e. the score of the bioresponse competition.
"""
attempt = np.clip(attempt, epsilon, 1.0-epsilon)
return - np.mean(actual * np.log(attempt) +
(1.0 - actual) * np.log(1.0 - attempt))
if __name__ == '__main__':
np.random.seed(0) # seed to shuffle the train set
n_folds = 10
verbose = True
shuffle = False
X, y, X_submission = load_data.load()
if shuffle:
idx = np.random.permutation(y.size)
X = X[idx]
y = y[idx]
skf = list(StratifiedKFold(y, n_folds))
clfs = [RandomForestClassifier(n_estimators=100, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=100, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=100, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=100, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=50)]
print ("Creating train and test sets for blending.")
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_submission.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
print (j, clf)
dataset_blend_test_j = np.zeros((X_submission.shape[0], len(skf)))
for i, (train, test) in enumerate(skf):
print ("Fold", i)
X_train = X[train]
y_train = y[train]
X_test = X[test]
y_test = y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_submission)[:, 1]
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
print()
print( "Blending.")
clf = LogisticRegression()
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]
print( "Linear stretch of predictions to [0,1]")
y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min())
print( "Saving Results.")
tmp = np.vstack([range(1, len(y_submission)+1), y_submission]).T
np.savetxt(fname='submission.csv', X=tmp, fmt='%d,%0.9f',
header='MoleculeId,PredictedProbability', comments='')
2.stacking
- stacking的核心:在训练集上进行预测,从而构建更高层的学习器。
- stacking训练过程:
1) 拆解训练集。将训练数据随机且大致均匀的拆为m份。
2)在拆解后的训练集上训练模型,同时在测试集上预测。利用m-1份训练数据进行训练,预测剩余一份;在此过程进行的同时,利用相同的m-1份数据训练,在真正的测试集上预测;如此重复m次,将训练集上m次结果叠加为1列,将测试集上m次结果取均值融合为1列。
3)使用k个分类器重复2过程。将分别得到k列训练集的预测结果,k列测试集预测结果。
4)训练3过程得到的数据。将k列训练集预测结果和训练集真实label进行训练,将k列测试集预测结果作为测试集。
# -*- coding: utf-8 -*-
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
import xgboost as xgb
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.linear_model import LogisticRegression
def load_data():
pass
def stacking(train_x, train_y, test):
""" stacking
input: train_x, train_y, test
output: test的预测值
clfs: 5个一级分类器
dataset_blend_train: 一级分类器的prediction, 二级分类器的train_x
dataset_blend_test: 二级分类器的test
"""
# 5个一级分类器
clfs = [SVC(C = 3, kernel="rbf"),
RandomForestClassifier(n_estimators=100, max_features="log2", max_depth=10, min_samples_leaf=1, bootstrap=True, n_jobs=-1, random_state=1),
KNeighborsClassifier(n_neighbors=15, n_jobs=-1),
xgb.XGBClassifier(n_estimators=100, objective="binary:logistic", gamma=1, max_depth=10, subsample=0.8, nthread=-1, seed=1),
ExtraTreesClassifier(n_estimators=100, criterion="gini", max_features="log2", max_depth=10, min_samples_split=2, min_samples_leaf=1,bootstrap=True, n_jobs=-1, random_state=1)]
# 二级分类器的train_x, test
dataset_blend_train = np.zeros((train_x.shape[0], len(clfs)), dtype=np.int)
dataset_blend_test = np.zeros((test.shape[0], len(clfs)), dtype=np.int)
# 5个分类器进行8_folds预测
n_folds = 8
skf = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=1)
for i,clf in enumerate(clfs):
dataset_blend_test_j = np.zeros((test.shape[0], n_folds)) # 每个分类器的单次fold预测结果
for j,(train_index,test_index) in enumerate(skf.split(train_x, train_y)):
tr_x = train_x[train_index]
tr_y = train_y[train_index]
clf.fit(tr_x, tr_y)
dataset_blend_train[test_index, i] = clf.predict(train_x[test_index])
dataset_blend_test_j[:, j] = clf.predict(test)
dataset_blend_test[:, i] = dataset_blend_test_j.sum(axis=1) // (n_folds//2 + 1)
# 二级分类器进行预测
clf = LogisticRegression(penalty="l1", tol=1e-6, C=1.0, random_state=1, n_jobs=-1)
clf.fit(dataset_blend_train, train_y)
prediction = clf.predict(dataset_blend_test)
return prediction
def main():
(train_x, train_y, test) = load_data()
prediction = stacking(train_x, train_y, test)
return prediction
if __name__ == "__main__":
prediction = main()
ensemble model
比较简明的资源有:
- 1.https://zhuanlan.zhihu.com/p/26890738
- 2.数据应用学院 Kaggle案例实战 公开课 Part 2 https://www.youtube.com/watch?v=BS4SY3HhVDI&t=4320s
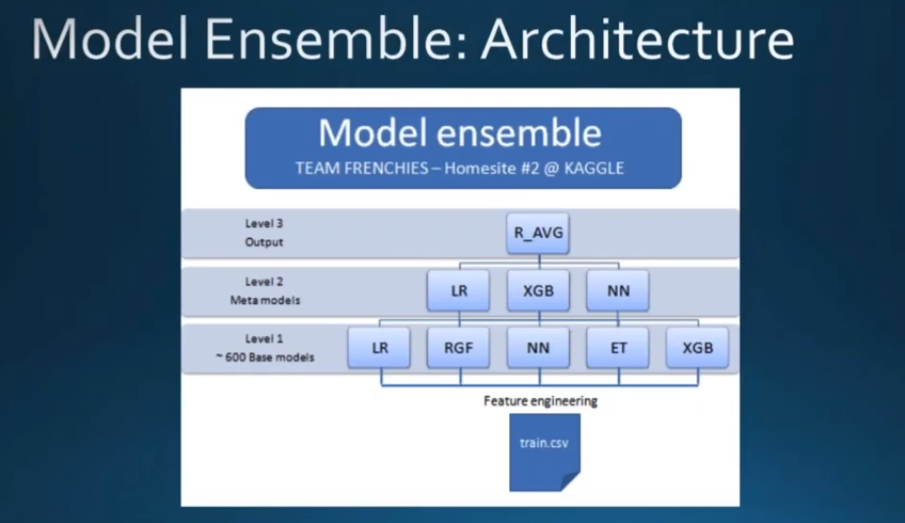
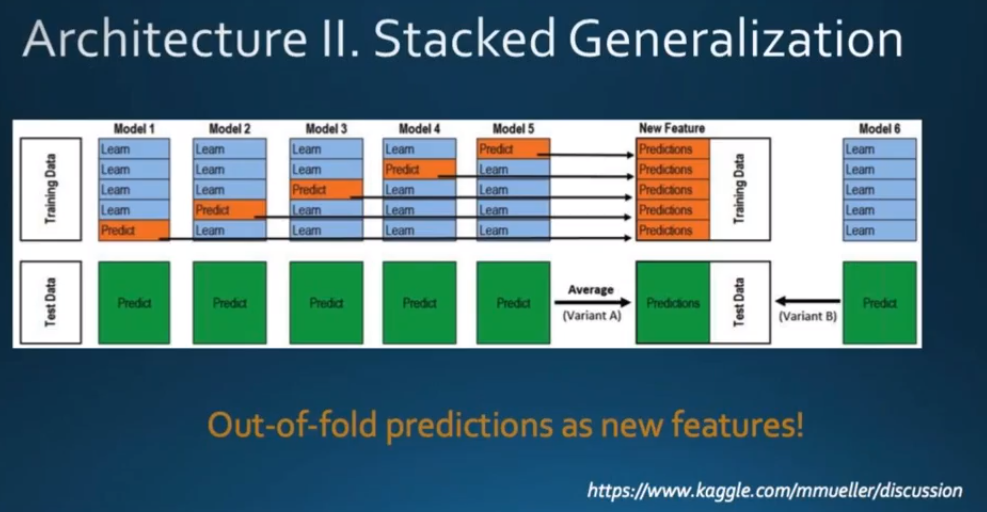
上面的是以5折为例,如果是2折的话就更简单了!

-----------------------------------------------------分割线------------------------------------------------------------------
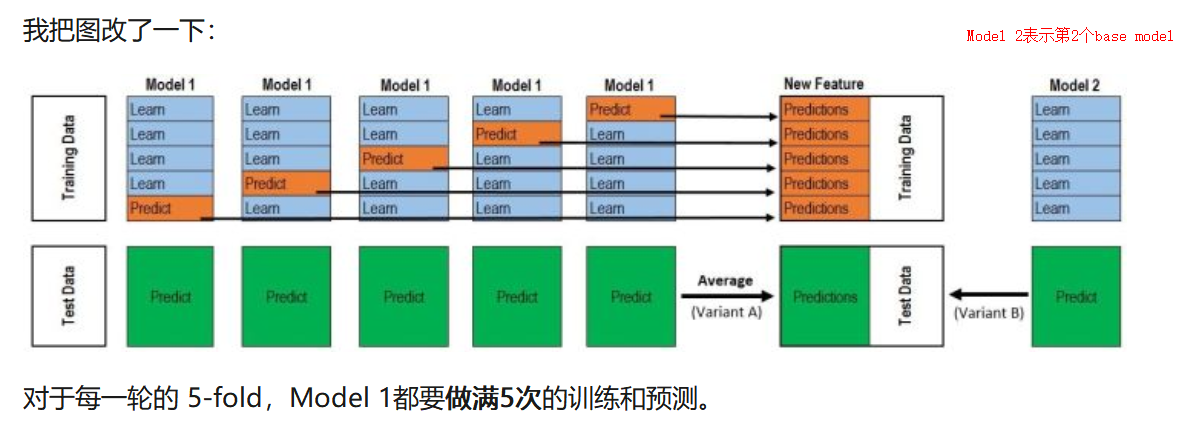
- 以Kaggle的泰坦尼克号为例子
# out-of-Fold Prdictions
TrainingData = train.shape[0] # 891行
TestData = test.shape[0] # 418 行
# 5 折
kf = KFold(n_splits = 5, random_state = 2017)
# X_train, y_train, X_test表示原生的数据
def get_oof(clf, X_train, y_train, X_test):
# oof_train对应于训练数据集TrainingData
oof_train = np.zeros((TrainingData, )) # 1 * 891型
# oof_test对应于测试集TestData
oof_test = np.zeros((TestData, )) # 1 * 418型
# oof_test_skf对应于5折之后的所有predict作为新的TestData(测试集),只要最后对行(axis = 0)取平均就得到平均predict值Test Data
oof_test_skf = np.empty((5, TestData)) # 5 * 418型
for i, (train_index, test_index) in enumerate(kf.split(X_train)):
# kf_X_train 表示train data每一折中用于训练的训练集(4份共有712个样本)
kf_X_train = X_train[train_index] # 712 * 7 例如712 instances for each fold
kf_y_train = y_train[train_index] # 712 * 1 例如712 instances for each fold
# kf_X_test 表示train data每一折中用于predict的数据集(也就是验证集validation data)
kf_X_test = X_train[test_index] # 179 * 7 例如178 instances for each fold
clf.train(kf_X_train, kf_y_train) # 训练模型
# 得到predict值(输出值)作为new feature输入用于第二层的训练
# 一个base model 就对应于new feature的一列,此时的new feature有多少列取决于你第一层用了多少个base model
oof_train[test_index] = clf.prdict(kf_X_test) # 1 * 179 ===> will be 1 * 891 after 5 folds
# 用TestData --这里X_test(测试集)用于预测
oof_test_skf[i, :] = clf.predict(X_test) # oof_test_skf[i, :],1 * 418 ===> will be 5 * 418 after 5 folds
# 5折stacking结束后
# 对测试集预测得到的predict值进行行(axis = 0)平均: 5 * 418 ===> 1 * 418
oof_test[:] = oof_test_skf.mean(axis = 0)
return oof_train.reshpae(-1, 1), oof_test.reshpae(-1, 1)
# oof_train.reshpae(-1, 1): 891 * 1 oof_test.reshpae(-1, 1): 418 * 1
-------------------------------------------------补充----------------------------------------------
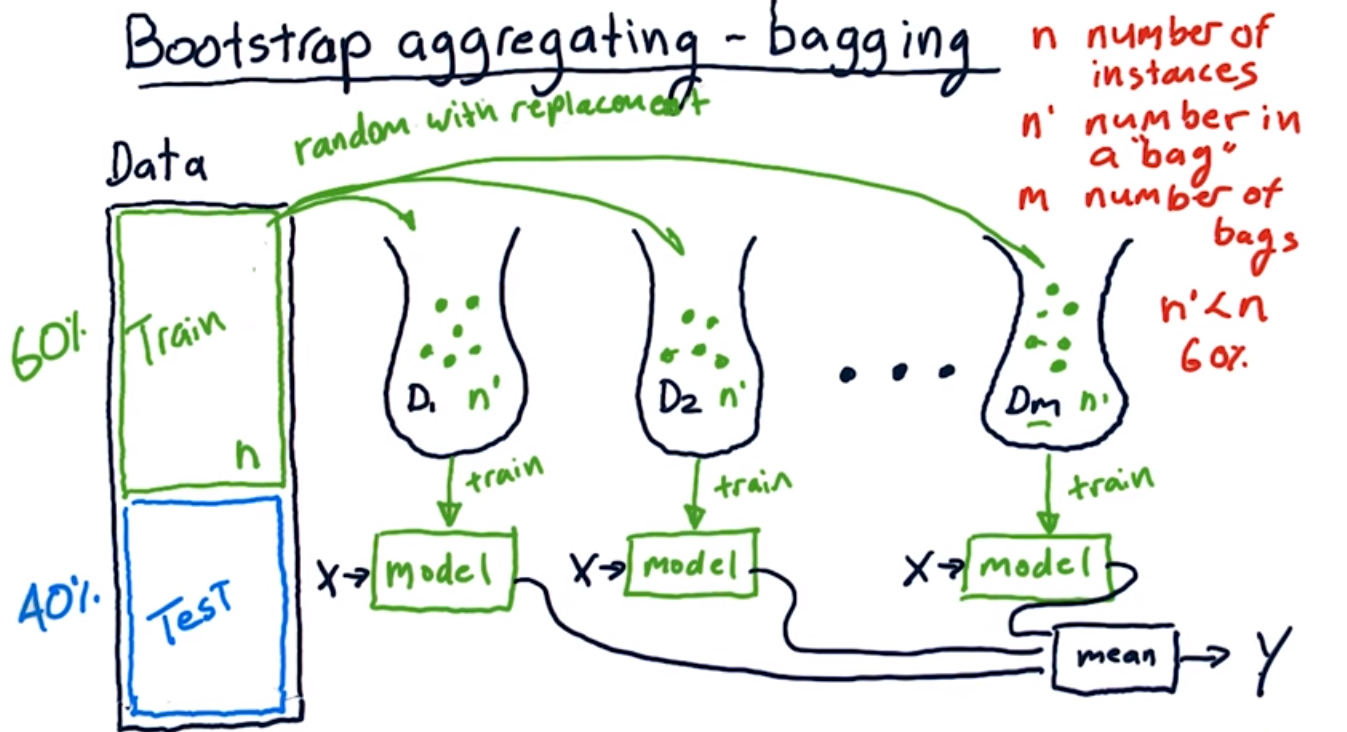
Udacity的几张图

本文版权归作者和博客园共有,欢迎转载,转载请注明出处和链接来源。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号