【论文阅读】Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings[NAACL2018]
腾讯AI实验室训练的词向量产物
论文地址:https://aclanthology.org/N18-2028.pdf
大规模中文词嵌入下载地址:https://ai.tencent.com/ailab/nlp/en/embedding.html
Abstract
在本文中,我们提出了方向跳跃图(DSG),这是一种简单但有效的跳跃图模型的增强,通过在单词预测中明确区分左右上下文。在此过程中,为每个单词引入一个方向向量,从而不仅通过单词在其上下文中的共现co-occurrence模式,而且通过其上下文单词的方向来学习单词的嵌入。关于复杂性的理论和实证研究表明,与skip-gram模型的其他扩展相比,我们的模型可以像原始skip-gram模型一样有效地训练。实验结果表明,在不同的数据集上,我们的模型分别在语义(词语相似度度量)和句法(词性标注)评估方面优于其他模型。
1 Introduction
单词嵌入及其相关技术对自然语言处理(NLP)至关重要(Bengio等人,2003年;Collobert和Weston,2008年;Turney和Pantel,2010年;Collobert等人,2011年;Weston等人,2015年;Song和Lee,2017年)。带负采样的skip-gram(SG)模型(Mikolov等人,2013a,c)是学习单词嵌入的流行选择,由于其高效的培训和在下游应用中的良好性能,在社区中产生了巨大的影响。尽管SG模型广泛用于多词表,但它在单词预测中依赖于本地上下文中的单词共现,而忽略了诸如词序、位置等更详细的信息。
为了改进原始单词嵌入模型,有各种研究利用外部知识,通过后处理更新单词嵌入(Faruqui等人,2015;Kiela等人,2015;Song等人,2017)或监督目标(Yu和Dredze,2014;Nguyen等人,2016)。然而,这些方法受到可靠语义资源的限制,这些资源很难获取或注释。为了克服这些限制,有许多方法可以进一步利用运行文本的特征,例如,上下文的内部结构。这些方法包括考虑词序扩大投影层(Bansal等人,2014;Ling等人,2015a),学习不同权重的上下文词(Ling等人,2015b),等等。它们有利于以端到端的无监督方式学习单词嵌入,而无需额外资源。然而,它们的实现也受到限制,例如它们通常需要更大的隐藏层或额外的权重,这需要更高的计算负担,并且当嵌入维数增大时可能导致梯度爆炸。另一个问题是,在考虑词序时,它们可能会遇到数据稀疏问题,因为gram覆盖率远小于word,特别是在训练数据有限的新领域的冷启动场景中。
2 Approach
2.1 Skip-Gram Model
SG模型(Mikolov等人,2013b)是一种通过利用单词与其相邻单词之间的关系来学习单词嵌入的流行选择。具体来说,SG模型是预测每个给定word $w_t$ 的上下文,并最大化
$\mathcal{L}_{S G}=\frac{1}{|V|} \sum_{t=1}^{|V|} \sum_{0<|i| \leq c} \log f\left(w_{t+i}, w_{t}\right)$
关于给定的词汇语料库$V$,其中$w_{t+i}$表示窗口中的上下文词$w_{t-c}^{t+c}$,$c$是窗口大小,本文中$f\left(w_{t+i}, w_{t}\right)=$$p\left(w_{t+i} \mid w_{t}\right)$,预测上下文词的概率由
$p\left(w_{t+i} \mid w_{t}\right)=\frac{\exp \left(v_{w_{t+i}}^{\prime}{ }^{\top} v_{w_{t}}\right)}{\sum_{w_{t+i} \in V} \exp \left(v_{w_{t+i}}^{\prime}{ }^{\top} v_{w_{t}}\right)}$
其中$v_{w_{t}}$是$w_{t}$的embedding,$v$和$v^{'}$分别指的是输入输出向量。因此,SG模型的训练过程是对语料库进行迭代最大化$\mathcal{L}_{S G}$。对于大型词汇表,Word2Vec使用分层softmax或负采样(Mikolov等人,2013b)来解决需要$|V| \times d$ 矩阵乘法的计算复杂性。
2.2 Structured Skip-Gram Model 结构化Skip Gram模型
SSG模型(Ling等人,2015a)是SG模型的一种改编,考虑了单词的顺序。SSG模型的总体可能性与等式1具有相同的SG模型形式,但是,具有自适应的$f\left(w_{t+i}, w_{t}\right)$,其中预测$w_{t+i}$的概率不仅考虑单词-单词关系,还考虑其与$w_t$的相对位置。实际上,每个单词$w_{t-c}^{t+c}$不是在输出embedding$v^{'}_{w_{t+i}}$上运行的单个预测器来预测的。相反,$w_{t+i}$是根据$w_t$在上下文中出现的位置由$2c$个预测器预测的。因此,SSG中的每个单词都应该有2c个相对位置的2c个输出嵌入。因此,预测$w_{t+i}$ SSG的概率公式如下:
$p\left(w_{t+i} \mid w_{t}\right)=\frac{\exp \left(\sum_{r=-c}^c v_{r,w_{t+i}}^{\prime}{ }^{\top} v_{w_{t}}\right)}{\sum_{w_{t+i} \in V} \exp \left(\sum_{r=-c}^c v_{r,w_{t+i}}^{\prime}{ }^{\top} v_{w_{t}}\right)}$
其中,$v_{r,w_{t+i}}$定义为$w_{t+i}$在位置$r$相对于$w_t$ 的positional输出embedding. $w_t$的embedding因此隐式地更新入了$v_{r,w_{t+i}}$.
2.3 Directional Skip-Gram Model
这个模型背后的直觉是,词序是影响我们语言生成的一个重要因素;一个单词应该与左边或右边的其他单词相关联。例如,在“圣诞快乐merry Christmas”和“平安夜Christmas eve”中,“欢乐merry”和“平安夜eve”分别与“圣诞节”频繁同时出现。考虑到上下文单词“Christmas”,识别要预测的单词位于左侧或右侧对于学习“merry”和“eve”的嵌入非常有用。【尽管SSG也可以对这种情况进行建模,因为“merry”和“eve”通常在固定位置与“Christmas”关联,但本示例的目的是说明通过区分左右上下文可以有效地对单词序列进行建模。】基于此,我们提出了一个softmax函数
$g(w_{t+i},w_{t})=\frac{exp(\delta_{w_{t+i}}{ }^{\top}v_{w_t})}{\sum_{w_{t+i}\in V}exp (\delta_{w_{t+i}}{ }^{\top}v_{w_t})}$
要测量上下文单词$w_{t+i}$在其左或右上下文中与$w_t$关联的方式,请为每个$w_{t+i}$引入一个新的向量$\delta$,以表示其相对于$w_t$的方向。该函数$g$共享与负采样类似的更新范例shares an updating paradigm similar to negative sampling:
$v_{w_t}^{(new)}=v_{w_t}^{(old)}-\gamma (\sigma (v_{w_t}^{\top}\sigma_{w_{t+i}})-D)\delta_{w_{t+i}}$
$\delta_{w_{t+i}}^{(new)}=\delta_{w_{t+i}}^{(old)}-\gamma (\sigma (v_{w_t}^{\top}\sigma_{w_{t+i}})-D)v_{w_{t}}$
其中$\sigma$表示sigmoid函数,\gamma表示\gamma学习率。具体而言,$D$是指定$w_{t+i}$ givenwt的相对方向的目标标签,定义为
$$ D = \left\{ \begin{array}{lr} 1 & : i < 0\\ 0 & : i > 0 \end{array} \right. $$
$w_{t+i}$着眼于$w_t$的相对位置。最终等式1中的$f$定义为:$f(w_{t+i},w_t)=p(w_{t+i}|w_t)+g(w_{t+i},w_t)$
2.4 Complexity Analysis2.4复杂性分析
为了定性分析我们提出的模型的效率,我们绘制了表1,其中比较了上述SG模型的复杂性。Parameters(参数)列报告参数大小,它表示空间复杂度。Operations column报告计算中的操作数,与时间复杂度有关。请注意,上述复杂性分析基于负采样。如果使用分层softmax,可以替换$n+1$ into $h$,它表示分层树的平均深度。
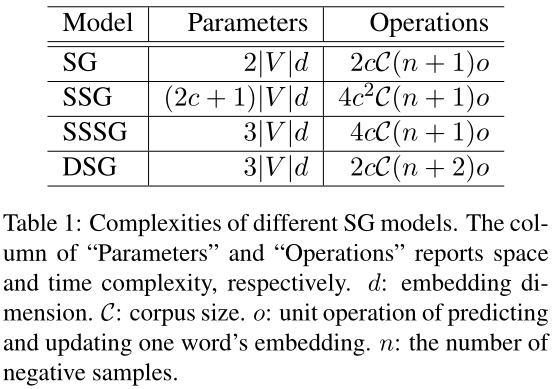
表1:不同SG型号的复杂性。“Parameters”和“Operations”列分别报告了空间和时间复杂性。d:嵌入维度。C:语料库大小。o:预测和更新一个单词嵌入的单元操作。n:负样本数
与SG模型相比,当上下文变大时,SSG模型在空间和时间上的复杂度都明显提高,而DSG模型中的每个单词只需要在原始SG模型的基础上进行一次额外的操作。因此,如果扩大上下文,DSG模型可以具有与SG模型相似的速度。
为了公平地比较我们的模型和SSG的效率,我们另外提出了一个简化的SSG(SSSG)模型,该模型只对给定单词的左右上下文建模。SSG中的每个单词只有两个表示左右上下文的输出嵌入,而不是在SSG中有2C输出嵌入。这是我们的模型在SSG框架内的近似值。在输出端,SSSG有两个“word”向量,分别用于左上下文和右上下文,而DSG有一个“word”向量和一个“direction”向量。因此,DSG的方向向量可以在单词预测中显式地预测上下文是在左边还是在右边,而SSSG不能。
3 Experiments
我们使用内在和外在评估来评估不同嵌入的有效性。为了验证§2.4中的分析,我们根据上述SGmodels的训练速度对其效率进行了调查。所有实验的设置如下所示。
Dataset.
这些嵌入是在最新的维基百科文章上进行训练的,其中包含大约20亿个单词的标记。
Comparison.对比
由于本文的重点是加强SG模型,我们主要考虑SG模型(Mikolov等人,2013B),SSG模型(Lin等人,2015A)及其简化版本SSSG模型,作为基线进行比较。
Settings.
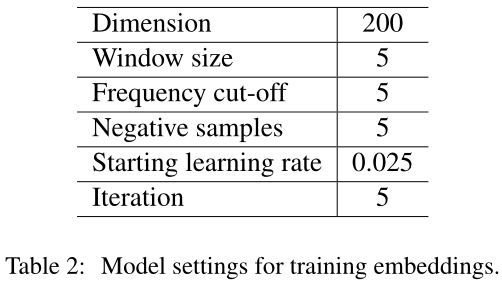
不同的模型在训练单词嵌入时共享相同的超参数,如表2所示。
3.1 Training Speed
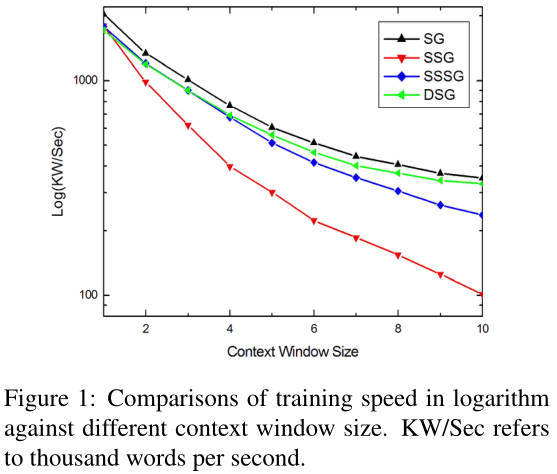
图1说明了不同SG模型(即SG、SSG、SSSG和DSG)的训练速度,给出了不同大小的上下文窗口。与原始SG模型相比,SSG模型在扩大上下文窗口时显示了相对较大的速度下降,而DSG模型观察到的下降要小得多。总体而言,四个模型的曲线大致符合表1中的定性分析。当仅从一个上下文单词开始时,SSG、SSSG和DSG模型共享相似的训练速度,因为在这种情况下,它们的时间复杂性不受有限上下文窗口大小的影响。当扩大上下文窗口时,SSG和SG模型之间的速度差距越来越大,而DSG和SG之间的差距越来越小【请注意,表1中的推导表示复杂性的上限,即每两个单词在上下文窗口中同时出现,这在实际场景中几乎不会发生。因此,观察到的差距比表1中所示的要小一些。】。
3.2 Word Similarity Evaluation
作为一种传统的内在评估,对MEN-3k(Bruni等人,2012年)、SimLex-999(Hill等人,2015年)和WordSim-353(Finkelstein等人,2002年)数据集进行单词相似性测试,以对不同嵌入进行定量比较。采用斯皮尔曼等级相关性(ρ)(Zar,1998)来衡量三个数据集上的相似性得分与人类判断的接近程度。除了SG、SSG和SSSG之外,我们还将CBOW和CWin作为词语相似度评估的参考基线。
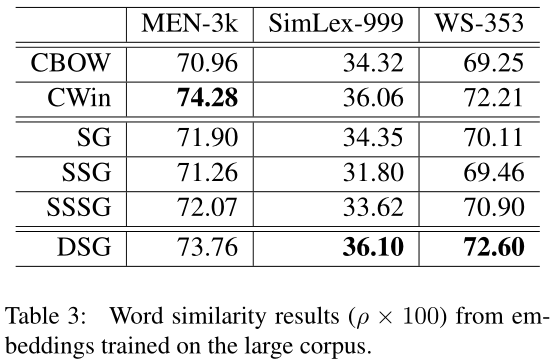
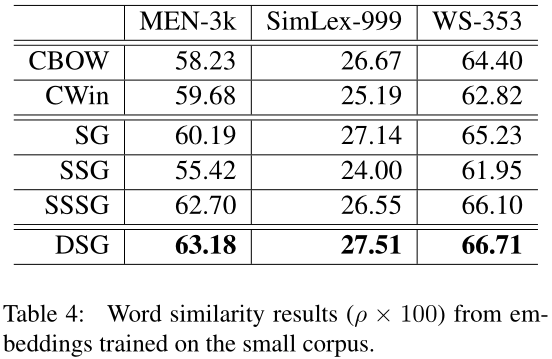
表3报告了在整个维基语料库上训练嵌入时的单词相似性结果。此外,我们还通过抽取0.1%的Wiki数据创建了一个小语料库,以模拟使用有限数据训练单词嵌入的冷启动场景。表4中报告了这个小语料库上所有模型的单词相似性表现。总体而言,在小数据集上训练时,所有模型的结果都较差,尤其是考虑上下文结构信息的模型,如CWin和SSG。究其原因,主要是由于建模顺序依赖性对数据稀疏性敏感,因此CWin模型无法为小语料库中普遍存在的低频词生成有意义的表示。这一观察结果表明,数据稀疏性问题是学习单词嵌入的关键。然而,DSG在不同规模的训练数据上产生了稳健的结果,这表明我们的模型提供了一种有效的解决方案,可以利用上下文中的结构来学习嵌入,同时不会严重受到数据稀疏性问题的影响。特别是在所有的SG模型中,DSG在大语料库或小语料库上训练时表现最好。这一事实进一步证明了区分SG嵌入的左右上下文的有效性。
3.3 Part-of-Speech Tagging
除了在语义上测试嵌入的内在评价外,我们还通过一种外在评价(词性标记)在句法上评价不同的嵌入。继Ling等人(2015a)之后,这项任务在新闻和社交媒体数据中执行。对于新闻数据,我们使用《华尔街日报》(WSJ)从宾夕法尼亚树状银行(Marcus et al.,1993)获得的比例,并分别按照38219/5527/5462句的标准划分进行训练、发展和测试。社交媒体数据基于ARK数据集(Gimpel et al.,2011),其中包含英语推文上的手动POS注释。ARK的标准拆分包含1000/327/500条推文,分别作为training/development/test。
POS预测由双向LSTM-CRF(Huang等人,2015;Lample等人,2016)进行,将产生的embedding作为输入。LSTM状态大小设置为200。对于《华尔街日报》,我们使用前面提到的从维基语料库训练的嵌入。对于ARK,我们准备了一个Twitter语料库(TWT)来构建嵌入。该数据包含通过推特流API收集的1亿条推特,然后使用Owoputi等人(2013)中描述的工具包进行预处理。TWT嵌入按照与Wiki嵌入相同的程序进行训练。与单词相似性任务类似,我们在该任务中使用CBOW、SG、CWin、SSG和SSSG作为基线。
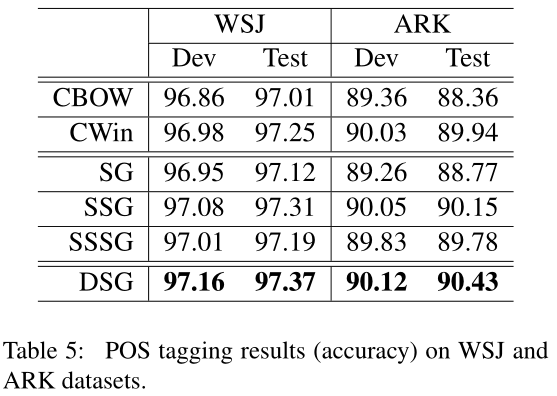
结果见表5。我们观察到,相比之下,DSG嵌入可以最好地指示POS标记。这表明,通过从左右两个方向探索单词上下文,DSG模型可以有效地捕获句法信息,这有助于预测词性标记。虽然在TWT上训练的嵌入可能会受到tweets的噪音和非正式性质的影响,但使用DSG嵌入的POS标记器在ARK数据上实现了最佳精度。这一观察结果表明,在噪声数据上学习具有上下文结构的单词嵌入时,DSG比SSG和SSSG等其他模型有其优越性。
4 Conclusions
本文介绍了DSG,它是学习单词嵌入的SG模型的一个简单而有效的扩展。给定一个输入词,我们的模型联合预测其上下文词以及它们指向给定词的方向。分析和实验表明,该模型的训练速度与原始SG模型相当。词语相似度评估和词性标注实验表明,与竞争基线相比,DSG能产生更好的语义和句法表示。更重要的是,还证明了DSG在小数据集上训练时可以有效地预测单词相似性,因此与现有方法相比,DSG对数据稀疏性的敏感度较低。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号