【论文阅读】Position-aware Attention and Supervised Data Improve Slot Filling[EMNLP2017]
论文地址:https://www.aclweb.org/anthology/D17-1004.pdf
代码地址:https://github.com/yuhaozhang/tacred-relation (原作者)
https://github.com/onehaitao/PA-LSTM-relation-extraction (复现)
“slot filling” task of filling in the relations between entities in the text.
This work addresses both of these problems.We propose a new, effective neural network sequence model for relation classification. Its architecture is better customized for the slot filling task: the word representations are augmented by extra distributed representations of word position relative to the subject and object of the putative relation.
On TACRED, our system achieves a relation classification F1score that is 5.7% higher than that of a strong feature-based classifier, and 2.4% higher than that of the best previous neural architecture that we re-implemented.
A Position-aware Neural Sequence Model Suitable for Relation Extraction
现有的用于关系抽取的神经网络模型主要存在以下两方面的问题:(1)尽管LSTM网络等序列模型采用门机制(gating mechanisms)来控制每个单词对句子最终表示的相对影响,这些控制往往无法覆盖整个语句;(2)大多数现有模没有对序列中实体的位置建模,或者只建模了局部区域的位置信息。
为了解决这些问题,我们提出了一种基于LSTM网络的具有位置感知注意机制(position-aware attention mechanism)的神经序列模型。该模型可以(1)在看到整个序列后,评价每个单词的相对贡献;(2)这种评价不仅基于序列的语义信息,还基于序列中实体的全局位置。
句子:$X=[x_1,...,x_n]$,用 $X_s=[x_{s_1},x_{s_1+1},...,x_{s_2}]$和 $X_o=[x_{o_1},x_{o_1+1},...,x_{o_2}]$分别表示句子中主实体$s$和从实体$o$分别对应的两个不重叠的连续区间,按照下式定义一个与主实体$s$相关的位置序列$[P_1^s,...,P_n^s]$:
$$ P_i^{s}=\left\{ \begin{array}{rcl} i-s_1 & & {i < s_1}\\0 & & {s_1 \leq i \leq s_2}\\ i-s_2 & & {i>s_2} \end{array} \right. $$
其中$s_1$与$s_2$分别是主实体的起始和中止索引值,从实体的位置序列$[P_1^o,...,P_n^o]$同理。位置序列中的每个元素可以视为$x_i$关于对应实体的相对距离。
引入位置attention机制的LSTM模型见下图:
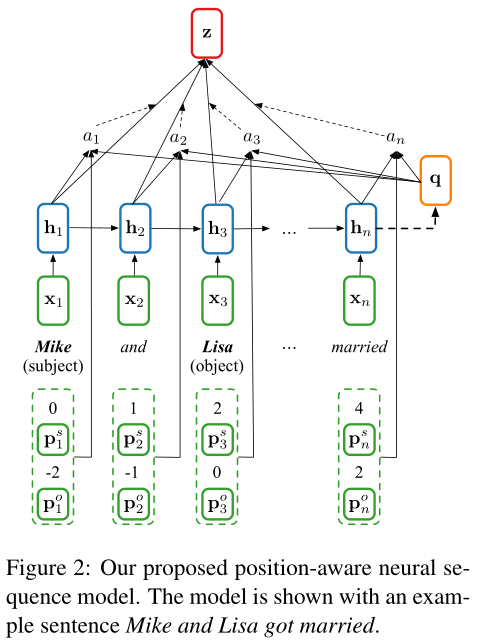
输入层为句子中每个单词的词嵌入表示,通过输入词嵌入序列得到句子的隐层表示,word embedding matrix $E∈R^{|V|*d}$,而位置嵌入序列 $P^s=[P_1^s,...,P_n^s]$和 $P^o=[P_1^o,...,P_n^o]$则通过位置嵌入矩阵 $P∈R^{(2L-1)*d_p}$求得(2L-1是句中实体的相对位置的取值范围长度,实体在句首可以取到L,实体在句尾可以取到-L)。
${h_1,...,h_n}=LSTM(\{x_1,...,x_n\})$
将LSTM的输出状态 $h_n$定义为序列的概要向量summary vector $q=h_n$,可以认为此向量编码了整个句子的信息。
对于每个隐层状态$h_i$ ,按照下式分别定义其attention权值:
$u_i=v^Ttanh(W_hh_i+W_qq+W_sP_i^s+W_oP_i^o)$
$a_i=\frac{exp(u_i)}{\sum_{j=1}^nexp(u_j)}$
由此,将矩阵 $W_h,W_q∈R^{d_a*d}$,$W_s,W_o∈R^{d_a*d_p}$ 和$v∈R^{d_a}$以及位置嵌入矩阵$P$和词嵌入矩阵$E$作为可学习参数。$d$是hidden_size,$d_p$是position embeddign dim,$d_a$为attention层的size。
句子的最终表示$z$按照下式计算,并且随后输入一个全连接层和一个softmax层,进行关系分类。
$$
Note that our model significantly differs from the attention mechanism in Bahdanau et al. (2015) and Zhou et al. (2016) in our use of the summary vector and position embeddings, and the way our attention weights are computed.
理解此模型最直观的方法是将attention的计算过程视为一个选择的过程,目的是从无意义的上下文中选择出有意义的上下文。
在这里,摘要向量summary vector($a$)帮助模型基于整个句子的语义信息(而不是仅基于每个单词)进行选择,而位置向量($P_i^s$,$P_i^o$)提供每个单词和实体之间的重要空间信息。
The TAC Relation Extraction Dataset(TACRED)
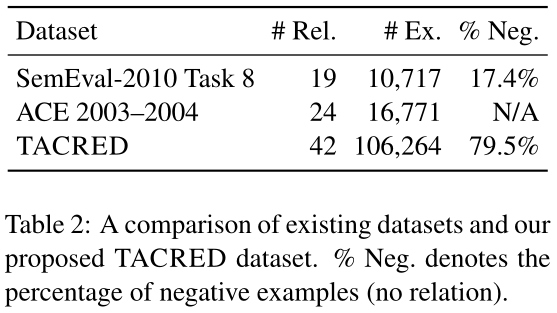
现有的关系抽取数据集,如SemEval-2010 Task 8数据集和自动内容抽取数据集(ACE)等,由于关系数据规模不足、涵盖的关系类型差异较大等原因,往往不能在槽填充任务中对抽取效果产生较大的改进。
为了解决此问题,本文针对TAC KBP评测中的关系类型,构建了一个大规模监督数据集TACRED。
本数据集主要基于近七年TAC KBP评测中的query实体和已标注的系统输出。该评测每年约100个query主实体,由参赛系统给出对应的关系和从实体,这些元素通过线上对源语料的众包标注后参与数据集的构建。
本数据集共收集了119,474个样本,并根据评测的年限划分为不同的子集(训练集、开发集、测试集),如下表所示,并且保留2015年的评测数据来作为槽填充任务的评测。
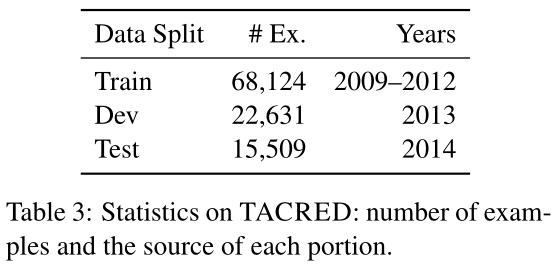
由下表可以看出,TACRED数据集显著增加了关系实例的规模(约一个数量级)。在标注的过程中对所有的负样本进行了标注,从而减小了使用本数据集训练的模型预测false positive的可能性。另外,TACRED数据集中的平均句长为36.2,而SemEval dataset仅为19.1,体现了真实文本中关系实体所处于的较为复杂上下文环境。
实验
- 基线模型
- 2015年度TAC KBP评测获胜系统(LR+Patterns):包含一个基于模式的抽取器和一个逻辑回归分类器
- 卷积神经网络(CNN):包含多个卷积操作、max-pooling层、全连接层和softmax层的一维CNN模型。作为拓展,将位置嵌入信息引入CNN(CNN-PE)作为对照
- 基于最短依存路径的LSTM(SDP-LSTM):每个最短依存路径被划分为由主实体和从实体到最低共同祖先节点的两个子路径,每个子路径输入LSTM,得到的每个词位上的隐层单元传入一个时间上的max-pooling层,形成该子路径的输出,两个子路径的输出组成最短依存路径的最终表示。同样,把无attention机制的LSTM模型作为对照.
Each sub-path is fed into an LSTM network, and the resulting hidden units at each word position are passed into a max-over-time pooling layer to form the output of this sub-path. Outputs from the two sub-paths are then concatenated to form the final representation.
- 在TACRED数据集上的评测结果
对每个模型在TACRED上通过随机初始化分别训练5轮,选择在开发集上取得居中$F_1$分数的轮次,记录其在测试集上的表现。结果如下表。
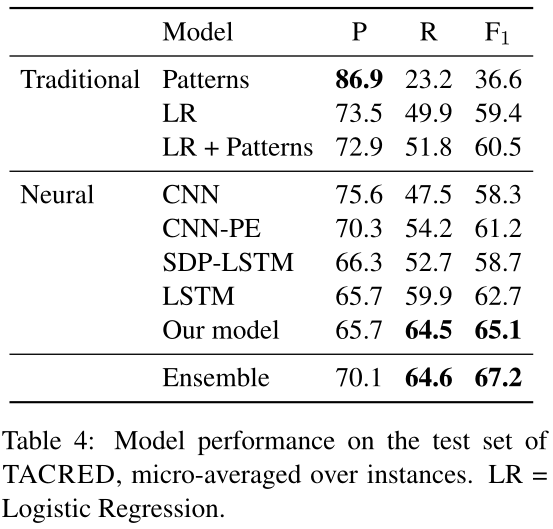
从上表可以发现,本文提出的position-aware机制将$F_1$分数显著提高到65.4%,相比于效果最好的基线模型LSTM提高了3.9%,而相对于逻辑回归(LR+patterns)系统提高了7.9%。
我们发现,不同的神经结构表现出不同的准确性和召回之间的平衡。基于CNN的模型往往具有更高的精度;基于RNN的模型有更好的召回率。这可以通过注意CNN中的过滤器本质上是一种“模糊n-gram模式”来解释。
Implementation Details
我们将在训练集中出现次数少于2次的单词映射为特殊<UNK>的token。我们使用预先训练好的GloVe向量(Pennington et al., 2014)来初始化词嵌入。对于所有的LSTM层,我们发现两层堆叠的LSTM通常比单层的LSTM工作得更好。我们使用AdaGrad使所有42种关系的交叉熵损失最小minimize cross-entropy(Duchi et al,2011)。我们将p = 0.5的Dropout应用于CNNs和LSTMs。在训练期间,我们还发现一个单词dropout策略非常有效:我们以概率p随机设置一个token为<unk>。对于SDP-LSTM模型,我们设p为0.06,其他所有模型设p为0.04。
Entity masking
我们用一个特殊的SUBJ-<NER>标记替换原来句子中的每个主语实体,其中<NER>是TACRED中提供的主语对应的NER类型。我们对object实体做同样的处理。此处理步骤有助于(1)提供具有实体类型信息的模型,以及(2)防止模型对特定实体的预测过度拟合。
Multi-channel augmentation 多通道增加
我们不再只使用词向量作为网络的输入,而是使用词性(POS)和命名实体识别(NER)嵌入来增加输入。我们运行Stanford CoreNLP (Manning et al., 2014)来获取POS和NER注释。
Model hyperparameters
We use 200 for word embedding size and 30 for every other embedding (i.e., position, POS or NER) size. For CNN models, we use filter window sizes ranging from 2 to 5, and 500 filters for each window size. For the SDP-LSTM model, in addition to POS and NER embeddings, we also include the type of dependency edges as an additional embedding channel. For our proposed position-aware neural sequence model, we use attention size of 200. For all models that require LSTM layers, we find a 2 layer stacked LSTMs works better than a single-
layer LSTM. We use one-directional LSTM layers in all of our experiments. Empirically we find bi-directional LSTM layers give no improvement to our proposed position-aware sequence model and marginal improvement to the simple LSTM model.We do not add max-pooling layers after LSTM layers as we find this harms the performance.
Training
During training, we employ standard dropout (Srivastava et al., 2014) for CNN models, and RNN dropout (Zaremba et al., 2014) for LSTM models. Additionally, for CNN models we apply ‘2regularization with coefficient $10^{−3}$to all filters to avoid overfitting. We use AdaGrad (Duchi et al., 2011) with a learning rate of 0.1 for CNN models and 1.0 for all other models. We train CNN models for 50 epochs and other models for 30 epochs, with a mini-batch size of 50. We monitor the training process by looking at the micro-averaged F1score on the dev set. Starting from the 20th epoch, we decrease the learning rate with a decay rate of 0.9 if the dev set micro-averaged F1 score does not increase after every epoch. Finally, we evaluate the model that achieves the best dev set F1score on the test set.
Analysis
- 模型分解 Model ablation
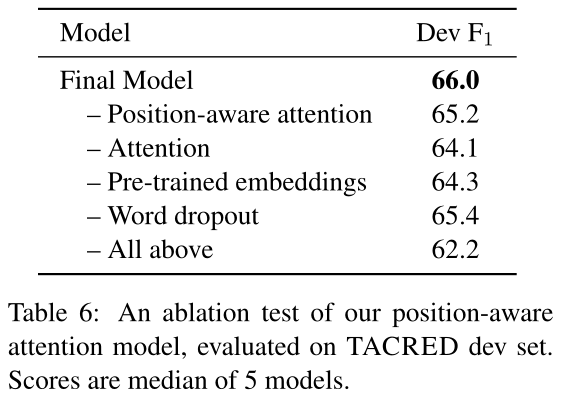
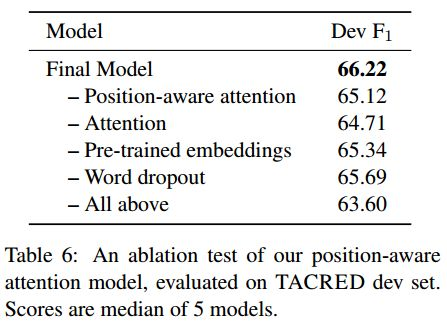
下表展示了position-aware模型在TACRED开发集上的分解测试结果。可以看出,整个attention机制贡献了约1.5/0.8%的$F_1$提升。(为什么一篇论文消融实验结果有两个表...)
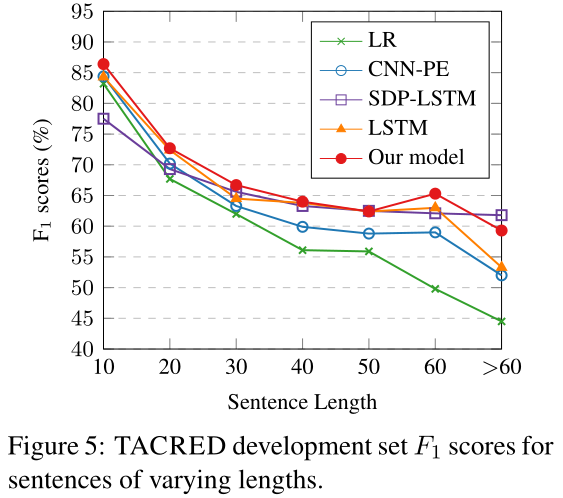
下图显示了不同句子长度下的性能。我们发现:(1)随着句子的变长,所有模型的性能都显著下降。(2)与基线Logistic回归模型相比,所有神经模型处理长句子的能力都较好。(3)与CNN-PE模型相比,基于rnn的模型对长句子具有更强的鲁棒性,而SDP-LSTM模型对句子长度最不敏感。(4)我们所提出的模型在所有长度的句子上都取得了相同或更好的结果,但在标记数超过60个的句子中,SDP-LSTM模型取得了最好的结果。
Attention visualization
下表中以不同深浅的颜色表示了本模型对开发集样本句中每个词分配的attention权值,可以看出,本模型会筛选出对关系更具指向性的单词,并且会着重关注从实体,因为从实体的实体类型对于关系的识别具有很强的指向性。

Conclusion
本文提出了一个用于关系抽取的认知位置的神经序列模型,以及一个大规模、多来源、显著提升关系实例数的数据集——TACRED。二者相结合,在冷启动槽填充评测中可以提升约4.5%的 $F_1$值。
参考:
阅读笔记:https://zhuanlan.zhihu.com/p/30828466
makedown大括号:https://blog.csdn.net/hhy_csdn/article/details/83722106


 浙公网安备 33010602011771号
浙公网安备 33010602011771号