【论文阅读】Character-Based LSTM-CRF with Radical-Level Features for Chinese Named Entity Recognition[2016]
Abstract
中文命名实体识别(CNER)的最先进系统需要大量手工制作的功能和特定领域的知识才能实现高性能。在本文中,我们采用双向LSTM-CRF神经网络,该网络同时利用字符级和部首级radical-level表示。我们是第一个将基于字符的BLSTM-CRF神经结构用于CNER的人。通过对比不同类型的LSTM块的结果,我们找到了最适合CNER的LSTM块。我们也是第一个在BLSTM-CRF体系结构中研究中国部首级表示的人,并且在没有精心设计的功能的情况下获得更好的性能。我们在第三个SIGHAN Bakeoff MSRA数据集上评估了我们的系统,以简化CNER任务,并实现了90.95%的最先进性能。
1 Introduction
Char LSTM[17]被引入学习字符级序列,例如英语中的前缀和后缀。对于汉语来说,每个字符都有语义意义,这要归功于它的象形词根来自古代汉语,如图1所示[26]。图1的左半部分展示了汉字的演变过程朝” . 图1的右边部分演示了分解。这个字符“朝”, 它的意思是“早晨”,分解为4个偏旁,由12个笔划组成。
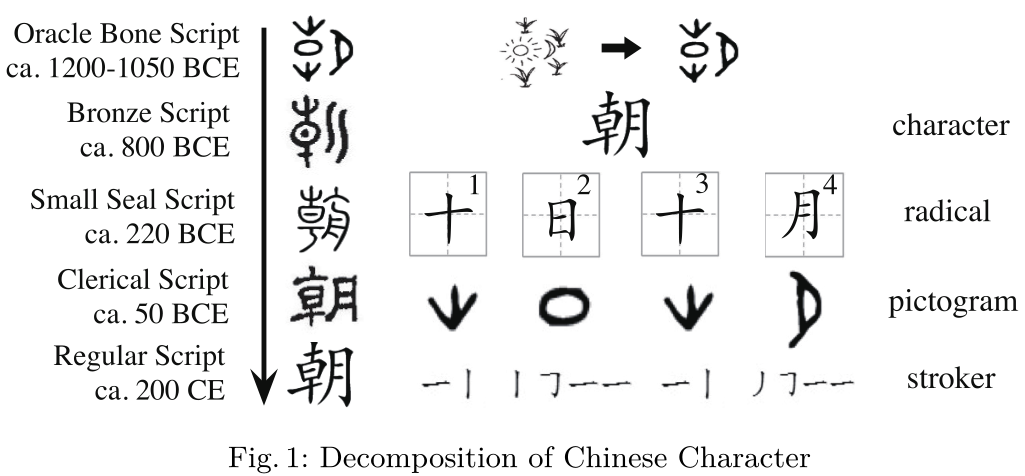
如图1右侧的象形图所示,第一个部首(第三个部首恰好相同)表示“草”,第二个和第四个部首分别表示“太阳”和“月亮”。这四个部首共同传达了“太阳从草上升起,月亮消失的时刻”的含义,这正是“早晨”。另一方面,笔画的语义很难理解,部首是汉语的最小语义单位。
在本文中,我们使用基于字符的双向LSTM-CRF(BLSTMCRF)神经网络来完成CNER任务。通过对比LSTM变量的结果,我们找到了适合CNER的LSTM块。受char-LSTM[17]的启发,我们提出了一种用于汉语的部首级LSTM,以捕获其象形词根特征,并在CNER任务中获得更好的性能。
3 Neural Network Architecture
3.1 LSTM
略
3.2 CRF
隐藏的上下文向量$h_t$可以直接用作特性,为每个output $y_t$做出独立的标记决策。但在CNER中,输出标签之间有很强的依赖性。例如,I-PER不能跟在B-ORG后面,这限制了B-ORG后面可能的输出标记。因此,我们使用CRF对整个句子的输出进行联合建模。对于输入语句,
$\mathbf{X}=\left(\mathbf{x}_{1}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{n}\right)$
我们重新计算BLSTM网络输出的分数矩阵。$P$ 为size $n×k$,其中$k$为不同标记的数量,$P_{i,j}$为句子中字符第$j$个标记第$i$个字符的分数。$P_{i,j}$ is the score of the $j$th tag of the $i$th character in a sentence.对于一系列预测,
$y=(y_1,y_2,...,y_n)$
we define its score as
$s(X,y)=\sum_{i=0}^n A_{y_i,y(i+1)}+\sum_{i=1}^n P_{i,y_i}$
其中$A$是一个转换分数矩阵,它模拟了从tag $i$ to tag $j$的转换。我们将$start$和 $End$ Tag添加到可能的标记集中,它们是$y_0$和$y_n$的标记,分别表示句子的开始符号和结束符号。因此,$A$ 是size $k+2$ 的平方矩阵。在所有可能的标签序列上应用softmax层后,序列$y$的概率:
$p(y|X) = \frac{e^{s(X,y)}}{\sum_{\tilde{y}\in Y_x}e^s(X,\tilde(y))}$
We maximize the log-probability of the correct tag sequence during training:
$log(p(y|X))=s(X,y)-log(\sum_{\tilde{y}\in Y_x}e^{s(X,\tilde{y})})=s(X,y)-logadd_{\tilde{y}\in Y_x}s(X,\tilde{y})$
其中,$Y_x$表示所有可能的标记序列,包括不符合IOB格式约束的标记序列。显然,不鼓励使用无效的输出标签序列。解码时,我们预测得到最大分数的输出序列,如下所示:
$y^{*} = argmax_{\tilde{y}\in Y_x}s(X,\tilde{y})$
We just consider bigram constraints between outputs and use dynamic programming during decoding.
3.3 Radical-Level LSTM
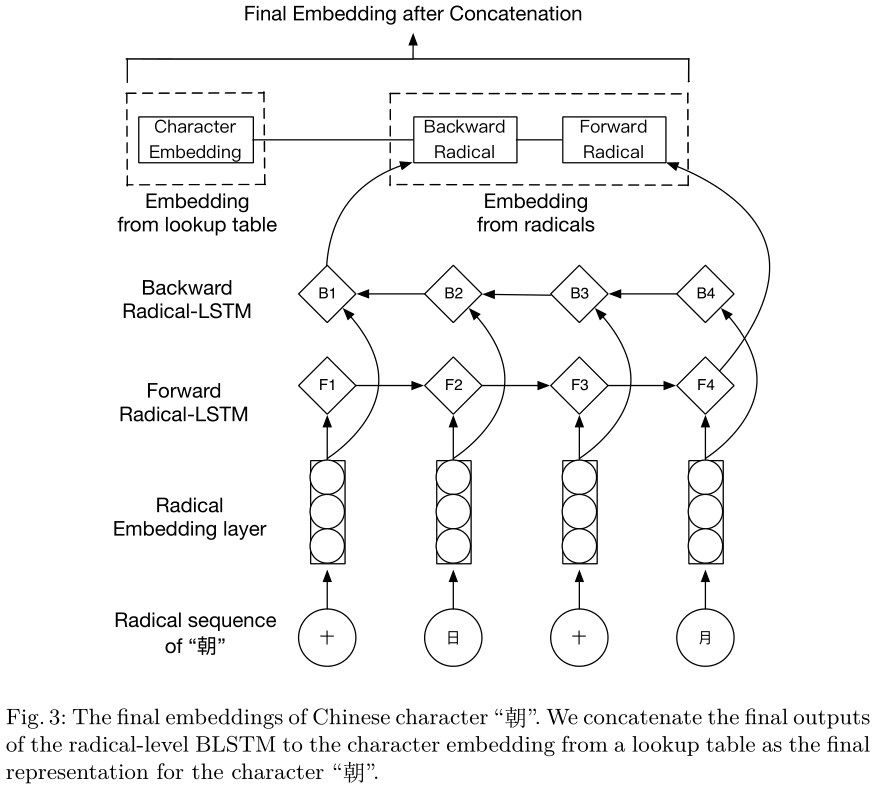
在现代汉语中,汉字通常包含几个部首。在MSRA数据集中,包括训练集和测试集,75.6%的字符有一个以上的部首。我们从网上的新华字典中找到汉字的部首。在简体中文中,字符内部的部首可能与原始形状不同。例如,汉字的第一个部首“腿”(腿)是“月”(moon),这是传统部首的简化形式“肉”(肉),而朝”(上午)也是“月”(moon)实际上是moon的意思。为了处理这些变体,我们替换了最重要的简化词根,也被称为bù(意思是“categories”),以其传统的部首形状恢复其原始含义。汉字的简化部首和传统部首也可以在在线新华字典中找到。对于单部首字符,我们只使用其自身作为其部首部分。在进行替换后,我们得到所有组成部首,我们用所有的部首来建立每个汉字的部首列表。由于一个字符的每个部首都有一个唯一的位置,我们将一个字符的部首视为书写顺序中的一个序列。我们使用部首级双向LSTM来捕获部首信息。图3显示了如何获得字符的最终输入嵌入。
3.4 Tagging Scheme
当我们使用基于字符的标记策略时,我们需要为句子中的每个字符指定一个命名实体标签。许多NE在一个句子中跨越多个字符。句子通常以IOB格式表示(内部、外部、开头)。在本文中,我们使用IOBES标记方案。使用此方案,将考虑有关下方标记the following tag的更多信息。
4 Network Training
4.1 LSTM Variants
1. No Peepholes, No Forget Gate, Coupled only Input Gate (NP,NFG,CIG)
2. Peepholes, No Forget Gate, Coupled only Input Gate (P,NFG,CIG)
3. No Peepholes, Forget Gate, Coupled only Forput Gate (NP,FG,CFG)
4. No Peepholes, Forget Gate, Coupled Input and Forget Gate (NP,FG,CIFG)
5. No Peepholes, Forget Gate(1), Coupled Input and Forget Gate (NP,FG(1),CIFG)
6. Gated Recurrent Unit (GRU)
4.2 Pretrained Embeddings
在深度学习中,通常有太多的参数无法仅从有限的训练数据中学习。为了解决这一问题,出现了一种只使用大量未标记语料库的无监督学习方法来预训练嵌入。与随机初始化的嵌入相比,良好预训练的嵌入对神经网络结构的性能非常重要[11,17]。我们观察到使用预训练字符嵌入比随机初始化嵌入有显著的改进。这里我们使用gensim[25],它包含word2vec的python版本实现。这些嵌入在训练期间进行了微调。我们使用中文维基百科备份转储20151201。将繁体中文转换为简体中文,去掉非utf8字符,统一不同标点符号风格,得到1.02GB的未标记语料库。字符嵌入使用CBOW模型进行预训练,因为它比skipgram模型更快。使用不同字符嵌入维度的结果如第5.2节所示。部首嵌入Radical embeddings是随机初始化的,维数为50。
4.3 Training
在输入LSTM层之前,我们以0.5的dropout概率,以避免过度拟合,并观察CNER性能的显著改善。根据[17],我们使用反向传播算法对网络进行训练,每次更新一个训练示例的参数。我们使用随机梯度下降(SGD)算法,在训练集上学习50个阶段,学习率为0.05。LSTM的维度与其输入维度相同。
5 Experiments
5.1 Data Sets
我们在第三个SIGHAN-Bakeoff中文命名实体识别任务的MSRA数据集上测试了我们的模型。此数据集包含三种类型的命名实体:位置、人员和组织。中文分词在测试集中不可用。我们只是用零替换每个数字,并统一MSRA和预训练嵌入中出现的标点符号样式。
5.2 Results
表1给出了我们与LSTM块不同变体的比较。(1) 在所有变体中实现最佳性能。我们观察到,窥视孔 peephole连接并没有改善CNER的性能,但由于连接更多,它们增加了训练时间。与[15,9]的结论不同,添加遗忘门后,无论如何更新单元状态,性能都会下降。但在将忘记门的偏差设置为1后,会提示性能,这使得忘记门倾向于记住长距离依赖关系。耦合输入和遗忘门的方式对性能没有显著影响,这与[9]相同。GRU由于内部结构的简化而不严重影响性能,因此需要较少的训练时间。最后,在接下来的实验中,我们选择(1)作为LSTM块。
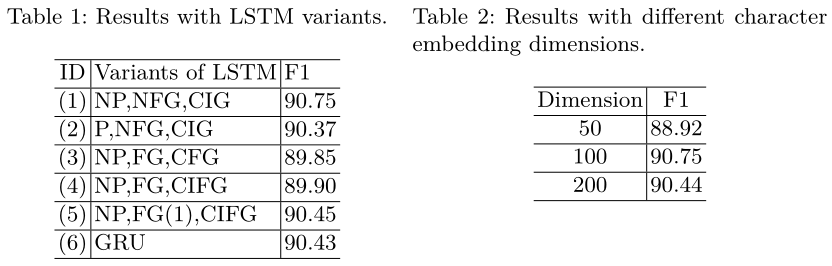
表2显示了不同字符嵌入维度的结果。我们在所有三个实验中使用预训练字符嵌入、dropout training、BLSTM-CRF架构。与[17]报道的英文结果不同,50维度不足以代表汉字。在CNER中,100个DIM比50个DIM的效果好1.83%,但使用200个DIM时,没有观察到更多的改善。我们在下面的实验中使用了100个DIM。
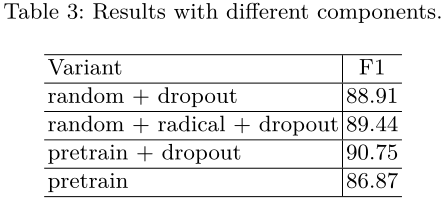
我们的体系结构有几个组件,它们对总体性能有不同的影响。如果没有CRF层,即使使用相同的学习率0.05,模型也无法在100个时期内收敛到稳定状态。我们探讨了dropout、部首级表征、字符预训练对LSTM-CRF体系结构的影响。表3给出了不同体系结构的结果。我们发现,使用随机初始化字符嵌入,部首级LSTM使我们的$F_1$提高了+0.53。显然,部首级信息对汉语是有效的。通过无监督学习,使用未标记的中文维基百科语料库对预训练字符嵌入进行训练,在dropout训练的基础上,将结果提高+1.84。dropout很重要,最大的进步是+3.88。部首级LSTM使用随机嵌入初始化的词汇字符,接近具有相似部首成分的已知字符。Radical-level LSTM makes out-of-vocabulary characters, which are initialized with random embeddings, close to known characters that have similiar radical components.在维基百科语料库中,在训练和测试集中只能找到3个字符characters。换句话说,使用随机嵌入初始化的字符很少。因此,我们没有发现使用部首级LSTM和良好预训练字符嵌入的进一步改进。当没有大型语料库进行字符预训练时,部首级LSTM显然是有效的。
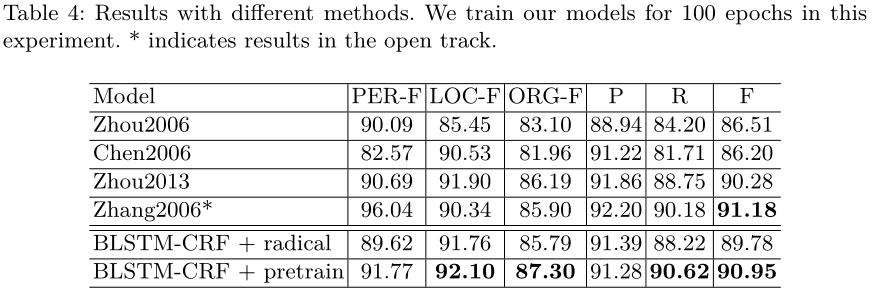
表4显示了我们与其他中文命名实体识别模型的比较结果。为了展示我们的模型的能力,我们对我们的模型进行了100个epoch的训练,而不是之前实验中的50个epoch。Zhou 2006[31]在MSRA数据集的封闭轨迹closed track中,使用基于单词character-base的CRF模型,并使用精细的手工制作的特征,以86.51%的F1率获得第一名。Chen2006[2]使用基于字符的CRF模型实现了86.20%的F1。Zhou 2013[32]使用一个全局线性模型,结合10个精心设计的CNER特征模板和[30]中的31个上下文特征模板,对CNER进行识别和分类。Zhou2013采用了更精细的标签方案,例如将短于4个字符且以中文姓氏开头的PER标签改为中文PER。在开放式跟踪中,Zhang2006[29]使用ME模型获得了第一名,该模型结合了来自各种来源的知识,如人名列表、组织名称词典、位置关键字列表等,占91.18%。我们的BLSTM-CRF与激进嵌入相比,总体上优于先前的最佳CRF模型+3.27。我们的BLSTM-CRF采用预训练字符嵌入,其性能优于除Zhang 2006在开放赛道上的结果外的所有先前模型,并以90.95%的F1成绩实现了最先进的性能。特别是对于最难识别的组织实体,我们的方法利用LSTM的能力来学习远程依赖,并取得了显著的性能。Zhang2006在总体F1中比我们的性能好+0.23的主要原因是,他们使用了额外的名称词典来实现非常高的PER-F,而我们不使用这些词典。我们的神经网络架构不需要任何手工制作的功能,这些功能在Zhou2013非常重要。
6 Conclusion
本文介绍了我们的神经网络模型,该模型将汉字部首级信息与基于字符的BLSTM-CRF相结合,获得了最先进的结果。我们利用LSTM块来学习长距离依赖关系,这有助于识别ORG实体。与专注于特征工程的研究不同,我们的模型不使用任何手工制作的特征或特定领域的知识,因此,它可以很容易地转移到其他领域。未来,我们希望将我们的模式转移到中国的社交媒体领域。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号