
【论文阅读】Glyce: Glyph-vectors for Chinese Character Representations[NeurIPS2019]
论文地址:https://arxiv.org/pdf/1901.10125.pdf
代码地址:https://github.com/ShannonAI/glyce
Glyce:汉字表示的字形向量
Abstract
直观地说,像中文这样的标识语言的NLP任务应该受益于这些语言中字形信息的使用。然而,由于字形中缺乏丰富的象形证据,以及标准计算机视觉模型对字符数据的泛化能力较弱,利用字形信息的有效方法仍有待找到。
在本文中,我们通过介绍Glyce(汉字表示的字形向量)来解决这一差距。我们进行了三大创新:(1)使用历史汉字(如青铜器文字、篆书、繁体中文等),以丰富汉字的象形证据;(2) 我们设计了适合汉字图像处理的CNN结构(称为天则阁CNN,tianzege-CNN);(3)在多任务学习系统中,我们使用图像分类作为辅助任务,以提高模型的泛化能力。
我们表明,基于glyph的模型能够在广泛的中文NLP任务中始终优于基于word/char ID-based的模型。我们能够为各种中文NLP任务设置最新的结果,包括标记(NER、CWS、POS)、句子对分类、单句分类任务、依存分析和语义角色标记。例如,该模型在OntoNotes数据集NER上的F1得分为80.6,在BERT上再加+1.5;在复旦语料库的文本分类中,它达到了几乎完美的99.8%的准确率。
1 Introduction
据报道,使用Wubi方案(一种模拟在计算机键盘上键入字符部首序列顺序的汉字编码方法)可以提高汉英机器翻译的性能[Tan等人,2018]。Cao等人[2018]深入研究了更大粒度的单位,并提出了字符建模的笔划n-gram。
最近,已经有一些努力应用基于CNN的算法对字符的视觉特征。不幸的是,它们并没有表现出持续的绩效提升[Liu等人,2017年,Zhang和LeCun,2017年],有些甚至产生负面结果[Dai和Cai,2017年]。例如,Dai和Cai[2017]在字符徽标char logos上运行CNN,以获得汉字表示,并将其用于下游语言建模任务。他们报告说,合并字形表示实际上会恶化性能,并得出结论,基于CNN的表示不能为语言建模提供额外有用的信息。使用类似的策略,Liu等人[2017]和Zhang及LeCun[2017]在文本分类任务中测试了该想法,并且仅在非常有限的设置中观察到性能提升。Su和Lee[2017]得出了积极的结果,他们发现字形嵌入有助于完成两项任务:单词类比和单词相似性。不幸的是,Su和Lee[2017]只关注单词级语义任务,没有将单词级任务的改进扩展到更高级别的NLP任务,如短语、句子或语篇级。结合部首表示法,邵等人[2017]在字符图形上运行CNN,并将输出作为词性标注任务中的辅助特征。
对于早期基于CNN的模型[Dai和Cai,2017]中报告的负面结果,我们提出以下解释:(1)没有使用正确版本的脚本:汉字系统有着悠久的进化历史。这些角色从易于绘制开始,慢慢过渡到易于书写。而且,随着时间的推移,它们变得越来越不象形,越来越不具体。到目前为止,使用最广泛的脚本版本,简体中文,是最容易书写的脚本,但不可避免地丢失了最大量的象形文字信息。例如,”人” (人类)和“入” (enter)在简体中文中具有高度相似的形状,但在历史语言(如青铜器文字)中却有很大的不同。(2) 未使用正确的CNN结构:与ImageNet图像[Deng等人,2009]不同,ImageNet图像的尺寸大多为800*600,字符徽标character logos明显更小(通常为12*12)。它需要一个不同的CNN架构来捕获角色图像的局部图形特征;(3) 以前的工作中没有使用任何监管功能 regulatory functions:与imageNet数据集上的分类任务不同,该数据集包含数千万个数据点,只有大约10000个汉字。因此,辅助训练目标对于防止过度拟合和提高模型的概括能力至关重要。
在本文中,我们提出了GLYCE,汉字表示的字形向量the GLYph-vectors for Chinese character representations。我们将汉字视为图像,并使用CNN获取其表示。我们通过使用以下关键技术解决上述问题:
1.我们使用历史和当代文字(如青铜器文字、隶书、篆书、繁体中文等)以及不同书写风格的文字(如草书)的组合,以丰富字符图像中的象形文字信息。
2.We utilize the Tianzige-CNN (田字格) structures tailored to logographic character modeling.
3.我们使用多任务学习方法,通过添加图像分类损失函数来提高模型的泛化能力。
GLYCE被发现可以改善中国NLP任务的很多方面。我们能够在广泛的中文NLP任务中获得SOTA性能,包括标记(NER、CWS、POS)、句子对分类(BQ、LCQMC、XNLI、NLPCC-DBQA)、单句分类任务(CHNSTICORP、复旦语料库、iFeng)、依存分析和语义角色标记。
2 Glyce
2.1 Using Historical Scripts
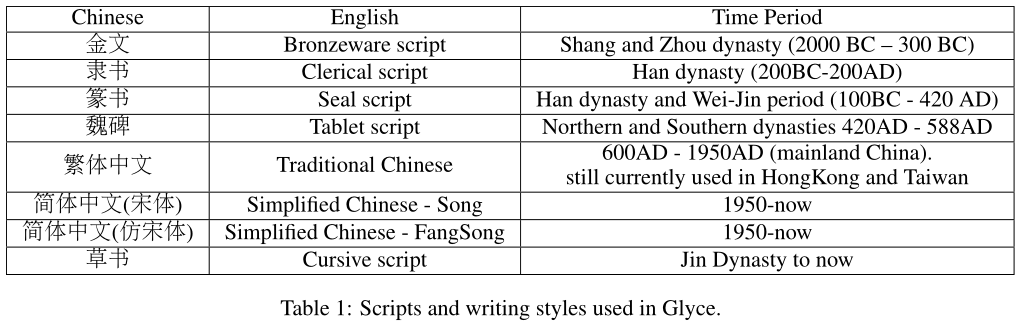
如第1节所述,简体中文中的象形文字信息严重丢失。因此,我们建议使用历史上不同时期以及不同写作风格的脚本。我们收集了以下主要历史脚本,详细信息如表1所示。来自不同历史时期的文字,其形状通常非常不同,有助于模型整合来自不同来源的象形文字证据;不同写作风格的脚本有助于提高模型的概括能力。这两种策略类似于计算机视觉中广泛使用的数据增强策略。
2.2 The Tianzige-CNN Structure for Glyce
在我们的任务中,直接使用deep CNNs He et al.[2016],Szegedy et al.[2016],Ma et al.[2018a]会导致非常差的性能,因为(1)字符图像的大小相对较小:Imagenet图像的大小通常为800*600,而汉字图像的大小明显较小,通常在12*12的范围内;(2)缺乏训练示例:imageNet数据集上的分类利用了数千万张不同的图像。相比之下,只有大约10000个不同的汉字。

为了解决这些问题,我们提出了田字格CNN结构,该结构适合于汉字建模,如图1所示。天子阁(田字格) 是中国书法的传统形式。它是一种四方形格式(类似于汉字)田) 供初学者学习书写汉字。输入图像最大化首先通过一个内核大小为5的卷积层和1024个输出通道来捕获低级图形特征。然后对特征映射应用内核大小为4的最大池,将分辨率从8×8降低到2×2。此2×2天字格结构呈现部首在汉字中的排列方式以及汉字的书写顺序。最后,我们应用了群卷积group convolutions[Krizhevsky等人,2012,Zhang等人,2017]与传统的卷积运算不同,它可以将天子格网格映射到最终输出。组卷积滤波器比普通滤波器小得多,因此不太容易过度拟合。将模型从单个脚本调整为多个脚本相当容易,只需将输入从2D更改即可(即$d_{font}×d_{font}$)到3D(即$d_{font}×d_{font}×N_{script}$),其中$d_{font}$表示字体大小,$N_{script}$表示我们使用的脚本数量。
2.3 Image Classification as an Auxiliary Objective 图像分类作为辅助目标
为了进一步防止过度拟合,我们使用图像分类任务作为辅助训练目标。来自CNN的glyph Embedding $H_{image}$将被转发到图像分类目标,以预测其相应的charID。Suppose the label of image $x$ is $z$。图像分类任务$L(cls)$的训练目标如下:
$\begin{aligned} \mathcal{L}(\mathrm{cls}) &=-\log p(z \mid x) \\ &=-\log \operatorname{softmax}\left(W \times h_{\mathrm{image}}\right) \end{aligned}$
让 $L(task)$表示我们需要处理的任务的任务特定目标,例如语言建模、分词等。我们将$L(task)$和$L(cls)$线性组合,使最终目标训练函数如下所示:
$\mathcal{L}=(1-\lambda(t)) \mathcal{L}($ task $)+\lambda(t) \mathcal{L}($ cls $)$
式中,$\lambda (t)$控制任务特定目标和辅助图像分类目标之间的权衡。$λ$是epochs $t$的函数:$\lambda(t)=\lambda_{0} \lambda_{1}^{t}$,其中$λ_0∈[0,1]$表示起始值$λ_1∈[0,1]$表示衰减值。这意味着图像分类目标的影响随着训练的进行而减小,直观的解释是,在训练的早期阶段,我们需要对图像分类任务进行更多的规定。将图像分类作为训练目标模仿了多任务学习的思想。
2.4 Combing Glyph Information with BERT
glyph嵌入可以直接输出到下游模型,如RNN、LSTM、transformers。
由于使用语言模型的大规模预训练系统,如BERT[Devlin et al.,2018]、ELMO[Peters et al.,2018]和GPT[Radford et al.,2018]在广泛的NLP任务中被证明是有效的,我们探索了将字形嵌入与BERT嵌入相结合的可能性。这种策略将潜在地赋予该模型同时具备字形证据和大规模预训练的优势。组合的概述如图2所示。该模型由四层组成:BERT层、glyph层、Glyce-BERT层和特定于任务的输出层。
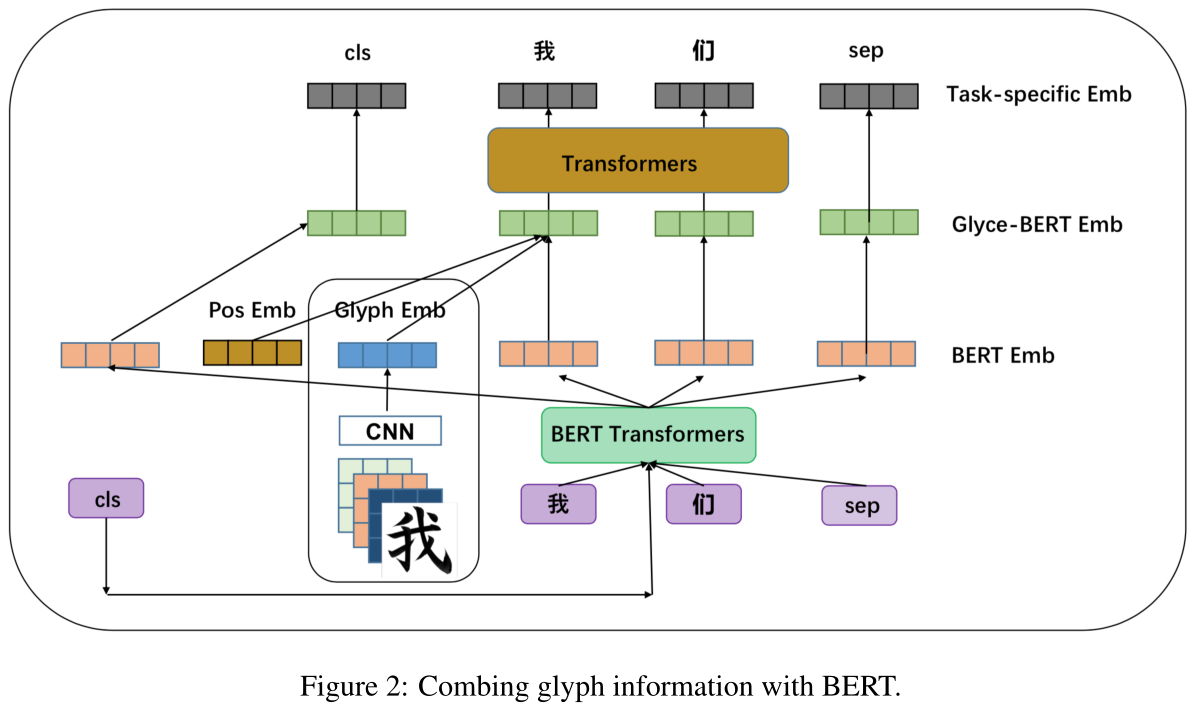
BERT Layer :输入句子$S$与表示句子开头的特殊字母$CLS$和表示句子结尾$SEP$的字母连接在一起。给定一个预训练的BERT模型,使用BERT计算每个token的embedding。我们使用BERT transformer最后一层的输出来表示当前token。
Glyph Layer : the output glyph embeddings of $S$ from tianzege-CNNs.
Glyce-BERT layer: Position embeddings are first added to the glyph embeddings. The addition is then concatenated with BERT to obtain the full Glyce representations.
Task-specific output layer: Glyce表示用于表示该位置的标记,类似于单词嵌入或Elmo emebddings[Peters等人,2018]。Contextual-aware信息已编码在BERT表示中,但未编码在glyph表示中。因此,我们需要额外的上下文模型来编码上下文感知字形表示。在这里,我们选择多层Transformers[Vaswani等人,2017]。Transformer的输出表示用作预测层的输入。值得注意的是,special CLS and SEP tokens的表示在最终的特定任务的嵌入层进行维护。
3 Tasks
在本节中,我们将描述如何将glypg嵌入用于不同的NLP任务。在普通版本中,glyph嵌入被简单地视为字符嵌入,它被提供给构建在单词嵌入层之上的模型,例如RNN、CNN或更复杂的模型。如果与BERT结合,我们需要在不同的场景中具体处理字形嵌入和BERT预训练嵌入之间的集成,如下所述:
Sequence Labeling Tasks
许多中文NLP任务,如名称实体识别(NER)、中文分词(CWS)和词性标注(POS),可以形式化为字符级character-level序列标注任务,其中我们需要预测每个字符的标签。对于glyce-BERT模型,任务特定层(如第2.4节所述)的embedding output被馈送至CRF模型,用于标签预测。
Single Sentence Classification
对于文本分类任务,将为整个句子预测一个标签。在BERT模型中,最后一层BERT中的记录表示将输出到softmax层进行预测。我们采用了类似的策略,将任务特定层中的字符表示形式反馈给softmax层,以预测标签。
Sentence Pair Classification
对于SNIS等句子对分类任务[Bowman et al.,2015],模型需要处理两个句子之间的交互,并输出一对句子的标签。在BERT设置中,一个句子对$(s_1,s_2)$与一个$CLS$和两个$SEP$标记连接,由$[CLS,s_1,SEP,s_2,SEP]$表示。连接被馈送到BERT模型,然后获得的$CLS$表示被馈送到softmax层用于标签预测。我们对Glyce-BERT采用类似的策略,其中$[CLS,s_1,SEP,s_2,SEP]$随后通过BERT层、Glyce-BERT层、Glyce-BERT层和特定于任务的输出层。来自任务特定输出层的CLS表示被馈送到softmax函数,用于最终标签预测。
4 Experiments
4.1 Tagging
NER
对于中文NER任务,我们使用了广泛使用的OnNotes、MSRA、微博和简历数据集。由于大多数数据集没有黄金分割标准,因此该任务通常被视为字符级标记任务char-level tagging task:为每个字符输出一个NER标记。目前使用最广泛的非BERT模型是Lattice LSTM[Y ang等人,2018年,Zhang和Y ang,2018年],其性能优于CRF+LSTM[Ma和Hovy,2016年]。

CWS
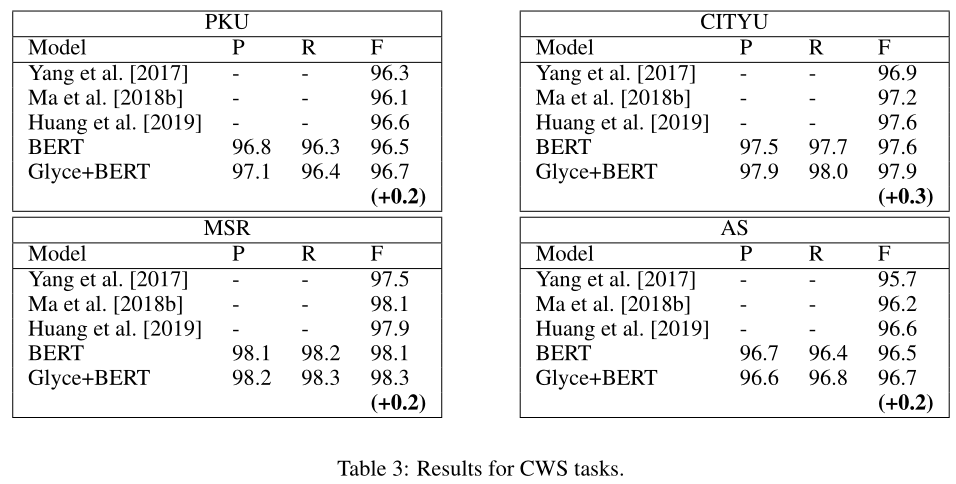
中文分词的任务通常被视为一个字符级char-level的标注问题。我们使用了广泛使用的北大、MSR、CITYU和SIGHAN 2005年作为基准进行bake-off for evaluation。
POS
中文词性标注任务通常形式化为字符级序列标注任务,为序列中的每个字符分配标签。我们使用CTB5、CTB9和UD1(通用依赖项)基准测试我们的模型。
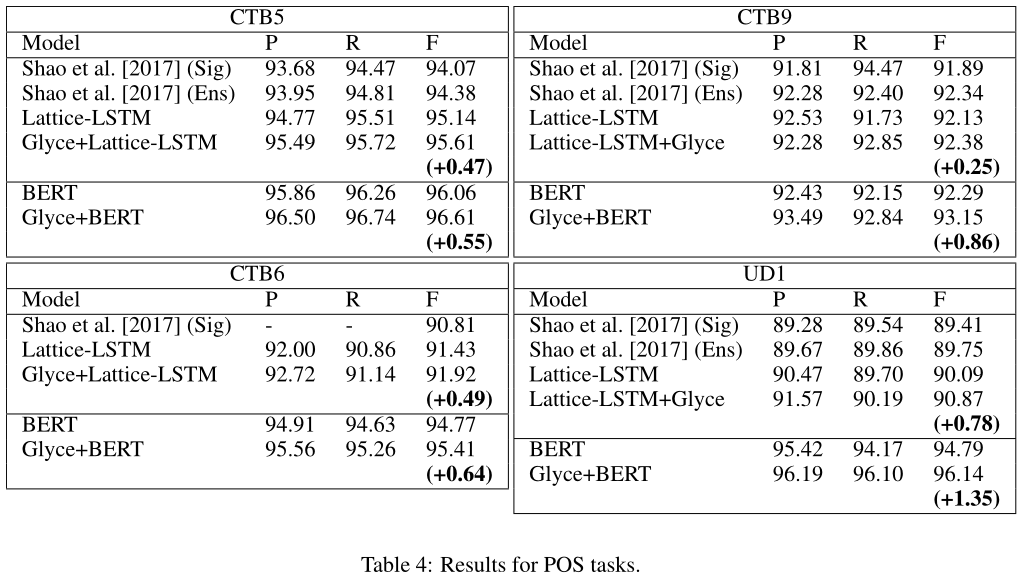
NER、CWS和POS的结果分别如表2、3和4所示。与非BERT模型相比,Lattice-Glyce在所有任务的所有数据集中的表现都优于所有非BERT模型。在除微博外的所有数据集中,伯特模型都优于非伯特模型。这是由于伯特预培训的数据集(即维基百科)和微博之间存在差异。Glyce-BERT模型优于BERT模型,并在所有数据集上设置了新的SOTA结果,表明了合并字形信息的有效性。我们能够使用Glyce模型本身或BERT-Glyce模型在所有数据集上实现SOTA性能。
4.2 Sentence Pair Classification
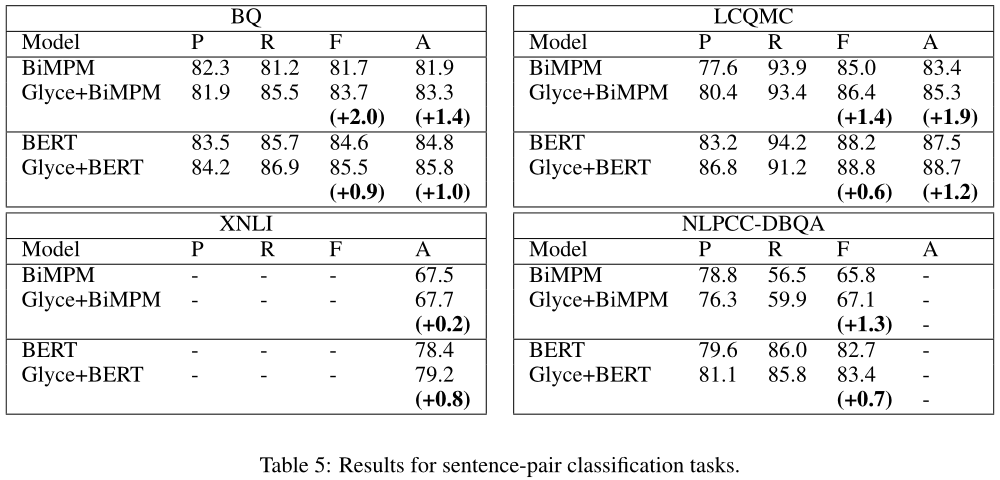
对于句子对分类任务,我们需要为每对句子输出一个标签。我们使用以下四种不同的数据集:(1)BQ(二元分类任务)[Bowman等人,2015];(2) LCQMC(二元分类任务)[Liu等人,2018],(3)XNLI(三级分类任务)[Williams和Bowman],以及(4)NLPCC-DBQA(二元分类任务)
当前的非BERT SOTA模型基于双边多视角匹配模型(BiMPM)[Wang等人,2017],该模型专门处理句子之间的亚单位subunit匹配。字形嵌入被纳入BiMPMS,形成Glyce+BiMPM基线。表5给出了不同数据集上各模型的结果。可以看出,BiPMP+Glyce的表现优于BiPMP,在非bert模型中取得了最好的结果。BERT优于所有非BERT模型,BERT+Glyce表现最好,在所有四个基准上都建立了新的SOTA结果。
4.3 Single Sentence Classification
对于单句/文档分类,我们需要输出文本序列的标签。标签可以是情绪指标,也可以是新闻类型。我们使用的数据集包括:(1)CHNSTINCorp(二进制分类);(2) 复旦语料库(五种分类)[Li,2011];和(3)Ifeng(五种分类)。
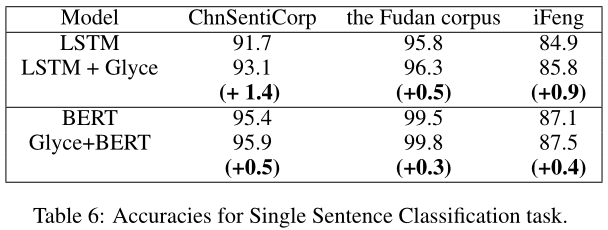
不同模型在不同任务上的结果如表6所示。我们观察到与之前类似的现象:Glyce+BERT在所有数据集上都获得了SOTA结果。具体而言,Glyce+BERT模型在复旦语料库上达到了近乎完美的准确度(99.8)。
4.4 Dependency Parsing and Semantic Role Labeling 4.4依赖项解析和语义角色标记
对于依赖项解析[Chen and Manning,2014,Dyer等人,2015],我们使用广泛使用的中国Penn Treebank 5.1数据集进行评估。我们的实现使用了以前的最先进的Deep Biafine模型Dozat和Manning[2016]作为主干。我们用Glyce单词嵌入替换了Biafine模型中的单词向量,并严格遵循其模型结构和training/dev/test分割标准。我们报告了未标记依恋分数unlabeled attachment score(UAS)和标记依恋分数(LAS)的分数。先前模型的结果摘自[Dozat和Manning,2016年,Ballesteros等人,2016年,Cheng等人,2016年]。Glyce word将SOTA的UAS和LAS得分分别提高了+0.9和+0.8。
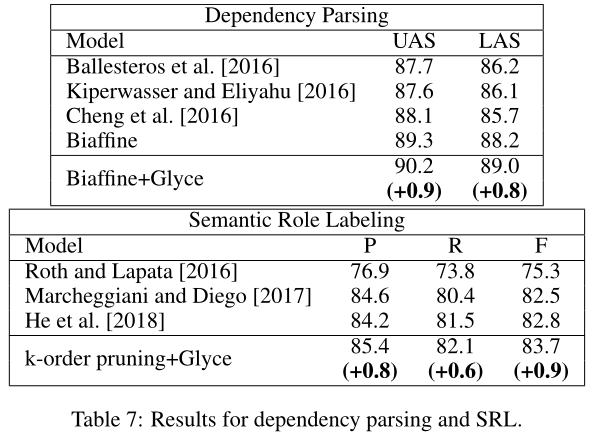
对于语义角色标记(SRL)任务[Roth和Lapata,2016年,Marcheggiani和Diego,2017年,He等人,2018年],我们使用了CoNLL-2009共享任务。我们使用当前的SOTA模型,即k阶剪枝算法[He et al.,2018]作为主干。我们将单词嵌入替换为Glyce嵌入。Glyce在F1成绩方面比之前的SOTA成绩高出0.9,新的SOTA成绩为83.7。
BERT在这两项任务中表现不具竞争力,因此结果被忽略。
5 Ablation Studies
在本节中,我们将讨论不同因素对所提出模型的影响。我们使用句子对预测任务的LCQMC数据集进行说明。我们讨论的因素包括训练策略、模型结构、辅助图像分类目标等。
5.1 Training Strategy
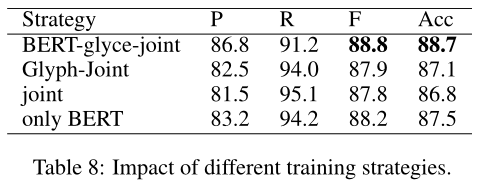
本节讨论一种训练策略(由BERT-glyce-joint表示),在这种策略中,给定特定于任务的监督,我们首先微调BERT模型,然后冻结BERT以微调字形glyph layer层,最后联合微调两个层,直到收敛。我们将此策略与其他策略进行比较,包括(1)$Glyph Joint$ strategy,其中BERT在开始时没有微调:我们首先冻结BERT来调整glyph层,然后联合调整两个层,直到收敛;(2)联合策略,直接联合训练两个模型直到收敛。
结果如表8所示。可以看出,BERT-glyce-joint 策略的表现优于其他两种策略。我们对Joint 策略性能较差的解释如下:BERT层是预训练的,而glyph层是随机初始化的。由于训练信号的数量相对较少,在训练的早期阶段,随机初始化的字形层可能会误导伯特层,从而导致较差的最终性能。
5.2 Structures of the task-specific output layer
Glyph嵌入和BERT嵌入的串联被馈送到特定于任务的输出层。特定于任务的输出层由两层transformer层组成。在这里,我们将变压器改为其他结构,如BILSTM和CNN,以探索其影响。我们还尝试了BiMPM结构Wang等人[2017]来查看结果。
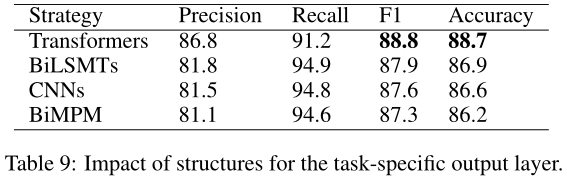
性能如表9所示。可以看出,transformers不仅优于BILSTM和CNN,还优于BiMPM结构,该结构是专门为句子对分类任务构建的。我们推测这是因为Transformer和BERT结构之间的一致性。
5.3 The image-classification training objective
我们还探讨了图像分类训练目标的影响,该目标将字形表示输出到图像分类目标。表10显示了其影响。可以看出,该辅助培训目标提高了+0.8的绩效。

5.4 CNN structures
不同CNN结构的结果如表11所示。可以看出,田字格结构的采用使F1的性能提升了约+1.0。在我们的任务中直接使用深度CNN会导致非常差的性能,因为(1)字符图像的大小相对较小:ImageNet图像的大小通常为800*600,而汉字图像的大小明显较小,通常为12*12;(2)缺乏训练示例:ImageNet数据集上的分类利用了数千万张不同的图像。相比之下,只有大约10000个不同的汉字。我们利用田字格为中文量身定做的标识字符建模。这种田字格结构在提取汉字意义方面具有重要意义。
6 Conclusion
在这篇文章中,我们提出了Glyce,用于汉字表示的字形向量。Glyce将汉字视为图像,并使用田字格CNN提取汉字语义。Glyce提供了一种通用的方法来建模标识语言的字符语义。它是一般性的和基本的。就像单词嵌入一样,Glyce可以集成到任何现有的深度学习系统中。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号