【论文阅读】Cross-Sentence N-ary Relation Extraction with Graph LSTMs[ACL2017]
论文链接:https://www.aclweb.org/anthology/Q17-1008.pdf
代码链接(theano):https://github.com/VioletPeng/GraphLSTM_release
In this paper, we explore a general relation extraction framework based on graph long short-term memory networks (graph LSTMs) that can be easily extended to cross-sentence n-ary relation extraction. The graph formulation provides a unified(统一的) way of exploring different LSTM approaches and incorporating various intra-sentential and inter-sentential dependencies, such as sequential, syntactic, and discourse relations(语篇关系).A robust contextual representation is learned for the entities, which serves as input to the relation classifier. This simplifies handling of relations with arbitrary arity(简化了任意参数数量的关系的处理), and enables multi-task learning with related relations.
1 Introduction
介绍了文档级关系抽取必要性。
In this paper, we explore a general framework for cross-sentence n-ary relation extraction, based on graph long short-term memory networks (graph LSTMs). By adopting the graph formulation, our framework subsumes prior approaches based on chain or tree LSTMs, and can incorporate a rich set of linguistic analyses to aid relation extraction. Relation classification takes as input the entity representations learned from the entire text关系分类以从整个文本中学习到的实体表示作为输入, and can be easily extended for arbitrary relation arity n. This approach also facilitates促进 joint learning with kindred relations where the supervision signal is more abundant.这种方法也有助于在监督信号更丰富的类似关系中进行联合学习。
Graph LSTMs that encode rich linguistic knowledge outperformed other neural network variants, as well as a well-engineered feature-based classifier.Multitask learning with sub-relations led to further improvement. Syntactic analysis conferred a significant benefit to the performance of graph LSTMs, especially when syntax accuracy was high.句法分析对图LSTMs的性能有很大的帮助,尤其是在句法精度较高的情况下。
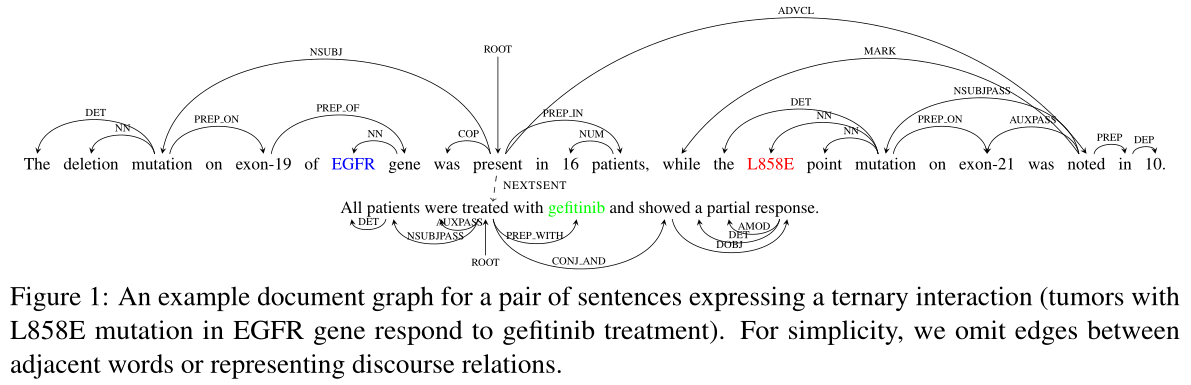
两个句子的依存树以及(EGFR,gefitinib,L858E:EGFR基因L858E突变的肿瘤对gefitinib治疗有反应)三元关系,ternary interaction :三元相互作用
2 Cross-sentence n-ary relation extraction
在标准的二元关系设置中,主要的方法通常是根据所讨论的两个实体之间的最短依赖路径来定义的,或者从路径中导出丰富的特征,或者使用深度神经网络对其进行建模。将这种范式推广到n元环境是很有挑战性的,因为有$C_n^2$路径。一个明显的解决方案是受戴维森语义学Davidsonian semantics的启发:首先,识别一个表示整个关系的触发器短语,然后将触发器和参数之间的n元关系简化为n个二进制关系。first, identify a single trigger phrase that signifies the whole relation, then reduce the n-ary relation to n binary relations between the trigger and an argument.通常很难指定一个触发器,因为关系是由几个词表示的,这些词通常不是连续的。此外,对训练示例进行注释是昂贵且耗时的,尤其是在需要触发器的情况下,这在以前的注释工作(如GENIA)中是很明显的。
此外,表示这种关系的词汇和句法模式将是稀疏的。为了处理这种稀疏性,传统的基于特征的方法需要大量的工程和大数据。不幸的是,当文本跨越多个句子时,这种挑战在跨句抽取中变得更加严峻。
3 Graph LSTMs
Graph LSTM以前从未应用于NLP任务,模型结构图:
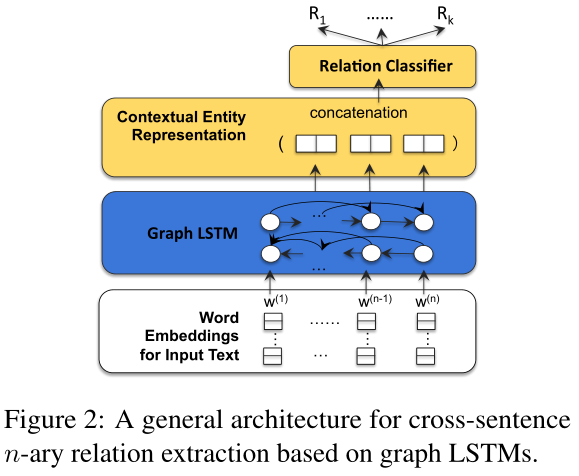
The input layer is the word embedding of input text.
Next is the graph LSTM which learns a contextual representation for each word. For the entities in question, their contextual representations are concatenated and become the input to the relation classifiers
For a multi-word entity, we simply used the average of its word representations and leave the exploration of more sophisticated aggregation approaches to future work.
At the core of the graph LSTM is a document graph that captures various dependencies among the input words. By choosing what dependencies to include in the document graph, graph LSTMs naturally subsumes linear-chain or tree LSTMs.
与传统的LSTMs相比,图的形式提出了新的挑战。由于图中存在潜在的循环,反向传播的直接实现可能需要多次迭代才能达到一个固定点。此外,在存在大量边类型(相邻词、句法依赖等adjacent-word, syntactic dependency, etc.)的情况下,参数化成为一个关键问题。
在本节的剩余部分中,我们首先介绍文档图,并展示如何在图LSTMs中进行反向传播。然后,我们讨论两种策略参数化的经常单位。最后,我们展示了如何在这个框架下进行多任务学习。
3.1 Document Graph
This document graph acts as the backbone主干 upon which a graph LSTM is constructed.If it con- tains only edges between adjacent words, we recover linear-chain LSTMs. Similarly, other prior LSTM approaches can be captured in this framework by restricting edges to those in the shortest dependency path or the parse tree.【如果只研究相邻单词之间的边,使用linear-chain LSTM模式,将边切换到the shortest dependency path or parse tree,捕获依赖关系】
3.2 Backpropagation in Graph LSTMs
作者考虑如果图中存在循环边,则梯度下降不好计算。在本文中,我们采用了一种简单的策略,在初步实验中取得了很好的效果,并对今后的工作做了进一步的探索。具体地说,我们将文档图划分为两个有向无环图(DAGs)。一个DAG包含从左到右的线性链以及其他前向指向依赖项。另一个DAG包含从右到左的线性链和向后指向的依赖关系。图3说明了这个策略。有效地,我们将原始图划分为向前的过程(从左到右),然后是向后的过程(从右到左),并相应地构造LSTMs。当文档图只包含线性链边linear chain edges时,graph LSTMs就是一个双向LSTMs(BiLSTMs)。
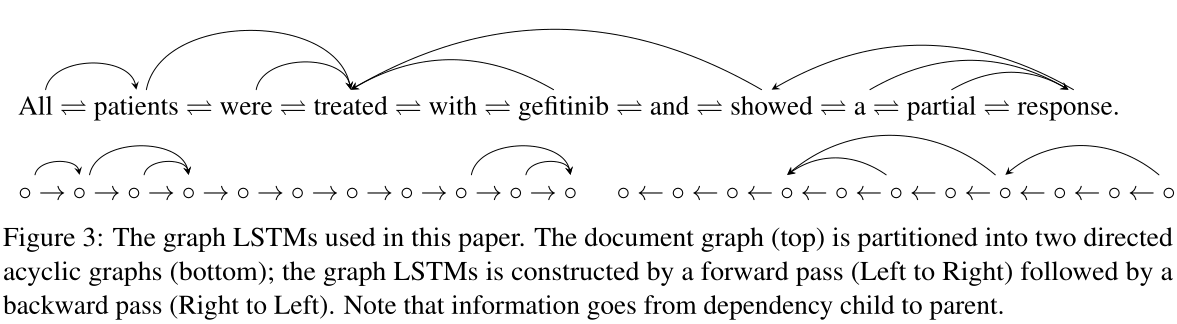
图3:本文使用的图LSTMs。文档图(顶部)被划分为两个有向无环图(底部);图LSTMs由前向传递(从左到右)和后向传递(从右到左)构成。请注意,信息从依赖关系的子节点传递到父节点。
3.3 The Basic Recurrent Propagation Unit
在linear-chain LSTMs中,每个单元只包含一个遗忘门,因为它只有一个直接的precedent前继节点(即,相邻的单词边指向前一个单词)。然而,在graph LSTMs中,一个单元可能有几个precedent,包括通过不同的边连接到同一个单词。因此,我们为每个precedent前继节点引入一个遗忘门。
Encoding rich linguistic analysis introduces many distinct edge types besides word adjacency, such as syntactic dependencies, which opens up many possibilities for parametrization. This was not considered in prior syntax-aware LSTM approaches (Tai et al., 2015; Miwa and Bansal, 2016). In this paper, we explore two schemes that introduce more fined-grained parameters based on the edge types.编码丰富的语言分析除了引入单词邻接外,还引入了许多不同的边缘类型,例如句法依赖,这为参数化提供了许多可能性。以前的语法感知LSTM方法没有考虑到这一点(Tai等人,2015;Miwa和Bansal,2016)。在本文中,我们探讨了两种基于边缘类型引入更细粒度参数的方案。
Full Parametrization
我们的第一个建议只是为每种边类型引入一组不同的参数,具体计算如下。$\bigodot$表示element-wise乘法
$i_t=\sigma(W_ix_t+\sum_{j∈P(t)}U_{i}^{m(t,j)}h_{j}+b_i)$
$o_t=\sigma(W_ox_t+\sum_{j∈P(t)}U_{o}^{m(t,j)}h_{j}+b_o)$
$f_{tj}=\sigma(W_fx_t+U_f^{m(t,j)}h_{j}+b_f)$
$ \tilde{c_t}=tanh(W_cx_t+\sum_{j∈P(t)}U_{c}^{m(t,j)}h_{j}+b_c)$
$c_t=i_t\bigodot \tilde{c_t}+\sum_{j∈P(t)}f_{tj}\bigodot c_{j}$
$h_t=o_t\bigodot tanh(c_t)$
In graph LSTMs, a unit might have multiple predecessors$ (P(t))$,for each of which $(j)$ there is a forget gate $f_{tj}$, and a typed weight matrix $U^{m(t,j)}$,where $m(t, j)$ signifies the connection type between $t$ and $j$.The input and output gates $(i_t, o_t)$ depend on all predecessors, whereas the forget gate $(f_{tj})$ only depends on the predecessor with which the gate is associated.$c_t$and$\tilde{c_t}$ represent intermediate computation results within the memory cell.
Full parameterization is straightforward, but it requires a large number of parameters when there are many edge types. For example, there are dozens of syntactic edge types, each corresponding to a Stanford dependency label. As a result, in our experiments we resort to using only the coarse-grained types: word adjacency, syntactic dependency, etc. Next, we will consider a more fine-grained approach by learning an edge-type embedding.完全参数化很简单,但是当有许多边类型时,它需要大量的参数。例如,有几十种语法边缘类型,每种类型对应一个斯坦福依赖标签。因此,在我们的实验中,我们只使用粗粒度的类型:单词邻接、句法依赖等。接下来,我们将考虑通过学习边缘类型嵌入来实现更细粒度的方法。
Edge-Type Embedding
To reduce the number of parameters and leverage potential correlation among fine-grained edge types, we learned a lowdimensional embedding of the edge types, and conducted an outer product of the predecessor’s hidden vector and the edge-type embedding to generate a “typed hidden representation”, which is a matrix. The new computation is as follows:
为了减少参数的数目和利用细粒度边缘类型之间的潜在相关性,我们学习了边缘类型的低维嵌入,并将前一个隐向量与边缘类型嵌入进行外积,生成一个“类型化隐表示”,即一个矩阵。新的计算方法如下:
$i_t=\sigma(W_ix_t+\sum_{j∈P(t)}U_{i}×_T(h_{j}\bigotimes e_j)+b_i)$
$o_t=\sigma(W_ox_t+\sum_{j∈P(t)}U_{o}×_T(h_{j}\bigotimes e_j)+b_o)$
$f_{tj}=\sigma(W_fx_t+U_f×_T(h_{j}\bigotimes e_j)+b_f)$
$ \tilde{c_t}=tanh(W_cx_t+\sum_{j∈P(t)}U_{c}×_T(h_{j}\bigotimes e_j)+b_c)$
$c_t=i_t\bigodot \tilde{c_t}+\sum_{j∈P(t)}f_{tj}\bigodot c_{j}$
$h_t=o_t\bigodot tanh(c_t)$
其中$U$等是$l×l×d$Tensor($l$是隐藏向量的维度,$d$是边类型embedding的维度),$h_j⊗e_j$是张量积tensor product产生$l×d$矩阵。$×_T$表示张量点乘积tensor dot prdouct定义为$T×_TA=\sum_d(T{:,:,d} \cdot A{:,d})$,产生$l$维度向量。边类型embedding$e_j$伴随其他参数联合训练。
3.4 Comparison with Prior LSTM Approaches
Miwa and Bansal(2016)通过将一个用于关系提取的LSTM堆叠在另一个用于实体识别的LSTM之上,进行了联合实体和二元关系提取。在graph-LSTMs中,可以使用文档图将两者无缝地结合起来,文档图包括单词邻接链和两个实体之间的依赖路径。文档图还可以包含其他语言信息。例如,共指和语篇分析coreference and discourse parsing在跨句关系抽取中具有直观的相关性。尽管现有系统尚未显示出能够改善句子间关系提取,但探索合并此类分析仍然是一个重要的未来方向。
3.5 Multi-task Learning with Sub-relations
Multi-task learning has been shown to be beneficialin training neural networks (Caruana, 1998; Collobert and Weston, 2008; Peng and Dredze, 2016). By learning contextual entity representations, our framework makes it straightforward to conduct multi-task learning. The only change is to add a separate classifier for each related auxiliary relation. All classifiers share the same graph LSTMs representation learner and word embeddings, and can potentially help each other by pooling their supervision signals.多任务学习已被证明有利于神经网络的训练。通过学习上下文实体表示,我们的框架可以直接进行多任务学习。唯一的变化是为每个相关的辅助关系添加一个单独的分类器。所有分类器共享相同的图表示学习者和词嵌入,并且可以通过汇集它们的监督信号来相互帮助。
In the molecular tumor board domain, we applied this paradigm to joint learning of both the ternary relation (drug-gene-mutation) and its binary sub-relation (drug-mutation). Experiment results show that this provides significant gains in both tasks.分子肿瘤板领域,我们将这种范式应用于三元关系(药物基因突变)和二元子关系(药物突变)的联合学习。实验结果表明,这在两种任务中都提供了显著的收益。【三元关系和二元关系联合学习就算多任务了】
4 Implementation Details
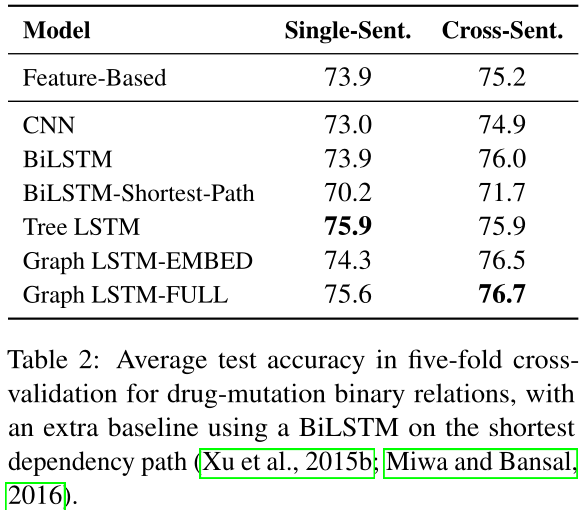
我们评估两个各种各样的graph LSTMs:“Graph LSTM-FULL” 有全参数化和 “Graph LSTM-EMBED” 伴随边类型embedding。我们对比graph LSTMs伴随三个强基准系统:一个设计好的基于特征的分类器,一个CNN,一个BiLSTM。随着Wang等,我们使用输入attention对于CNN和一个输入窗口大小5。Quirk和Poon仅仅抽取二院关系。我们扩展到三元关系通过剥离特征到每个实体对(伴随增加标注去增大两个实体类别),池化所有对的特征。
对于二元关系抽取,先验syntax-aware方法直接适当的。所以我们还对比当前的树LSTM系统和BiLSTM在最短依赖路径在两个实体之间。
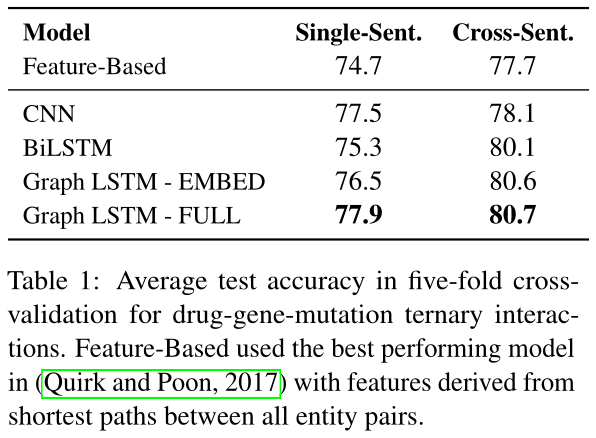
Table 1展示交叉句子的结果,三元关系抽取。所有神经网络基于模型表现好于基于特征的分类器,表明它们在处理稀有语言模型不带需要的强度特征工程的优势。所有LSTMs显著地好于CNN在交叉句子设置,正式捕获长距离依赖的重要性。
两个graph LSTMs的变种执行在每个,尽管Graph LSTM-FULL拥有一个小的优势,认为更多探索参数化策略可以有用。特别的,edge-type embedding可能增强通过预训练在未标记文本伴随句法分析。
两个graph变种显著的表现好于BiLSTMs($p < 0.05$通过McNemar's chi-square测试),尽管区别很小。结果令人振奋。在Quirk和Poon,最好的系统合并句法依赖且表现好于线性链变体通过一个大的margin。所以为什么graph LSTMs不能获得一个相等的显著结果通过建模句法依赖。
一个原因是线性链LSTMs可以已经捕获一些长距离依赖可用在句法分析。BiLSTMs显著的表现好于基于特征的分类器,甚至不带独特的句法依赖建模。结果不能完全贡献到词embedding由于LSTMs表现好于CNNs。
另一个原因是句法分析比生物医学领域少正确率。分析错误使困难graph LSTM学习,限制潜在的获得。在部分6,我们展示支持的证据在金分析可用的领域。
我们还报告准确率在单个句子的实例上,展示广泛的相似的集的趋势。注意到单个句子和交叉句子准确率不是直接对比的,由于测试集不同(一个归纳入另一个)。
我们执行同样的实验在二元副关系在药物-变异对。Table 2展示结果,相似于三元例子:Graph LSTM-FULL一贯的表现的最好对于单个句子和价差句子实例。BiLSTMs在最短路径显著的表现差于BiLSTMs或者graph LSTMs,大约差了4-5点的准确率,可以贡献于低分析质量的生物医学领域。有趣的,现存的树LSTMs也表现差于graph LSTMs,尽管他们编码本质的同样的语言结构(词邻近和句法依赖)。我们贡献获得的事实Miwa和Bansal使用的分离的LSTMs对于线性链和依赖树,然而graph LSTMs学习单个表示对于两个。
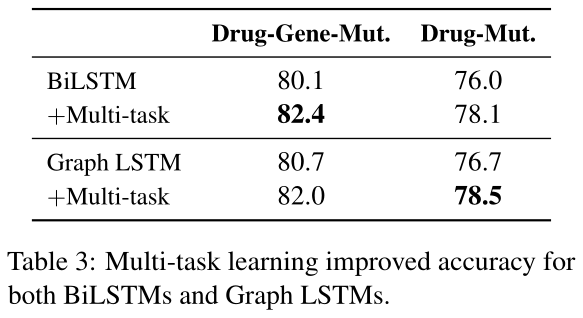
去评估是否共同学习伴随副关系可以帮助,我们执行多任务学习使用Graph LSTM-FULL共同训练抽取器对三元交互关系和药物-变异,药物-基因从属关系。Table 3展示了结果。多任务学习结果重大的获得对于三元交互关系和药物-变异交互关系。有趣的,graph LSTMs对于BiLSTMs的优势是减少多任务学习,揭示伴随更多监督信号,甚至线性链LSTMs可以学习捕获长范围依赖,通过分析graph LSTMs的特征的证据。注意到有许多实例对于药物-基因交互关系相比其他,所以我们仅仅采样相当大小的子集。因此,我们不评估药物-基因交互关系的表现,在实践中,可以简单学习所有可用数据,子样例结果不可比。
我们包括互参和语篇关系在我们的文档graph。然而,我们没有观察任何重大的获得,相似的观察在Quirk和Poon。我们留在更多的探索在之后的工作。
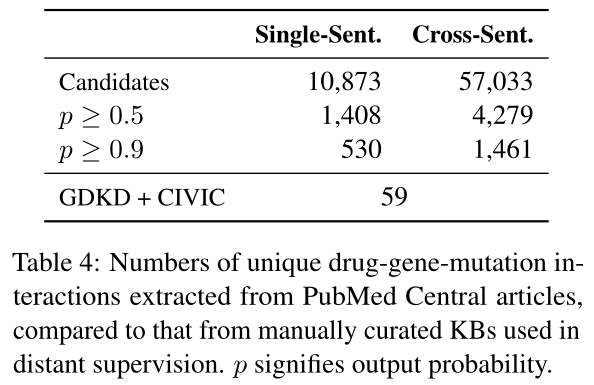
5.4 PubMed-Scale抽取
我们最终的任务是抽取所有知识来自可用的文本。我们因此重新训练我们的模型使用最好的系统来自自动评估(也就是Graph LSTM-FULL)在所有可用的数据。结果模型用来抽取关系来自所有PubMed Central文章。
Table 4展示候选数量和抽取的交互关系。59个独立基因-药物-变异三元来自两个数据集,我们学习到抽取巨大更多独一无二交互关系顺序。结果还强调交叉句子抽取的有用性,产生3到5次更多关系相比单个句子抽取。
Table 5执行相似对比在唯一的药物,基因,变异的数量。再一次,机器阅读覆盖更多唯一实体,特别是伴随句子抽取。
5.5 人工评估
我们自动评估对比计算方法是有用的,但是可能不反应真分类器精准由于标记有噪音。因此,我们随机采样抽取关系实例并找三个知识的研究员在精准医学去评估它们的正确性。对于实例,标注被呈现伴随起源:句子伴随药物。基因和变异被强调。标注着决定每个例子不管这个实例暗示给出的实体是相关的。注意到评估不试图辨认是否关系是真的或复制在接下来的paper;当然,它关注在是否关系是需要的通过文本。
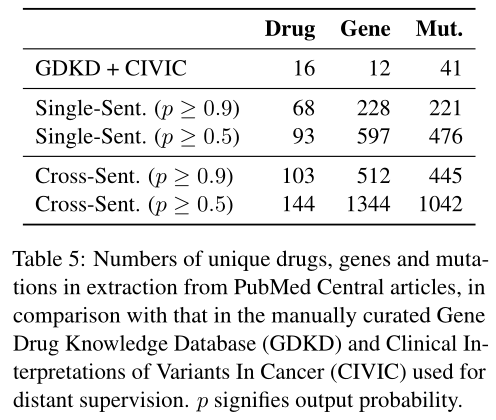
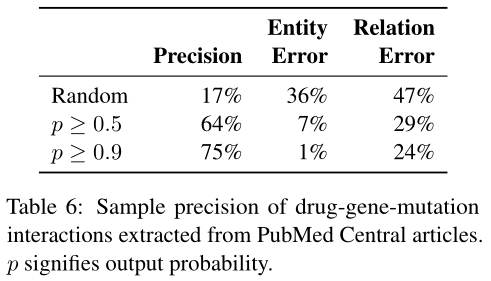
我们关注我们的评估成就在交叉句子三元关系设置。我们考虑三个可能threshold:0.9对于高precision但是可能的低recall设置,0.5,和随机的所有候选的样例。对每个例子,150样例被选择对于所有450个标注。一个150实例的子集被两个标注者检查,inter-annotator同意达88%。
Table 6展示分类器确实过滤掉大部分潜在候选,伴随评估实例准确率64%在threshold0.5,和75%在0.9。有趣的是,LSTMs是有效率的在筛选出许多实体提及错误,可能因为他们包括广泛文本特征。
6 Domain: Genetic Pathways
我们还执行实验在抽取基因途径交互关系使用GENIA事件抽取数据集。这个数据集包括金句法分析对于句子,赋予一个唯一机会去调查句法分析的影响在graph LSTMs。它还允许我们测试我们的框架在监督学习。
原始共享任务评估在复杂叠套的事件对九事件类别,许多是一元关系。跟随Poon等,我们关注在基因标准化并减少它的二元关系分类对于head-to-head对比。我们跟随他们的实验准则通过sub采样负向样例到三次正向样例。
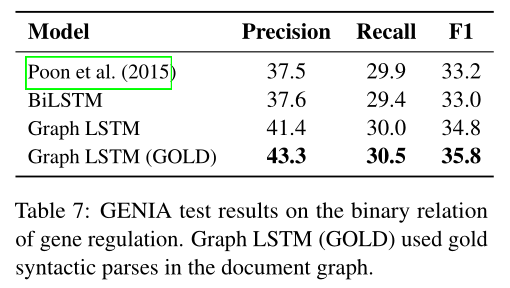
由于数据集不是完全平衡的,我们报告precision, recall, and F1。我们使用我们最好的graph LSTM表现来自之前实验。默认的,自动分析被用在文档graph,然而在Graph LSTM(GOLD),gold分析被使用。Table 7展示结果。再一次,尽管缺乏强度特征工程,线性链LSTMs呈现在对上伴随基于特征分类器。Graph LSTMs展示更多优势在线性链LSTMs在这个领域,显著的表现好于后者($p < 0.01$通过McNemar's chi-square测试)。最有趣的是,graph LSTMs使用gold分析显著的表现好于使用的自动分析,揭示编码高度质量分析是十分有用的。
7 Related Work
大多在关系抽取已经应用到单个句子的实体的二元关系。我们首先检查相关工作在单个句子二元关系抽取任务,接着检查相关工作n元交叉句子关系抽取。
二元关系抽取 传统基于特征的方法依赖仔细的设计特征学习好的模型,经常融入多样的证据来源例如词序列和句法文本。基于核方法设计各种sub序列或者树核去捕获结构信息。最近,模型基于神经网络增进现存通过自动学习有力的特征表示。
大多神经结构集结Figure 2,其中有核表示学习器(蓝色)去词embedding作为输入并产生文本实体表示。如此表示取关系分类器产生最终预测。有效的表示词序列,同时卷积和基于RNN的结构都成功。大多关注模型既是表面词序列或是等级句法结构。Miwa和Bansal提出按个结构利于两种信息类型,使用表面序列层,跟随依赖树序列层。
n元关系抽取 早期工作在抽取关系,在多于两个参数之间在MUC-7,重点关注事实/事件抽取来自新闻标题。情感角色标记在Propbank或者FrameNet风格以及n元关系抽取实例,伴随抽取事件表达在单个句子。McDonald等抽取n元关系在生物医学领域,首先考虑n元关系配对关系在所有实体对之间,接着构建最大相关的实体圈子。最近,神经模型应用情感角色标记。这些工作学习神经表示通过有效的分解n元关系到二元关系在谓语和每个主题之间,通过embedding这个依赖路径在每个对之间,或者通过合并两个使用前向网络的特征。尽管一些再排序或者共同inference模型已经被采用,个体主题的表示不会相互影响。对比的,我们提出一个神经结果共同的表示n实体mention,考虑长距离依赖和inter句子信息。
交叉句子关系抽取 几个关系抽取任务有利来自交叉句子抽取,包括MUC因素和事件抽取,记录抽取来自web pages,生物医学领域因素抽取,并语义角色标记覆盖含蓄inter句子主题扩展。这些先前的工作要么依赖特别的共同reference标注,或者假设全部文档refer到单个coherent时间,去简化问题并减少需求对强大的多句子文本实体mention的表示。最近,交叉句子关系抽取模型已经被学习伴随弱监督,且使用整体的文本多重类型证据不带依赖在这些假设上,但是工作关注在二院关系仅仅且特别的工程稀少指示器特征。
关系抽取使用弱监督 弱监督应用到抽取二元和n元关系,传统的使用手工工程特征。神经结构最近应用弱监督抽取二元关系。我们的工作是首先提出一个神经结构用于n元关系抽取,其中tuple个实体的表示不可分解到独立表示的个体实体或实体对,整体多样信息来自多句子文本。为了利用训练数据更有效,我们展示如何多任务学习对组成的二元sub关系可以曾倩表现。我们学习的表示合并信息源带着单个句子在一个更整体和一般化相比先前方法,可以增强单个句子二元关系抽取的表现。
8 Conclusion
我们探索一个一般框架对交叉句子n元关系抽取基于graph LSTMs。graph公式化归纳线性链和树LSTMs且使得它简单合并富语言分析。实验在生物医学领域展示超过句子边界的提取产生更多知识,对丰富的语言知识进行编码可以获得持续的收获。
虽然在召回和准确性方面都有很大的改进空间,但我们的结果表明,机器阅读在精准医疗方面已经很有用了。特别是,自动提取的事实(章节5.4)可以作为人工管理的候选对象。人类策展人不会从头开始扫描数百万篇文章,而是会快速审查数千篇摘录。馆长发现的错误为机器阅读系统的持续改进提供了直接监督。因此,最重要的目标是达到高的查全率和合理的查准率。我们目前的型号已经相当有能力了。
未来的发展方向包括:用户反馈的交互式学习;改进图LSTMs的语篇建模方法探索其他反向传播策略;联合学习与实体联结;应用程序到其他域。
参考:
论文阅读:https://www.jianshu.com/p/9ead20c4ebe0
论文笔记:https://www.moshangxingzou.com/index.php/2020/05/19/554/#comment-1373


 浙公网安备 33010602011771号
浙公网安备 33010602011771号