【论文阅读】DocRED: A Large-Scale Document-Level Relation Extraction Dataset[ACL2019]
论文地址:https://arxiv.org/pdf/1906.06127v3.pdf
代码地址:https://github.com/thunlp/DocRED
DocRED竞赛地址:https://competitions.codalab.org/competitions/20717
为了避免歧义,笔者会将专有名词附上原文
1 背景及意义:
关系抽取以前重心只放在句内,忽略了句间关系抽取问题,文档级关系抽取需要整合文档中多个句子内部和跨多个句子的信息,并捕获语句实体之间的复杂交互。在文档中有效的整合相关信息仍然是一个具有挑战性的课题,作者2019年发表了非限定领域的文档级关系抽取数据集DocRED。
2 DocRED数据集的特点
为了加速对文档级RE的研究,我们引入了DocRED,一个由Wikipedia和Wikidata构建的新数据集,具有三个特点:
(1)DocRED同时标注命名实体和关系,是目前最大的纯文本文档级RE人工标注数据集;(截至2019年)
(2)DocRED要求阅读文档中的多个句子,通过综合文档的所有信息来提取实体并推断它们之间的关系;
(3) 除了人工标注的数据外,我们还提供了大规模的远程监督数据,这使得DocRED可以用于有监督和弱监督的场景。
为了验证文档级 RE的挑战。采用了最新的RE方法,并在DocRED上对这些方法进行了全面的评估。实证结果表明,DocRED对现有的RE方法具有挑战性,说明文档级RE仍然是一个开放的问题,需要进一步努力。

DocRED注释很规范。每个文档都用命名实体提及(named entity mentions)、共指信息(coreference information)、句内和句间关系(intra- and inter-sentence relations)以及支持证据(supporting evidence)加以注释。图中涉及到两种关系的命名实体提及使用蓝色表示,其他命名实体提及用下划线表示。另外请注意,第一关系实例中的Kungliga Hovkapellet 和 Royal Court Orchestra为同一主题提及。
文档级关系抽取多跳推理问题:

这个过程需要阅读和推理一个文档中的多个句子,这在直觉上是句子级RE方法所不能达到的。根据作者从维基百科文档中抽取的人类注释语料库的统计,至少有40.7%的关系事实只能从多个句子中提取出来,这一点不容忽视。
3 主要贡献
(1) DocRED包含132375个实体和56354个关系事实,在5053个Wikipedia文档上进行了注释,是最大的人工注释文档级RE数据集。
(2) 由于DocRED中至少40.7%的关系事实只能从多个句子中提取出来,DocRED要求阅读文档中的多个句子,通过综合文档中的所有信息来识别实体并推断它们之间的关系。这将DocRED与那些句子级的RE数据集区分开来。
(3) 作者还提供了大规模的远程监督数据来支持弱监督的再研究
数据集详细信息如下图所示:
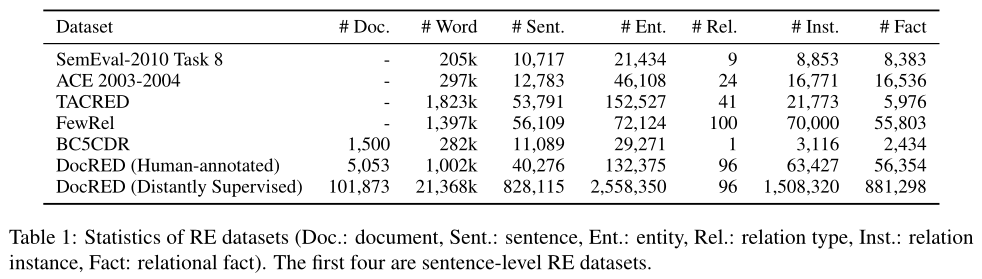
作者建立数据集的过程我就略过了,感兴趣的读者可以自己阅读论文Section 2。
推理类型(Reasoning Types):作者从dev和test集中随机抽取300个文档,其中包含3820个关系实例,并手动分析提取这些关系所需的推理类型。下图显示了数据集中主要推理类型的统计信息。
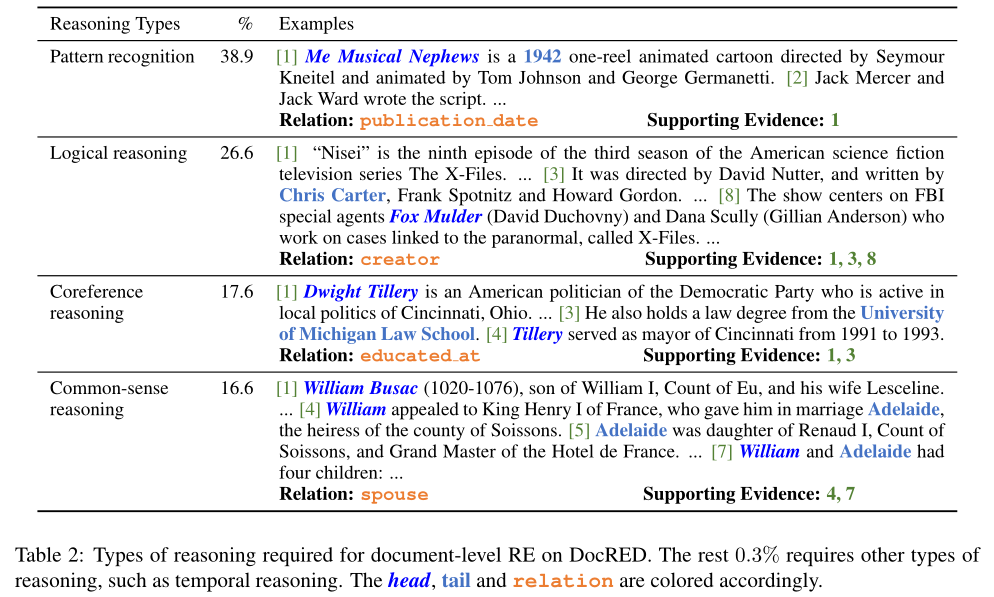
从推理类型的统计来看,我们有以下观察:
(1) 大多数关系实例(61.1%)需要进行推理识别,只有38.9%的关系实例可以通过简单的模式识别来提取,这表明推理对于文档级RE来说是必不可少的。
(2) 在具有推理的关系实例中,大多数(26.6%)需要逻辑推理,其中所讨论的两个实体之间的关系是由桥接实体间接建立的。逻辑推理要求RE系统能够对多个实体之间的交互进行建模。
(3) 相当数量的关系实例(17.6%)需要共指推理(coreference reasoning),其中必须首先执行共指解析(coreference resolution),以识别丰富上下文中的目标实体。
(4) 相似比例的关系实例(16.6%)必须基于常识推理进行识别,读者需要将文档中的关系事实与常识相结合来完成关系识别。总之,DocRED需要丰富的推理技巧来综合文档的所有信息。
句间关系实例(Inter-Sentence Relation Instances)
作者发现每个关系实例平均关联1.6个支持句(supporting sentence),其中46.4%的关系实例与多个支持句关联。此外,详细分析表明,40.7%的关系事实(relational facts)只能从多个句子中提取出来,说明DocRED是文档级RE的一个很好的基准。我们还可以得出结论:阅读、整合(synthesizing)和多个句子推理能力是文档级RE任务的关键。
4 Benchmark Settings 基准设置
我们分别为监督(Supervised Setting)和弱监督(Weakly Supervised Setting)场景设计了两个基准设置。两种设置均在高质量人工注释数据集上评估,这为文档级RE系统提供了更可靠的评估结果。
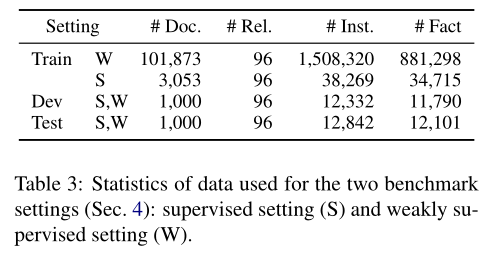
Supervised Setting
挑战1:文档级RE所需的丰富的推理技能。61.1%的关系实例依赖于复杂的推理技巧,而不是模式识别,这就要求RE系统不仅要在单个句子中识别简单的模式,而且要对文档中的全局性和复杂信息进行推理
挑战2:建模长文档的高计算成本和文档中大量的潜在实体对,相对于文档中的实体数(平均19.5个实体),时间复杂度$O(n^2)$。因此,使用二次或甚至更高计算复杂度的算法对上下文信息进行建模的RE系统对于文档级RE来说不够有效。因此,需要进一步提高上下文感知RE系统的效率,以适用于文档级RE。
Weakly Supervised Setting
基本设置与监督设置相同,只是训练集被远程监督数据替代。除了上述两个挑战外,伴随着远监督数据不可避免的错误标记问题也是弱监督环境下RE模型的一个主要挑战。之前有些学者也在研究句子级关系抽取噪声优化问题,但是文档级远程监控数据的噪声显著高于句子级的噪声。因此,我们相信在DocRED中提供远程监控数据将加速文档级远程监督RE方法的发展。此外,还可以联合利用远程监督数据和人工注释数据来进一步提高RE系统的性能。
5 Experiments
作者采用了四种模型基于CNN(Zeng et al., 2014)的模型、基于LSTM (Hochreiter and Schmidhuber, 1997)的模型、基于双向LSTM(BiLSTM)(Cai et al., 2016)的模型和上下文感知模型the Context-Aware model (Sorokin and Gurevych, 2017) 最初旨在利用上下文关系(contextual relations)来改善句内intra-sentence RE 。前三种模型仅在encoding the document的encoder部分不同
基于CNN/LSTM/BiLSTM的模型首先将包含n个单词的$D=\{w_i\}_{i=1}^n$ 文档编码成一个隐藏状态向量序列$\{h_i\}_{i=1}^n$,然后计算实体的表示,最后预测每个实体对的关系。每个单词其特征向量是GloVe word embedding,entity type embedding实体类型嵌入,coreference embedding共指嵌入的concatenation(最后一维度的拼接)。实体类型嵌入是通过使用嵌入矩阵将分配给单词的实体类型(例如PER、LOC、ORG)映射到向量来获得的。实体类型由人类为人类注释的数据指定,并通过微调的BERT模型为远程监督的数据指定实体类型。与同一实体相对应的命名实体(同一个实体对应的不同mention以第一个出现的mention的id作为基准)被赋予相同的实体id,这是由它在文档中第一次出现的顺序决定的。将实体id映射为向量作为共指嵌入。
对于每一个从第s个单词到第t个单词的命名实体提及,我们将其表示形式定义为$m_k=\frac {1}{t-s+1}\sum_{j=s}^t{h_j}$, 一个具有K个提及(mention)的实体的表示被计算为这些提及(mentions)的表示的平均值$e_i=\frac 1K\sum_k{m_k}$, 我们将关系预测视为一个多标签分类问题。特别是,对于每个实体对($e_i$,$e_j$ ),我们首先用相对距离嵌入连接(concatenate)实体表示,然后使用双线性函数计算每种关系类型的概率:
$$\hat{e_i}=[{e_i};E(d_ij)],\hat{e_j}=[{e_i};E(d_ji)]$$
$$P(r|{e_i},{e_j})=sigmoid(\hat{e_i}W_r\hat{e_j}+b_r)$$
$[;]$ denotes concatenation,$d_{ij}$和$d_{ji}$是文档中实体i实体j的第一个mention之间的相对距离,$E$是一个嵌入矩阵,$r$是一种关系类型,$W_r$,$b_r$是关系式可训练参数
AUC和F1 值作为评价指标,还计算了不包括训练集和开发/测试集重叠关系事实的分数,分别表示为Ign F1和Ign AUC
下图显示了在监督和弱监督设置下的实验结果,我们从中得到以下观察结果:
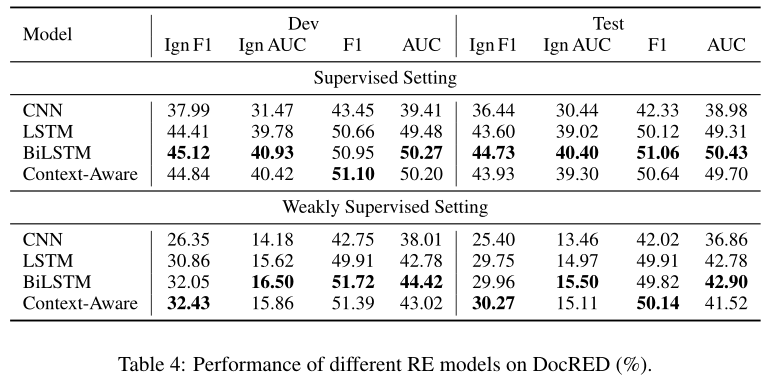
(1) 使用人类注释数据训练的模型通常比在远程监督数据上训练的模型性能要好。这是因为虽然远程监控可以很容易地获得大规模的远程监控数据,但错误的标记问题可能会损害RE系统的性能,这使得弱监督设置变得更加困难。
(2) 一个有趣的例外是,LSTM、BiLSTM和上下文感知在远程监控数据上进行了训练达到了与那些在人工标注数据集上训练相当的F1值,但在其他指标上的得分却明显较低,这表明训练集和开发/测试集之间的重叠实体对确实会导致评估偏差。因此,报告Ign F1和Ign AUC是必要的。
(3) 利用丰富的上下文信息的模型通常可以获得更好的性能。LSTM和BiLSTM的性能优于CNN,说明在文档级RE中对长依赖语义建模的有效性。Context-Aware上下文感知模型取得了竞争性的性能,但是,它不能明显优于其他神经模型。结果表明,在文档级RE中考虑多个关系的关联是有益的,而现有的模型不能很好地利用关系间的信息。
Performance v.s. Supporting Evidence Types
文档级RE需要综合来自多个支持语句的信息。为了研究从不同类型的支持证据中综合信息的难度,我们将开发集中的12332个关系实例分为三个不相交的子集:
(1) 6115个只有一个支持句的关系实例(定义为single);
(2)1062个具有多个支持句的关系实例和实体对在至少一个支持句中同时出现(定义为mix);
(3)4668个多个支持句的关系实例与实体对在任何支持中都不同时出现句子,这意味着它们只能从多个支持句中提取(定义为multiple)。
需要注意的是,当一个模型预测一个错误的关系时,我们不知道哪些句子被用作支持证据,因此预测的关系实例不能被归类到上述子集中,计算精度是不可行的。因此,我们只报告了每个子集的RE模型召回率,single召回率为51.1%,mix召回率为49.4%,multiple为46.6%。这表明,尽管mix中的多个支持句可以提供补充信息,但如何有效地综合丰富的全局信息是一个挑战。此外,在multiple中表现不佳表明RE模型在提取句间关系方面仍有困难。
Feature Ablations
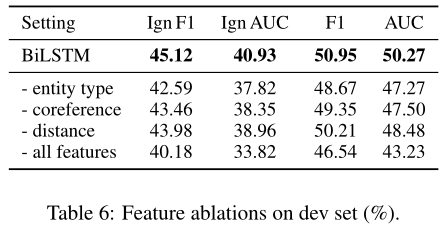
Supporting Evidence Prediction
我们提出了一个新的任务来预测关系实例的支持证据。一方面,联合预测证据提供了更好的解释性。另一方面,从文本中识别支持证据和推理关系事实(reasoning relational facts)是一项自然的双重任务,具有潜在的相互增强作用。我们设计了两种支持性证据预测方法:
(1) 启发式预测器(Heuristic predictor)。我们实现了一个简单的基于启发式的模型,将包含头或尾实体的所有句子作为支持证据。
(2) 神经预测器(Neural predictor)。我们还设计了一个神经支持的证据预测器。给定一个实体对和一个预测关系,句子首先通过单词嵌入和位置嵌入的串联(concatenation)转换成输入表示,然后输入到BiLSTM编码器中进行上下文表示(contextual representations)。受(Yang et al. 2018)的启发,我们将BiLSTM在第一个和最后一个位置的输出与可训练关系嵌入连接起来,以获得句子的表示,用于预测句子是否被用作给定关系实例的支持证据。
如下图所示,神经预测器在预测支持证据方面明显优于基于启发式的基线,这表明了RE模型在联合关系和支持证据预测方面的潜力。
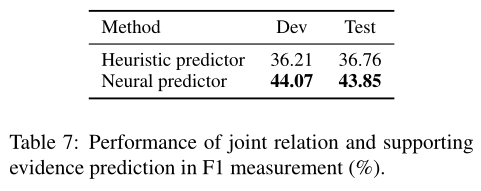
Discussion
从以上的实验结果和分析可以得出结论:文档级的RE比句子级的RE更具挑战性,要缩小RE模型的性能与人类的差距还需要更大的努力。我们认为以下研究方向值得遵循:
(1) 探索明确考虑推理的模型;
(2) 设计更具表现力的句子间信息收集与合成(synthesizing)模型体系结构;
(3) 利用远程监控数据提高文档级RE的性能
DocRED是由信息丰富的群体工作者构建的,不局限于任何特定领域,适合于通用文档级RE系统的培训和评估。
6 Conclusion
为了将RE系统从句子级提升到文档级,我们提出了一个大型文档级RE数据集DocRED,该数据集具有数据量、多个句子的阅读和推理需求,以及远程监控数据为弱监督文档级RE的开发提供了方便。实验表明,人的表现明显高于RE基线模型,这表明未来改进的机会很大。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号