Bidirectional 双向编码器
13.1.BERT公认的里程碑
-
BERT 的意义在于:从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
-
近年来优秀预训练语言模型的集大成者:
- 参考了 ELMO 模型的双向编码思想、
- 借鉴了 GPT 用 Transformer 作为特征提取器的思路、
- 采用了 word2vec 所使用的 CBOW 方法
-
BERT 和 GPT 之间的区别:
- GPT:GPT 使用 Transformer Decoder 作为特征提取器、具有良好的文本生成能力,然而当前词的语义只能由其前序词决定,并且在语义理解上不足
- BERT:使用了 Transformer Encoder 作为特征提取器,并使用了与其配套的掩码训练方法。虽然使用双向编码让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强
-
单向编码和双向编码的差异,以该句话举例 “今天天气很{},我们不得不取消户外运动”,分别从单向编码和双向编码的角度去考虑 {} 中应该填什么词:
- 单向编码:单向编码只会考虑 “今天天气很”,以人类的经验,大概率会从 “好”、“不错”、“差”、“糟糕” 这几个词中选择,这些词可以被划为截然不同的两类
- 双向编码:双向编码会同时考虑上下文的信息,即除了会考虑 “今天天气很” 这五个字,还会考虑 “我们不得不取消户外运动” 来帮助模型判断,则大概率会从 “差”、“糟糕” 这一类词中选择
13.2.BERT 的结构:强大的特征提取能力
- 如下图所示,我们来看看 ELMo、GPT 和 BERT 三者的区别

- ELMo 使用自左向右编码和自右向左编码的两个 LSTM 网络,分别以\(P(w_i|w_1, \cdots , w_{i - 1})\)和\(P(w_i|w_{i + 1}, \cdots , w_n)\)为目标函数独立训练,将训练得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码。
- GPT 使用 Transformer Decoder 作为 Transformer Block,以\(P(w_i|w_1, \cdots , w_{i - 1})\)为目标函数进行训练,用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码,是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务。
- BERT 也是一个标准的预训练语言模型,它以 \(P(w_i|w_1, \cdots , w_{i - 1}, w_{i + 1}, \cdots , w_n)\)为目标函数进行训练,BERT 使用的编码器属于双向编码器。
- BERT 和 ELMo 的区别在于使用 Transformer Block 作为特征提取器,加强了语义特征提取的能力;
- BERT 和 GPT 的区别在于使用 Transformer Encoder 作为 Transformer Block,并且将 GPT 的单向编码改成双向编码,也就是说 BERT 舍弃了文本生成能力,换来了更强的语义理解能力。
BERT 的模型结构如下图所示:
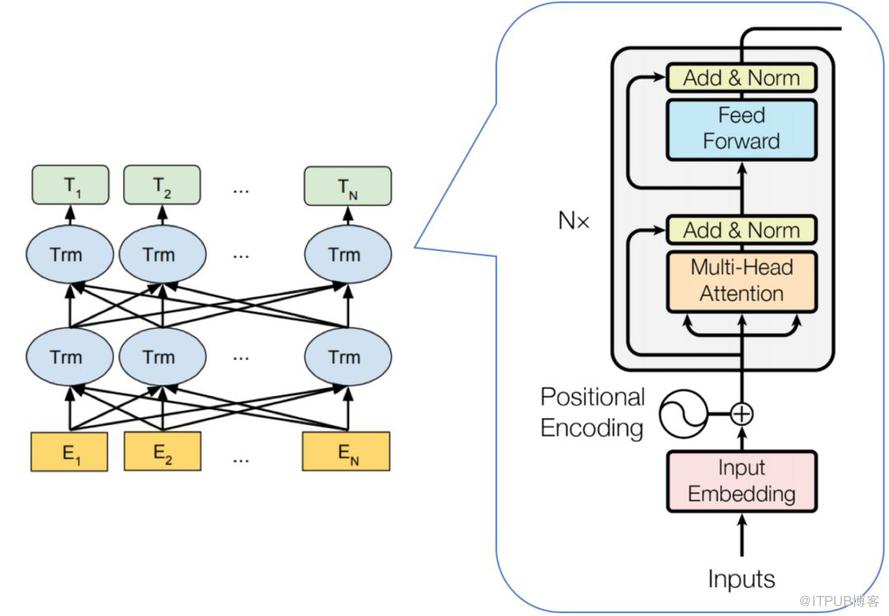
从上图可以发现,BERT 的模型结构其实就是 Transformer Encoder 模块的堆叠。在模型参数选择上,论文给出了两套大小不一致的模型。
\(BERT_{BASE}:\) L=12,H=768,A=12,总参数量为1.1亿(可在单GPU上运行)
\(BERT_{LARGE}:\) L=24,H=1024,A=16,总参数量为3.4亿(需要在TPU上运行)
其中 L 代表 Transformer Block 的层数;H 代表特征向量的维数(此处默认 Feed Forward 层中的中间隐层的维数为 4H);A 表示 Self-Attention 的头数,使用这三个参数基本可以定义 BERT的量级。
BERT 参数量级的计算公式:
-
- 两个全连接层
- \(FFN(X) = max(0,xW1+b1)W2+b2\)
- 惯用的全连接层大小设置\(4*hidden_{size}也即4*d_{model}\)
- 两个全连接层
-
- W1=W2=W3(d_{model},\(d_k=d_v=d_{model}/h\))
`- *3 - *block(12)
- W1=W2=W3(d_{model},\(d_k=d_v=d_{model}/h\))
-
- 有\(\gemma\)和\(\beta\)等两个参数
- 三个地方用到了LayerNorm层
- Embedding层后
- Multi-Head Attention后
- Feed-Forward后
\[\begin{align*}
&词向量参数+12∗(Multi-Heads参数+Feed-Forward参数+layernorm参数) \\
&=(30522+512+2)*768+768*2 \\
&+12*[(768*768/12*3*12+768*768)+(768*3072*2)+(768*2*2)] \\
&=108808704.0 \\
&≈110M
\end{align*}
\]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号