
2023秋招总结
前言
这是我的2023秋招总结,分类整理了一下我遇到的面试\笔试题目。
标题之后的数字表示我大概被问到了几次,这只是一个粗略统计,但你可以通过这些数字粗略地看出这些面试题的重要程度。
如果标题之后没有数字,表示一整个秋招没有被问到这个题目,但为了完整性还是整理了
排序
排序算法复杂度 (5)
极高频度的面试题
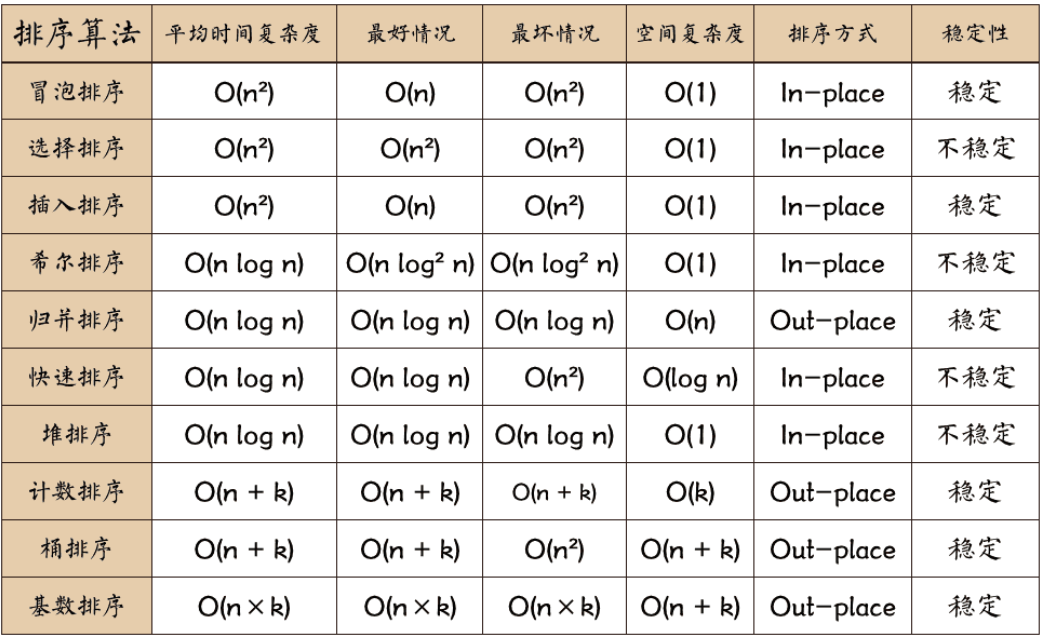
易错:
- 堆排的空间复杂度:O(1)
- 快速排序的时间复杂度 O(1)
依次介绍
冒泡 (1)
美团实习一面
当输入数组已经有序,且应用提前返回优化时,最好时间复杂度为O(n)
输入数组倒序排列时,最差时间复杂度为O(n^2)
选择排序
插入排序
当输入数组已经有序时,最好时间复杂度为O(n)
输入数组倒序排列时,最差时间复杂度为O(n^2)
数据量较小时,使用插入排序,比如stl::sort,当数据量小于16时,使用插入排序
efficient for data sets that are already substantially sorted: the time complexity is O(kn) when each element in the input is no more than k places away from its sorted position
归并排序(2)
空间复杂度为O(n),是辅助数组占大头,递归的空间复杂度为(Ologn)
快速排序(3)
非稳定算法!
当输入数组已经有序且pivot总是选择第一个时,或者输入数组元素都相同时,达到最差时间复杂度
空间复杂度为O(logn), 递归空间深度
基数排序(1)
好像是百度问的
(36条消息) 基数排序(LSD+MSD)详解_lsd基数排序_潮帅的学习空间的博客-CSDN博客
introsort
是std::sort使用的方法
Introsort - C++’s Sorting Weapon - GeeksforGeeks
STL的sort
Introsort - C++’s Sorting Weapon - GeeksforGeeks : 很好的文章
std::sort使用introsort算法,集成了quicksort、insertion sort以及heapsort。
-
为什么使用insertionsort? 因为插入排序在小数据集的情况下时间复杂度低,且对部分有序数组的排序性能很高为O(kn)。参考Insertion sort - Wikipedia
-
Quicksort vs. Heapsort | Baeldung on Computer Science : 讲了quicksort与heapsort的对比。虽然quicksort与heapsort的平均时间复杂度都是O(nlogn),但是再实践中,quicksort比heapsort快,因为heapsort的时间复杂度的常数项比quicksort大。但如果空间复杂度有要求(比如嵌入式系统),那么heapsort可能是一个很好的选择。但是为了避免quicksort的时间复杂度退化为O(n2)的情况,当递归深度超出限制时,introsort该用heapsort。
introsort的部分C++实现源码:
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first, RandomAccessIterator last) {
if (first != last) {
__introsort_loop(first, last, value_type(first), __lg(last - first) * 2); // 最大递归深度限制为 log(last - first) * 2
__final_insertion_sort(first, last); // 插入排序
}
}
template <class Size>
inline Size __lg(Size n) {
Size k;
for (k = 0; n > 1; n >>= 1) ++k;
return k;
}
//
template <class RandomAccessIterator, class T, class Size>
void __introsort_loop(RandomAccessIterator first,
RandomAccessIterator last, T*,
Size depth_limit) {
while (last - first > __stl_threshold) { // __stl_threshold = 16,即当元素个数大于16时一直递归
if (depth_limit == 0) {
partial_sort(first, last, last); // 堆排序
return;
}
--depth_limit;
RandomAccessIterator cut = __unguarded_partition
(first, last, T(__median(*first, *(first + (last - first)/2),
*(last - 1)))); // quicksort的partition操作
__introsort_loop(cut, last, value_type(first), depth_limit);
last = cut;
}
}
template <class RandomAccessIterator, class T>
void __partial_sort(RandomAccessIterator first, RandomAccessIterator middle,
RandomAccessIterator last, T*) {
make_heap(first, middle);
for (RandomAccessIterator i = middle; i < last; ++i)
if (*i < *first)
__pop_heap(first, middle, i, T(*i), distance_type(first));
sort_heap(first, middle);
}
template <class RandomAccessIterator>
inline void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last) {
__partial_sort(first, middle, last, value_type(first));
}
std::sort是非稳定的,也有稳定的排序算法,即std::stable_sort
数据结构与算法
堆
- 将一个数组调整为大根堆,最后能够得到的数组序列
- 将一个元素插入大根堆,需要比较的次数?
似乎都和siftdown操作有关?
在大数组中找到最大的k个数(3)
科大讯飞提前批一面
最小堆
建堆的时间复杂度(1)
O(n)
树
满二叉树和完全二叉树(1)
科大讯飞提前批一面
它们的区别
平衡二叉树
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过1,和红黑树相比,AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差的绝对值不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道AVL树适合用于插入与删除次数比较少,但查找多的情况
由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多,更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果应用场景中对插入删除不频繁,只是对查找要求较高,那么AVL还是较优于红黑树。
原文链接:https://blog.csdn.net/u010899985/article/details/80981053
红黑树性质
- 每个节点非红即黑
- 根节点是黑的;
- 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
- 如图所示,如果一个节点是红的,那么它的两儿子都是黑的;
- 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
性质:红黑树是一种*弱*平衡二叉树,最长的路径不超过最短路径的两倍(最短的路径必然都是黑色节点,最长的路径是红黑相间,又由于4,5,那么最长路径一定是最短路径的2别)
最小生成树
调整过程
(36条消息) 平衡二叉树的调整(详解 LL、RR、LR、RL)_ll lr rl rr_Hairui瑞的博客-CSDN博客
哈夫曼树(5)
笔试很常见
可以看一下学院派的课程恶补一下
hash表
hash表实现(5
如何处理hash冲突?(2
美团实习一面 :如果使用开链法,那么链表元素过多的情况下有什么优化措施? -- 将链表换成红黑树
时间轮算法(1)
一个游戏公司的二面,忘了叫啥,是做咸鱼之王的那个公司
优缺点是什么
[游戏定时器算法-简单时间轮 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/628043114#:~:text=执行时间轮的时间复杂度:O (1) ~ O,(n) 优缺点 优点:占用资源少、简单 缺点:不能延时超过最大刻度,需要升级为多重时间轮 空间占用较大,时间轮需要维护一个定时任务队列,当任务数量比较大时,会占用较多的空间。)
数据库
mysql执行一条语句的流程(1)
忘了谁问的了
可以参考极客上面的一篇教程,较详细
索引下推
参考了小林coding的资料
相关关键词:联合索引
直接在联合索引中判断另一个条件,而不是回表到主键索引中再判断

回表
相关词汇:二级索引
索引有聚簇和非聚簇索引之分,非聚簇索引就是二级索引。
回表指:从二级索引中得到主键后,再次查询聚簇索引
覆盖索引
相关词汇: 二级索引、回表
“如果覆盖索引了,那么就不用回表了”
最左匹配原则
相关关键词:前缀索引, 索引失效
在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效
Q1:
select * from t_table where a > 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
只有a
Q2:
select * from t_table where a >= 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
a和b,当 a = 1的记录中,是按b排序,所以这里能用到b索引
Q4:
SELECT * FROM t_user WHERE name like 'j%' and age = 22,联合索引(name, age)哪一个字段用到了联合索引的 B+Tree?
name 和 age都用到了
索引失效
- 当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
请见:[MYSQL | 最左匹配原则的原理-腾讯云开发者社区-腾讯云 (tencent.com)](https://xiaolincoding.com/mysql/index/index_lose.html)
高频面试题-mysql索引失效的情况_牛客网 (nowcoder.com)
B+树相对于平衡二叉树
二叉树太高了,B+树相对矮胖。找到一个节点,B+树需要经过的节点数更少,而内容存储在磁盘上,因此也会对磁盘的随机存取操作会更少。
且一个B+的节点存储的内容比二叉树多,因此总的磁盘读取操作也会减少,因为磁盘市按ye
B+树对于B树(1
美团一面:B+树与B树各自的优劣势

存储形式:
B树:每个节点都存储完整的记录。
B+树:非叶子节点只存储索引记录,叶子节点存储完整记录。
所以:依次IO 能B+中获取更多的节点,反过来也就是说B+树节省IO
范围查询:
B树:需要中序遍历(B树本质是一个二叉树),可能涉及到随机IO
B+树:访问到头尾节点,然后顺序IO
且顺序IO的耗时小于随机IO,所以:B+树更加节省IO次数。
插入和删除操作:
B树:没有冗余节点,所以需要维护树的形状,可能涉及到很多树的变形
B+树:存在冗余节点,且只需要在叶子节点中增加/删除,额外的维护操作少了很多
B树相对于B+树的优势
为什么 MongoDB 使用 B 树?-mongodb为什么用b树不用b+树 (51cto.com)
B数在单点查询上更有优势
聚簇索引和非聚簇索引

常见的Join算法,以及它们的优势和选用场景(1)
美团二面,被问懵了,没怎么准备
参考资料:
- CMU 15-445/645 Database Systems (Fall 2022) :: Join Algorithms
- MySQL :: Hash join in MySQL 8
- Mysql几种join连接算法-腾讯云开发者社区-腾讯云 (tencent.com)
nested loop join : 太慢,所以有了几种优化算法:
Block Nested Loop Join, 通过一次缓存多条数据批量匹配的方式来减少外层表的循环次数INdex Nested Loop Join:通过索引的机制减少内层表的循环次数
sort join :当输入本身有序,或者要求求过有序时,可以使用sort join
hash join :大部分情况下优于sort join。而且如果系统知道了外表的大小,它可以使用静态hash表,如果不知道的话就只能使用动态hash表。但是hashjoin只能用于等值连接!!
mysql直到8.0之前还没有使用hashjoin,大多是使用nested loop jion 和 其优化算法。
总结:

select(*) 和 select(1)的区别?(1)
select(*) 返回所有表s护具
select(1) 返回1,没有遍历表的操作
linux
常见命令(2)
问的也比较多
-
管道、重定向(输出调试日志的时候常用)
-
grep命令,经常配合ps和管道命令一起用,找到特定的用户进程
-
free命令可以查看剩余的实际物理空间和剩余的swap空间
-
top命令,也能查看剩余的实际物理空间和剩余的swap空间。
- 也可以查看进程使用的虚拟地址总量, 进程优先级、nice值, CPU占用率、内存占用率等。
-
man
-
cat /proc/
pidstat 查看进程自愿和非自愿的上下文切换次数(1)
pidstat - linuxcmd - 博客园 (cnblogs.com)
该命令能够查看进程自愿和非自愿的上下文切换速度
time命令也可以看
缓存命中率怎么看(1)
/proc/ 目录 (1)
忘了谁问的了,好像是自己主动提的
linux目录结构(1
由规定FHS(Filesystem Hierarchy Standard)
Linux Filesystem Hierarchy (tldp.org)
(36条消息) 深入理解linux系统的目录结构(总结的非常详细)_linux 目录结构_通幽通明的博客-CSDN博客
【基础知识】Linux文件目录结构一览表 - 腾讯云开发者社区-腾讯云 (tencent.com)
| 一级目录 | 功能 |
|---|---|
| /bin/ | 存放系统命令,普通用户和root都可以执行。比如cat 、ls 、bash、echo、grep、mkdir等常见命令都在这个目录下 |
| /home/ | 普通用户的主目录。比如/home/ljc /home/ubuntu。 通常在此目录下存储用户的数据。 特别的 ~ 表示当前用户的home目录 |
| /sbin/ | 存放只有root才能运行的一些指令,这些指令用来设定系统环境 |
| /lib/ | The /lib directory contains kernel modules and those shared library images (the C programming code library) needed to boot the system and run the commands in the root filesystem, ie. by binaries in /bin and /sbin. |
| /usr/ | 该目录包含了linux上最多的共享数据。全称为Unix Software Resource。应把软件产品的数据合理的放置在 /usr 目录下的各子目录中,而不是为他们的产品创建单独的目录 |
| 二级目录 | 功能 |
|---|---|
/usr/bin |
存放了系统上的大部分二进制文件、可执行文件。比如gcc、vi、ld、apt、ar等。当我们在shell中敲打一个命令比如gcc时,系统将根据#PAHT变量保存的路径到各种目录中搜寻该命令,而/usr/bin则是#PATH变量中的一个常见搜索路径。这也是为什么我们在使用一些系统命令时,用不着键入绝对路径的原因。但反过来说,如果没有#PATH变量,或者#PATH变量没有/usr/bin路径,那么单单键入vi是没用的,必须写 /usr/bin/vi 才可以 |
| /usr/include | The directory for 'header files', needed for compiling user space source code. 比如C/C++等编程语言头文件的防止目录。 |
| /usr/local | 可以用来存放手动安装的软件,一般建议源码包软件安装在这个位置 |
| /usr/lib | 存放各软件\命令的库函数 |
| /usr/share | 存放的几乎都是文本。常见的有/usr/share/man /usr/share/info 等帮助文档 |
操作系统
printf函数在内核所作的工作
首先printf会调用一次vprintf函数,该函数比较长,主要作用是将字符串中的占位符替换为真正的字符串。该函数依然位于C的库函数中。
然后会使用系统调用sys_write将字符串打印在控制台。这一步骤就是内核所作的工作。
内核所作的工作大致有二:
- 将控制台抽象成一个文件,这样sys_write就能使用一个文件描述符进行write、read等操作
- 底层驱动的控制,具体来说是对显卡的控制。内核将操作显卡的函数赋值给file结构的file_operations结构,这vfs就可以调用file->fop->write函数去打印字符串了。
标准输出的的文件描述符为1,该文件描述符是在程序运行之前就建立的。因为大多数用户程序通过shell程序调用fork+exec执行,而fork又会将父进程的文件描述符赋值到子进程,因此只要shell进程事先打开了标准输入、标准输出这两个文件,用户程序也就自动打开了。
linux文件 、 设备、 设备树?(1
字节实习一面,了解设备树吗 ? ——不了解
缓冲区溢出?(1
字节实习一面
基于栈的缓冲区溢出
-
可能的发生原因:strcpy 函数,可能覆盖return address,然后转而执行其他程序。

但为什么栈的内存有执行权限?把它改成不可执行不就可以预防了吗?
-

现在gcc的stack似乎默认为不可执行。
在发展历史中,为什么不一开始就将其设为不可执行呢?有什么其他需求,要求stack段是可执行吗?---有,这里就不展开了
而且即时将栈设置为不可执行,任然是不安全的,见下面的讨论
-
-
基于栈的shellcode缓冲区溢出攻击::: Phrack Magazine ::. 和W8 L3 Buffer Overflow Attacks - YouTube 详细讲了如何攻击
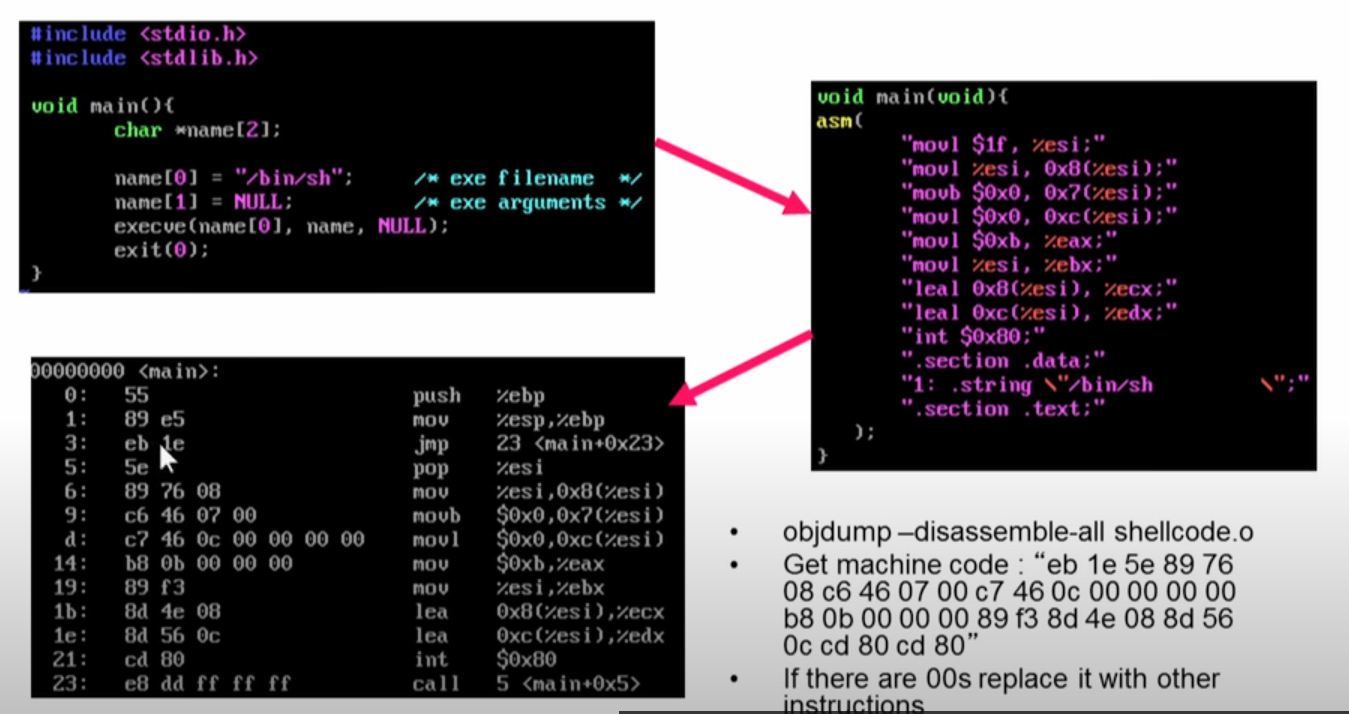
基于栈的缓冲区溢出攻击的预防措施:
-
使栈
不可执行,但这种方法与操作系统提供的功能相关:
但是有些程序需要stack可执行!比如 linux signal delivery?
-
但即使栈不可执行,仍然会遭到基于栈的缓冲区攻击,被称作:
return to libc attack,它依然能够在栈被标记为不可执行的程序中实现攻击。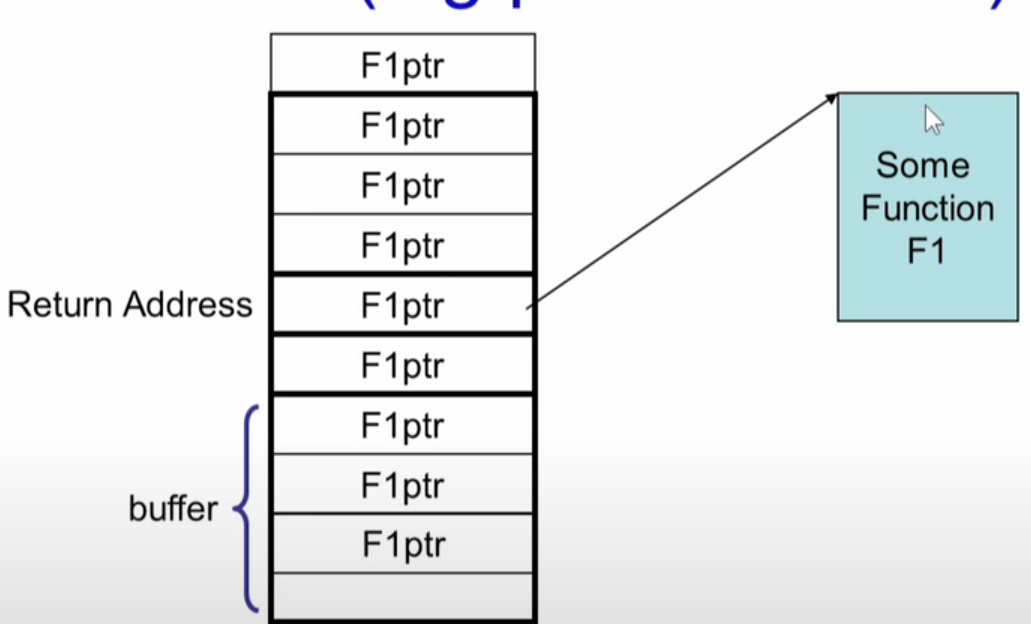
some function f1一定是
在代码段中已经存在的、合法的一段函数程序,比如system库函数:
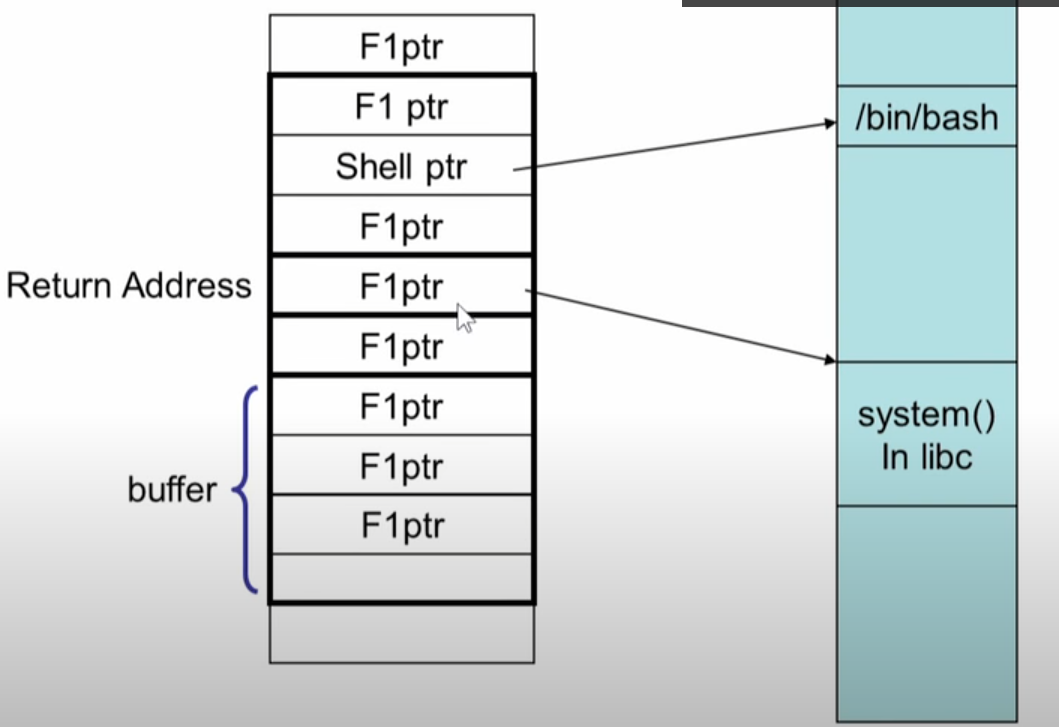
-
introduce randomization to the memory space of the executing program

就比如执行shellcode的攻击,我们需要直到stack在内存中的位置,才能知道被溢出的buffer存放在何处。下面是.:: Phrack Magazine ::.论文中的描述:

所以如果栈的地址是随机的话,那么攻击者也很难猜到buffer存放在哪里
-
Canaries:改变栈帧的结构,在其中加上一个guard变量,每次返回前都要检查这个数字是否与之前相同,如果不同,那么就说明这个数字被覆盖率,那么很有可能return address也覆盖了。这个guard变量的具体值应是随机的。g++编译器默认实现了这样的防御措施,当然它的实现要比这个复杂很多。
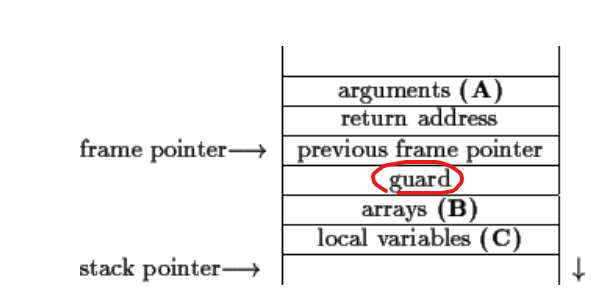
-
不用strcpy 改用strcpy_s, 后者规定需要复制的字符个数。
W8 L3 Buffer Overflow Attacks - YouTube(直观易懂)
W8 L4 Preventing Buffer Overflow Attacks - YouTube(直观易懂)
.:: Phrack Magazine ::.(讲了具体如何产生一个缓冲区溢出攻击,主属于修改返回地址的栈溢出攻击类型)
Stack buffer overflow - Wikipedia
Buffer overflow protection - Wikipedia
Protecting from stack-smashing attacks (archive.org)
死锁产生的4个条件(2
- 互斥:线程之间需要互斥地堆资源进行访问
- 非抢占:资源被线程获得后,不可被剥夺
- 持有并等待:线程持有一个资源,又等待另一个资源
- 循环等待:A线程等待B线程占有的资源,B线程等待C线程占有的资源。。。Z线程等待A线程占有的资源
大小端(5
面试笔试都很常见
小端:数据的低位在低地址
大端:数据的低位在高地址
写一个判断程序:
#include <iostream>
using namespace std;
int main() {
unsigned short a = 0x0001;
unsigned char* aptr = (unsigned char*)&a;
if (aptr[0] == 0x01) {
cout << "小端\n";
}else {
cout << "大端\n";
}
return 0;
}
分页与分段(2
美团实习一面
- 为什么分页、分段? -- 粒度、内存利用率
操作系统 虚拟内存 、分段、分页的理解 - myseries - 博客园 (cnblogs.com)
Difference Between Paging And Segmentation // Unstop (formerly Dare2Compete)
- linux x86还用分段吗?用,由于历史原因,为了保证兼容性,x86现在分页前先进行分段。
读取文件的具体流程(1)
美团实习一面,从系统调用具体到磁盘block。紧接着问了Linux的page cache,当时还不了解,没答上。
page cache?(2)
美团实习一面,问了解 page_cache不,有什么作用,没答好
科大讯飞一面
浮点数如何存储(1
2.7 为什么 0.1 + 0.2 不等于 0.3 ? | 小林coding (xiaolincoding.com)
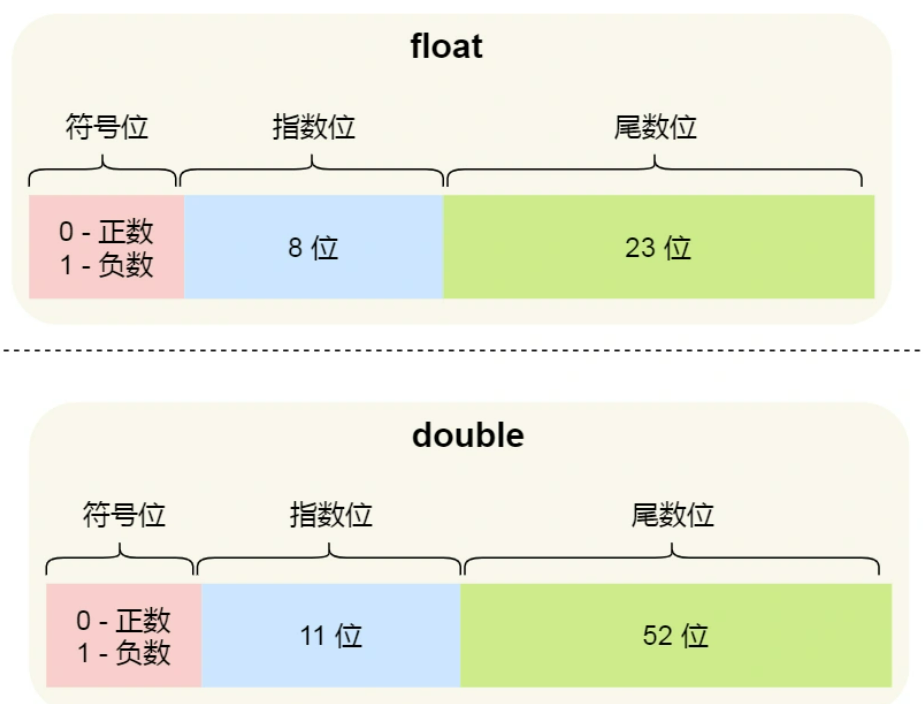
而我们二进制只能精准表达 2 除尽的数字 1/2, 1/4, 1/8,但是对于 0.1(1/10) 和 0.2(1/5),在二进制中都无法精准表示时,需要根据精度舍入。
宏内核与微内核的优势劣势?(1
微内核涉及到更多的进程切换,因此微内核相对来说效率更慢些。
软硬中断的区别(1)
如何防止死锁 (1)
注意加锁顺序
NUMA(1)
科大讯飞 : 了解NUMA吗?代码层面如何利用NUMA?
进程间通信效率对比
匿名管道、有名管道、TCP、UDP的对比 : 数据量较小时,管道的效率比socket高;数据量大时,socket的效率高。 (管道的缓冲区是有限的,通常2个PAGE_SIZE, 用完了就得阻塞进程然后等待。
网络编程:进程间通信性能比较 - 知乎 (zhihu.com) : 数据量大是socket的效率最高,因为共享内存需要额外加锁,效率最低。
进程和线程的区别(3)
问得确实挺多的。
进程是资源分配的最小单位,线程是任务调度和执行的最小单位。
-
创建线程的时间比创建进程的花费少
-
线程切换比进程切换的开销少
-
线程间共享数据比进程间共享数据简单
Linux早期版本不区分线程进程,调度器只能看到task_struct,这就表示了一个可调度实体,task_struct的pid_t就是一个可调度实体的唯一标识。
但Posix要求实现线程,要求所有线程调用getpid函数是返回相同进程的id。Linux为了满足标准,在taskt_struct中又加入了一个属性pgid_t,即线程组id。
包含多线程的进程又被称作线程组,这些线程组的第一个线程称为主线程,其他线程的pgid_t等于主线程的pid。另外task_struct中有group_leader这个结构指向线程组的主线程的task_struct。
所以当用户在一个线程中调用getpid(获取进程id)时返回的时pgid_t,调用gettid(获取线程id)时返回的时pid_t。
操作系统比较卡的原因有些什么?如何排查?(1)
科大讯飞正式批一面
软件中断与硬件中断(1)
硬件中断:有CPU或者连接到CPU的外围设备差生的中断,前者通常是一些异常,后者则是设备中断,比如鼠标、键盘等。
混淆的点: 也有资料将异常称为软中断,将外围设备产生的中断叫做硬中断
软件中断:指实现中断处理程序下半部分的实现方式。包括软中断、tasklet和工作队列。下半部的任务就是执行与处理与中断处理密切相关但中断处理程序本身不执行的工作(因为,中断程序本身就应该简短、快速)
中断上半部分:简短、快速,不允许睡眠,处理时关闭中断
中断下半部分:处理时允许响应其他所有中断。除了工作队列允许睡眠外,其他两种方式也不允许睡眠。
工作队列也是唯一能在进程上下文运行的下半部实现机制。
当未处理的软中断过多时,内核将唤醒内核线程 ksoftirqd, 每个处理器都有一个该线程

内存分配算法
首次适应算法(First Fit):从空闲分区表的第一个表目起查找该表,把最先能够满足要求的空闲区分配给
作业,这种方法的目的在于减少查找时间。为适应这种算法,空闲分区表(空闲区链)中的空闲分区要按地址由低到
高进行排序。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区。
最佳适应算法(Best Fit):从全部空闲区中找出能满足作业要求的、且大小最小的空闲分区,这种方法能使
碎片尽量小。为适应此算法,空闲分区表(空闲区链)中的空闲分区要按从小到大进行排序,自表头开始查找到第一
个满足要求的自由分区分配。该算法保留大的空闲区,但造成许多小的空闲区。
最差适应算法(Worst Fit):从全部空闲区中找出能满足作业要求的、且大小最大的空闲分区,从而使链表中
的结点大小趋于均匀,适用于请求分配的内存大小范围较窄的系统。为适应此算法,空闲分区表(空闲区链)中的空
闲分区按大小从大到小进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留小的空闲区,尽量
减少小的碎片产生。
版权声明:本文为CSDN博主「GreyBtfly王宝彤」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/GreyBtfly/article/details/84646981

操作系统【动态分区分配算法——首次适应算法、最佳适应算法、最坏适应算法、临近适应算法】_upward337的博客-CSDN博客
try catch怎么实现(1)
阿里灵犀一面,不会
bss段存放的是什么变量,是什么时候被赋值的?(1)
大疆一面。
存放未初始化或者初始化为0的全局变量(以及局部static变量)
在操作系统加载进程ELF文件时,根据ELF的段头进行0初始化操作。
操作系统的0地址为什么是无效的?操作系统如何直到它是无效的?1地址呢?(1)
大疆一面
为了安全考虑,0地址实际上是不会被映射的,那么当我们去解引用一个0地址时,首先硬件会因为pTE的P标志位为0产生一个缺页异常,内核函数do_page_fault处理缺页异常, 它从cr2寄存器中取出产生fault的虚拟地址,发现这个地址本身就没有被映射,内核将直接终止进程。
那么Linux是如何保证用户不会人为地将0地址覆盖呢?因为mmap系统调用可以使用MAP_FIXED标志位指定需要映射的虚拟地址。答案是不会,操作系统会检测出低地址,并报错,可以运行下面程序实验:
int main(void) {
int prot = PROT_WRITE | PROT_READ;
int flags = MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED;
void *p = mmap((void*)(0), 1024, prot, flags, -1, 0);
if(p == MAP_FAILED) {
perror("map");
return -1;
}
printf("%s\n", (char *)p);
munmap(p, 1024);
return 0;
}
可能不同的linux版本,有不同的规定,我在ubuntu的18.04上进行实验时,指定的虚拟地址至少要大于等于4096 * 16才能正确运行。可见,1地址也是不能被映射的。
linux2.6的内核源码中,沿着do_mmap => do_mmap_pgoff => round_hint_to_min, 看到round_hint_to_min函数,它将会调整参数到最小的允许地址:
/*
* If a hint addr is less than mmap_min_addr change hint to be as
* low as possible but still greater than mmap_min_addr
*/
static inline unsigned long round_hint_to_min(unsigned long hint)
{
#ifdef CONFIG_SECURITY
hint &= PAGE_MASK;
if (((void *)hint != NULL) &&
(hint < mmap_min_addr))
return PAGE_ALIGN(mmap_min_addr);
#endif
return hint;
}
如何进行CPU绑核?如何查看进程运行在哪个CPU上?为什么绑核就能够提高系统效率(1)
Linux中CPU亲和性(affinity) - LubinLew - 博客园 (cnblogs.com)
- linux命令 taskset命令
- 编程API : sched_setaffinity
判断Linux进程在哪个CPU核运行的方法_linux 查看进程所在cpu_ibless的博客-CSDN博客
- ps -o pid,psr
HugePages的优势?(1)
忘了哪个公司问的,可能是oppo面试问的吧
- 减少
TLB(Translation Lookaside Buffer)的失效情况。 - 减少
页表的内存消耗。 - 减少 PageFault(缺页中断)的次数。
页表少了,也就是对应的物理地址和虚拟地址的映射减少了
bin文件(二进制文件)和elf文件的区别(1)
忘了哪个公司问的了
多进程与多线程的选择(2)
【linux】多线程还是多进程的选择及区别 - 知乎 (zhihu.com)
linux内核如何管理内存 -- 伙伴算法和slab (1)
oppo、美团
不嫌弃的话,可以看看我的一篇博客
线程调度算法及其适用场景(1)
函数调用,在汇编层面栈的变化(2)
函数调用时栈是如何变化的? - 知乎 (zhihu.com)
linux线程状态什么时候TASK_INTERRUPTIBLE 什么时候TASK_UNINTERRUPTIBLE(1)
oppo正式一面
TASK_INTERRUPTIBLE 可被信号唤醒。 锁
TASK_UNINTERRUPTIBLE 不能被信号唤醒。 read、write等系统调用被阻塞时
C语言
内存对齐相关
struct A {
int a;
union {
long b;
short c;
} dd;
};
struct B {
char e;
struct A d; // 注意规则三,d应该从8字节偏移处开始存储!!
int f;
};
cout << sizeof(struct A ) << endl; // 16
cout << sizeof(struct B) << endl; // 32 为什么32?
内存对齐的规则有3:
-
规则一:结构体中元素是按照定义顺序一个个放到内存中的,但并不是紧密排列的。从结构体存储的首地址开始,每一个元素放置到内存中时,它都会认为内存是以它自己的大小来划分的,因此元素放置的位置一定会在自己大小的整数倍上开始(以结构体变量首地址为0计算)。
-
规则二:在按照第一规则进行内存分配后,需要检查计算分配的内存大小是否为所有成员中大小最大的成员的大小的整数倍,若不是,则补齐为它的整数倍。
-
规则三:如果一个结构体B里嵌套另一个结构体A,则结构体A应从offset为A内部最大成员的整数倍的地方开始存储。(struct B里存有struct A,A里有char,int,double等成员,那A应该从8的整数倍开始存储。),结构体A中的成员的对齐规则仍满足规则1、规则2。
pragma(4) 与 #pragma(8)下内存占比分别是多少?
struct one {
double d;
char c;
int i;
}; // 大小分别为: 16 16
struct two {
char c;
double d;
int i;
}; // 大小分别为 :16 24, double在两种对齐方式中的开始偏移地址是不同的
有效对其值:是给定值#pragma pack(n)和结构体中最长数据类型长度中较小的那个
地址传参(1)
腾讯实习一面,没想出来
以下程序不能正常运行,如何修改?
void get(char* p,int num)
{
*p = (char *)malloc(sizeof(char)*num);
}
int main()
{
char *str;
get(str,100);
strcpy(str,"hello");
printf("str = %s\n", str);
return 0;
}
错误原因:指针以拷贝的方式传递,指针的值是它指向的内存的地址,我们需要将存放该指针本身的地址传给函数,因此需要使用二维指针:
void get(char** p,int num)
{
*p = (char *)malloc(sizeof(char)*num);
}
int main()
{
char *str;
get(&str,100);
strcpy(str,"hello");
printf("str = %s\n", str);
return 0;
}
memmove 与 memcpy
void *memmove(void *dest, const void *src, size_t n);
void *memcpy(void *restrict dest, const void *restrict src, size_t n);
从函数申明来看,两个函数的作用是相同的。但是memmove对dest、src重叠的情况有优化。
【C语言】浅谈memcpy与memmove 的区别_DanteIoVeYou的博客-CSDN博客
strcpy实现
gcc的实现:
char *
STRCPY (char *dest, const char *src)
{
return memcpy (dest, src, strlen (src) + 1);
}
libc_hidden_builtin_def (strcpy)
apple的实现?:
char *
strcpy(to, from)
register char *to;
register const char *from;
{
char *save = to;
for (; *to = *from; ++from, ++to);
return(save);
}
也可以将for循环改成while循环:
char* my_strcpy(char* dest, char* src) {
char* ret = dest;
while ((*dest++ = *src++)) {
}
return ret;
}
为什么strcpy返回指针?
为了能够达成链式操作
扩展:strcpy的安全性得不到保障,于是有了 strcpy_s, 最后的s代表“safe”(请见缓冲区溢出攻击);
安全的字符串拷贝strcpy_s的实现与理解 - 知乎 (zhihu.com)
返回两个值中较大的一个,编写一个宏
笔试常见题
用一个宏实现求两个数中的最大数 - micro虾米 - 博客园 (cnblogs.com)
C++
如何看待friend?他不破坏封装性吗?
分两个角度看,friend使得友元函数\类能够读取本类的私有属性。但是使用friend暴露的封装性可控。如果不使用友元有要使其他类能够读写本类的数据成员,那么只能将数据成员写成public,这样的封装性破坏更严重!
例子: weak_ptr通过lock函数能转换为sharedptr,这必然涉及到调用shareptr的构造函数,然后由sharedptr操作waekptr的成员函数,那么这就要求weakptr类声明shareptr为友元模板类。
friend 是单向的还是双向的?能被继承吗?(1)
单向,不能被继承
虚函数原理(5)
重点中的重点,只要问C++,几乎就会被问到
inline关键词的作用?除了内联以外的作用?(2
字节实习一面,仅答了内联,问还有什么作用。答不知道。
inline关键词除了经典的内联函数体外还有什么作用? 与ODR有关,inline允许每个翻译单元都有一个自己的定义。
智能指针指针(5)
极高频面试、笔试题
各种指针大致介绍下
shared ptr
shared_ptr,引用计数何时增加和减少 ?
- 增加:拷贝构造、赋值构造
- 减少:移动构造、移动赋值、赋值构造(首先减少本来所管理资源的ref count,再增加新管理资源的ref count)
如何用普通指针初始化 shared_ptr ?
auto raw_ptr = new Widget;
std::shared_ptr<Widget> shared_p(raw_ptr);
用普通指针初始化 shared_ptr 这种用法有什么坏处?
容易造成多个shared_ptr的引用控制块,意味着可能会对裸指针施加多次delete操作,容易造成未定义行为。
std::shared_ptr<Widget> shared_p(raw_ptr);
....
std::shared_ptr<Widget> shared_p2(raw_ptr);
shared_p 和shared_p2管理同一个裸指针,但是有不同的引用计数控制块,因此它们会对裸指针分别执行一次delete操作,造成未定义行为。
shared pointer 有什么注意点?
线程安全性问题
循环引用问题
给定struct结构体的某个成员变量的地址,如何求结构体本身的地址?(2
vivo实习一面,希奥端一面
首先求出,这个成员变量在这个结构体中的偏移地址:
struct Something {
int a = 0;
int b = 0;
char Member = 1;
};
size_t offset = (size_t) &((struct SomeThing*)0)->Member
注意前面那个&符号,取得的是偏移地址。
然后将Member的地址减去偏移地址即可得到整个struct结构体的实际地址。
栈的效率为什么比堆高?
- 申请速度快。栈在程序一开始运行时就已经分配了空间,因此如果局部变量不大的话,则在运行时几乎不需要再向操作系统申请空间。但是堆上的空间时动态分配的,大概率会发生一次page fault,pagefault的这个过程又涉及从用户到和心态的切换,比较耗时
- CPU硬件支持。CPU有专门的寄存器esp、ebp来操作栈,但是堆使用的是直接寻址
多继承下数据分布 具体顺序(2
字节实习一面
科大讯飞提前一面
分多继承和虚继承来回答?
static(2
“被static修饰的全局变量只对本文件可见”的延申
头文件定义static int a = 1; 1.cpp 和 2.cpp都include这个头文件,那么最终链接形成的elf中有几个int a?
2个。实例程序如下:
// head.h
static int a = 3;
// 1.cpp
#include "head.h"
#include <iostream>
#include <ostream>
using namespace std;
static int b = 1;
void fun() {
cout << "1.cpp : a = " << a << endl;
a += 5;
cout << "1.cpp : a + 5 , a = " << a << endl;
}
// 2.cpp
#include "head.h"
#include <iostream>
using namespace std;
extern void fun() ;
int main() {
cout << "2.cpp : a = " <<a << endl;
a += 4;
cout << "2.cpp : a += 4 , a = " <<a << endl;
fun();
}
编译链接两个文件然后执行:g++ 1.cpp 2.cpp -o obj && ./obj 。输出如下:
2.cpp : a = 3
2.cpp : a += 4 , a = 7
1.cpp : a = 3
1.cpp : a + 5 , a = 8
可以看到两个文件中各自有一个int a变量,它们互不影响。
作为验证,我们可以查看obj文件的符号表,nm obj:
0000000000202010 d a
0000000000202018 d a
可以看到有两个a变量,但是它们存储的位置不相同。
以上结论对static修饰的普通函数也适用。
// static_fun.c
#include <iostream>
static int fun() {
std::cout << "head fun()\n";
}
// 1.cpp
#include "static_fun.h"
extern void fun2();
void fun1() {
std::cout << "int 1.cpp call fun():\n";
fun();
}
int main() {
fun1();
fun2();
}
// 2.cpp
#include "static_fun.h"
int fun2() {
std::cout << "int 2.cpp call fun():\n";
fun();
}
同样会在符号表中出现两个fun符号,但是它们都是局部符号,且地址不用:
000000000000081a t fun()
00000000000008c6 t fun()
如果A文件有定义: static int b = 1; B 文件申明extern int b;那么B文件能存取A的a变量吗??
不能,会报链接错误:undefined reference to `b'
迭代器的萃取机制是如何实现的?(1
字节实习一面
模板推导、模板特化、模板偏特化
malloc和new的区别
使用上:
- malloc需要程序员指定内存大小,new则不用
- malloc返回void指针,需要程序员做进一步的转换,new直接返回对应类型的指针,不需要转换
分配失败
- malloc返回空指针,new默认抛出异常(bad_alloc),但如果在new时传入nothrow标志,则不会抛出异常,也返回空空该指针
分配地址:
- malloc分配在堆上,new分配内存则在自由存储区。
- 自由存储区包括了堆,产生这样的差异我觉得主要是由于new操作符能够重载。new默认分配的在对上,但是如果重载一个类的new操作符,使其不分配在堆区(比如全局对象池)上,那么自由存储区就不等同于堆区了
malloc最大能够分配多少内存?
实验例程序:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
unsigned long long int maximum = 0;
int main (int argc, char* argv[])
{
unsigned int block_size = 1024*1024*1024;
void* addr = NULL;
int i = 0;
while (1) {
addr = malloc(block_size);
if (!addr) break;
i++;
}
printf("malloc %d GB, aroud %lf TB\n", i, i / 1024.0);
getchar();
return 0;
}
实验环境:Ubuntu 18,64位机子。
结果:127TB(在vm.overcommit_memory=1的情况下),符合理论(理论最大为128TB,但进程本身的资源也要占用虚存)。
但是这个实验并不严谨,可以参考我的这篇博客
struct与class的区别(1
科大讯飞提前批一面
回调函数如何实现(2
科大讯飞提前批一面
海康实习一面
C++内存区域划分(2)
科大讯飞提前一面
海康实习一面
栈 mmap区域 堆 text data段
其中栈与mmap区域都从高往低扩展,堆则向上扩展
如何限制类只能在堆或者栈上创建对象?
只能在堆上创建对象:
将类的构造函数/析构函数设为私有(因为如果要在栈上创建,编译器首先需要检擦类的构造\析构函数,如果它们是private的,编译器就会报错,这样就不能在栈上创建对象了),但是要提供对应的包装函数以便在对上创建
只能在栈上创建对象:
重载operator new并将其设为private
C++中的内存分配(2)
问得挺多,应该不止这个数
动态方式 : 栈、堆
静态方式: static变量,在编译时已经在ELF文件中存储(data)\标识(bss)
const 变量的内存分配?
C++Const变量的存储位置 - 别杀那头猪 - 博客园 (cnblogs.com)
constexpr
若constexpr修饰变量,则表示该变量不仅是const的,而且在编译阶段就能被计算出来。
作为对比,const变量则没有这个保证。比如一个const 局部变量:
int main () {
int ss ;
ss = ....// ....
const const_a = ss;
}
const_a的值是在运行时确定的。
若constexpr修饰函数,并不代表该函数的返回结果一定在编译器已知,而是视函数的参数而定:
- 若函数参数都是编译器期确定,那么该函数的返回值也是编译器已知的
- 若函数参数有一个在编译器未知,那么constexpr修饰的函数与普通函数是类似的
C++11中对constexpr函数有一个限制:函数应该只有一条
C++14中该限制放开了
函数调用规约(2)
秋招,科大讯飞
芯云科技
cdecl(C declaration) : 参数从右往左压栈,由调用者清理栈空间
stdcall: 参数从右往左压栈,由被调用者清理栈空间
thiscall:在调用C++非静态成员函数时使用的调用规约。GCC编译器的thiscall与cdecl几乎相同,参数都是从右往左压栈,this指针作为最后一个参数入栈,由调用者清理空间。VC++中,this指针通过exc传递,参数从右往左,由被调函数清理空间。
从右往左压参数,是实现可变参数的关键
强弱符号
已初始化的全局变量是强符号,未初始化的全局变量是若符号。
C语言中的强符号与弱符号_astrotycoon的博客-CSDN博客
链接器处理强弱符号的规则有3:
不允许强符号被多次定义,否则,链接器报错- 如果一个符号在某个目标文件是强符号,在其他目标文件中表现为弱符号,那么选择强符号
- 如果一个符号在所有目标文件中都表现为弱符号,则选用空间占比较大的那个。
动静态链接与静态链接(2)
问得有很多,但是没把握,直接答不知道:
- 动态链接如何实现
- 如果程序报错找不到动态链接库,该从哪几个方面着手解决?
从静态链接的两个问题出发:
-
浪费空间
比如有一个simple.c文件,只是用到了C函数库的printf函数
// simple.cc #include <stdio.h> int main() { printf("hello\n"); printf("word\n"); }分别使用动态和静态链接:
gcc simple.c -o simple_dynamic gcc simple.c -static -o simple_dynamic然后观察它们的大小:
$> ls -l total 844 -rw-rw-r-- 1 ubuntu ubuntu 79 Dec 27 22:37 simple.c -rwxrwxr-x 1 ubuntu ubuntu 8304 Dec 27 22:38 simple_dynamic -rwxrwxr-x 1 ubuntu ubuntu 845240 Dec 27 22:38 simple_static动态链接后的可执行文件的大小大约有8KB,然而静态链接的可执行文件的大小是前者的一百倍!这还只是一个文件,如果多个文件使用到了printf,那么内存中将会存在多份printf函数依赖的C运行库的部分代码,显然造成了内存浪费。原因就在于静态链接虽然只是使用到了printf函数,但是链接器会将包含printf的整个文件合并到最终的输出文件中,此外printf函数可能也会依赖C函数库中的各种符号或者函数,这样这些文件也会合并到最终的输出文件中,最终导致了可执行文件的庞大无比。
-
不利于程序的更新、部署和发布
许多程序需要依赖其他的模块,当一个模块更新时,那么我们必须显示地将这个新模块与应用程序重新进行静态链接,这项工作不方便,也很耗时。
链接顺序
问题出在链接静态库的操作上,见CSAPP P477,假设 a.o 依赖 静态库lib.a中的某些文件,那么在使用gcc链接时需要将lib.a 写在后面。
const int 和 int形参能构成重载吗?
不能
但是int& 与 const int & 能构成重载!!
main函数之前会有什么代码执行吗?(1)
比如全局对象的构造函数
C++四大转换?哪个是运行时? dynamic_cast原理了解过吗?(1)
C++位运算的与或 和 逻辑运算的与或,有何区别?(1)
对一个inline函数进行取地址会发生什么?
函数就不能进行inline操作了
有什么方法可以尽可能防止内存泄漏?(1)
- 智能指针
- RAII
- 注意new和delete的配套使用
- 借助工具辅助诊断,入valgrind
STL
STL使用的区间大多为前闭后开
腾讯实习一面:
vecotr
vector底层实现
扩容为什么是1.5或者2?
(36条消息) 面试题:C++vector的动态扩容,为何是1.5倍或者是2倍_vector扩容_森明帮大于黑虎帮的博客-CSDN博客
在vs中扩容因子是1.5, linux中的扩容因子是2
也有可能是stl的内存池的原因?stl内存池管理的内存块大小都是2的幂次方
- 使用1.5的扩容因子,有机会重新使用之前分配的地址
- 但是为什么g++的vector的扩容因子是2?我个人想到了两点原因,都和上一章的allocator的内存池相关
- 内存池freelist管理的对象大小都是2的幂次方,扩容大小即时小于2,也会round_up成2的幂次方
- 内存池freelist中串联的内存并不保证连续,而重用之前分配的地址则需要先后分配的地址连续。
扩容前后的第一个元素的地址相同吗?
不相同,因为扩容是会分配新的内存块的。
以下程序为验证:
int main() {
vector<int> a(1,1);
cout << a.size() << " " << a.capacity() << " \n";
printf("first ele's address = %p\n",&a[0]);
a.push_back(2);
cout << a.size() << " " << a.capacity() << " \n";
printf("first ele's address = %p\n",&a[0]);
return 0;
}
1 1
first ele's add = 0x5648f54f0e70
2 2
first ele's add = 0x5648f54f12a0 // 首个元素的内存不相同
vector 与 list的区别(2)
如何缩小capacity(1)
中望一面
swap一个空的vector
shrink_to_fit 它是减少 capacity() 到 size()非强制性请求。请求是否达成依赖于实现。详见cppreference
clear和resize(0)(1)
达到的效果是相同的,都能将size变成0,但是capacity不会变
unoredered_map
与map的区别,如何选择使用哪个?
其底层原理。
各容器的适用场景(5)
问得挺多
尤其数组和链表的比较,红黑树与哈希表的比较
string类
写时拷贝
(40条消息) C++基础之string写时复制(代理模式)_string复制_菜鸟队长2012的博客-CSDN博客
SSO
几何问题
如何判断一个点在三角形内?
判断一个点是否在三角形内_牛客博客 (nowcoder.net)
叉积
大数据
如何在大量数据中判断某条数据存不存在(无
面试被问,一千万个整数里面快速查找某个整数,你会怎么去做? - 知乎 (zhihu.com)
教你如何迅速秒杀掉99%的海量数据处理面试题 - 掘金 (juejin.cn)
项目
单例模式的好处?(1)
学习到什么设计模式?(1)
科大讯飞提前批一面
CMU15-445 : 工厂模式,生成各种plan
虚拟文件系统:外观模式? 比如Linux中的struct file结构中的f_op指针指向的具体数据结构是不同的。
应该是外观模式吧,起初以为式策略模式,但看着好像不是。
CMU15-445
读写page的流程?(无
dynamic hashing 流程(2
讲不清楚,结合ppt讲吧。
会不会造成内存碎片?(1
字节实习二面。
比如delete了一个记录,然后再插入一个记录后,会覆盖标记为删除的记录吗? --- 会。
这里主要看insert和delete的逻辑的逻辑。
首先是table heap类的insert tuple方法:
- 该方法会从该table heap的第一个page开始(first_page_id_)执行插入操作,如果对该页的插入操作失败就会循环获取下一个pageid(因为一个table heap的页是以双向链表连接的,所以很容易找到下一个)的页进行插入操作。直到某个页有足够的剩余空间容纳新的记录,或者新创建一个页执行完插入操作位置。
然后是table_page的insert tuple方法:
- 首先判断这个table_page还有没有剩余空间存放要插入的tuple。(每个tablepage都会维护一个freepointer,我们可以通过这个快速计算剩余空间)
- 如果空间不够,则返回false
- 从头往后遍历"slot", slot中记录了每个tuple的大小和偏移地址,选择tuple大小等于0的那一个
- 移动freepointer,“claim" the space
- 然后将tuple复制到tuple page的空闲区域中
- 最后更改header信息
table_page的MarkDelete方法:
- 首先明白何为"某条记录标记为删除",它的意思就是说这条记录的slot中记录的tuplesize被置为0或者和DeleteMask相与后为true。(其中DeleteMask是一个无符号64位整数,其值位INT_MAX + 1, 又由于tuplesize是大于等于0的有符号整数,一般它的其实位为0,但是与DeleteMask相与后就变成1)
- markdelete就是将对应记录的slot中的tuplesize与DeleteMask相与,将其最高为置为1。
table_page的ApplyDelete方法:(从本方法可以看出,BUSTUB通过内存compact在一定程度上预防了内存碎片):
-
// 把tuple_offset - free_space_pointer这一整段往前挪tuple_size距离,相当于一个 compact操作 memmove(GetData() + free_space_pointer + tuple_size, GetData() + free_space_pointer, tuple_offset - free_space_pointer);
事务在提交时,由tracsaction manager执行apply delete:
void TransactionManager::Commit(Transaction *txn) {
txn->SetState(TransactionState::COMMITTED);
// Perform all deletes before we commit.
auto write_set = txn->GetWriteSet();
while (!write_set->empty()) {
auto &item = write_set->back();
auto table = item.table_;
if (item.wtype_ == WType::DELETE) {
// Note that this also releases the lock when holding the page latch.
table->ApplyDelete(item.rid_, txn);
}
write_set->pop_back();
}
// ......
}
disk manager(1)
如何预防死锁(1)
记录结构可自定义吗?(1)
遇到的困难?
可扩展哈希表的算法逻辑,merge => extra merge算法逻辑有误
涉及到多线程以及读写锁。
- split insert是个递归函数,且该函数需要加锁,那么在进行递归前应该先解锁。
- 函数有多个return语句,容易忘记unlock导致死锁。后来改用lock_guard.
- 读写锁的粒度问题,不能过早地优化
C++语法问题
-
类成员初始化顺序与声明顺序一致,如果成员之间相互依赖,则必须按顺序初始化
-
引用的使用,初学C++时经常在一个容器的拷贝而不是应用上修改,导致根本没有改动任何东西
内存泄漏?
项目自带valgrind检查,但是线下测试用例不完整,线上测试的奔溃原因可能不显示内存泄漏,由此导致debug方向错误。
最难的的是第二个任务。
-
首先,要求我们实现一个可扩展哈希表,算法逻辑比较复杂,而且资料比较少。我后来在一个外文网站的科普和youtube的一个视频,大体弄懂了它的思想、
-
但是,大多数的实现都不考虑线程安全。因此如何线程安全需要自己摸索。在这一方面,由于之前没有接触过多线程编程,所以遇到了比较多的问题:
- 死锁问题,程序常表现为运行停顿,测试出现超时错误。常见错误为:在函数中有多个return语句,往往在其中一条或几条中漏写了unlock解锁代码。后来通过阅读和实践,用lock_guard类代替了原先的手动加锁和解锁。
- 加锁的粒度问题,可扩展哈希表分为目录页和桶页,应该视具体情况加锁,不能对一整个哈希表加锁,如果只是对一个桶的操作,那么只需要对该桶加锁即可
- 读写锁问题,这和上面都是为了效率的考量进行的一些优化。哪些操作该加读锁,哪些操作必须加写锁,刚开始不熟悉的时候非常容易弄混
-
整个Project2依赖于Project1,即可扩展哈希表对页的存取都通过BufferPool来实现,BufferPool是和磁盘交互的中介。而IO操作又很费时,因此为了效率考量,BufferPool的UnpinPage Api可以传入一个flag,Unpin表示上层调用者不需要该页了,而flag表示上层调用者在这期间是否对该页进行了修改。如果没有进行修改,那么BufferPool就不会把这个页刷盘。为了减少IO,尽可能使flag成false。然而,刚开始不熟悉项目流程,很容易出现该刷盘的没刷盘,不该刷盘的却刷盘了,后者可能还好就是效率低了,但是前者往往导致程序的正确性问题,我刚开始经常出现Segmentation Fault就是对这个标志位的理解不够好。
-
过早的优化也是不可取的。如上所述,我们可以对锁粒度、读写锁和IO进行优化,但这都要在确保程序正确运行的基础上的。我当时将这些目标杂糅在了一起,导致自己陷入了一个Bug出现了却很难定位的窘境。我当时推翻重写了一遍,先写单线程版的程序,再写多线程版的程序,正确性保证后,考虑一些优化。
-
最大的问题,还是算法正确性的问题,可扩展哈希表的一些操作复杂,其中有一个API涉及到递归,想要正确实现算法逻辑是不容易的。我最长的Debug时常就是卡在了这上面,怎么调都不对。最后,还是看了别人的博客的实现逻辑,发现我少了一个额外合并的步骤,然后着手修改。修改的过程也并不顺利,我通过打印足够多的日志信息帮助自己判断,数据量很大的时候会将输出重定向文件中,一个个画图然后对比发现错误点。
-
其他的一些困难,就是C++语法上的,但是只是对C++语言入了个门,其实可能连入门都算不上,我当时只是看了一个英文的入门教程就上上手做这个教程。但是很多东西都不懂,比如C++11的内容,STL,C++对象模型的内容等等,很容易出现语法错误。比如引用,我在做项目前只用过Java,Java几乎所有都是引用,因此刚刚接触C++的时候很不习惯,经常没有使用引用去修改对象,导致程序的结果不如意料的那样。还有C++的类变量的初始化顺序,它于变量的定义顺序有关,所以在初始化的时候也要按照定义顺序进行,否则如果刚好两个变量又依赖关系那么出现未定义错误。还有很多,尤其是C++11那块,左右值,std::move,移动语义, reinterpret_cast等。解决的办法就只有多看多学了,尤其是C++11,在youtube上看到一个很有帮助的频道叫CPP Conference,它有一个BackTOBasics系列,专门将C++的基础语法,我的C++11大多通过这些视频入门。
-
其他的困难,硬要说的话,就是课程提供的线上测试平台不是很友好。
优化的工具?(1)
项目架构图
Project #3 - Query Execution | CMU 15-445/645 :: Intro to Database Systems (Spring 2023)
2023的架构图:
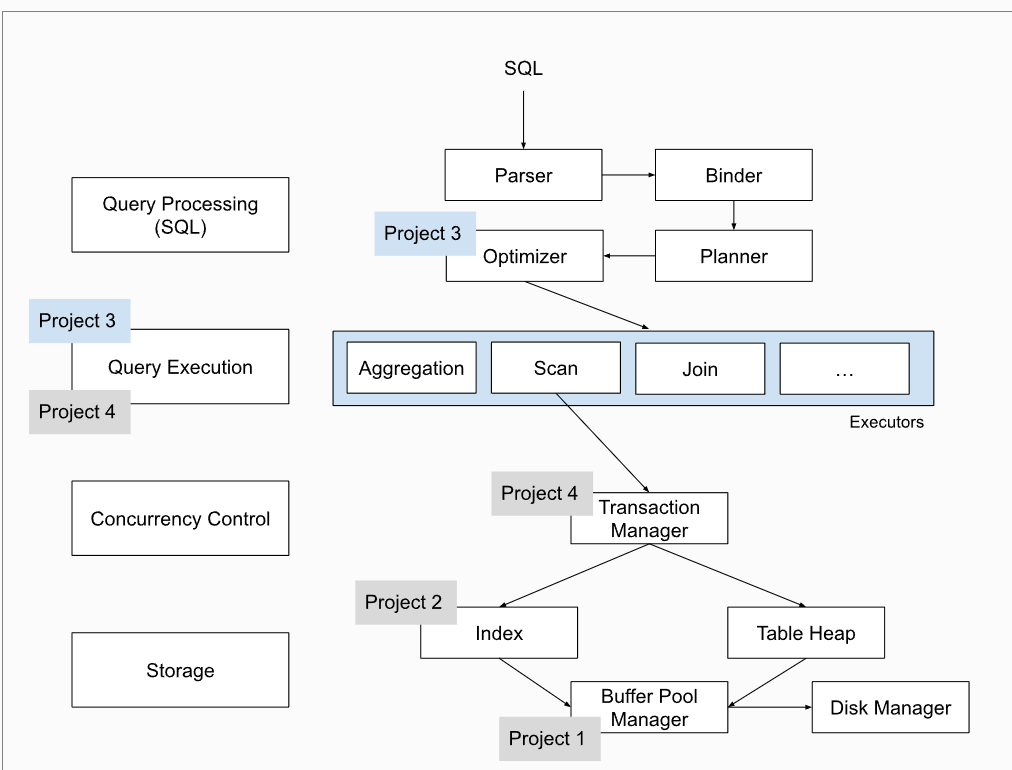
自己仿照画的2021的架构图:
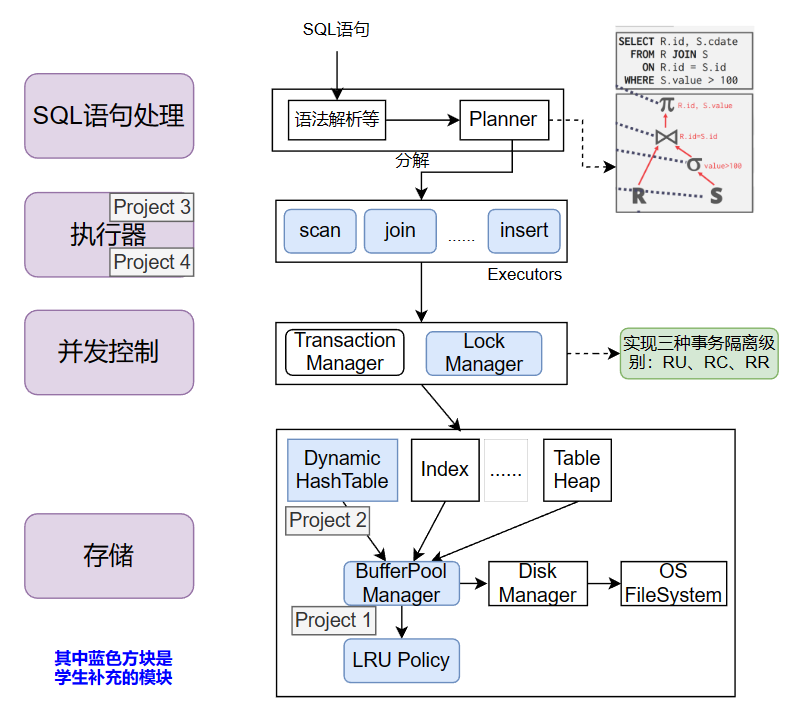
对比来看,2023的实验项目完整了很多。难度上,应该是2023更难一点(魔鬼B+树),实验任务也更多一些。
有做什么优化吗(2)
使用perf和Flame Graphs的一个脚本生成了火焰图,发现时间主要是消耗在两个地方:
- 锁的操作
- io操作
尤其是io方面,所以要尽量减少IO操作
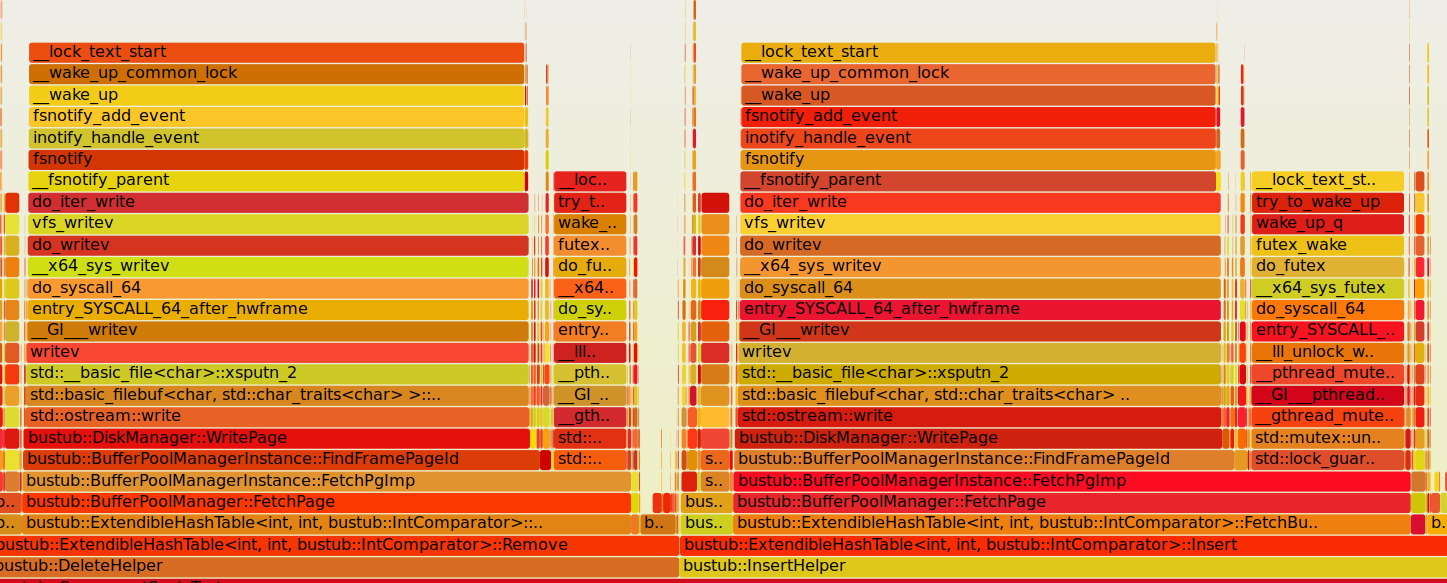
生成火焰图的具体操作可见:
perf对多线程Profile简单流程_perf 多线程_BanFS的博客-CSDN博客
sudo perf record -g -F 99 <要检测的程序名> // -p 后跟进程id
perf script | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > output.svg // 输出的svg文件就是火焰图
bufferpool flag ?
目标是减少数据库的io操作。在Project2中,基于buffer pool manager实现了可扩展哈希表,哈希表大体上由 directory page 和 bucket page组成,通过bufferpool来获取和释放其中的某种页。释放时,buffer pool要求设置一个标志位,表示该页是否为脏。如果为脏那么lru剔除策略在剔除时需要先将该页刷盘,如果不为脏,则拿来就用。因此不能一股脑地将页设置为脏,需要更加细粒度地进行分辨。
读写锁 ?
粒度优化,比如
insert方法,先为derectory page加读锁,然后为bucket page加写锁,进行insert,这里期望derectory是不发生改变的,因此加读锁即可。
但如果bucekt页满了,则执行split insert方法,split insert方法为derectory page 和 bucket page 都加上写锁。
C++语言方面 ?
项目介绍(近2/3的面试都会问)
第一部分:
- 第一部分主要是对BufferPool的实现。
项目的第三部分介绍一直没有表达地很好,整理一下:
- 项目的第三部分是执行器的实现。执行器是对SQL语句的具体实现,这个项目已经帮我们完成了其中的前置部分。什么叫前置部分,比如一个SQL语句,Select ... from 表1 Join 表二 where 一些限制条件,首先会对这个语句进行语法分析,然后会生成一个树形的执行计划,这棵树的节点就表示了某个具体执行器。比如刚刚那个SQL语句生成的执行计划树,就可能由多个顺序扫描执行器和HashJoin执行器组成。语法分析并生成计划树的部分就是前置部分,不需要去实现,而计划树上的执行器节点是我要去实现的,包括顺序扫描、HashJoin、Limit、Insert、Update操作等等。
- 这个部分本生的代码逻辑并不是很难,主要是代码量比较大,然后阅读量也比较大,因为项目本身已经实现的代码也有很多,需要认真去看这些实现理解项目提供的API。
第四部分:
除了火山模型还了解什么其他模型?(1)
阿里控股集团二面
mit6.828
上下文切换流程?(3)
有没有在这个操作系统上跑过用户自己编写的代码?(1)
字节实习二面,被问懵了。
实话是没有。
第一,我没有实现JOS的touch、mkdir等调用(实验也没有要求)的,因此JOS连创建一个文件都做不到。其次,就算是我实现了这两个调用,创建了一个.c文件然后在新的文件中写下C代码,最终问题是如何编译它?JOS内可没有GCC。
对于那些.c文件的库函数、实验验证文件,写lab的老师的做法是使用宿主机的GCC先将这些.c文件编译,然后放入一个fs.img, 该img与kernel.img(内核编译好后的映像文件)一同被写入qemu的虚拟磁盘中(见mit6.828/GNUmakefile 第151 ~ 154行)
项目优化
6.828 - Lab2 Challenge 5:Buddy System - 知乎 (zhihu.com)
finish lab2 challenges · Kirhhoff/jos@2dca0e8 (github.com)
自己仿照xv6加了一个LRU剔除策略
其他可以做优化:
加上日志层:
Challenge! The file system is likely to be corrupted if it gets interrupted in the middle of an operation (for example, by a crash or a reboot). Implement soft updates or journalling to make the file system crash-resilient and demonstrate some situation where the old file system would get corrupted, but yours doesn't.
项目介绍
都会问,但是一般都会往Linux系统上扩展,这是大部分面试官熟悉的部分。如果面试官往深了问,几乎一定能问到知识盲区。不过也别紧张,把自己会的答好,然后下去查一下不会的就行。
实验室项目
算法的输入输出是什么?
有没有想过规模问题? 支持多少机器、多少用户需求? 算法完成一个匹配需要多少时间。
算法消耗的资源是多少?
GDB
基本命令
- run/r 启动/重启线程
- b xx 打断点, xx可以是行号,也可以是函数名
- b xx if yy 打条件断点,yy为条件,当它满足时在xx处停下执行流
- watch xx xx通常是某个变量,当这个变量的值发生改变时,GDB就会停止进程的执行
- info breakpoints 查看断点,也会显示watch设置的断点
- clear xx 删除断点,xxxx可以是行号,也可以是函数名
- backtrack/bt 查看调用栈,通常在Segmentation Fault时很有用
- frame xx xx 为bt 显示的栈编号,能够切换到某个栈中
- info locals 查看栈的所有局部变量
- print/p xx 打印变量xx的值
GDB断点实现的原理
CppCon 2018: Simon Brand “How C++ Debuggers Work” - YouTube
用图文带你彻底弄懂GDB调试原理 - 腾讯云开发者社区-腾讯云 (tencent.com)
Playing with ptrace, Part II | Linux Journal
关键点:
- ptrace系统调用
- INT 3 指令
- 信号机制
gdb使用fork + exec运行将要被跟踪的用户程序,然后调用ptrace函数跟踪这个进程。
dgb使用ptrace修改子进程的的某个断点代码,将其修改为INT 3, 然后调用wait等待子进程停止运行。当子进程执行到断点时就因为INT 3指令从用户态转为内核态,内核态执行do_debug()函数,强制向子进程发送SIG_TRAP信号,子进程收到该信号后将把进程状态改成TASK_STOPED暂停运行,然后给父进程也就是GDB进程发送信号。
gdb收到子进程的信号后,将子进程被修改为INT 3指令的部分恢复,然后唤醒子进程继续执行。
GDB 条件断点怎么整(1)
科大讯飞提前批一面,
b line_num if predecate
line_num是行号, predecate是断点发生的条件
可以用在循环中:
1 // ...
2 for (int i = 0; i < 5; i++) {
3 // ...
4 }
可以打在i = 1的时候:
b 2 if i== 1
如何调试多线程
gdb调试多线程程序总结 - lsgxeva - 博客园 (cnblogs.com)
重要命令
- info threads, 查看运行的线程
- thread <thread_id> , 切换至某个线程
- set scheduler-locking off|on|step
- on 只有当前被调试进程会运行,其他线程被挂起
- off 运行全部进程
- thread apply threadId1 threadId2 command , 让一个或者多个制定的线程执行GDB命令command
- thread applay all commad,
- break xx : 会对所有线程加上断点
- break xx threadId : 只对某个thread施加断点
如何调试回溯
ReverseDebug - GDB Wiki (sourceware.org)
如何调试段错误
core 文件查看具体哪一行引发段错误, back trace命令查看从哪些函数调用一步步地引发段错误, frame <栈帧编号> 查看当前函数哪一行引发段错误
(38条消息) 使用gdb调试段错误(segment fault)_gdb 调试段错误_Deutschester的博客-CSDN博客
如何优雅的调试段错误-腾讯云开发者社区-腾讯云 (tencent.com)
if else 分支,如果再else中停止运行,如何使得程序返回至if分支执行?(1)
计算机网络
建议是撸一遍小林coding的内容
DNS查询用的什么协议?(1)
为什么 DNS 协议使用 UDP?只使用了 UDP 吗?-腾讯云开发者社区-腾讯云 (tencent.com)
域名解析的场景下,一般报文长度不超过512字节,所以通常使用UDP协议
DNS解析流程(1)
客户端先询问本地DNS服务器,如果本地DNS服务器有缓存,则直接返回,如果没有则:
- 本地DNS向根域名服务器提出请求,返回顶级域名服务器的地址
- 本地DNS向顶级域名服务器提出请求,返回权威DNS服务器的地址
- 本地DNS向权威DNS服务器提出查询请求,返回真实域名的IP地址
HTTP2有什么改进?(1)
http get和post的区别(1)
TCP三次握手(5)
被问好多次
TCO四次挥手(5)
被问好多次
TCP连接为什么不能两次握手?(3)
TCP使用三次握手的主要原因:阻止历史连接,避免资源资源浪费。也能帮助双方初始化序列号。
为什么两次握手不能阻止历史连接? 如果只用两次握手,那么服务端在收到第一个syn报文后就变成了Establish状态。然后...4.1 TCP 三次握手与四次挥手面试题 | 小林coding (xiaolincoding.com)
TCP为什么需要三次握手、四次挥手,一句话来回答(1)
time_wait、close_wait状态过多是什么原因造成的?(1)
TCP:一方一直发送数据,另一方一直不读会发生什么情况(1)
零窗口报文
探测报文
键入网址到网页显示,期间发生了什么
2.2 键入网址到网页显示,期间发生了什么? | 小林coding (xiaolincoding.com)
-
dns查询,得到网址机器的IP地址。
-
使用上一步得到的IP地址,进行TCP三次握手建立TCP连接,通报窗口大小。将源端口号和目的端口号封装,目标端口号为http服务器的默认端口号80,将标志位中的syn标志位指令,随机初始化序列号等等。总之,最后得到了TCP报文。
-
进行IP数据包的生成,使用1中得到的ip地址进行IP报文的生成,将源IP与目的IP封装。
-
接下来查询路由表,确定将这个包往哪个路由器发,即知道了目标路由器的IP地址。
-
物理上两点之间的接发由MAC地址确定,因此使用ARP协议查询目标路由器的MAC地址(当然先查询ARP缓存,如果本来就有的话就不需要ARP协议了)。最后封装成帧,由网卡将其发出。
-
这个数据包根据IP地址一步一步地到达目标机器,目标机器按照MAC => IP => TCP 的顺序解封数据包,判断得出这是客户端的syn报文。服务端内核自动生成(半连接队列未满的情况下)syn +ack报文对客户端进行响应。 客户端收到服务端的报文后,内核返回ack,此时客户端方向连接就已经建立。当服务端收到这个ack后,表示TCP的双向连接已经建立。
- 这里是不是可以插入,服务器使用epoll_wait监听客户端连接、读、写时间的请求?
-
接着,客户端就可以在TCP报文中封装HTTP报文进行通信了。
TCP粘包和解决方法(1)
HTTP的解决方法:
- 特殊分隔符,对请求头进行分隔
- contentlenth请求头指明消息题的长度
mss与mtu
MTU = Maximum Transmit Unit:最大传输单元,是物理层对IP层做出的限制
MSS = Maximum Segment Size: 是TCP对应用层的限制,一般来说,MTU = 1500 byte ,则MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte
epoll和select的区别
epoll惊群
linux - epoll惊群效应深度剖析 - 个人文章 - SegmentFault 思否
epoll 的ET和LT
epoll的LT模式(水平触发)和ET模式(边沿触发) - 知乎 (zhihu.com)
关于epoll的et模式一次没读完,下次有新数据来了,还会触发么? 会,但是如果没有新数据来,且内核缓冲区有未读完的数据,那么这些未读完的数据就会被忽视。
epoll为什么使用红黑树但不使用hash表呢?
没有面试官主动问过,但是经常会被问哈希表和红黑树(unordered_map和map)的区别,会主动举这个例子。
epoll用于网络连接场景,但通常情况下网络的断开和连接是比较频繁的。意味着需要往某个数据结构中频繁地插入和删除,显然红黑树更适合这个场景。
select为什么只支持1024个文件描述符?
select与epoll的区别
select : 轮询,内核将使用无线循环去查询每个fd
poll: 轮询
epoll: 回调函数
何时选用select函数?低并发,高活跃时。具体地需要监听的文件描述符较少(少于1024个),且每个文件描述符都比较活跃时。
何时选用epoll函数?高并发,低活跃。
select返回值
select返回值:
- /> 0 时,有时间发生
- = 0时,超时
- < 0时, 出错
- 但是在这种情况下,如果errno == EINTR,认为没有出错,可以继续监听。因为系统调用被信号处理流程打断,调用者可以正常重启
select优于epoll的情况
慢启动算法,门阈是多少?(1)
计算机网络(基础篇)-传输层_慢启动阈值_垃圾攻城狮的博客-CSDN博客
64KB
TCP传输的时候,如果遇到传输的数据不完整该怎么办,比如说200k的数据只接受了100k。
逻辑题
-
12个球,其中一个的重量不相同,给你一个天平,找出这个球。(2)
-
100个球,自己和小明依次拿球,每次拿1-5个球,自己先拿球,问如何保证自己拿到最后一个球。(1)
自己每次拿球使得剩下的球的个数为6的倍数。
总结
(TUDO)可能需要详细说明一下我自己的情况?
本人是2024届毕业生,感觉寒气满满。几个大厂的offer都是最后快沉不住气的时候拿到的。
总结一下几个公司的面试风格(叠甲:仅以我的体验来看)
- 互联网:比较注重计算机网络、数据库、实践经验
- pdd:一面重基础知识,二面重实践经验,挂
- 美团:实习投的是基础架构,问的都是操作系统相关的,但最后可能因为实习时间的原因,没发offer;秋招投递了北京的类似于数据治理的一个部门,一面秒过了,二面问了sql、网络 + 算法题没做出来,秒挂了
- 腾讯:无论是实习还是正式,都非常看重基础知识,问的都是比较基础的东西(操作系统、C++、算法),我不擅长网络,面试官没怎么问;秋招拿到offer了,但还是因为个人选择拒绝了,心好痛 😢
- 字节:只面了实习,一面狂问基础,二面问项目,重实践,挂了;感觉实习面试影响到了面评,后来秋招没收到面试
- 其他互联网:百度、快手、阿里等等:挂,可能是准备的方向不对口,当然最大的原因是自己菜
- 芯片相关的公司:比较注重操作系统的知识,算法题没怎么做
- 天数:狂问操作系统,通过
- 沐曦:狂问操作系统,两道简单算法,通过
- 恒玄:线下面试,挺神奇的;狂问项目,一道算法,简单线下笔试,通过
- 广立微:电话面试,挺简单的,不知道为什么挂了
- 其他:就不一一记录了
- 手机/电脑/汽车等硬件生产商:
- oppo:面了两次,两次都通过了。狂问操作系统,通过
- 华子:线下面试,面试通过,但是性格测试挂了,而且是实习的时候挂的!nnd,能给i人一条活路吗
- 荣耀:面试通过,性格测试挂了,不愧是爸爸和儿子,这个测试的标准都是一样的😒
- vivo:简历没过,nnd
- 小米:面了两次,都通过。狂问操作系统、cpp的一些基础知识,通过
- 蔚来:被捞去一个充电桩的嵌入式岗位 🤣 , 感觉是互相没看上了,挂了
- 理想:忘了问啥了,但挂了
- 科大讯飞:提前批、正式批面了好多次,面的不难,但最后还是挂,不知道是不是准备方向不对口的原因,还是说看出来我不太想去合肥🤣
- 大疆:两次技术面,狂问操作系统,一次总监面,面试过,排序挂,nnd
- 联想:只面了实习,面试挺简单的,过了,但是没去,心痛 😢
总结的总结:
- 互联网大多重视基础尤其是网络和数据库,也重视实践经验。纵观所有面试,就属互联网面试的难度最高:基础挖得深、算法问得难、重视实践项目
- 芯片厂商重视操作系统,挺简单的(天数问得挺深的,深入到某些linux内核源码实现)
- 硬件厂商也注重操作系统,可能会深挖,比如大疆也深入到了内核源码实现
- 还有一些没记录的公司,现在都记不住了
- 如果东西太多觉得hold不住的话,就专注一个方向吧。我的话对操作系统花的时间最多,所以一般面试狂问操作系统知识的话,自我感觉就比较良好。但是其他领域的知识确实是弱点哈哈
- 运气真的有点说法在里头的,放轻松吧,不要把它看得很重

 浙公网安备 33010602011771号
浙公网安备 33010602011771号