【论文阅读】HIN: Hierarchical Inference Network for Document-Level Relation Extraction[PAKDD2020]
论文地址:https://arxiv.org/abs/2003.12754
代码地址:未找到
视频讲解:http://videolectures.net/pakdd2020_tang_hin_inference/
Abstract
为了充分利用实体层、句子层和文档层的丰富信息,提出了一种层次推理网络Hierarchical Inference Network (HIN)。对多个子空间中的目标实体对进行平移约束和双线性变换Translation constraint and bilinear transformation,得到实体级的推理信息。其次,建立实体级信息与句子表示之间的推理模型,实现句子级的推理信息。最后,采用层次聚合方法获得文档级推理信息。通过这种方式,我们的模型可以有效地从这三种不同的粒度聚集推理信息。实验结果表明,该方法在大规模DocRED数据集上达到了最先进的性能。我们还证明了使用BERT表示可以进一步提高性能。
1 Introduction
从技术上看,文档级RE面临着两个主要挑战:(1)如何获得不同粒度的推理信息;(2)如何将这些不同粒度的推理信息进行聚合并做出最终的预测。
本文提出了一种新的神经网络结构层次推理网络(HIN)来解决上述问题。具体来说,是受平移约束translation constraint的启发【TranE?】,which models a relational fact $r(e_h, e_t)$ with $e_h+r ≈ e_t$, we apply this translation constraint to target entity pair.此外,还利用双仿射层bi-affine layer来获得目标实体对的双线性表示bilinear representation。为了共同处理来自不同表示子空间的信息,我们在多个子空间中并行实现了上述两种变换,并获得了完整的推理信息【就是通过了两个线性层呗】。为了获得句子级的推理信息,我们首先应用vanilla注意机制来计算每个句子的向量表示,这使得我们的模型更加关注信息词。然后采用自然语言推理领域广泛应用的语义匹配方法,将实体级推理信息与每个句子向量进行比较。此外,为了计算文档级的推理信息,我们采用了层次化的BiLSTM,并再次使用注意机制来区分关键的句子级推理信息,以实现整个文档级的推理表示。最后,将不同粒度的推理信息进行聚合,将实体级和文档级的推理表示组合成一个固定长度的向量,并将其送入分类层进行预测。
综上所述,我们做出了以下贡献:
1.提出了一种用于文档级推理的层次推理网络(HIN),它能够将推理信息从实体级聚合到句子级,再聚合到文档级。
2.我们对DocRED数据集进行了全面的评估。结果表明,我们的模型达到了最先进的性能。我们进一步证明了使用BERT表示进一步显著地提高了性能。
3.我们分析了我们的模型在不同支持句数目下的有效性,实验结果表明,当支持句数目较大时,我们的模型比以前的工作有更好的表现。
3 Proposed Approach
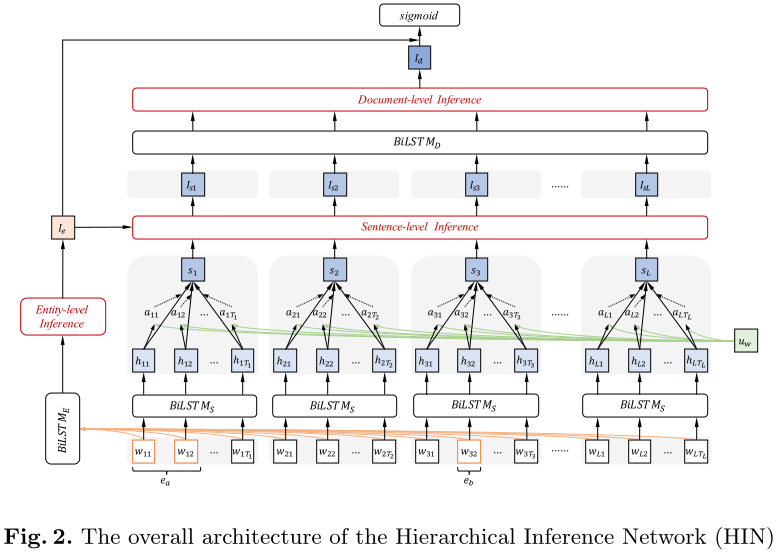
HIN模型分为四部分:input layer、entity-level inference module、hierarchical document-level inference module、prediction layer。
input layer:原始的输入有三部分:word embedding、entity type embedding、coreference embedding。其中,word embedding就是每一个token的word embedding,其维度:$d_w$;entity type embedding指的是将entity 的type信息转换为一个dense vector,其维度是:$d_t$;coreference embedding指的是同一个entity的不同的mention被分配同一个entity id,其维度:$d_c$。这一层的输出是这三者的concat。$X=[w_1,w_2,...,w_n]$,where each word vector $w_i∈ R^{d_w+d_t+d_c}$and $n$ is the length of the document.
entity-level inference module:首先使用BILSTM来对document进行编码,即:$h_i=BILSTM(w_i),i\in[1,n]$,$n$表示一个document中所有的token数目;每一个mention的rep是其每一个word的avg,每一个entity是其所有的mention rep的avg,即:$e_l=avg_{w_i\in e_l}(h_i), E_a=avg_{e_l\in E_a}(e_l)$,其中,$e_l$表示某一个mention的rep,$E_a$表示某一个entity的rep。由于收到multi-head attention的影响:将vector映射到不同的latent space会enrich 模型的信息,所以在HIN模型中,也是同样的做法,将得到的entity rep映射到不同的K个latent space,即:
$E^k_a=W^{(1)}_k(RELU(W^{(0)}_kE_a))$
where $E^k_a∈ R^k$ corresponds to the representation of Eain the k-th latent space, $W^{(0)}_k ∈ R^{d×d}$ and $W^{(1)}_k ∈ R^{d×k}$ are the learnable projection matrices corresponding to the k-th subspace.
之后,由于又收到TransE算法的影响,知:$e_h+r≈e_t$,所以作者认为$E_b−E_a$能够在某种程度上反应entity pair $(e_a,e_b)$的relation。所以第$k$个latent space的结果是:
$I^k_e=Concat[E^k_aR^kE^k_b;E^k_b-E^k_a;E^k_a;E^k_b]$
where $R_k∈ R^{k×k×k}$ is a learned bi-affine tensor, $Concat$ denotes concatenation.
此外,我们相信,两个目标实体之间的相对距离可以帮助我们更好地判断关系。根据经验,我们使用两个实体的第一次提及之间的相对距离作为两个目标实体之间的相对距离。最后,将不同潜在空间中的所有实体级推理表示和相对距离嵌入输入到前馈神经网络(FFNN)中,形成最终的实体级推理信息:
$I_e=G_e([I^1_e,I^2_e,...,e^K_e;M({d_{ba}})-M({d_{ab}})])$
here $G_e$ is a FFNN with ReLU activation function, $M$ is an embedding matrix, $d_{ab}$ and $d_{ba}$ are the relative distances between $E_a$ and $E_b$ in the document. $I_e∈ R^d$ describes relation features between $E_a$ and $E_b$ at entity level.
hierarchical document-level inference module:这一部分又分为两部分:sentence-level inference与document-level inference。在sentence-level inference中,假设一个document有$L$个句子,$w_{jt}$表示第$j$个sentence的第$t$个word,我们使用BILSTM对每一个sentence进行编码,如下:
$h_{jt}=BILSTM_S(w_{jt}),j=1,...,L,t\in [1,T_j]$
然后借鉴HAN模型,对$h_{jt}$使用attention【context-aware(attention的BiLSTM)】,然后得到sentence vector,如下:
$\alpha_{jt}=u^T_wtanh(W_wh_{jt}+b_w)$
$a_{jt}=\frac{exp(\alpha_{jt})}{\sum_{t}exp(\alpha_{jt})}$
$S_j=\sum_{t}a_{jt}h_{jt}$
其中$u_w,b_w∈R^d$,$W_w∈R^{d×d}$可学习参数。单词隐藏状态$h_{jt}∈R^d$首先通过一层MLP,然后通过测量“哪些单词与目标实体更相关”得到单词的权重。最后,我们计算句子向量$s_j$作为单词隐藏状态的加权和。
为了获得句子级的推理信息,我们采用了以前的NLI模型中使用的语义匹配方法。通过比较句子向量$S_j$和实体级推理表示$I_e$,我们可以得出第$j$个句子的句子级推理表示$I_{sj}$:
$I_{sj}=G_s([S_j;I_e;S_j-I_e;S_j \ o \ I_e])$
where $G_s$ is FFNN with ReLU function, a matching trick with elementwise subtraction and multiplication is used for building better matching representations. $I_{sj}$ represents the inference information derived from the j-th sentence.
在document-level inference中,我们还是借鉴HAN模型,使用BISLTM+attention的方式,得到最终document vector,如下:
$c_{sj}=BILSTM_D(I_{sj}),j\in[1,L]$
$\alpha_{j}=u^T_stanh(W_sc_{sj}+b_s)$
$a_{jt}=\frac{exp(\alpha_{j})}{\sum_{j}exp(\alpha_{j})}$
$I_d=\sum_{j}a_{j}c_{sj}$
here $u_s,b_s∈ R^d$ and $W_s∈ R^{d×d}$ are learnable parameters, $I_d∈ R^d$ is the document-level inference representation which represents all the inference information that we can obtain from the document.
prediction layer:我们首先对entity-level inference rep与document-level inference rep进行concat,再输入到FFN中进行最终得分类。如下:
$P(r|E_a,E_b)=sigmoid(W_r \left[\begin{matrix}I_e \\ I_d \end{matrix}\right]+b_r)$
where $W_r$, $b_r$are the weight matrix and bias for the linear transformation.
A binary label vector $y$ is set to indicate the set of true relations holding between the entity pair, where 1 means an relation is in the set, and 0 otherwise. In our experiments, we use the binary cross entropy (BCE) as training loss:
$Loss==\sum_{r=1}^ly_rlog(p_r)+(1-y_r)log(1-p_r)$
where $y_r∈ {0,1}$ is the true value on label r and l is the number of relations.
给定一个文档,我们根据它们的置信度对预测结果进行排序,并在dev集上按F1得分从上到下遍历这个列表,取F1最大值对应的概率值作为阈值$δ$。该阈值用于控制测试集上提取的关系事实的数量。
4 Experiments
4.1 Dataset
DocRED
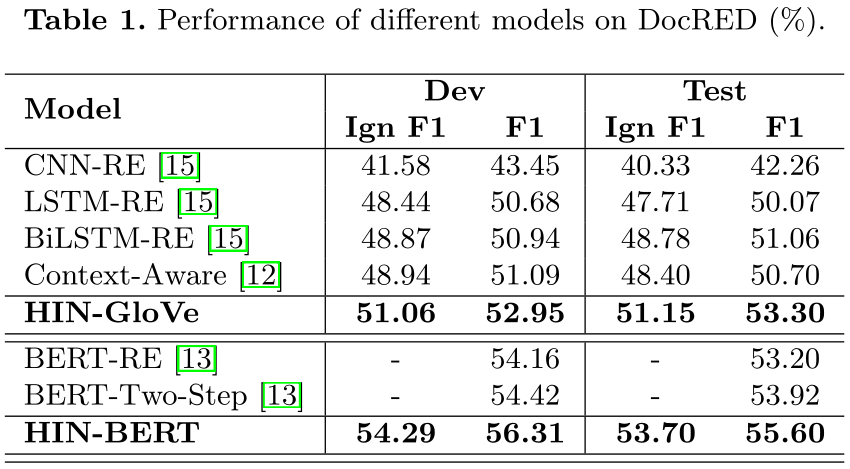
4.2 Comparison Models & Evaluation Metrics
Ablation Study
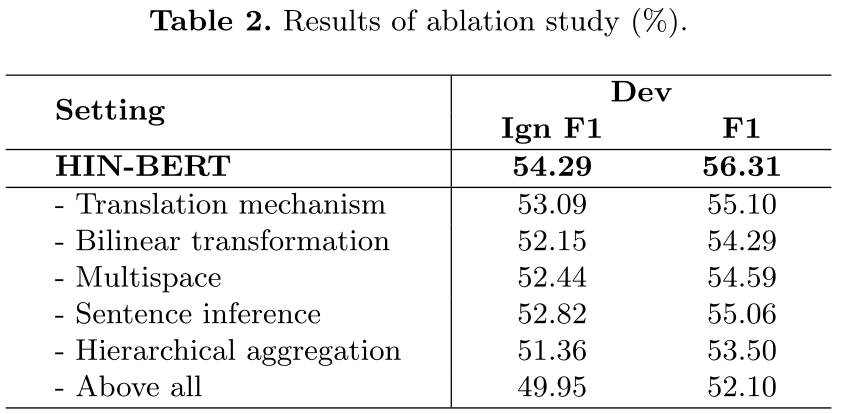
通过这些实验,我们发现:(1)去除翻译机制和双线性变换后,F1评分分别下降了1.21%和2.02%,说明这两种变换可以提高HIN在实体水平上的表达能力。(2) 去除多空间投影对结果的影响为1.72%,这说明该模型能够联合处理不同表示子空间的信息。(3) 当去掉句子级推理机制,即用句子向量代替句子级推理向量时,F1下降了1.25%。(4) 当我们放弃分层聚合方法时,F1下降了2.81%。相反,我们在整个文档上运行BiLSTM,然后运行meanpooling层来获得文档向量。(5) 我们还观察到,当我们把上述所有因素一起丢弃时,F1下降了4.21%。总之,所有组件在我们的模型中都扮演着重要的角色。
Analysis by the number of supporting sentences

正如我们之前所讨论的,文档级RE从多个句子推理是一个挑战。为了进一步证明HIN的有效性,我们在这里分析了不同支持句数量的关系事实的Recall。如图3所示,我们发现我们的模型总是比其他基线表现更好,特别是当支持句数量逐渐增加时。更具体地说,当支持句个数超过4个时,HIN-GloVe的性能甚至优于BERT-RE,充分证明了HIN的优越性。请注意,当支持句的数目超过7时,HIN GloVe和其他基线的行为相同。我们认为这是因为在dev集合中只有很少的样本有超过7个支持句。我们相信当支持句较多的关系事实的数量增加时,我们的模型会取得更好的结果。
6 Conclusion
本文提出了一种用于文档级推理的层次推理网络(HIN)。它采用分层推理的方法,将实体级、句子级和文档级的推理信息进行聚合。我们证明了我们的方法在最大的人类注释DocRED数据集上达到了最先进的性能。实验分析表明,该模型中的推理机制和层次聚合方法都起着重要的作用。在未来,我们计划结合外部知识来进一步改进所提出的模型。
参考:
小毛日记:https://zhuanlan.zhihu.com/p/156127013
codewithzichao:https://codewithzichao.github.io/2020/10/24/NLP-RE-Integrate-GNN-into-Document-level-RE-task-PART-TWO/


 浙公网安备 33010602011771号
浙公网安备 33010602011771号