Unicorn快速入门
看James给的SPIR-V看麻了,转过来快速入门一下unicorn。早该学学了。官网:https://www.unicorn-engine.org/
(搞完这个继续看SPIR-V(确信))
简介与安装
Unicorn 是一个基于QEMU的轻量级、多平台、多架构的 CPU 模拟器框架。我们可以更好地关注 CPU 操作, 忽略机器设备的差异。 比如说,在分析恶意代码时,你想跳过有害进程,继续分析病毒特征;或者只想模拟代码的执行而非真的用 CPU 去跑一次,这些都可以用 unicorn 实现
Unicorn 的特色:
- 多架构:ARM、ARM64 (ARMv8)、M68K、MIPS、SPARC 和 X86(16、32、64 位)
- 干净/简单/轻量级/直观的架构中立 API
- 用纯 C 语言实现,绑定了 Crystal、Clojure、Visual Basic、Perl、Rust、Ruby、Python、Java、.NET、Go、Delphi/Free Pascal、Haskell、Pharo 和 Lua。
- 原生支持Windows 和 *nix(已确认 Mac OSX、Linux、*BSD 和 Solaris)
- 高性能JIT即时编译
安装非常简单:pip install unicorn,建议切虚拟环境
虚拟内存
Unicorn 采用虚拟内存机制,使得虚拟CPU的内存与真实CPU的内存隔离。摘录一下 Unicorn 用来操作内存的API:
uc_mem_map(address, size)
uc_mem_read(address, size)
uc_mem_write(addreee, code)
使用uc_mem_map映射内存的时候,address 与 size 都需要与0x1000对齐,也就是0x1000的整数倍,否则会报UC_ERR_ARG 异常。
Hook机制
Unicorn的Hook机制为编程控制虚拟CPU提供了便利。
Unicorn 支持多种不同类型的Hook,大致可以分为(hook_add第一参数,Unicorn常量):
-
指令执行类
UC_HOOK_INTR UC_HOOK_INSN UC_HOOK_CODE UC_HOOK_BLOCK -
内存访问类
UC_HOOK_MEM_READ UC_HOOK_MEM_WRITE UC_HOOK_MEM_FETCH UC_HOOK_MEM_READ_AFTER UC_HOOK_MEM_PROT UC_HOOK_MEM_FETCH_INVALID UC_HOOK_MEM_INVALID UC_HOOK_MEM_VALID -
异常处理类
UC_HOOK_MEM_READ_UNMAPPED UC_HOOK_MEM_WRITE_UNMAPPED UC_HOOK_MEM_FETCH_UNMAPPED调用hook_add函数可添加一个Hook。Unicorn的Hook是链式的,而不是传统Hook的覆盖式,也就是说,可以同时添加多个同类型的Hook,Unicorn会依次调用每一个handler。
快速入门
快速入门当然是要直接上手操作。摸一个题,hxpctf 2017的Fibonacci。可以在这里找源文件:https://bbs.kanxue.com/thread-224330.htm
运行后发现输出越来越慢,差不多是卡死了

在sub_400670函数内,我们发现了一个斐波那契数列,并且他与输出的flag有关
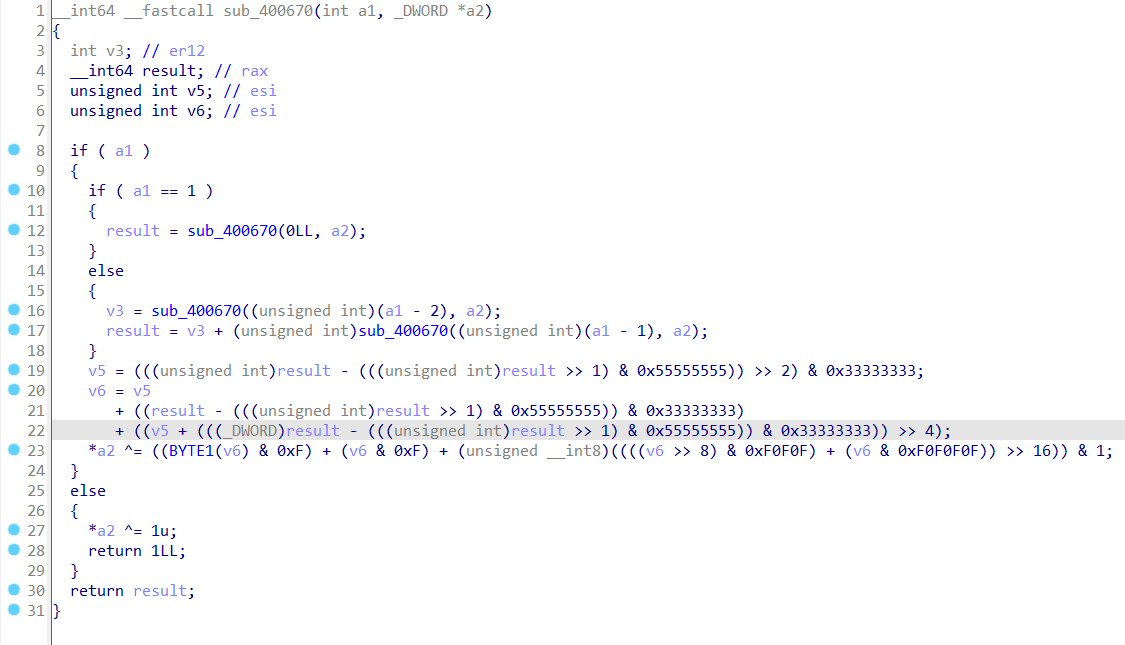
最直接的想法就是重写这个函数,然后直接运行;但今天学的是Unicorn
模拟程序
直接开始写Unicorn
from unicorn import * # 加载主要的二进制模块,以及Unicorn中的基本常量
from unicorn.x86_const import * # 加载一些特定的x86和x64常量
import struct
import pwntools
# 下面这三个是常用函数,直接用pwntools也行
# def read(name): #返回文件中的内容
# with open(name) as f:
# return f.read()
#
# def u32(data): #把四字节的bytes array转换为integer,以小端序表示
# return struct.unpack("I", data)[0]
#
# def p32(num): #与上一个相反
# return struct.pack("I", num)
mu = Uc(UC_ARCH_X86, UC_MODE_64) # 为x86-64架构初始化Unicorn引擎。第一个参数:架构类型,第二个参数:架构细节说明
# 使用Unicorn引擎之前需要手动初始化内存。我们需要将代码写入到某个地方,并且分配一些栈空间
BASE_ADDR = 0x400000 # 基址
STACK_ADDR = 0x0 # 栈地址
STACK_SIZE = 1024 * 1024 # 栈空间
mu.mem_map(BASE_ADDR, 1024 * 1024)
mu.mem_map(STACK_ADDR, STACK_SIZE) # mem_map函数来映射内存
mu.mem_write(BASE_ADDR, read("./fibonacci")) # read仅仅返回文件中的内容,加载二进制文件到基址上
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 1) # 初始化RSP寄存器指向栈底(倒着的)
def hook_code(mu, address, size, user_data): # 在启动之前写一个hook函数来输出调试信息
print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' % (address, size))
# 四个参数分别是:Uc实例句柄、指令的地址、执行的长度、用户自定义的数据,这个自定义的数据可以在hook_add的可选参数中随便挑一个
mu.hook_add(UC_HOOK_CODE, hook_code) # 添加hook
mu.emu_start(0x4004E0, 0x400575) # 启动模拟执行,从main开始,到while外面的IO_putc结束
稍微介绍下hook_code:
- 当起始地址 < 终止地址时,在起始地址到终止地址的每一条指令执行之前都会调用一遍hook_code函数
- 当起始地址 > 终止地址时,整个程序的所有指令执行之前都会调用一遍hook_code函数
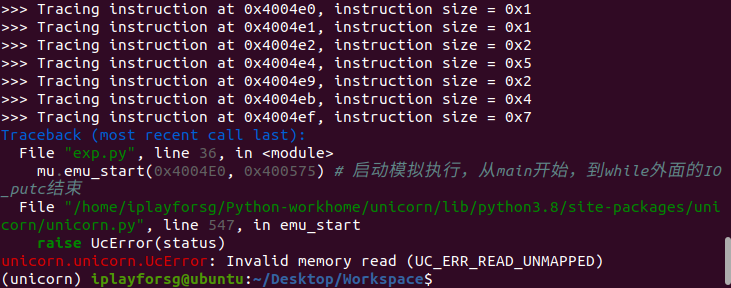
根据上方的调试信息可以发现:在0x4004EF处抛出了异常
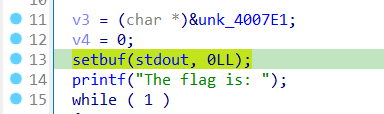

这条指令从地址0x601038处读取内存,而这个地址是.bss段,然而我们并没有分配这个区段的内存,所以他报错了;下面的的_setbuf是glibc里面的函数,但我们模拟执行的程序没有在内存中加载glibc,所以我们也不能调用这个函数。根据代码逻辑来看,整个问题的求解并不需要这一句,我们可以直接跳过这句话。同理,后面有相似问题的我们也可以选择直接跳过。
修改后的代码如下:
from unicorn import * # 加载主要的二进制模块,以及Unicorn中的基本常量
from unicorn.x86_const import * # 加载一些特定的x86和x64常量
import struct
from pwn import *
# 下面这三个是常用函数,直接用pwntools也行
# def read(name): #返回文件中的内容
# with open(name) as f:
# return f.read()
#
# def u32(data): #把四字节的bytes array转换为integer,以小端序表示
# return struct.unpack("I", data)[0]
#
# def p32(num): #与上一个相反
# return struct.pack("I", num)
mu = Uc(UC_ARCH_X86, UC_MODE_64) # 为x86-64架构初始化Unicorn引擎。第一个参数:架构类型,第二个参数:架构细节说明
# 使用Unicorn引擎之前需要手动初始化内存。我们需要将代码写入到某个地方,并且分配一些栈空间
BASE_ADDR = 0x400000 # 基址,建议与IMAGE_BASE保持一致
STACK_ADDR = 0x0 # 栈地址
STACK_SIZE = 1024 * 1024 # 栈空间
mu.mem_map(BASE_ADDR, 1024 * 1024)
mu.mem_map(STACK_ADDR, STACK_SIZE) # mem_map函数来映射内存
mu.mem_write(BASE_ADDR, read("./fibonacci")) # read仅仅返回文件中的内容,加载二进制文件到基址上
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 1) # 初始化RSP寄存器指向栈底(倒着的)
black_list = [0x4004EF, 0x4004F6, 0x400502, 0x40054F]
def hook_code(mu, address, size, user_data): # 在启动之前写一个hook函数来输出调试信息
# print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' % (address, size))
# 四个参数分别是:Uc实例句柄、指令的地址、执行的长度、用户自定义的数据,这个自定义的数据可以在hook_add的可选参数中随便挑一个
if address in black_list: # 跳过会报错的指令
mu.reg_write(UC_X86_REG_RIP, address + size)
elif address == 0x400560: # 有输出函数的地方直接输出
flag = mu.reg_read(UC_X86_REG_EDI)
print(chr(flag), end="")
mu.reg_write(UC_X86_REG_RIP, address + size)
mu.hook_add(UC_HOOK_CODE, hook_code) # 添加hook
mu.emu_start(0x4004E0, 0x400575) # 启动模拟执行,从main开始,到while外面的IO_putc结束
运行一下发现:确实能跑了,但比以前还慢了

那么现在该提速了
程序提速
我们已经成功的模拟执行了原程序,现在该分析一下如何将原程序的运行效率提高。
在IDA中可以发现,原程序的斐波那契函数是用递归方式实现的,并且该函数被反复调用了。显然,用记忆化搜索能极大地提升效率(不会的建议百度一下)。
再看到sub_400670函数。他带有两个参数,第一个参数是一个整型,保存在寄存器EDI中,第二个参数是一个指针,保存在寄存器RSI中,最终的返回值保存在RAX中,当然,RSI保存的指针值也会同返回值一样改变。
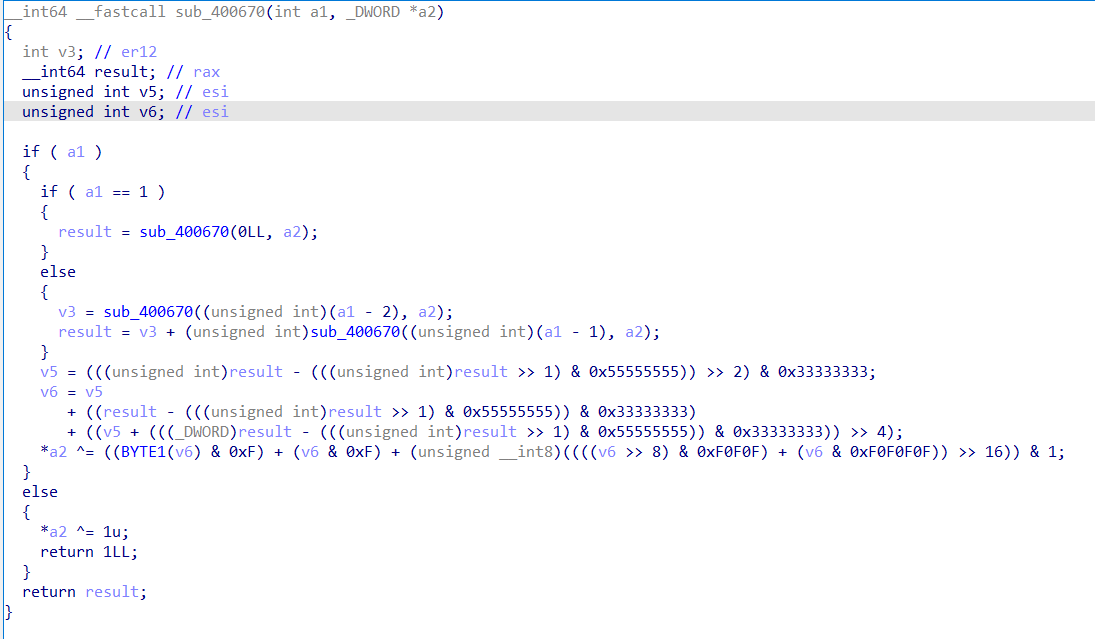
考虑用dp数组保存这两个参数是否被访问过,来形成记忆化搜索。由于函数本身是递归调用的,我们还需要用一个栈来存储每个参数对应的返回值;此外,由于递归的特性,我们在返回的时候由于函数本身处于hook中,所以我们需要从其它没有被hook的函数中随便找一个retn指令进行返回。
现在,我们得出最终的exp:
from unicorn import * # 加载主要的二进制模块,以及Unicorn中的基本常量
from unicorn.x86_const import * # 加载一些特定的x86和x64常量
import struct
from pwn import *
# 下面这三个是常用函数,直接用pwntools也行
# def read(name): #返回文件中的内容
# with open(name) as f:
# return f.read()
#
# def u32(data): #把四字节的bytes array转换为integer,以小端序表示
# return struct.unpack("I", data)[0]
#
# def p32(num): #与上一个相反
# return struct.pack("I", num)
mu = Uc(UC_ARCH_X86, UC_MODE_64) # 为x86-64架构初始化Unicorn引擎。第一个参数:架构类型,第二个参数:架构细节说明
# 使用Unicorn引擎之前需要手动初始化内存。我们需要将代码写入到某个地方,并且分配一些栈空间
BASE_ADDR = 0x400000 # 基址
STACK_ADDR = 0x0 # 栈地址
STACK_SIZE = 1024 * 1024 # 栈空间
mu.mem_map(BASE_ADDR, 1024 * 1024)
mu.mem_map(STACK_ADDR, STACK_SIZE) # mem_map函数来映射内存
mu.mem_write(BASE_ADDR, read("./fibonacci")) # read仅仅返回文件中的内容,加载二进制文件到基址上
mu.reg_write(UC_X86_REG_RSP, STACK_ADDR + STACK_SIZE - 1) # 初始化RSP寄存器指向栈底(倒着的)
black_list = [0x4004EF, 0x4004F6, 0x400502, 0x40054F]
ENTRY_ADDR = 0x400670 # 斐波那契函数的起始点
END_ADDR = [0x4006F1, 0x400709] # 斐波那契函数的结尾,有两处
stack = []
dp = {}
def hook_code(mu, address, size, user_data): # 在启动之前写一个hook函数来输出调试信息
# print('>>> Tracing instruction at 0x%x, instruction size = 0x%x' % (address, size))
# 四个参数分别是:Uc实例句柄、指令的地址、执行的长度、用户自定义的数据,这个自定义的数据可以在hook_add的可选参数中随便挑一个
if address in black_list: # 跳过会报错的指令
mu.reg_write(UC_X86_REG_RIP, address + size)
elif address == 0x400560: # 有输出函数的地方直接输出
flag = mu.reg_read(UC_X86_REG_EDI)
print(chr(flag), end="")
mu.reg_write(UC_X86_REG_RIP, address + size)
elif address == ENTRY_ADDR:
arg_0 = mu.reg_read(UC_X86_REG_EDI)
rsi = mu.reg_read(UC_X86_REG_RSI)
arg_1 = u32(mu.mem_read(rsi, 4)) # 访问rsi指向的地址保存的数据
# 如果这种情况已经被访问过,就把dp数组中的第一个参数赋给RAX寄存器,第二个参数的数据写入RSI指向的地址中
if (arg_0, arg_1) in dp:
(ret_rax, ret_rsi) = dp[(arg_0, arg_1)]
mu.reg_write(UC_X86_REG_RAX, ret_rax)
mu.mem_write(rsi, p32(ret_rsi))
mu.reg_write(UC_X86_REG_RIP, 0x400582)
else:
stack.append((arg_0, arg_1, rsi))
elif address in END_ADDR:
(arg_0, arg_1, rsi) = stack.pop()
ret_rax = mu.reg_read(UC_X86_REG_RAX)
ret_rsi = u32(mu.mem_read(rsi, 4))
dp[(arg_0, arg_1)] = (ret_rax, ret_rsi)
mu.hook_add(UC_HOOK_CODE, hook_code) # 添加hook
mu.emu_start(0x4004E0, 0x400575) # 启动模拟执行,从main开始,到while外面的IO_putc结束


 浙公网安备 33010602011771号
浙公网安备 33010602011771号