ceph 存储
第1章 概念
1.1 存储概念
总结:
文件存储
设备:FTP、NFS服务器
特点:一个大文件夹,大家都可以获取文件
优点:可以共享
缺点:传输速率低
块存储
设备:cinder,磁盘阵列,硬盘,虚拟硬盘
特点:分区、格式化后,可以使用,与平常主机内置硬盘的方式完全无异
优点:直接挂载使用
缺点:不能共享数据
对象存储
设备:swift,键值存储
特点:具备块存储的高速以及文件存储的共享等特性
优点:速率快,共享方便
缺点:不兼容现有模式
对象存储(Object-based Storage)是一种新的网络存储架构,基于对象存储技术的设备就是对象存储设备(Object-based Storage Device)简称OSD。对象存储: 也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL和其他扩展,如七牛、又拍、Swift、S3
【块存储】
典型设备:磁盘阵列,硬盘
块存储主要是将裸磁盘空间整个映射给主机使用的,就是说例如磁盘阵列里面有5块硬盘(为方便说明,假设每个硬盘1G),然后可以通过划逻辑盘、做Raid、或者LVM(逻辑卷)等种种方式逻辑划分出N个逻辑的硬盘。(假设划分完的逻辑盘也是5个,每个也是1G,但是这5个1G的逻辑盘已经于原来的5个物理硬盘意义完全不同了。例如第一个逻辑硬盘A里面,可能第一个200M是来自物理硬盘1,第二个200M是来自物理硬盘2,所以逻辑硬盘A是由多个物理硬盘逻辑虚构出来的硬盘。)
接着块存储会采用映射的方式将这几个逻辑盘映射给主机,主机上面的操作系统会识别到有5块硬盘,但是操作系统是区分不出到底是逻辑还是物理的,它一概就认为只是5块裸的物理硬盘而已,跟直接拿一块物理硬盘挂载到操作系统没有区别的,至少操作系统感知上没有区别。
此种方式下,操作系统还需要对挂载的裸硬盘进行分区、格式化后,才能使用,与平常主机内置硬盘的方式完全无异。
优点:
1、 这种方式的好处当然是因为通过了Raid与LVM等手段,对数据提供了保护。
2、 另外也可以将多块廉价的硬盘组合起来,成为一个大容量的逻辑盘对外提供服务,提高了容量。
3、 写入数据的时候,由于是多块磁盘组合出来的逻辑盘,所以几块磁盘可以并行写入的,提升了读写效率。
4、 很多时候块存储采用SAN架构组网,传输速率以及封装协议的原因,使得传输速度与读写速率得到提升。
缺点:
1、采用SAN架构组网时,需要额外为主机购买光纤通道卡,还要买光纤交换机,造价成本高。
2、主机之间的数据无法共享,在服务器不做集群的情况下,块存储裸盘映射给主机,再格式化使用后,对于主机来说相当于本地盘,那么主机A的本地盘根本不能给主机B去使用,无法共享数据。
3、不利于不同操作系统主机间的数据共享:另外一个原因是因为操作系统使用不同的文件系统,格式化完之后,不同文件系统间的数据是共享不了的。例如一台装了WIN7/XP,文件系统是FAT32/NTFS,而Linux是EXT4,EXT4是无法识别NTFS的文件系统的。就像一只NTFS格式的U盘,插进Linux的笔记本,根本无法识别出来。所以不利于文件共享。
【文件存储】
典型设备:FTP、NFS服务器
为了克服上述文件无法共享的问题,所以有了文件存储。
文件存储也有软硬一体化的设备,但是其实普通拿一台服务器/笔记本,只要装上合适的操作系统与软件,就可以架设FTP与NFS服务了,架上该类服务之后的服务器,就是文件存储的一种了。
主机A可以直接对文件存储进行文件的上传下载,与块存储不同,主机A是不需要再对文件存储进行格式化的,因为文件管理功能已经由文件存储自己搞定了。
优点:
1、造价交低:随便一台机器就可以了,另外普通以太网就可以,根本不需要专用的SAN网络,所以造价低。
2、方便文件共享:例如主机A(WIN7,NTFS文件系统),主机B(Linux,EXT4文件系统),想互拷一部电影,本来不行。加了个主机C(NFS服务器),然后可以先拷到C,然后AB挂载就OK了。
缺点:
读写速率低,传输速率慢:以太网,上传下载速度较慢,另外所有读写都要1台服务器里面的硬盘来承担,相比起磁盘阵列动不动就几十上百块硬盘同时读写,速率慢了许多。
【对象存储】
典型设备:内置大容量硬盘的分布式服务器
对象存储最常用的方案,就是多台服务器内置大容量硬盘,再装上对象存储软件,然后再额外搞几台服务作为管理节点,安装上对象存储管理软件。管理节点可以管理其他服务器对外提供读写访问功能。
之所以出现了对象存储这种东西,是为了克服块存储与文件存储各自的缺点,发扬它俩各自的优点。简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利 于共享的出来呢。于是就有了对象存储。
首先,一个文件包含了了属性(术语叫metadata,元数据,例如该文件的大小、修改时间、存储路径等)以及内容(以下简称数据)。
以往像FAT32这种文件系统,是直接将一份文件的数据与metadata一起存储的,存储过程先将文件按照文件系统的最小块大小来打散(如4M的文件,假设文件系统要求一个块4K,那么就将文件打散成为1000个小块),再写进硬盘里面,过程中没有区分数据/metadata的。而每个块最后会告知你下一个要读取的块的地址,然后一直这样顺序地按图索骥,最后完成整份文件的所有块的读取。
这种情况下读写速率很慢,因为就算你有100个机械手臂在读写,但是由于你只有读取到第一个块,才能知道下一个块在哪里,其实相当于只能有1个机械手臂在实际工作。
而对象存储则将元数据独立了出来,控制节点叫元数据服务器(服务器+对象存储管理软件),里面主要负责存储对象的属性(主要是对象的数据被打散存放到了那几台分布式服务器中的信息),而其他负责存储数据的分布式服务器叫做OSD,主要负责存储文件的数据部分。当用户访问对象,会先访问元数据服务器,元数据服务器只负责反馈对象存储在哪些OSD,假设反馈文件A存储在B、C、D三台OSD,那么用户就会再次直接访问3台OSD服务器去读取数据。
这时候由于是3台OSD同时对外传输数据,所以传输的速度就加快了。当OSD服务器数量越多,这种读写速度的提升就越大,通过此种方式,实现了读写快的目的。
另一方面,对象存储软件是有专门的文件系统的,所以OSD对外又相当于文件服务器,那么就不存在文件共享方面的困难了,也解决了文件共享方面的问题。
所以对象存储的出现,很好地结合了块存储与文件存储的优点。
最后为什么对象存储兼具块存储与文件存储的好处,还要使用块存储或文件存储呢?
1、有一类应用是需要存储直接裸盘映射的,例如数据库。因为数据库需要存储裸盘映射给自己后,再根据自己的数据库文件系统来对裸盘进行格式化的,所以是不能够采用其他已经被格式化为某种文件系统的存储的。此类应用更适合使用块存储。
2、对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。
1.2 Ceph概念
无论您想为云平台提供Ceph对象存储和/或Ceph块设备服务、部署Ceph文件系统或将Ceph用于其他目的,所有Ceph存储集群部署都是从设置每个Ceph节点、您的网络和Ceph存储集群开始的。Ceph存储集群至少需要一个Ceph Monitor,Ceph Manager和Ceph OSD (对象存储守护进程)。运行Ceph Filesystem客户端时也需要Ceph元数据服务器。
监视器:Ceph Monitor(ceph-mon)维护集群状态的映射,包括监视器映射,管理器映射,OSD映射和CRUSH映射。这些映射是Ceph守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常至少需要三个监视器。
管理器:Ceph Manager守护程序(ceph-mgr)负责跟踪运行时指标和Ceph集群的当前状态,包括存储利用率,当前性能指标和系统负载。Ceph Manager守护进程还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的Ceph Manager Dashboard和 REST API。高可用性通常至少需要两名经理。
Ceph OSD:Ceph OSD(对象存储守护进程 ceph-osd)存储数据,处理数据复制,恢复,重新平衡,并通过检查其他Ceph OSD守护进程来获取心跳,为Ceph监视器和管理器提供一些监视信息。冗余和高可用性通常至少需要3个Ceph OSD。
MDS:Ceph元数据服务器(MDS ceph-mds)代表Ceph文件系统存储元数据(即,Ceph块设备和Ceph对象存储不使用MDS)。Ceph的元数据服务器允许POSIX文件系统的用户来执行基本的命令(如 ls,find没有放置在一个Ceph存储集群的巨大负担,等等)。
Ceph将数据存储为逻辑存储池中的对象。使用 CRUSH算法,Ceph计算应该包含对象的放置组,并进一步计算哪个Ceph OSD守护进程应该存储放置组。CRUSH算法使Ceph存储集群能够动态扩展,重新平衡和恢复。
Ceph对cpu,ram(内存),磁盘的要求
Ceph元数据服务器动态地重新分配其负载,这是CPU密集型的。因此,您的元数据服务器应具有强大的处理能力(例如,四核或更好的CPU)。Ceph OSD运行RADOS服务,使用CRUSH计算数据放置,复制数据,并维护自己的集群映射副本。因此,OSD应具有合理数量的处理能力(例如,双核处理器)。监视器只是维护集群映射的主副本,因此它们不是CPU密集型的。除了Ceph守护进程之外,您还必须考虑主机是否将运行CPU密集型进程。例如,如果您的主机将运行计算VM(例如,OpenStack Nova),则需要确保这些其他进程为Ceph守护程序留下足够的处理能力。我们建议在不同的主机上运行其他CPU密集型进程。
元数据服务器和监视器必须能够快速提供数据,因此它们应该有足够的RAM(例如,每个守护进程实例有1GB的RAM)。OSD不需要为常规操作提供尽可能多的RAM(例如,每个守护进程实例有500MB RAM); 但是,在恢复期间,他们需要更多的RAM(例如,每个守护进程每1TB存储大约1GB)。通常,RAM越多越好。
我们建议每台主机至少有两个1Gbps网络接口控制器(NIC)。由于大多数商用硬盘驱动器的吞吐量大约为100MB /秒,因此您的NIC应该能够处理主机上OSD磁盘的流量。我们建议至少使用两个NIC来考虑公共(前端)网络和群集(后端)网络。群集网络(最好不连接到Internet)处理数据复制的额外负载,并帮助阻止阻止群集实现的拒绝服务攻击active + cleanOSD的状态,因为OSD会在群集中复制数据。考虑从机架中的10Gbps网络开始。
1:默认内核的版本较旧btrfs,我们不建议用于ceph-osd存储节点。我们建议使用XFS。
2:默认内核有一个旧的Ceph客户端,我们不建议内核客户端(内核RBD或Ceph文件系统)。升级到推荐的内核。
3:btrfs 使用文件系统时,默认内核在QA中经常失败。我们不建议btrfs用于支持Ceph OSD。
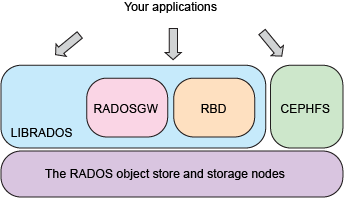
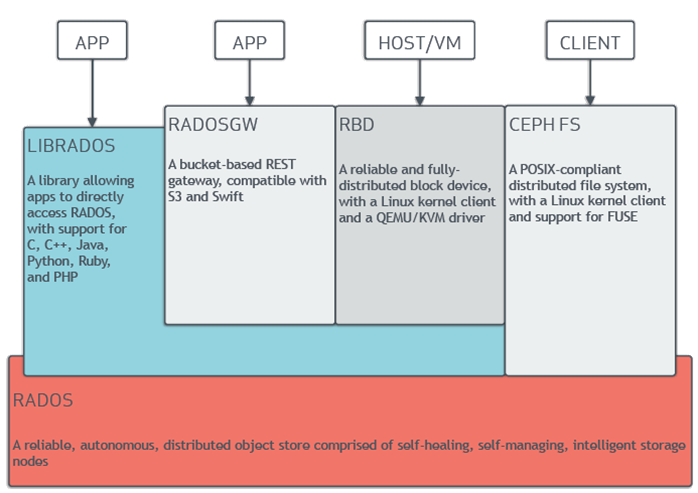
Ceph的软件库为客户端应用程序提供了直接访问RADOS基于对象的存储系统的基础,同时也为Ceph的一些高级功能提供了基础,包括RADOS Block Device(RBD),RADOS Gateway(RGW)和Ceph File System CephFS)。
RADOS网关(RGW)
Ceph对象网关是构建在librados之上的对象存储接口,用于为应用程序提供Ceph存储集群的RESTful网关。Ceph对象存储支持两个接口:与S3兼容:通过与Amazon S3 RESTful API的大型子集兼容的界面提供对象存储功能。Swift兼容:通过一个与OpenStack Swift API的大型子集兼容的接口提供对象存储功能。
LIBRADOS
Ceph librados软件库支持用C,C ++,Java,Python,PHP和其他语言编写的应用程序使用本机API访问Ceph的对象存储系统。librados库提供了高级功能,包括:
部分或完整的读取和写入
快照
具有附加,截断和克隆范围等特性的原子事务
对象级关键值映射
Ceph的对象存储系统不限于本地绑定或RESTful API。您可以将Ceph安装为精简配置的块设备!当您使用块设备将数据写入Ceph时,Ceph会自动分条并在集群中复制数据。Ceph的RADOS块设备(RBD)还与内核虚拟机(KVM)集成,将Ceph的无限存储空间带给Ceph客户端上运行的KVM。
Ceph RBD与提供librados接口和Ceph FS文件系统的Ceph对象存储系统连接,并将块设备映像存储为对象。由于RBD构建在librad之上,RBD继承了librados功能,包括只读快照并恢复为快照。通过在整个集群中分散图像,Ceph提高了大型块设备映像的读取访问性能。
优点
Thinly provisioned
Resizable images
Image import/export
Image copy or rename
Read-only snapshots
Revert to snapshots
Ability to mount with Linux or QEMU KVM clients!
与许多当今可用的对象存储系统相比,Ceph的对象存储系统提供了一个显着的特性:Ceph提供了一个具有POSIX语义的传统文件系统接口。对象存储系统是一项重大的创新,但它们补充而不是取代传统的文件系统。随着传统应用程序对存储需求的增长,企业可以将其传统应用程序配置为使用Ceph文件系统!这意味着您可以为对象,数据块和基于文件的数据存储运行一个存储群集。
Ceph的文件系统运行在提供对象存储和块设备接口的同一个对象存储系统之上。Ceph元数据服务器群集提供了一种将文件系统的目录和文件名映射到存储在RADOS群集中的对象的服务。元数据服务器集群可以扩展或收缩,并且可以动态地重新平衡文件系统以在集群主机之间均匀分配数据。这确保了高性能并防止集群内特定主机的负载过重。
优点
为任务关键型应用提供更强大的数据安全性。
为文件系统提供几乎无限的存储。
使用文件系统的应用程序可以使用Ceph FS和POSIX语义。无需整合或定制!
Ceph自动平衡文件系统以实现最高性能。
所有 Ceph 部署都始于 Ceph 存储集群。一个 Ceph 集群可以包含数千个存储节点,最简系统至少需要一个监视器和两个 OSD 才能做到数据复制。Ceph 文件系统、 Ceph 对象存储、和 Ceph 块设备从 Ceph 存储集群读出和写入数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号