动手学深度学习PyTorch版-task02
task0201.文本预处理

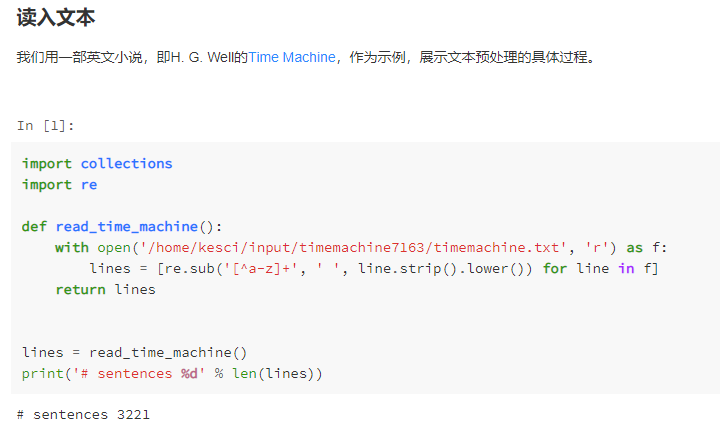
- 代码解读
import collections
import re
with open('timemachine.txt', 'r', encoding='UTF-8') as f:
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
print(lines)

In[8]: lines[0]
Out[8]: 'the time machine'
In[9]: lines[1]
Out[9]: ''
In[10]: lines[0].split()
Out[10]: ['the', 'time', 'machine']
In[11]: lines[0].split(' ')
Out[11]: ['the', 'time', 'machine']




文本预处理步骤:
1.读取文本 2.分词 3.构建字典 建立索引
Vocab字典构建步骤:
1.统计词频,去重筛选掉低频词
2.根据需求添加特殊的token
3.建立字典,将每个token建立映射到唯一的索引
4.建立索引到token的映射
部分知识汇总:
string = ' AbcDe' # 主要是说明string是一个字符串,下面是视频中涉及到了两个操作
string.strip() # 用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列,在这里是用来删除单词之间的空格和换行符
string.lower() # 将字符串中的所有大写字母都转化成小写
#两者还可以拼起来用:string.strip().lower() 具体的意思也就是上面两个意思拼起来
lines = [re.sub('[^a-z]+', ' ', line.strip().lower()) for line in f]
# 上面这行代码的正则部分为
re.sub('[^a-z]+', ' ', str)
# re.sub()函数是用来字符串替换的函数
# '[^a-z]+' 注意这里的^是非的意思,就是说非a-z字符串
# 上面句子的含义是:将字符串str中的非小写字母开头的字符串以空格代替
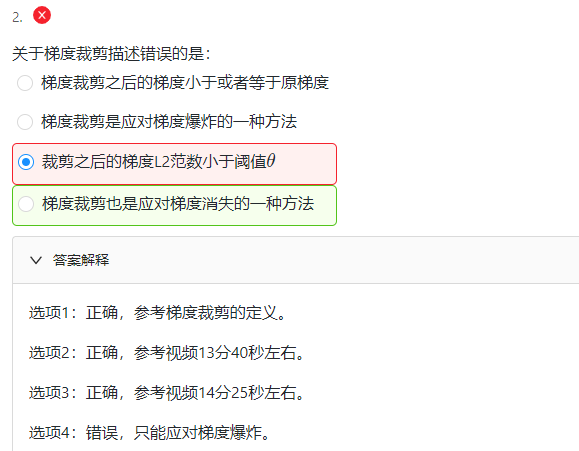
课后习题

task0202.语言模型与数据集




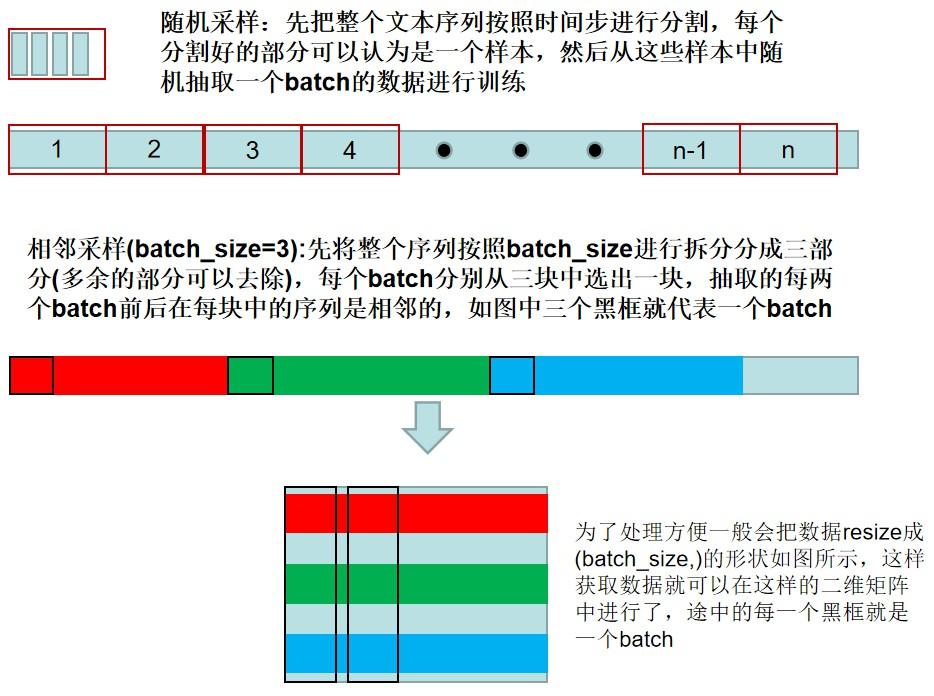
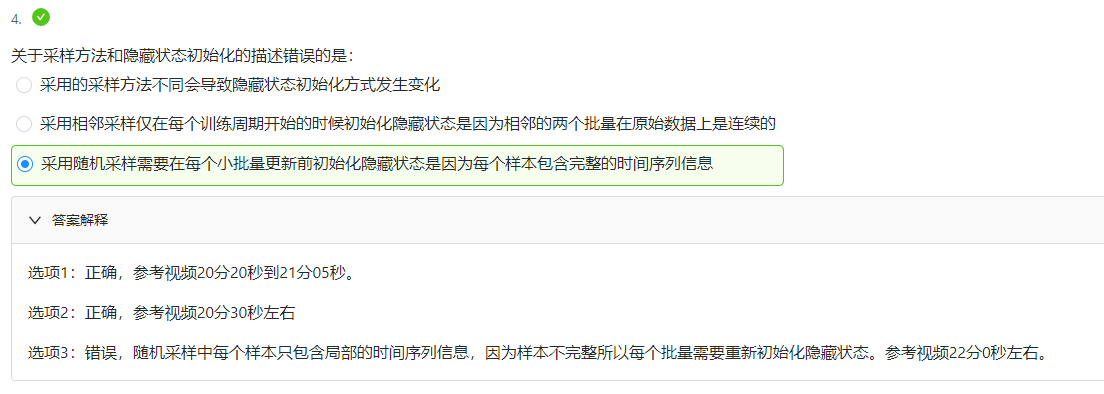
课后习题


task0203.循环神经网络基础
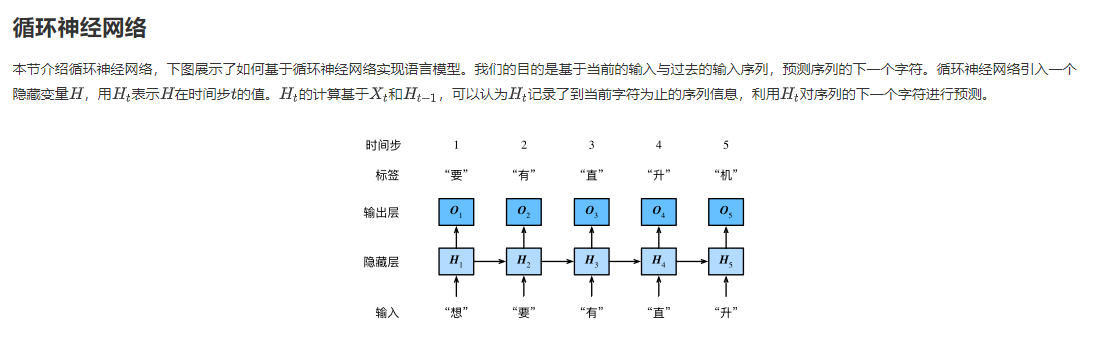


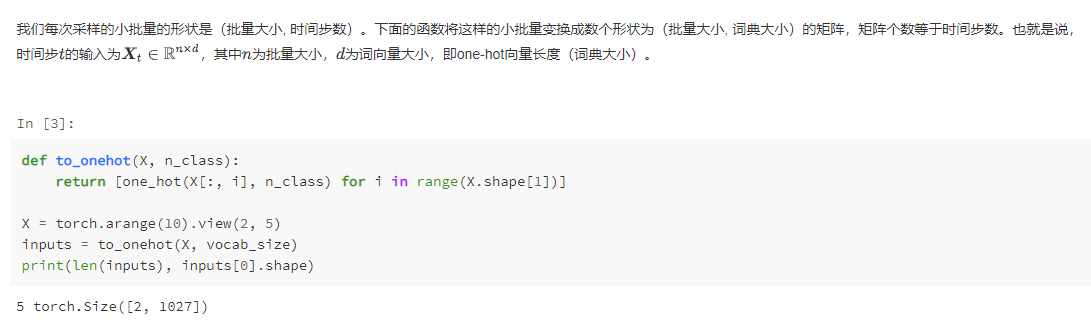



课后习题


本文版权归作者和博客园共有,欢迎转载,转载请注明出处和链接来源。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号