【论文阅读】A Weighted GCN with Logical Adjacency Matrix for Relation Extraction[ECAI2020]
论文地址:http://ecai2020.eu/papers/957_paper.pdf
代码地址:https://github.com/LILI-ZHOU/EA-WGCN
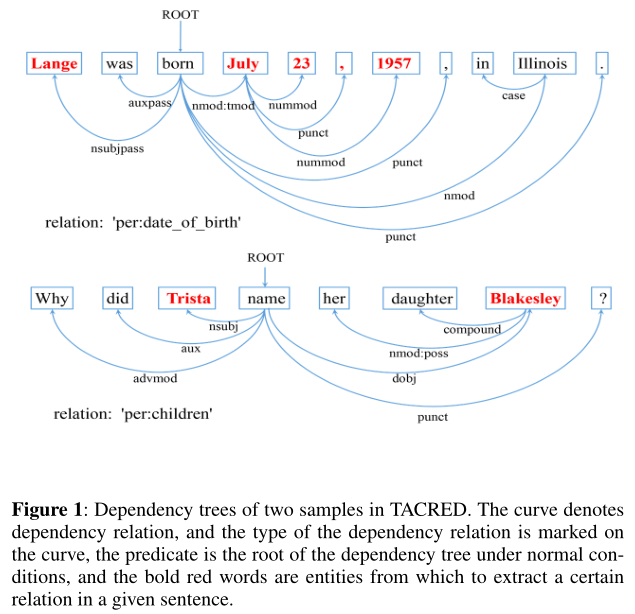
然而,现有的基于GCN的模型仅建立词与词之间的一阶( first-order)依赖关系,其效率和有效性受到限制。一些重要的词(如图1中的“23”)与它们的谓语有间接的联系。因此,如果需要k阶邻域依赖,就需要对多层GCN进行叠加。从经验上看,结构较深、参数较多的神经网络能产生较好的实验结果。虽然GCN比其他方法有显著的优势,但它也有一些基本的缺点。Li等人[12]表明,GCN带来了许多卷积层过平滑的潜在问题。
“first-order” means the neighbor nodes to which the target node only need 1 step, and ”k-order” requires steps within distance k.
为了解决这些问题,我们提出了一种新的加权图卷积网络模型weighted graph convolutional network model(WGCN)。在该模型中,我们在依赖树中加入虚边virtual edges 来构造一个逻辑邻接矩阵 logical adjacency matrix(LAM),它只需要一层WGCN就可以直接求出k阶邻域依赖k-order neighborhood dependence。我们利用WGCN层间的残差块 residual blocks[7]来缓解消失梯度。我们还应用实体注意(Entity-Attention,EA)机制来丰富实体表示,使词与词之间的语义信息更加集中,从而有利于实体对的关系提取。贡献:
1)提出了一种新的加权图卷积网络(WGCN)模型,该模型只需在1层网络上获得k阶邻域信息,不需要额外的网络参数,并通过引入残差块来缓解图网络中的消失梯度问题。
2)我们提出了实体注意机制(EA)来丰富实体表示的相关信息。
3)最后,我们分析了LSTM、注意机制和GCN在自然语言处理中的亮点和互补作用。
我们的模型也是基于GCN的,但现有的GCN只能直接获取一阶邻域信息,需要多层结构间接求出k阶邻域信息k-order neighbor information。考虑到这一局限性,我们通过在图结构上添加虚边来构造一种新的加权图卷积网络(WGCN),它可以直接获得k阶邻域信息。这样,在保留GCN固有优点的同时,在不失简单性的前提下提高了模型的精度。
3 Model
Sentence:$\cal{X}=[x_1,x_2,...,x_N]$,$x_i$ is the $i$th token,$N$ is the length of $\cal{X}$
the subject entity span and the object entity span:$\cal{X_s}=[x_{s_1},x_{s_2},...,x_{|\cal{x}_s|}]$,:$\cal{X_o}=[x_{o_1},x_{o_2},...,x_{|\cal{x}_o|}]$
Given $\cal{X}$, $\cal{X}_s$ and $\cal{X}_o$, relation extraction is to make a prediction of the relation $r \in R$ between the two entities. $R$ represents a predefined relation set.
Our novel model (EA-WGCN):
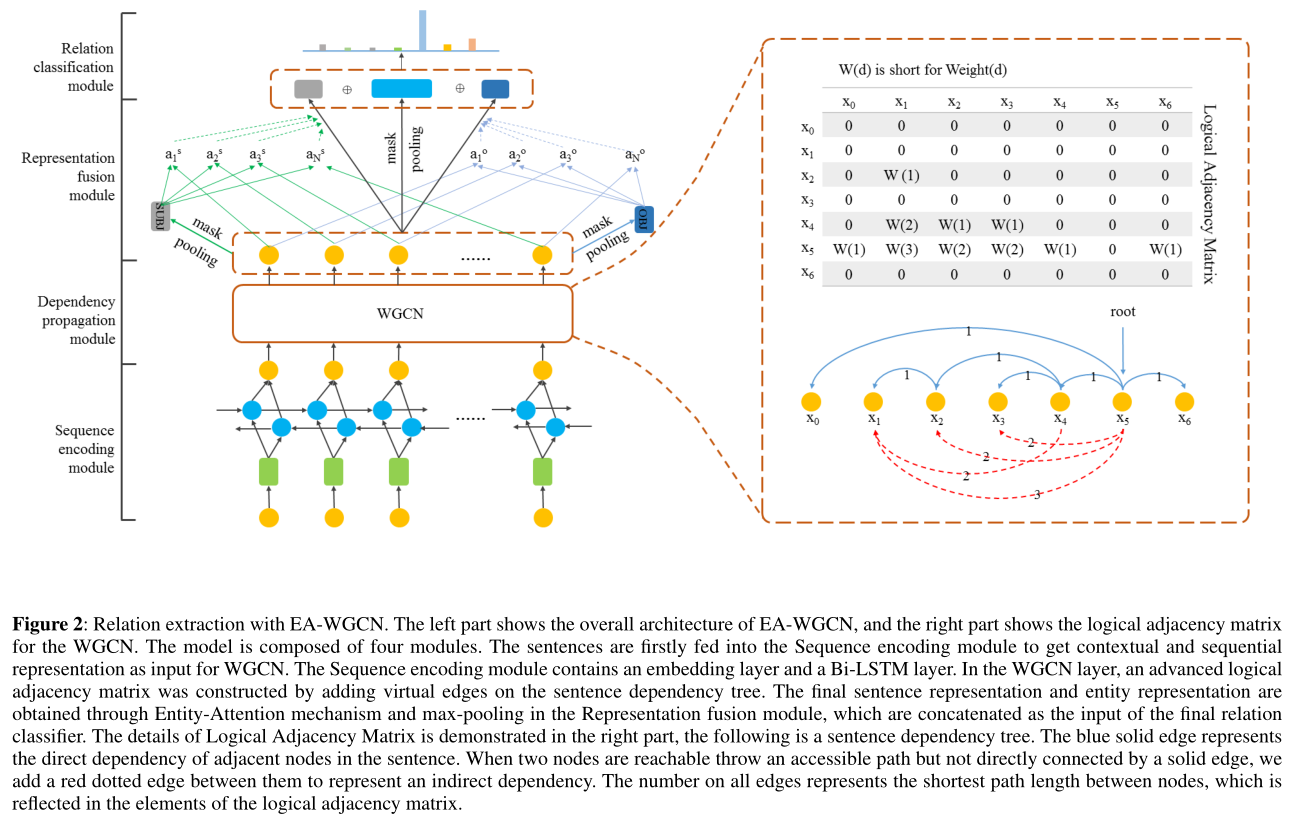
图2:EA-WGCN的关系提取。左侧显示了EA-WGCN的总体架构,右侧显示了WGCN的逻辑邻接矩阵。该模型由四个模块组成。首先将句子输入到序列编码模块,得到上下文和序列表示作为WGCN的输入。序列编码模块包括嵌入层和bilstm层。在WGCN层,通过在句子依赖树上添加虚边来构造高级逻辑邻接矩阵。在表示融合模块中,通过实体注意机制和最大池Entity-Attention mechanism and max-pooling,得到最终的句子表示和实体表示,作为最终关系分类器的输入。逻辑邻接矩阵的细节在右边部分演示,下面是一个句子依赖树。蓝色的实心边表示句子中相邻节点的直接依赖关系。当两个节点有一条可访问的路径但没有直接通过实线连接时,我们在它们之间添加一条红色虚线来表示间接依赖关系。所有边上的数字表示节点之间的最短路径长度,它反映在逻辑邻接矩阵的元素中。
采用加权图卷积网络结构和实体注意机制,能更好地捕获句子依赖树中的结构信息,为关系抽取任务提供更好的结果。图2展示了模型的概述。该模型主要由四个模块组成:(1)序列编码模块(2)依赖传播模块(3)表示融合模块(4)关系分类模块。我们模型的创新主要体现在第二和第三模块
3.1 Sequence Encoding Module
$e_t = [e_t^{word};e_t^{ner}:e_t^{pos}]$
$m = d_{word}+d_{ner}+d_{pos}$
The vectors of all time steps are serialized into a 2-D matrix $E = [e_1, e_2, . . . , e_N] \in R^{N×m}$
$h_t=[\overrightarrow{h}_t:\overleftarrow{h}_t]\in \cal{R}^{2d_l}$ (5)
3.2 Dependency Propagation Module
回顾GCN:Before introducing this module, we review Graph Convolutional Network (GCN), which provides a new method for processing graph-structured data. Given $G = (V, E)$,the input of GCN is:
1)A feature matrix $X$ ,whose shape is $N × F^0$,where $N$ represents the number of nodes in the graph, $F^0$ is the input feature dimension of each node.
2)A $N×N$ adjacency matrix $A$ of this graph, where $A_{ij}=1$ if there is an edge going from node $i$ to node $j$.
Hence, the output of $l$-layer GCN is written as:
$H^{(l)}=\sigma(AH^{(l-1)}W^{(l)}+b^{(l)})$
where $H^0= X$, $W^l$ is a linear transformation, $b^l$ is a bias term, and $\sigma$ is a nonlinear function (e.g.,$RELU$).
在关系抽取任务中,我们将依赖树解析为句子上的图结构,其中每个标记表示一个节点。如果单词之间存在依赖关系,则相应的节点之间存在一条边。在每一个图卷积运算之后,通过融合邻域节点的特征来更新每个节点的信息。
Weighted graph convolutional network.
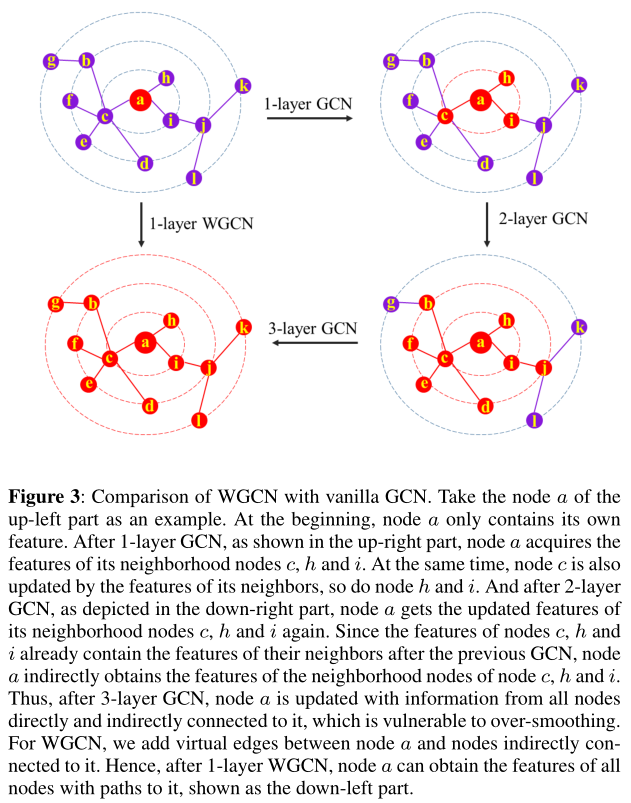
图3:WGCN与vanilla GCN的比较。以左上角的节点a为例。一开始,节点a只包含自己的特征。在1层GCN之后,如右上部分所示,节点a获取其邻居节点c、h和i的特征。同时,节点c也由其邻居的特征更新,节点h和i也是如此。在2层GCN之后,如右下部分所示,节点a再次获取其邻居节点c、h和i的更新特征。由于节点c、h和i的特征已经包含了前一个GCN之后的邻居的特征,因此节点a间接地获得了节点c、h和i的邻居节点的特征,因此,在三层GCN之后,节点a被直接和间接连接到它的所有节点的信息更新,容易过度平滑。对于WGCN,我们在节点a和间接连接到它的节点之间添加虚拟边。因此,在1层WGCN之后,节点a可以获得所有具有路径的节点的特征,如左下部分所示。
然而,基于1层GCN的特征融合只表示一阶first-order邻域依赖。当需要k阶k-order邻域特征进行进一步的关系提取工作时,只能通过多层GCN结构间接获取,耗时且有很高的过平滑倾向,如图3所示。
为了避免这种局限性,实现单层图网络的多跳特征融合,提出了一种加权图卷积网络(WGCN)。在该模型中,我们在依赖树中加入虚边来构造一个逻辑邻接矩阵logical adjacency matrix(LAM),它只需要一层WGCN就可以直接求出k阶邻域依赖。构造LAM的算法如算法1所示。

算法1中的加权函数$Weight$ function用于计算节点间特征融合的权重系数。节点之间的距离越短,权重就越大,反之亦然vice versa。相邻节点间的融合权重系数为1,表示最大信息融合权重。在我们的模型中,我们选择了定义为:
$Weight(d)=\frac{1}{e^{d-1}}$
其中e是欧拉数Eular's number。然后我们可以得到一个新的相关信息融合传播公式,如下所示:
$h_i^{(l)}=\sigma(\sum_{j=1}^N\tilde{LAM}_{ij}h_j^{(l-1)}W^{(l)}/d_i+b^{(l)})\in \cal{R}^{d_w}$
where $h_i^0= h_i$ in Equation 5,$\tilde{LAM} = LAM + I$,which means all nodes in dependency tree added self-loop connection, and $d_i=\sum_{j=1}^N\tilde{LAM}_{ij}$ is the degree of node $i$,$d_w$ denotes the WGCN hidden size, and $W^{(l)} \in \cal{R}^{2d_i×d_w}$.
这样,一层WGCN就可以直接集成k阶邻域信息,而不需要引入额外的参数。随着深度的增加,图形网络的梯度逐渐消失,使得WGCN的感受野receptive field 在信息传递过程中极有可能产生大量的噪声。因此,在WGCN中构建residual blocks残差块【我们直接使用最后一层WGCN的输出作为依赖传播模块的输出】以缓解该问题。通过这个模块,我们可以得到句子的依赖表示。
3.3 Representation Fusion Module
为了用更集中的语义信息来表示句子中的主语实体和宾语实体,我们提出了一种实体注意机制Entity-Attention mechanism(EA),在EA机制下,实体可以捕获句子中与其相关的部分。首先,没有注意的实体表示定义为Firstly, the entity representation without attention is defined as:
$h_{entity}^{'}=maxpool[H_{es:ee}^{(L)}]$ (9)
where $H^{(L)}= [h_1^{(L)}, h_2^{(L)}, . . . , h_N^{(L)}]$ is matrix representation of sentence after L-layer WGCN, es indicates the start subscript 开始下标of the entity and ee indicates the end subscript. The $maxpool$ function reduces the representation from 2-dimension to 1-dimension as $d_w$. Then the final entity representation with Entity-Attention is given by:
$a = softmax(H^{(L)}h_{entity}^{'})$ (10)
$h_{entity} = maxpool[(aH^{(L)})_{es:ee}]$ (11)
where $a$ is a vector of entity-to-sentence attention weights. Then the final representation $h_s$, $h_o$ of $\cal{X}_s$,$\cal{X}_o$ can be obtained from Equation 9,10,11, which are already enriched with focused information. And we also obtain the sentence representation vector directly by:
$h_{sent}=maxpool[H^{(L)}]$
最后,我们通过连接句子和实体的最终表示来整合所有特征,如下:
$h_{out}=[h_{sent};h_{s};h_{o}]$
3.4 Relation Classification Module
在该模块中,将包含丰富的顺序信息和依赖信息的融合表示形式通过softmax操作输入到一个前馈神经网络中,得到关系的概率分布。
该模型采用反向传播算法进行训练,训练过程中采用交叉熵函数作为模型的损失函数。我们的竞争优势在于我们在没有额外参数和复杂结构的情况下获得了更好的性能。
4 EXPERIMENT
4.1 Datasets
TACRED SemEval 2010 Task 8
For both datasets, we use pre-trained 300-dimensional GloVe [18] to initialize word embedding, and randomly initialized POS embedding and NER embedding with 30 dimensions.The Bi-LSTM hidden size is set to 100, and WGCN hidden size is set to 200, which effectively enables residual computation. And we set the dropout rate 0.5, prune $k = 1$ [29]. For TACRED, We choose 2 layer WGCNs, initializing learning rate 1.0 with a decay rate 0.9. For SemEval, we set 3 layer WGCNs, 0.5 learning rate with a decay rate of 0.95. For both datasets, we trained our model for 150 epochs.
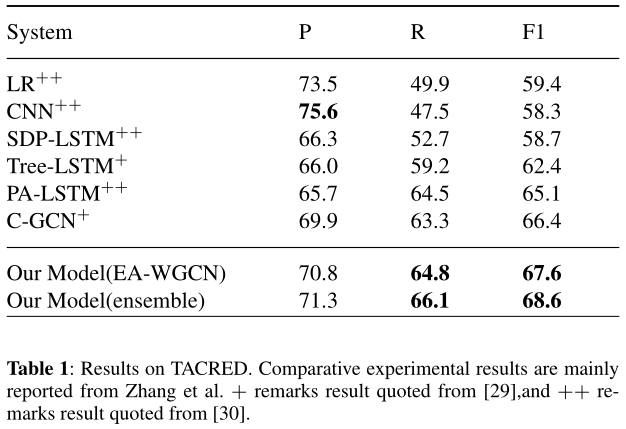
通过观察实验结果,我们发现我们的模型比其他模型至少提高了1.2F1。CNN获得了最高的精确度分数75.6和最低的Recall分数47.5,这导致了最低的F1分数。我们假设CNN可能倾向于对定义的关系进行精确分类,而对定义的类型和未定义的类型进行错误分类。CNN achieves the highest precision score 75.6 and a lowest recall score 47.5, which leads to a lowest F1 score. We hypothesize that CNN may tend to precisely classifying the defined relations while make misclassification between defined and undefined types.我们的EA-WGCN模型获得了最高的召回分数64.8和最高的F1 67.6。特别是与C-GCN相比,该模型在准确度、召回率和F1评分方面都有一定的提高。我们还通过平均5次随机初始化的softmax结果来运行我们的EA-WGCN模型的集成an ensemble of our EA-WGCN,这将F1分数提高了1%。
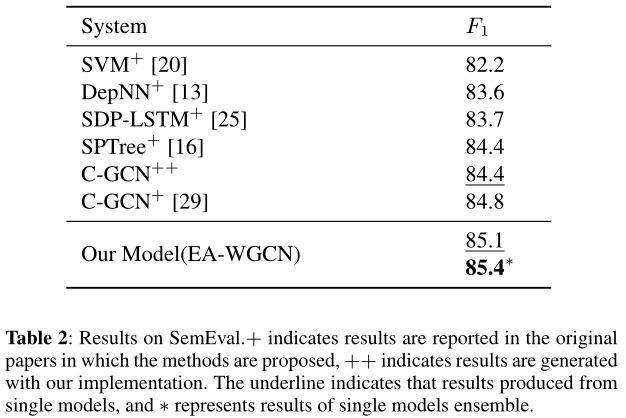
SemEval 2010任务8。为了证明我们提出的模型的多功能性,我们还对另一个数据集SemEval进行了实验。我们主要使用一些依赖关系模型进行实验,如表2所示。SemEval数据集比TACRED数据集小得多,但是我们的模型仍然获得了F1 85.1,并且优于任何其他依赖模型。在相同的集成ensemble方法中,我们将单一EA-WGCN模型的F1分数提高到85.4分。
5 ANALYZE & DISCUSSION
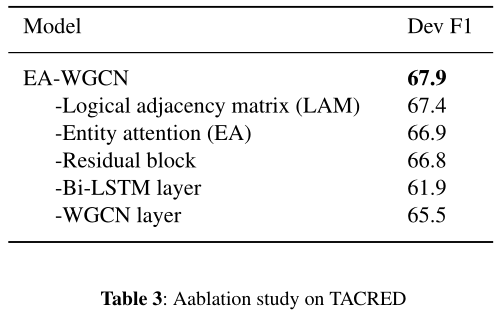
5.1 Ablation study
5.2 Effect of Logical Adjacency Matrix
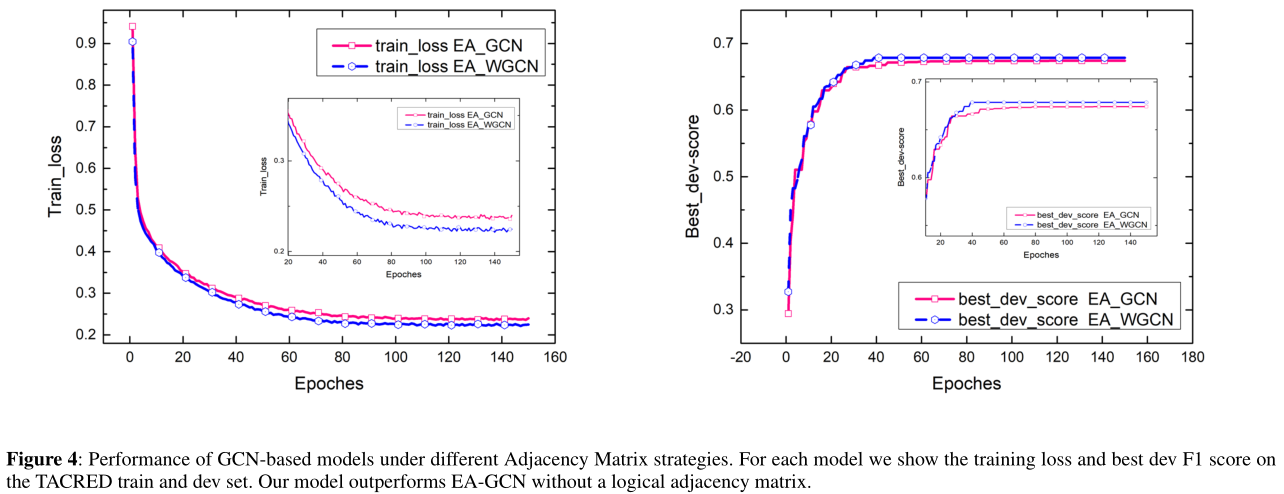
在我们的研究中,我们坚持认为逻辑邻接矩阵(LAM)只需要一层GCN就可以捕获k阶邻域信息,而不需要添加额外的层和参数。为了验证LAM在关系抽取模型中的有效性,我们在EA-WGCN(我们的模型)和EA-GCN之间进行了一个比较实验,用一个普通的邻接矩阵代替了我们模型中的LAM。不同邻接矩阵策略下的收敛结果如图4所示。我们的模型很快收敛到一个更好的解决方案。EA-GCN也表现得相当好,尽管收敛速度比我们的模型慢。在本例中,我们还比较了EA-GCN和我们的模型之间的最佳dev F1得分,如图5所示。就最终最佳F1得分而言,我们的模型比EA-GCN的F1得分至少高出0.5分,并在第40个时代前后达到峰值。以上结果证明,LAM算法能有效地捕捉k阶邻域特征,在关系抽取任务中取得较好的预测效果。
5.3 Effect of Entity-Attention
分析每个句子词在确定实体表示中的意义,对实体间的关系提取具有启发意义。
图5显示了句子中每个单词对给定实体的影响程度。颜色深度表示等式10中注意向量$a$中权重的重要程度,颜色越深越重要。以第一句话为例,主体(“联邦”)(”The Federation”)和客体(“1994”)之间的关系是组织:成立””org:founded”. 我们观察到,实体注意机制导致这两个实体更加关注“成立于1994年””founded in 1994”这一短语。类似地,第二句的实体更关注短语“12500名雇员” “12500 employees in”,这导致我们的模型提取关系组织:数量员工/会员 ’ org:number of employees/members ’。显然,实体注意有助于从整个句子中动态地获得重要性引导的实体表征。
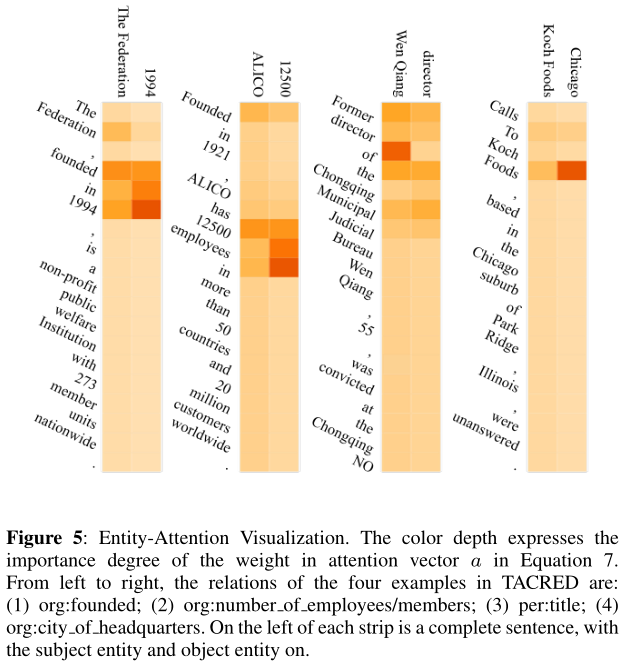
在每一条的左边是一个完整的句子,主语实体和宾语实体在上面。
5.4 Analyze of LSTM & Attention & GCN
在基于深度学习的自然语言处理模型中,LSTM和注意机制得到了广泛的应用。通过将前向和后向LSTM状态串联起来,文本中的每个单词都可以获得一个上下文语义的表示。注意机制有助于将注意力更多地集中在重要的部分,而不是其他不重要的因素上。该模型以实体作为查询向量,通过实体注意机制为句子中的每个词分配注意权重,起到全局观察的作用。最新的基于句子依赖树的GCN模型允许每个词直接捕获其依赖词的信息,甚至在原文中离它很远的地方。因此,LSTM、注意机制和GCN对特征的重视程度不同提取。如图所示如表3所示,所有三个特征抽取器对我们的模型都贡献了F1分数,这说明了LSTM在顺序信息捕获、全局相关性获取中的注意机制和依赖性获取中的GCN的互补效应。将LSTM、注意机制和GCN相结合,丰富了词级和句子级的表达,获取了尽可能多的语义信息,实现了更精确的关系抽取。
此外,WGCN中的LAM是一个$N*N$矩阵。对于每个单词,它计算出其他单词的融合权重系数,权重之和被归一化为1,这看起来与注意机制非常相似。但事实上,LAM只包含句子依赖树中直接或间接可达的词的相关信息,这对关系抽取任务非常有帮助,而注意机制则关注句子中所有词之间的全局关系。
6 CONCLUSION
本文提出了一种新的基于实体注意机制的加权图卷积网络(EA-WGCN)来进行关系抽取。在WGCN中,我们通过在依赖树中有路径但不直接相邻的节点之间添加虚拟边来构造逻辑邻接矩阵。这种操作只需一层WGCN就可以直接获得k阶邻域信息,从而实现了结构简单的多跳关系。通过在WGCN层之间引入残差块,有效地缓解了消失梯度问题。实体注意机制使得实体表示能够从句子中获得重要的语义信息。在TACRED数据集和semeval2010任务8数据集上的实验结果表明,EA-WGCN能够更全面地利用依赖树中的结构信息,得到比以前更好的结果。我们还发现了LSTM在顺序信息获取、注意机制在全局相关性获取和GCN在依赖性获取中的互补作用。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号