【论文阅读】Attention-based bidirectional long short-term memory networks for relation classification[ACL2016]
原文链接:https://www.aclweb.org/anthology/P16-2034/
代码链接(Pytorch):https://github.com/zhijing-jin/pytorch_RelationExtraction_AttentionBiLSTM
作者只使用了预训练词向量以及,没有借助其他词汇资源,和上一篇作者相同。
⟨e1⟩ Flowers ⟨/e1⟩ are carried into the ⟨e2⟩ chapel ⟨/e2⟩.⟨e1⟩,⟨/e1⟩,⟨e2⟩,⟨/e2⟩是四个位置指示器,用于指定名称的开始和结束。
手工特征费时费力泛化能力差。深度学习方法提供了减少手工特征数量的有效方法,这些方法使用词汇资源(such as WordNet, NER,POS,dependency parsers).Our model utilizes neural attention mechanism with Bidirectional Long Short-Term Memory Networks(BLSTM)捕捉句子中最重要的语义信息。该模型不使用任何来自词汇资源或NLP系统的特性。
使用数据集:SemEval-2010-task-8
F1-score:论文作者:84.0%;Pytorch复现:71%
2 Related Work
双向RNN能够访问过去和未来的上下文信息,为了克服存在的梯度消失问题引入了LSTM。
Zhang et al. (2015)提出BLSTM模型,This model utilizing NLP tools and lexical resources to get word, position, POS, NER, dependency parse and hypernym features, together with LSTM units, achieved a comparable result to the state-ofthe-art.
our method regards the four position indicators ⟨e1⟩,⟨/e1⟩,⟨e2⟩,⟨/e2⟩ as single words, and transforms all words to word vectors, forming a simple but competing model.简单但有效
3 Model
在Attention BiLSTM网络中,主要由5个部分组成:
- 输入层(Input layer):指的是输入的句子,对于中文,指的是对句子分好的词;
- Embedding层:将句子中的每一个词映射成固定长度的向量;
- LSTM层:利用双向的LSTM对embedding向量计算,实际上是双向LSTM通过对词向量的计算,从而得到更高级别的句子的向量;
- Attention层:对双向LSTM的结果使用Attention加权;produce a weight vector, and merge word-level features from each time step into a sentence-level feature vector, by multiplying the weight vector;
- 输出层(Output layer):输出层,输出具体的结果。the sentence-level feature vector is finally used for relation classification.
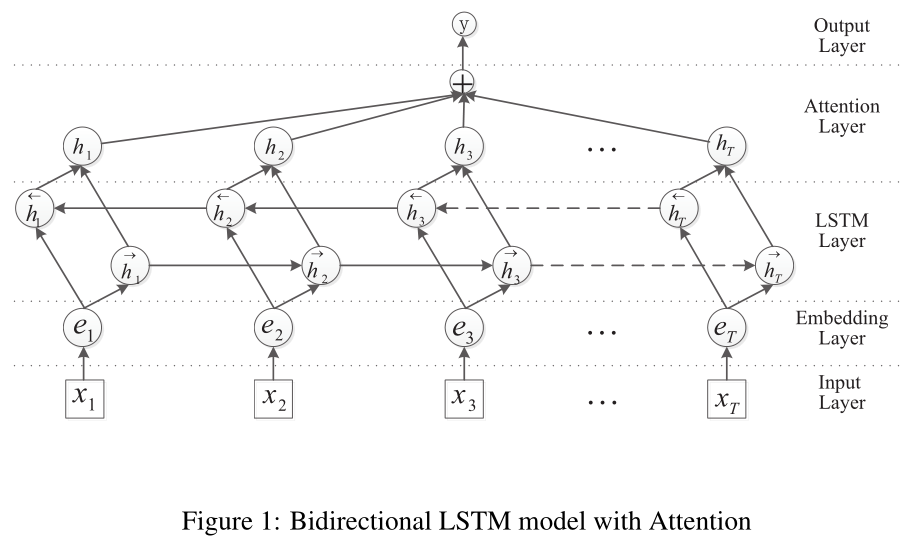
3.1 Word Embeddings
句子$S$,句长$T$,$S={x_1,x_2,...,x_T}$,每个$x_i$convert to real-valued vector $e_i$,,the embedding matrix $W^{wrd}∈R^{d^w|V|}$,$V$是一个固定大小的词汇表is a fixed-sized vocabulary,$d^w$ is the size of word embedding,本实验$W^{wrd}$是一个要学习的参数,$d^w$ is a hyper-parameter.We transform a word $x_i$ into its word embedding $e_i$ by using the matrix-vector product:
$e_i=W^{wrd}v^i$
where $v^i$is a vector of size $|V|$ which has value 1 at index $e_i$ and 0 in all other positions.Then the sentence is feed into the next layer as a real-valued vectors$emb_s={e_1,e_2,...,e_T}$
3.2 Bidirectional Network
双向LSTM是RNN的一种改进,其主要包括前后向传播,每个时间点包含一个LSTM单元用来选择性的记忆、遗忘和输出信息。LSTM单元的公式如下:
$i_t=\sigma(W_{x_i}x_t+W_{h_i}h_{t-1}+W_{c_i}c_{t-1}+b_i)$
$f_t=\sigma(W_{x_f}x_t+W_{h_f}h_{t-1}+W_{c_f}c_{t-1}+b_f)$
$g_t=tanh(W_{x_c}x_t+W_{h_c}h_{t-1}+W_{c_c}c_{t-1}+b_c)$
$c_t=i_tg_t+f_tc_{t-1}$
$o_t=\sigma(W_{x_o}x_t+W_{h_o}h_{t-1}+W_{c_o}c_{t}+b_o)$
$h_t=o_ttanh(c_t)$
模型的输出包括前后向两个结果,通过对应元素相加(element-wise sum)$h_t=[\overleftarrow{h_t}\oplus\overrightarrow{h_t}]$作为最终的Bi-LSTM输出。
3.3 Attention
In this section, we propose the attention mechanism for relation classification tasks.$H$是由LSTM层产生的$[h_1,h_2,...,h_T]$,其中$T$是句子长度。The representation r of the sentence is formed by a weighted sum of these output vectors:
$M=tanh(H)$
$\alpha=softmax(w^TM)$
$r=H\alpha^T$
其中$H∈R^{d^w*T}$,$d^w$ is the dimension of the word vectors,$w$ is a trained parameter vector and $w^T$ is a transpose. The dimension of $w$,$α$,$r$ is $d^w$, $T$, $d^w$separately.
We obtain the final sentence-pair representation used for classification from:
$h^{*}=tanh(r)$
3.4 Classifying
The classifier takes the hidden state $h^{*}$ as input:
$\hat{p}(y|S)=softmax(W^{(S)}h^{*}+b^{S})$
$\hat{y}=arg\max_y\hat{p}(y|S)$
The cost function is the negative log-likelihood of the true class labels $\hat{y}$:
$J(\theta)=-\frac{1}{m}\sum_{i=1}^mt_ilog(y_i)+\lambda||\theta||_F^2$
$t ∈ ℜ^m$ is the one-hot represented ground truth,$y ∈ ℜ^m$is the estimated probability for each class by softmax (m is the number of target classes).and $λ$ is an L2 regularization hyperparameter. In this paper, we combine dropout with L2 regularization to alleviate overfitting.
3.5 Regularization
We employ dropout on the embedding layer, LSTM layer and the penultimate(倒数第二) layer.We additionally constrain L2-norms of the weight vectors by rescaling(重新缩放) $w$ to have $∥w∥ = s$, whenever $∥w∥ > s$ after a gradient descent step, as shown in equation 15. Training details are further introduced in Section 4.1
4 Experiments
4.1 Dataset and Experimental Setup
采用SemEval-2010 Task 8数据集,We adopt the official evaluation metric(评估指标) to evaluate our systems, which is based on macro-averaged F1score for the nine actual relations (excluding the Other relation) and takes the directionality into consideration.由于没有官方的dev数据集,我们随机选取800句进行验证。我们模型的超参数根据每个任务的开发集进行了调整。我们的模型使用AdaDelta(Zeiler,2012)进行训练,学习率为1.0,minibatch大小为10。The model parameters were regularized with a perminibatch L2 regularization strength of $10^{-5}$。We evaluate the effect of dropout embedding layer, dropout LSTM layer and dropout the penultimate layer, the model has a better performance, when the dropout rate is set as 0.3, 0.3, 0.5 respectively. Other parameters in our model are initialized randomly.
4.2 Experimental Results
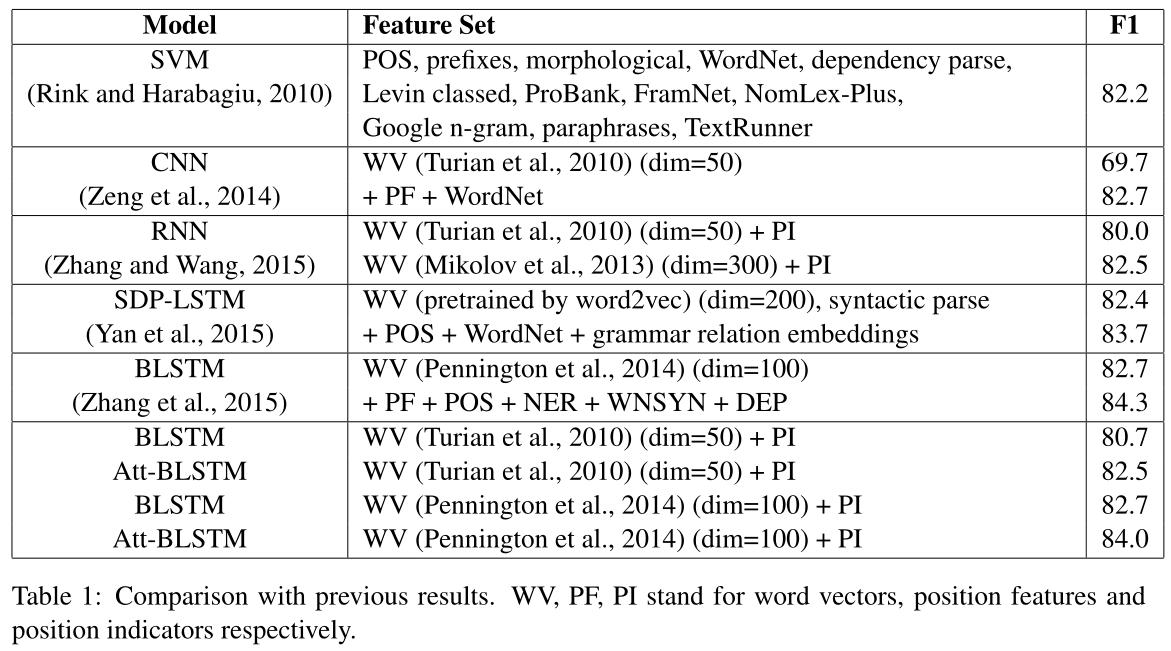
5 Conclusion
本文提出了一种新的关系分类神经网络模型Att-BLSTM。该模型不依赖NLP工具或词法资源获取,而是使用带有位置指示符的原始文本作为输入。以SemEval-2010关系分类任务为例,验证了AttBLSTM模型的有效性。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号