Ubuntu Hadoop集群 安装与使用
参考资料
主要参考:Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0(2.7.1)/Ubuntu14.04(16.04)
Ubuntu下 hadoop的安装与配置
主要参考:ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境
Apache Hadoop 分布式集群环境安装配置详细步骤
实验环境
两个虚拟机Ubuntu
Hadoop
Java
SSH
主要步骤
选定一台机器作为 Master
在 Master 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
在 Master 节点上安装 Hadoop,并完成配置
在其他 Slave 节点上配置 hadoop 用户、安装 SSH server、安装 Java 环境
将 Master 节点上的 /usr/local/hadoop 目录复制到其他 Slave 节点上
在 Master 节点上开启 Hadoop
准备步骤
配置 hadoop 用户
sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
sudo adduser hadoop sudo #为hadoop用户增加管理员权限
su - hadoop #切换当前用户为用户hadoop
sudo apt-get update #更新hadoop用户的apt,方便后面的安装

安装SSH server
sudo apt-get install openssh-server #安装SSH server
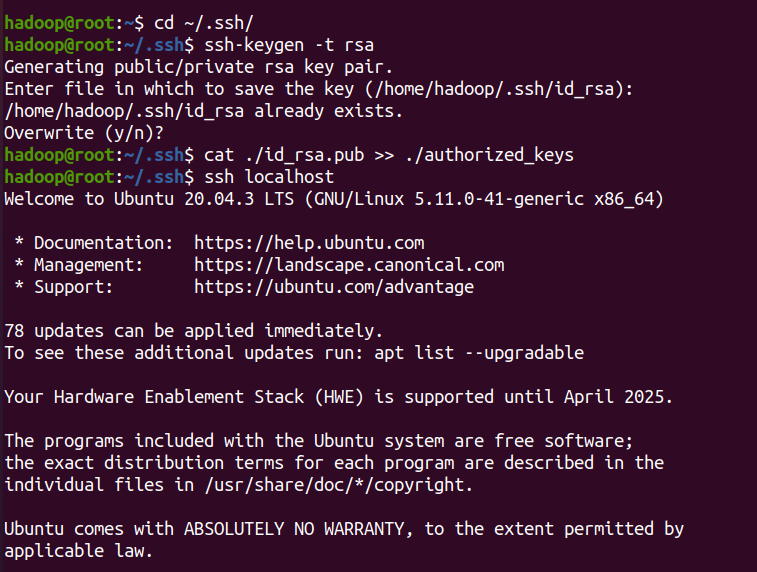
ssh localhost #登陆SSH,第一次登陆输入yes
exit #退出登录的ssh localhost
cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
ssh-keygen -t rsa
安装Java环境
第一种方式,手动安装
第二种方式
sudo apt-get install openjdk-8-jdk # 安装
vim ~/.bashrc # 配置环境变量
在文件最前面添加代码
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
保存并退出
source ~/.bashrc # 使配置生效
用 java -version 查看是否安装成功


下载错了的删除指令sudo apt-get remove openjdk*
安装Hadoop
cd /usr/local/
sudo wget https://mirrors.cnnic.cn/apache/hadoop/common/stable2/hadoop-2.10.1.tar.gz
sudo tar -xvf hadoop-2.10.1.tar.gz
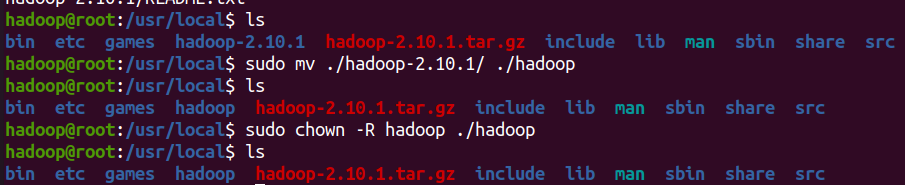
sudo mv ./hadoop-2.10.1/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
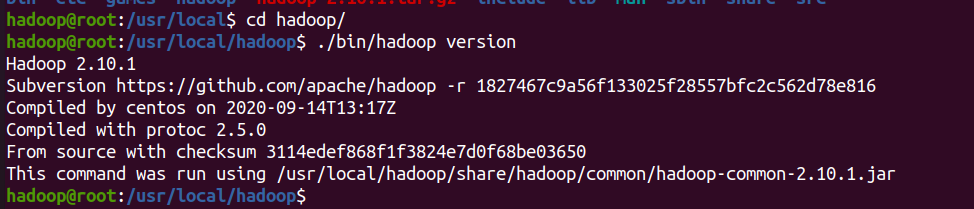
cd /usr/local/hadoop
./bin/hadoop version # 如果成功会显示hadoop版本号
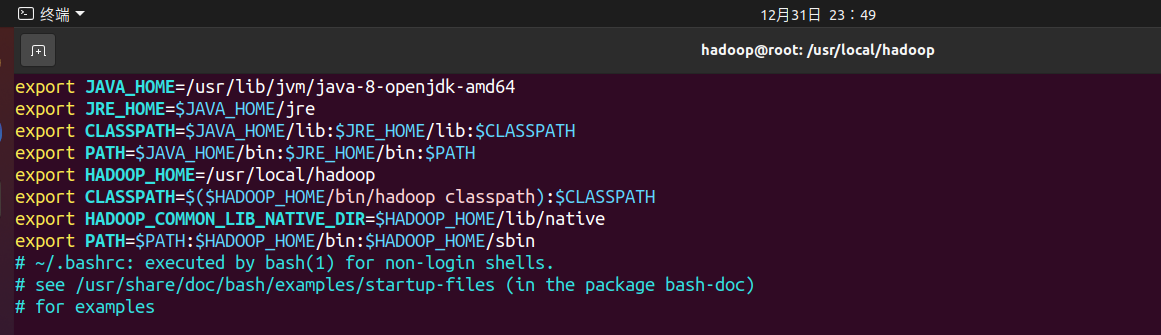
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
使配置生效source ~/.bashrc
检查是否安装成功
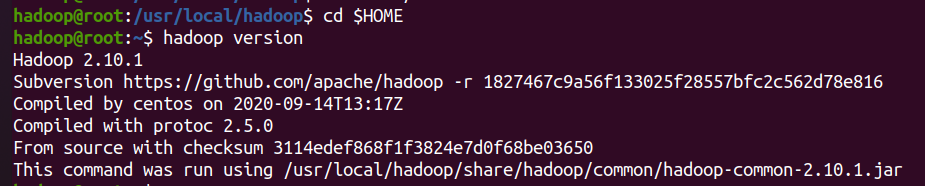
在另一台虚拟机上也同样进行上面四步
搭建Hadoop集群环境
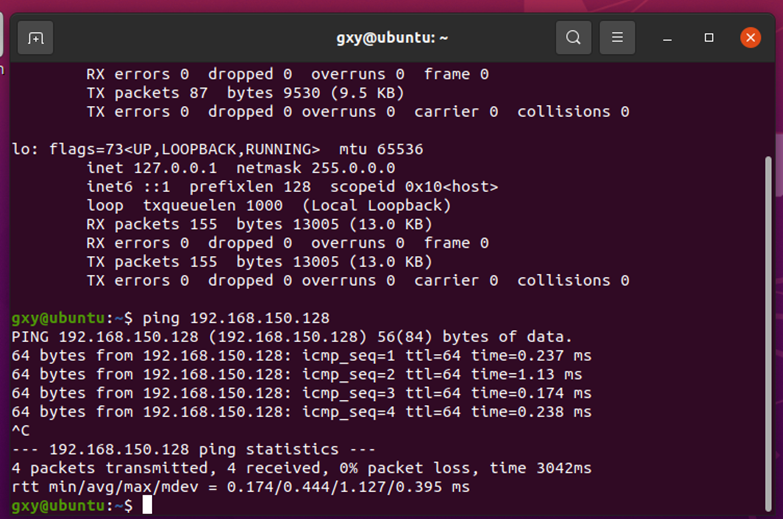
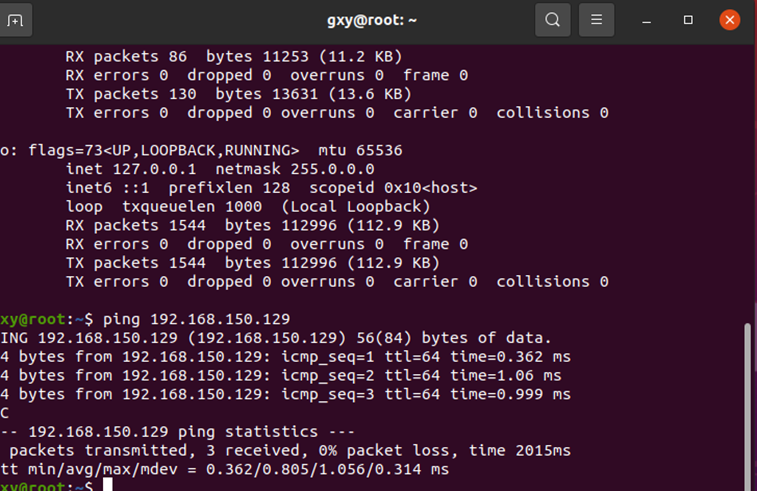
两台虚拟机相互ping通
https://blog.csdn.net/sinat_41880528/article/details/80259590
配置两台虚拟机
设置桥接模式
关闭防火墙 sudo ufw disable
两台虚拟机分别设置自动获取ip地址
vim /etc/network/interfaces
添加代码
source /etc/network/interfaces.d/*
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet dhcp
ifconfig查看ip地址
重启,互相ping一下
在虚拟机上打开ssh,两台虚拟机都要打开22端口,用exit可以退出ssh
sudo apt-get install openssh-server
sudo apt-get install ufw
sudo ufw enable
sudo ufw allow 22
在Master结点上完成准备工作
修改主机名
sudo vim /etc/hostname
修改所有结点名称和IP地址的映射
sudo vim /etc/hosts
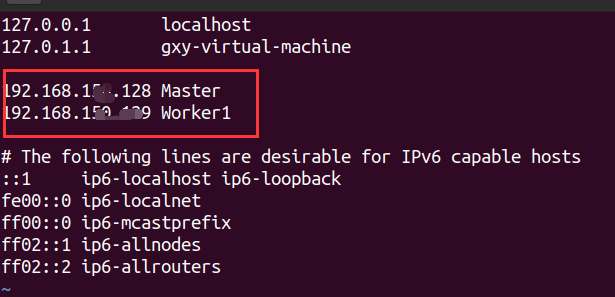
修改完需要重启
在所有节点上,都要进行这些修改
下面操作需要分在Master上操作,或者是在Worker1上操作。
在每个结点上进行ping操作
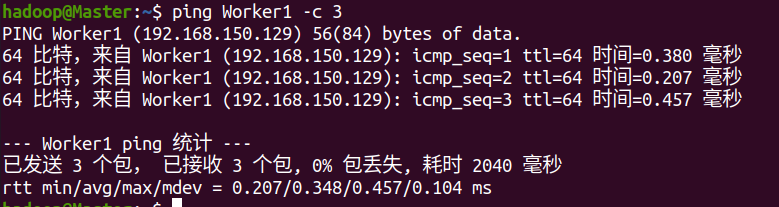
在Worker1上ping Master
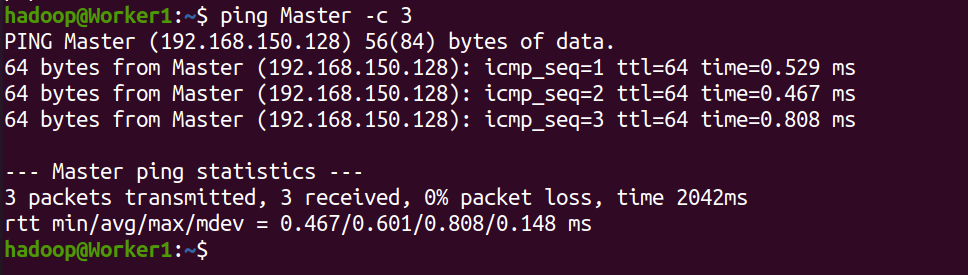
在Master上ping Worker1
SSH无密码登录结点(Master)
使Master结点可以无密码登录到各个Worker节点上
在Master结点终端执行
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
让Master无密码SSH登录本机
cat ./id_rsa.pub >> ./authorized_keys
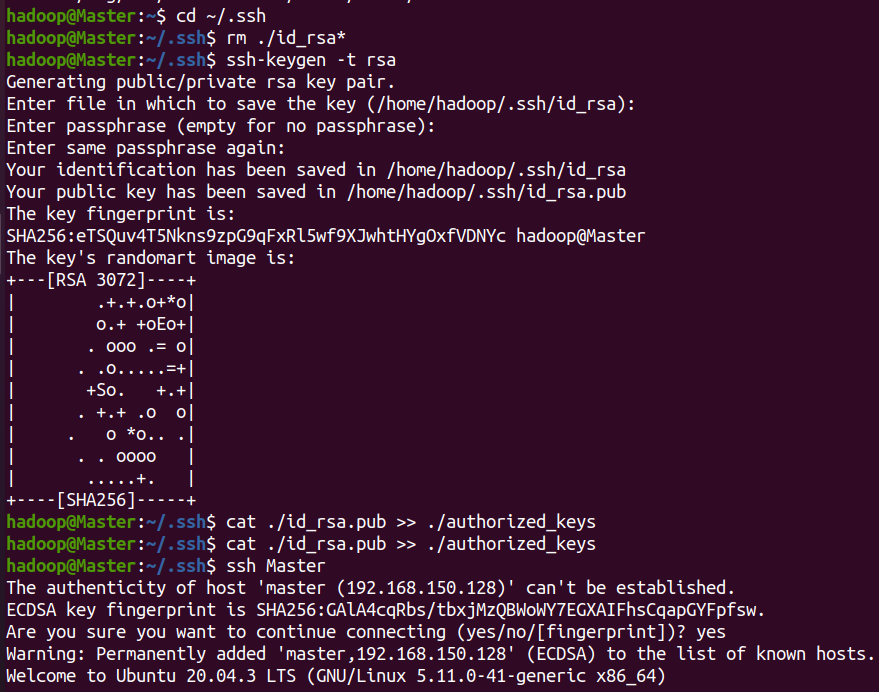
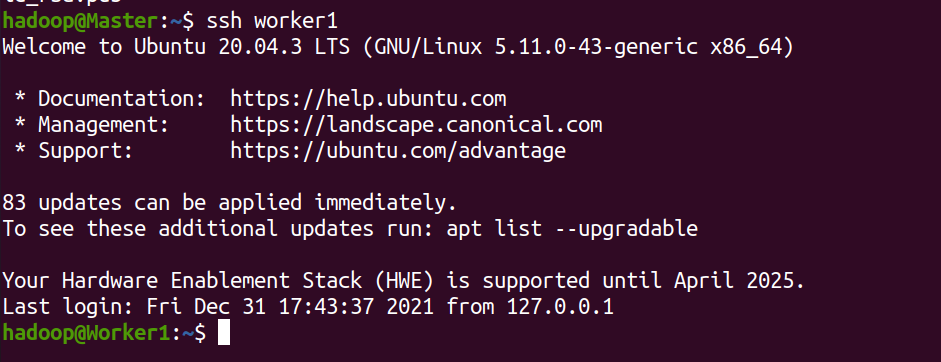
完成后可执行 ssh Master 验证一下(可能需要输入 yes,成功后执行 exit 返回原来的终端)。接着在 Master 节点将上公匙传输到 Slave1 节点:
scp ~/.ssh/id_rsa.pub hadoop@Worker1:/home/hadoop/

在Worker1结点上,将ssh公钥加入授权
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了
在Master结点上进行检验,是否可以无密码登录
Master结点分布式环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
配置文件在目录/usr/local/hadoop/etc/hadoop/下
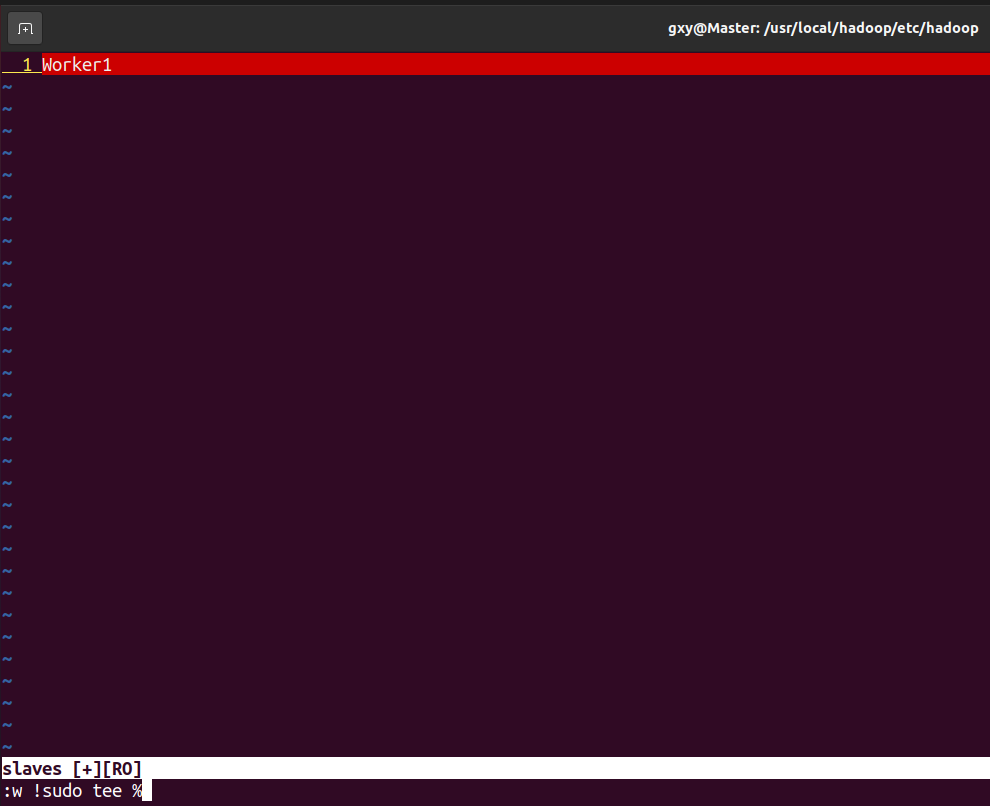
- 配置slaves文件
cd /usr/local/hadoop/etc/hadoop/
vim slaves

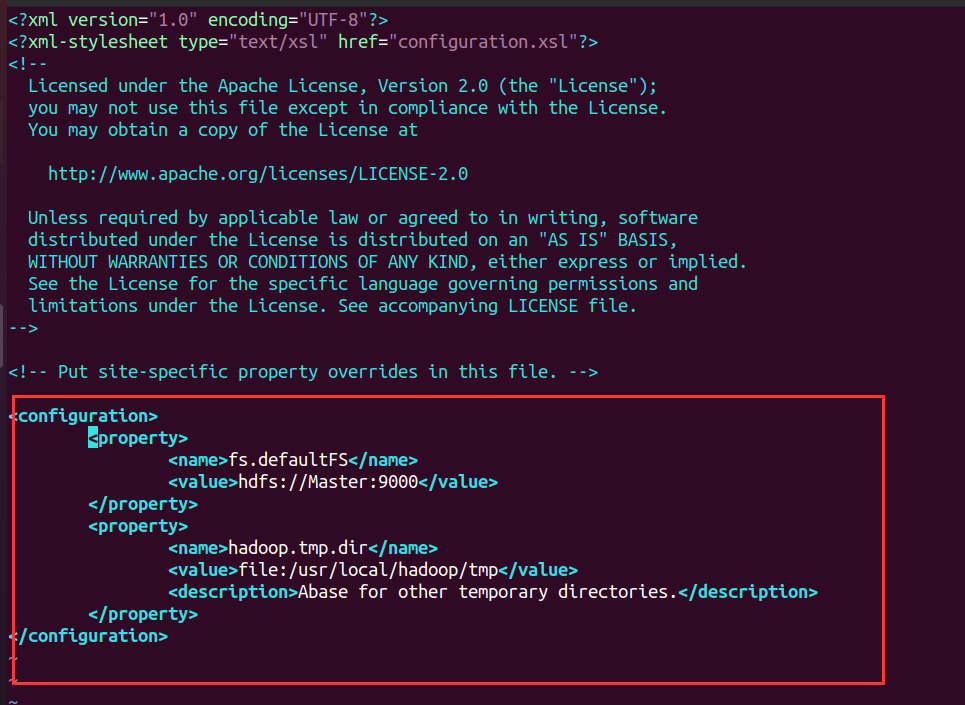
- 配置core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
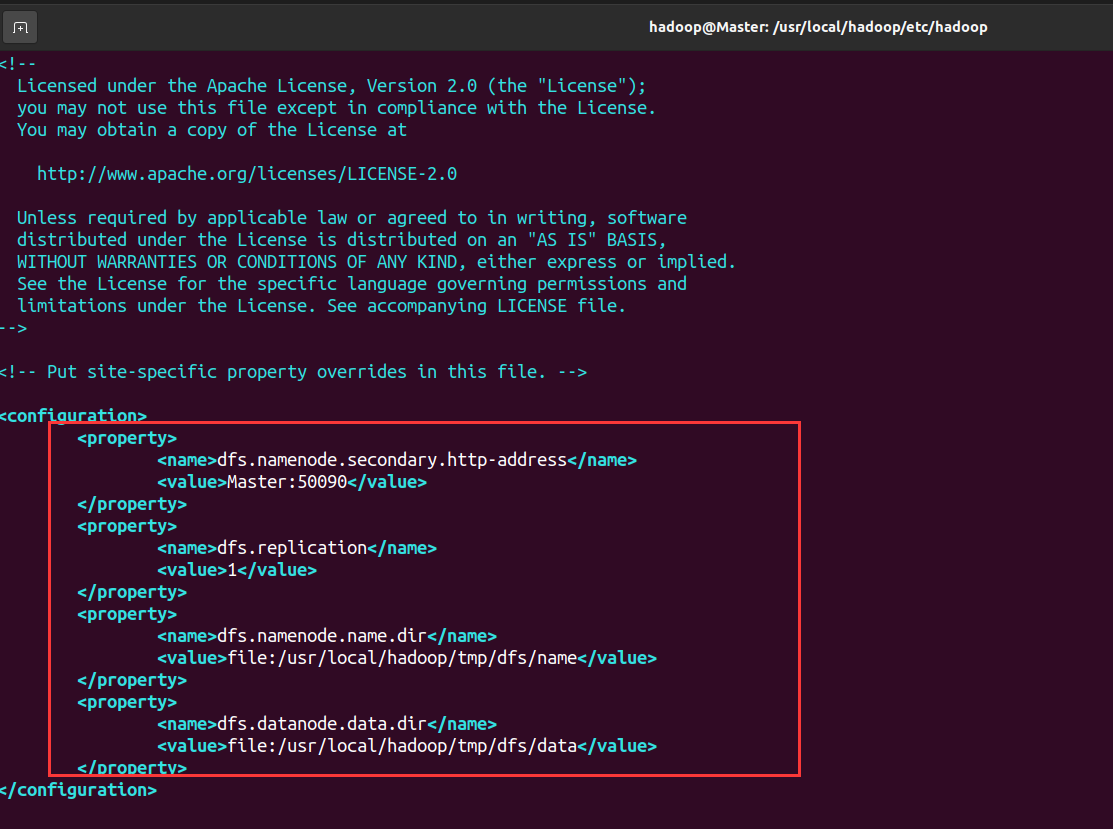
- 配置hdfs-site.xml文件,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
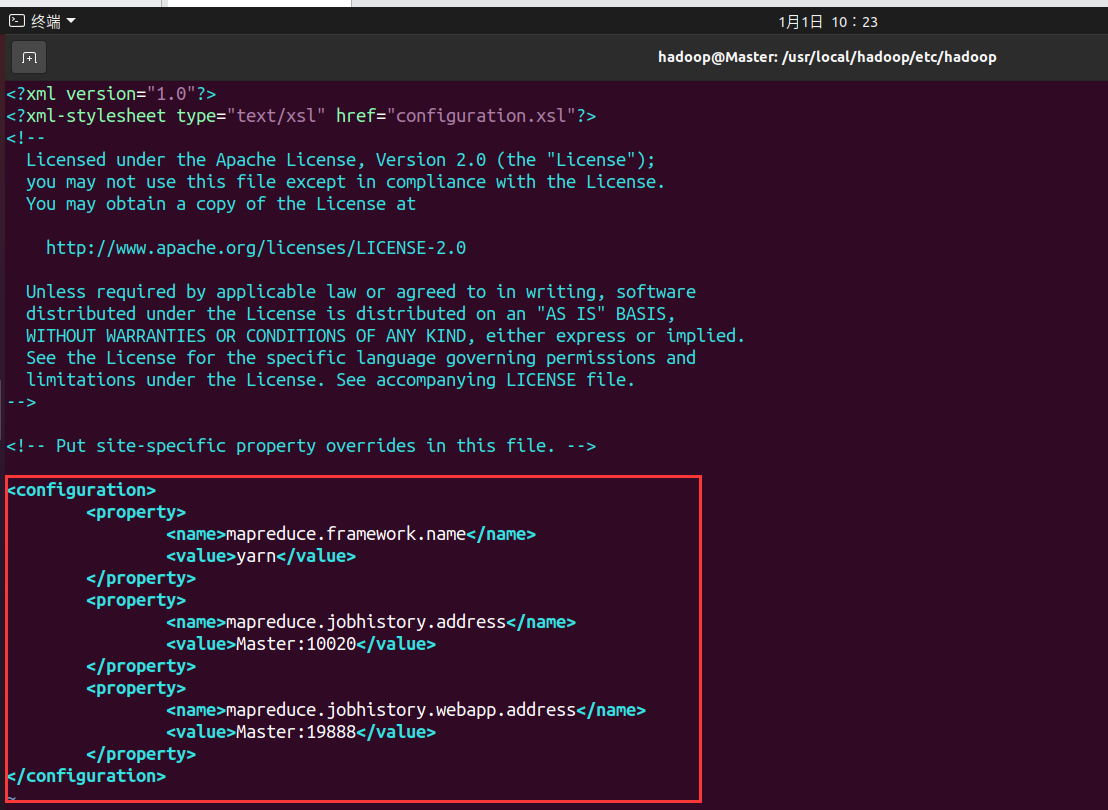
- 配置mapred-site.xml文件,(可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
重命名mv mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>
- 配置yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
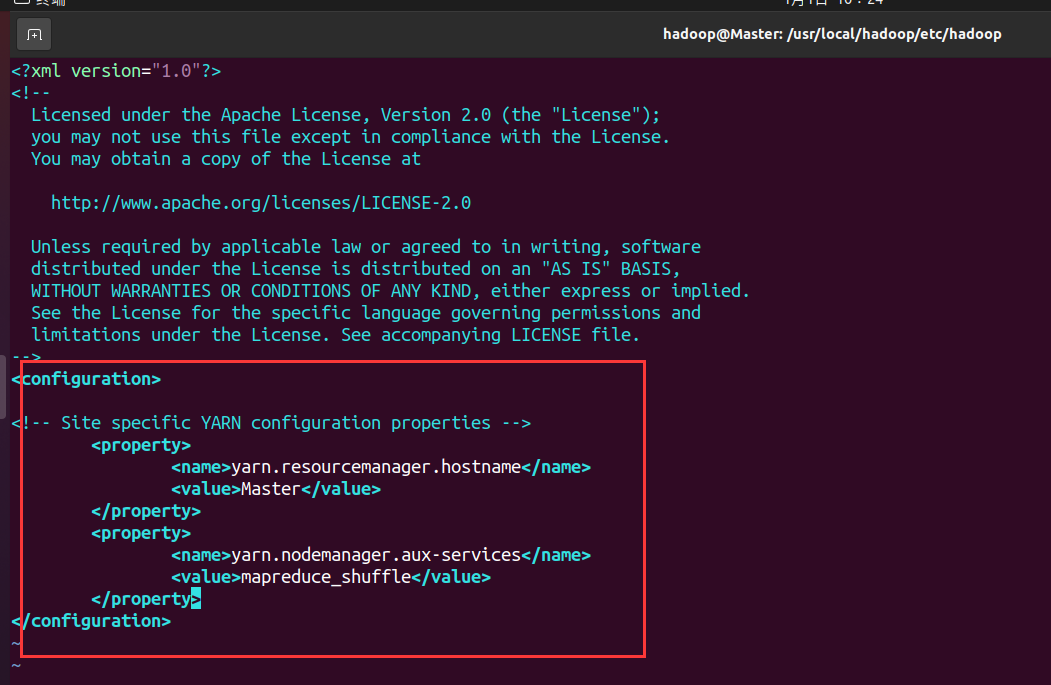
- 配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。在 Master 节点上执行
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件,没有这个文件就不用操作
sudo rm -r ./hadoop/logs/* # 删除日志文件,没有这个文件就不用操作
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Worker1:/home/hadoop # 如果有其他结点,也传到其他节点上
rm ~/hadoop.master.tar.gz # 删除压缩文件,不删也行
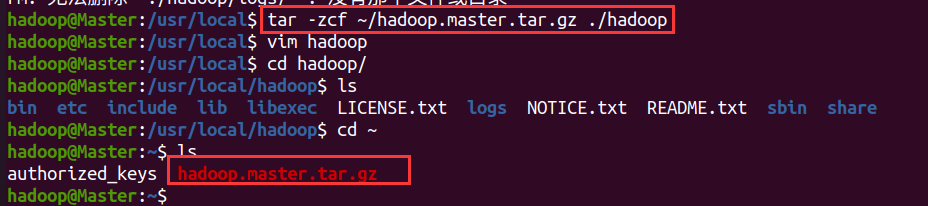

- 在Worker1结点上操作
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/hadoop
rm ~/hadoop.master.tar.gz # 删除压缩包,不删也行

启动Hadoop
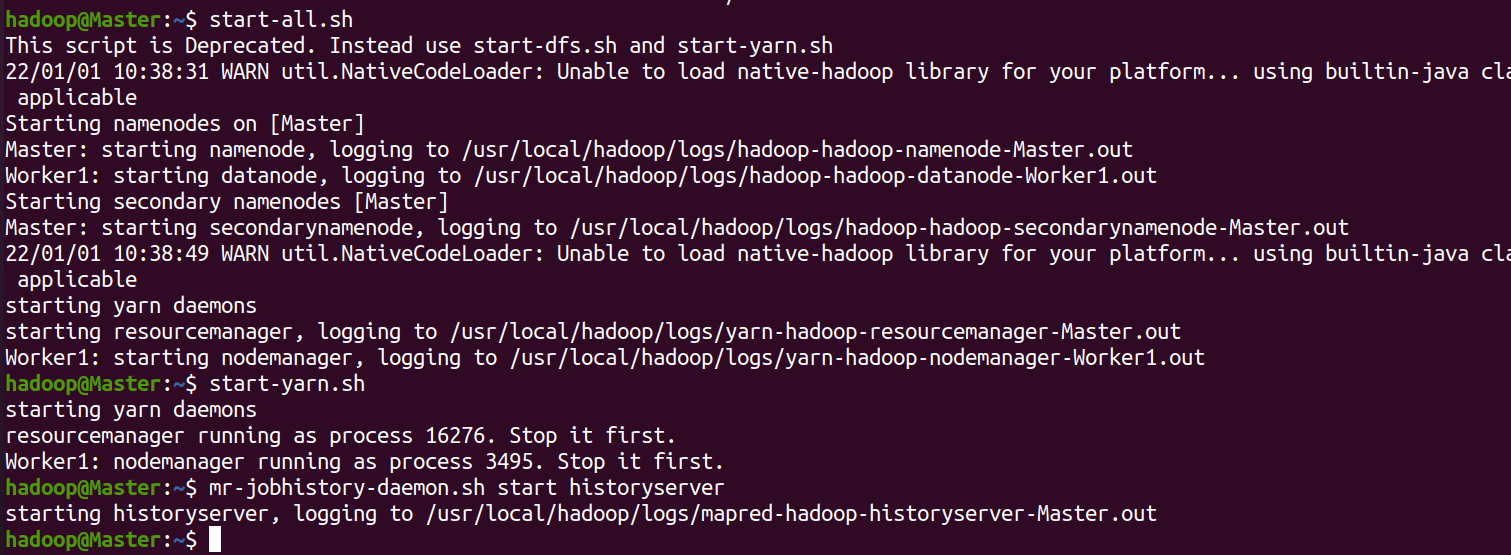
- 在Master结点上执行
首次启动需要先在 Master 节点执行 NameNode 的格式化:hdfs namenode -format
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
通过命令 jps 可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程,如下图所示:
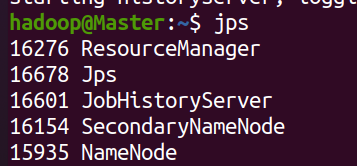
- Worker结点
在 Worker节点可以看到 DataNode 和 NodeManager 进程,如下图所示:
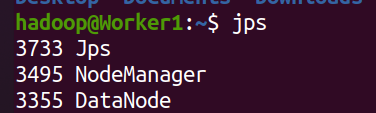
- 关闭 Hadoop集群也是在 Master节点上执行的(需要关闭时,再执行)
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
- 打开浏览器访问 http://localhost:50070 ,可以查看集群信息

运行单词计数例程
创建test.txt
vim test.txt
内容:
Hello world
Hello world
Hello world
Hello world
Hello world
下面的步骤都在/usr/local/hadoop文件夹下执行
cd /usr/local/hadoop
Hadoop创建
hdfs dfs -mkdir -p /user/hadoop # 在HDFS中创建用户目录
hdfs dfs -mkdir input # 创建input目录
hdfs dfs -put ~/test.txt input # 将本地文件上传到input里
hdfs dfs -ls /user/hadoop/input # 查看是否上传成功
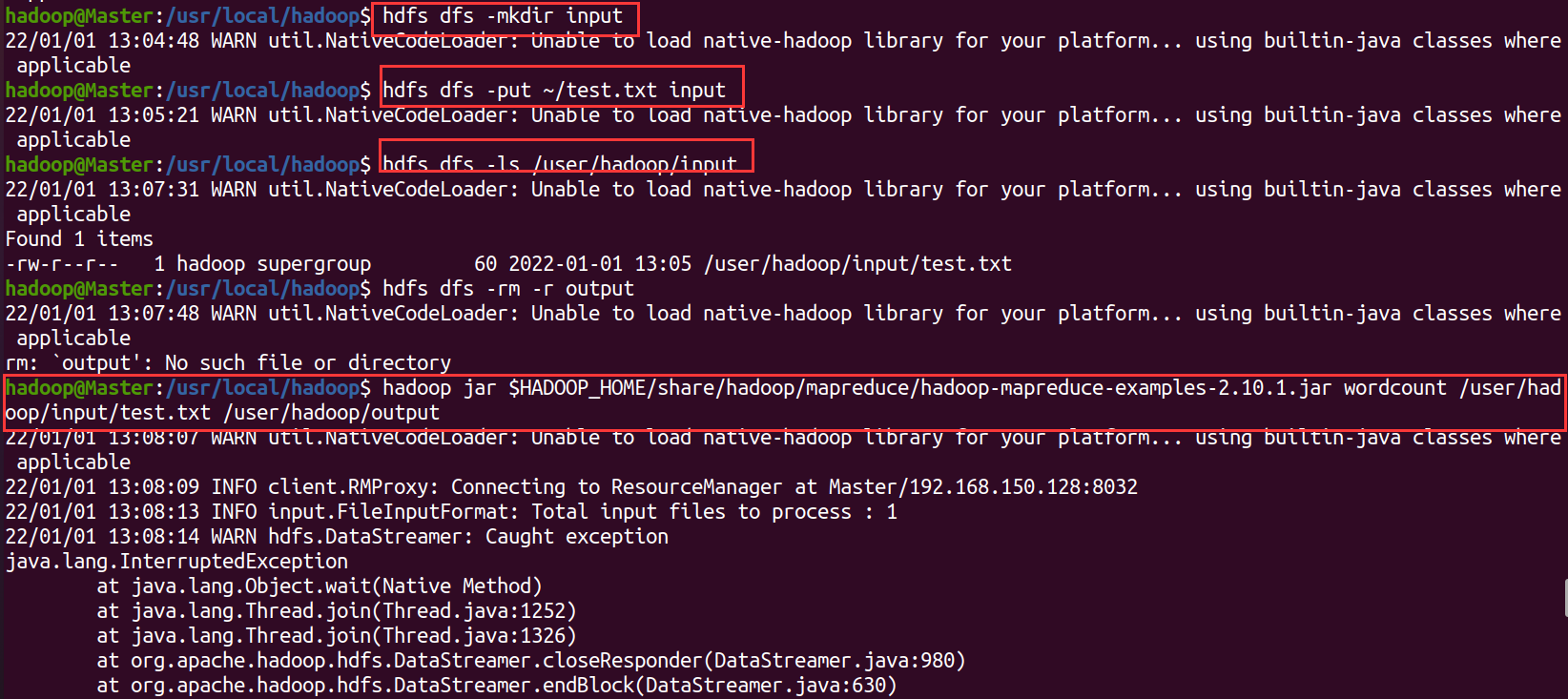
这四步命令可能出错,具体问题百度,有warning可以不用管
统计词频
hdfs dfs -rm -r output #Hadoop运行程序时,输出目录不能存在,否则会提示错误,不存在就不用删
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /user/hadoop/input/test.txt /user/hadoop/output
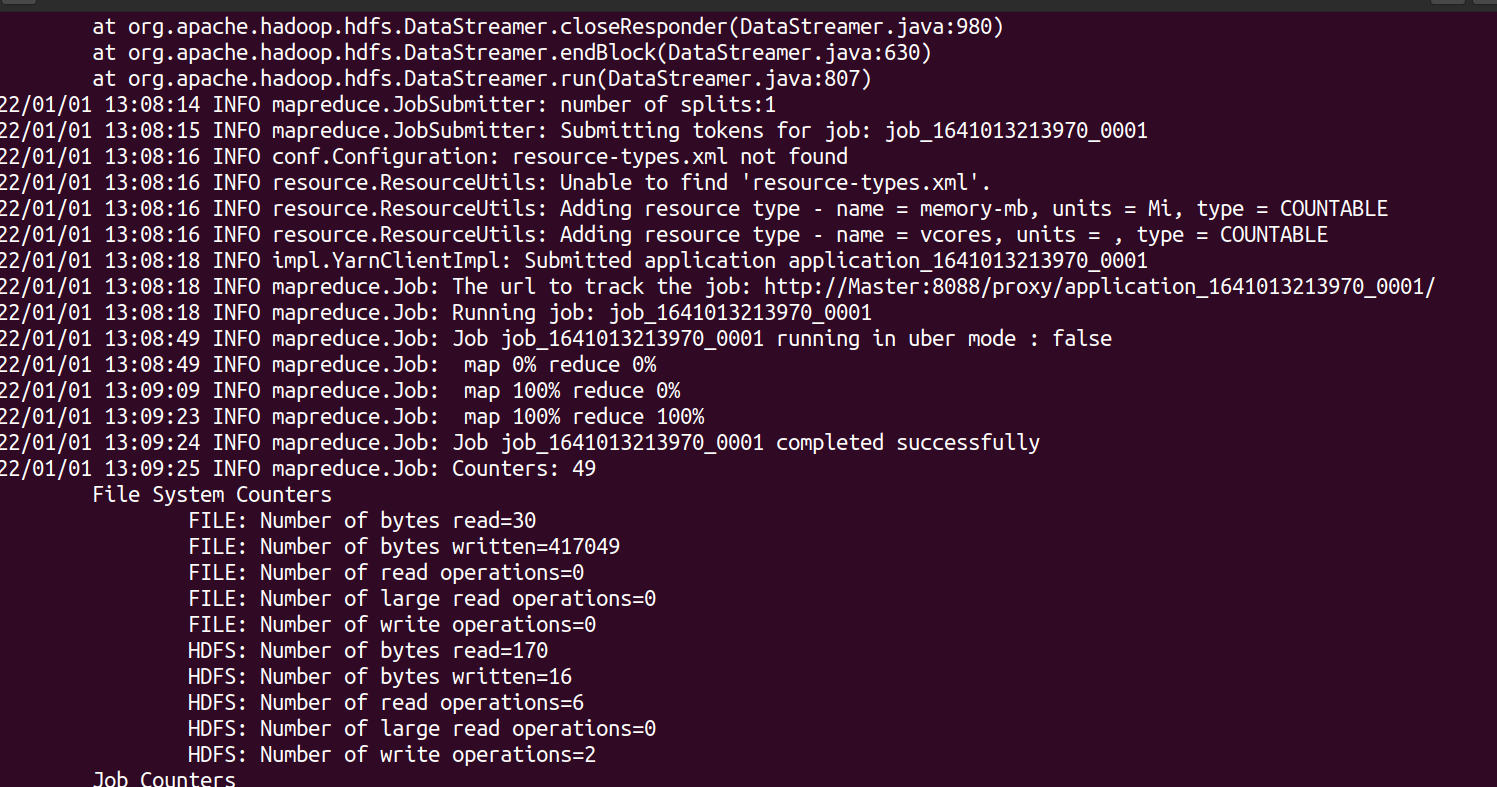
查看运行结果
hdfs dfs -cat output/*

将结果保存到本地
rm -r ./output #如果本地存在output目录,没有就不删
hdfs dfs -get output ./output
cat ./output/*

删除output目录
hdfs dfs -rm -r output
rm -r ./output
如果修改了配置文件,重新执行:配置Master结点分布式环境、启动Hadoop、 在HDFS中创建用户目录这些步骤
遇到的问题
Hadoop上传文件报错: File /user/cookie/input/wc.input.COPYING could only be replicated to 0 nodes instead
启动HIVE时报: CALL FROM HADOOP /192.168.1.128 TO HADOOP :9000 FAILED ON CONNECTION的原因之一HADOOP启动没有NAMENOD
hadoop上传文件错误org.apache.hadoop.ipc.RemoteException(java.io.IOException)
Master 和 Worker1上用jps查看进程,进程少了几个
原因:使用hadoop namenode -format 格式化多次后,导致两个虚拟机上的namespaceId不同
解决方法:
# 停止所有节点工作
stop-all.sh
# 清理hadoop运行时产生的文件tmp和logs
用rm指令删除这两个文件
# 重新进行格式化
hadoop namenode -format
# 重新启动Hadoop集群
start-all.sh
注:有错误请指出!轻喷

 浙公网安备 33010602011771号
浙公网安备 33010602011771号