Let's reproduce GPT-2 (124M)
exploring the GPT-2 (124M) OpenAI checkpoint
pipeline
# https://www.bilibili.com/video/BV12s421u7sZ?spm_id_from=333.788.videopod.sections&vd_source=068bf9c06ddeefc09ffa32c255e98266
from transformers import GPT2LMHeadModel
model_hf = GPT2LMHeadModel.from_pretrained("gpt2") # 124M
sd_hf = model_hf.state_dict()
for k, v in sd_hf.items():
print(k, v.shape)
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
"""
[{'generated_text': "Hello, I'm a language model, but what I'm really doing is making a human-readable document. There are other languages, but those are"},
{'generated_text': "Hello, I'm a language model, not a syntax model. That's why I like it. I've done a lot of programming projects.\n"},
{'generated_text': "Hello, I'm a language model, and I'll do it in no time!\n\nOne of the things we learned from talking to my friend"},
{'generated_text': "Hello, I'm a language model, not a command line tool.\n\nIf my code is simple enough:\n\nif (use (string"},
{'generated_text': "Hello, I'm a language model, I've been using Language in all my work. Just a small example, let's see a simplified example."}]
"""
以下是对 GPT-2 模型的状态字典进行注释的解释:
transformer.wte.weight torch.Size([50257, 768])
# 词嵌入层的权重,表示从词汇表(50257个词)到隐藏层大小(768)的映射。
# 这是模型的输入嵌入部分,将输入的词汇ID映射为向量表示。
transformer.wpe.weight torch.Size([1024, 768])
# 位置嵌入的权重,表示不同位置(最多1024个位置)到隐藏层大小(768)的映射。
# 用于编码词序列中每个词的位置,帮助模型理解词序列中的顺序信息。
transformer.h.0.ln_1.weight torch.Size([768])
transformer.h.0.ln_1.bias torch.Size([768])
# 第一层 Transformer 中的第一个 LayerNorm(归一化)层的权重和偏置。
# 在每一层的输入上进行归一化,确保每个特征的均值为0,方差为1。
transformer.h.0.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.0.attn.c_attn.bias torch.Size([2304])
# 第一层自注意力机制的权重和偏置。
# 输入的维度为 768,输出的维度为 2304。注意力层包含了查询(Q)、键(K)、值(V)的投影矩阵。
# 2304(768 * 3)是为每个头的注意力计算而预留的维度。
transformer.h.0.attn.c_proj.weight torch.Size([768, 768])
transformer.h.0.attn.c_proj.bias torch.Size([768])
# 第一层自注意力机制中的输出投影权重和偏置。
# 负责将自注意力计算的结果映射回原始的 768 维空间。
transformer.h.0.ln_2.weight torch.Size([768])
transformer.h.0.ln_2.bias torch.Size([768])
# 第二层 LayerNorm,归一化来自自注意力层的输出,确保计算的稳定性。
transformer.h.0.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.0.mlp.c_fc.bias torch.Size([3072])
# 第一层 MLP(多层感知机)中的全连接层权重和偏置。
# 该层用于将输入的 768 维向量映射到更大的空间(3072维)。
transformer.h.0.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.0.mlp.c_proj.bias torch.Size([768])
# 第二层 MLP 的全连接层权重和偏置,将 3072 维的输出映射回原始的 768 维。
# 接下来的层(transformer.h.1 到 transformer.h.11)遵循相同的模式,每一层都包括以下几个部分:
# 1. LayerNorm:用于规范化每一层的输入。
# 2. 自注意力机制:包括 Q、K、V 投影和输出投影。
# 3. MLP:包含两层全连接层,用于生成最终的输出。
# 以下是 Transformer 层的参数注释(以 transformer.h.1 为例):
transformer.h.1.ln_1.weight torch.Size([768])
transformer.h.1.ln_1.bias torch.Size([768])
# 第二层的 LayerNorm 权重和偏置。
transformer.h.1.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.1.attn.c_attn.bias torch.Size([2304])
# 第二层的自注意力机制的投影矩阵和偏置。
transformer.h.1.attn.c_proj.weight torch.Size([768, 768])
transformer.h.1.attn.c_proj.bias torch.Size([768])
# 第二层自注意力机制的输出投影权重和偏置。
transformer.h.1.ln_2.weight torch.Size([768])
transformer.h.1.ln_2.bias torch.Size([768])
# 第二层的第二个 LayerNorm。
transformer.h.1.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.1.mlp.c_fc.bias torch.Size([3072])
# 第二层 MLP 的第一层全连接层。
transformer.h.1.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.1.mlp.c_proj.bias torch.Size([768])
# 第二层 MLP 的第二层全连接层。
# transformer.h.2 到 transformer.h.11 部分也是类似的,依次递增每一层的参数。
# 每层都包括:
# 1. LayerNorm:用于输入的规范化。
# 2. 自注意力机制的 Q、K、V 投影和输出投影。
# 3. MLP:两层全连接层,分别进行映射和输出。
transformer.ln_f.weight torch.Size([768])
transformer.ln_f.bias torch.Size([768])
# 最后一层的 LayerNorm,通常在所有 Transformer 层之后,处理最终输出。
lm_head.weight torch.Size([50257, 768])
# 输出层的权重,表示从 768 维的隐藏层到输出词汇表大小(50257个词)的映射。
# 这个层负责根据模型的隐藏状态生成最终的预测词。
总结:
GPT-2 模型的每一层都包含以下组成部分:
- LayerNorm:对输入进行归一化,确保训练稳定性。
- 自注意力机制(Attention):将输入的上下文信息结合起来,通过查询(Q)、键(K)和值(V)进行信息传递。
- MLP(多层感知机):用于在每一层中进行更复杂的非线性变换。
每一层的权重和偏置大小与模型的隐藏层大小和其他超参数(如词汇表大小、最大位置等)有关,确保输入的词向量和模型的表示能够传递并变换。
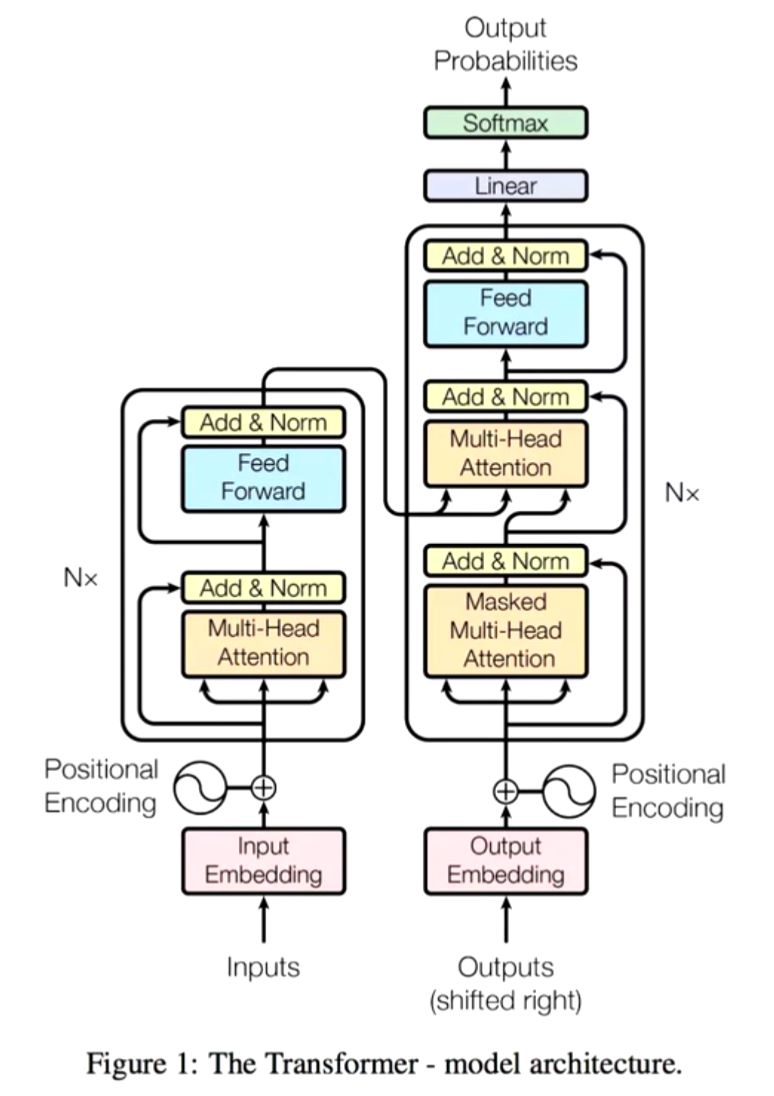
SECTION 1: implementing the GPT-2 nn.Module
device
# attempt to autodetect the device
device = "cpu"
if torch.cuda.is_available():
device = "cuda"
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = "mps"
print(f"using {device}")
import
import os
import math
import time
import inspect
from dataclasses import dataclass
import torch
import torch.nn as nn
from torch.nn import functional as F
from hellaswag import render_example, iterate_examples
CausalSelfAttention
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
self.c_proj.NANOGPT_SCALE_INIT = 1
# regularization
self.n_head = config.n_head
self.n_embd = config.n_embd
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
# nh is "number of heads", hs is "head size", and C (number of channels) = nh * hs
# e.g. in GPT-2 (124M), n_head=12, hs=64, so nh*hs=C=768 channels in the Transformer
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# attention(materializes the large (T, T) matrix for all the queries and keys)
# att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
# att = F.softmax(att, dim=-1)
# y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = F.scaled_dot_product_attention(q, k, v, is_causal=True) # flash attention 27%的改进
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.c_proj(y)
return y
MLP
class MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.gelu = nn.GELU(approximate='tanh')
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
self.c_proj.NANOGPT_SCALE_INIT = 1
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
return x
Block
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
GPT
@dataclass
class GPTConfig:
block_size: int = 1024 # max sequence length
vocab_size: int = 50257 # number of tokens: 50,000 BPE merges + 256 bytes tokens + 1 <|endoftext|> token
n_layer: int = 12 # number of layers
n_head: int = 12 # number of heads
n_embd: int = 768 # embedding dimension
class GPT(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# weight sharing scheme torch.size([50257, 768])
# 50257*768 = 38,597,376 -> 40/124 * 100% = 30% 即节约了30%的参数
self.transformer.wte.weight = self.lm_head.weight
# init params
# 如果遵循 Javier 初始化:标准差通常是1除以进入此层特征数量的平方根 0.02恰好范围
self.apply(self._init_weights)
# 残差growth问题:
"""
x = torch.zero(768)
n = 100 # eg. 100 layers
for i in range(100):
x += n**-0.5 * torch.randn(768)
原本每个参与残差累积的 x 的初始为 0, 方差为 1
残差流激活的方差增加,通过缩放因子把 x.std() 放到 1 附近
"""
def _init_weights(self, module):
if isinstance(module, nn.Linear):
std = 0.02
if hasattr(module, 'NANOGPT_SCALE_INIT'):
std *= (2 * self.config.n_layer) ** -0.5
torch.nn.init.normal_(module.weight, mean=0.0, std=std)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, targets=None):
# idx is of shape (B, T) (batch dimension of B, time dimension of T)
B, T = idx.size()
assert T <= self.config.block_size, f"Cannot forward sequence of length {T}, block size is only {self.config.block_size}"
# forward the token and posisition embeddings
pos = torch.arange(0, T, dtype=torch.long, device=idx.device) # shape (T)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (T, n_embd)
tok_emb = self.transformer.wte(idx) # token embeddings of shape (B, T, n_embd)
x = tok_emb + pos_emb
# forward the blocks of the transformer
for block in self.transformer.h:
x = block(x)
# forward the final layernorm and the classifier
x = self.transformer.ln_f(x)
logits = self.lm_head(x) # (B, T, vocab_size)
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
return logits, loss
@classmethod
def from_pretrained(cls, model_type):
"""Loads pretrained GPT-2 model weights from huggingface"""
assert model_type in {'gpt2', 'gpt2-medium', 'gpt2-large', 'gpt2-xl'}
from transformers import GPT2LMHeadModel
print("loading weights from pretrained gpt: %s" % model_type)
# n_layer, n_head and n_embd are determined from model_type
config_args = {
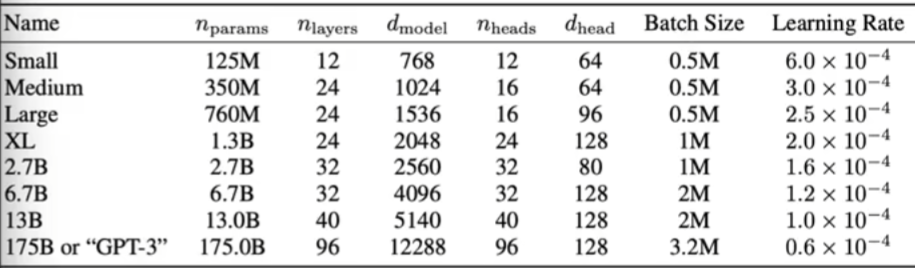
'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params
'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params
'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params
'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params
}[model_type]
config_args['vocab_size'] = 50257 # always 50257 for GPT model checkpoints
config_args['block_size'] = 1024 # always 1024 for GPT model checkpoints
# create a from-scratch initialized minGPT model
config = GPTConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith('.attn.bias')] # discard this mask / buffer, not a param
# init a huggingface/transformers model
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# copy while ensuring all of the parameters are aligned and match in names and shapes
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.masked_bias')] # ignore these, just a buffer
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.bias')] # same, just the mask (buffer)
transposed = ['attn.c_attn.weight', 'attn.c_proj.weight', 'mlp.c_fc.weight', 'mlp.c_proj.weight']
# basically the openai checkpoints use a "Conv1D" module, but we only want to use a vanilla Linear
# this means that we have to transpose these weights when we import them
assert len(sd_keys_hf) == len(sd_keys), f"mismatched keys: {len(sd_keys_hf)} != {len(sd_keys)}"
for k in sd_keys_hf:
if any(k.endswith(w) for w in transposed):
# special treatment for the Conv1D weights we need to transpose
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else:
# vanilla copy over the other parameters
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model
def configure_optimizers(self, weight_decay, learning_rate, device):
# start with all of the candidate parameters (that require grad)
param_dict = {pn: p for pn, p in self.named_parameters()}
param_dict = {pn: p for pn, p in param_dict.items() if p.requires_grad}
# create optim groups. Any parameters that is 2D will be weight decayed, otherwise no.
# i.e. all weight tensors in matmuls + embeddings decay, all biases and layernorms don't.
decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]
nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]
optim_groups = [
{'params': decay_params, 'weight_decay': weight_decay},
{'params': nodecay_params, 'weight_decay': 0.0}
]
num_decay_params = sum(p.numel() for p in decay_params)
num_nodecay_params = sum(p.numel() for p in nodecay_params)
print(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")
print(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")
# Create AdamW optimizer and use the fused version if it is available
fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parameters
use_fused = fused_available and "cuda" in device
print(f"using fused AdamW: {use_fused}")
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=(0.9, 0.95), eps=1e-8, fused=use_fused)
return optimizer
DataLoadLite
class DataLoaderLite:
def __init__(self, B, T):
self.B = B
self.T = T
# at init load tokens from disk and store them in memory
with open('input.txt', 'r') as f:
text = f.read()
enc = tiktoken.get_encoding('gpt2')
tokens = enc.encode(text)
self.tokens = torch.tensor(tokens)
print(f"loaded {len(self.tokens)} tokens")
print(f"1 epoch = {len(self.tokens) // (B * T)} batches")
# state
self.current_position = 0
def next_batch(self):
B, T = self.B, self.T
buf = self.tokens[self.current_position : self.current_position+B*T+1]
x = (buf[:-1]).view(B, T) # inputs
y = (buf[1:]).view(B, T) # targets
# advance the position in the tensor
self.current_position += B * T
# if loading the next batch would be out of bounds, advance to next shard
if self.current_position + (B * T * self.num_processes + 1) > len(self.tokens):
self.current_position = 0
return x, y
# tiny shakespeare dataset
# import sys; sys.exit(0)
!wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt
import tiktoken
enc = tiktoken.get_encoding('gpt2')
with open('input.txt', 'r') as f:
text = f.read()
text = text[:1000]
tokens = enc.encode(text)
B, T = 4, 32
buf = torch.tensor(tokens[:B*T + 1])
buf = buf.to('cuda')
x = buf[:-1].view(B, T)
y = buf[1:].view(B, T)
lr优化

lr
max_lr = 3e-4
min_lr = max_lr * 0.1
warmup_steps = 10
max_steps = 50
def get_lr(it):
# 1) linear warmup for warmup_iters steps
if it < warmup_steps:
return max_lr * (it + 1) / warmup_steps
# 2) if it > lr_decay_iters, return min learning rate
if it > max_steps:
return min_lr
# 3) in between, use cosine decay decay down to min learning rate
decay_ratio = (it - warmup_steps) / (max_steps - warmup_steps)
assert 0 <= decay_ratio <= 1
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) #coeff starts at 1 and goes to 0
return min_lr + coeff * (max_lr - min_lr)
train_loader = DataLoaderLite(B=4, T=32)
torch.set_float32_matmul_precision('high')
model = GPT(GPTConfig()).to('cuda')
model = torch.compile(model)
max_lr = 3e-4
min_lr = max_lr * 0.1
warmup_steps = 10
max_steps = 50
def get_lr(it):
# 1) linear warmup for warmup_iters steps
if it < warmup_steps:
return max_lr * (it + 1) / warmup_steps
# 2) if it > lr_decay_iters, return min learning rate
if it > max_steps:
return min_lr
# 3) in between, use cosine decay decay down to min learning rate
decay_ratio = (it - warmup_steps) / (max_steps - warmup_steps)
aassert 0 <= decay_ratio <= 1
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio)) #coeff starts at 1 and goes to 0
return min_lr + coeff * (max_lr - min_lr)
# optimizer!
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4, betas=(0.9, 0.95), eps=1e-8)
for i in range(50):
t0 = time.time()
optimizer.zero_grad()
# 混合精度
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
logits, loss = model(x, y)
loss.backward()
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
torch.cuda.synchronize() # wait for the GPU to finish work
t1 = time.time()
dt = (t1 - t0) # time difference in miliseconds
tokens_processed = train_loader.B * train_loader.T
tokens_per_sec = tokens_processed / dt
print(f"step {i:4d} | loss: {loss.item():.6f} | norm: {norm:.4f} | dt: {dt*1000:.2f}ms | tok/sec: {tokens_per_sec:.2f}")
model = GPT(GPTConfig())
model.eval()
model.to('cuda')
logits, loss = model(x)
model = GPT.from_pretrained('gpt2')
model.eval()
model.to('cuda')
num_return_sequences = 5
max_length = 30
# prefix tokens
import tiktoken
enc = tiktoken.get_encoding('gpt2')
tokens = enc.encode("Hello, I'm a language model,")
tokens = torch.tensor(tokens, dtype=torch.long) #(8,)
tokens = tokens.unsqueeze(0).repeat(num_return_sequences, 1) # (5, 8)
x = tokens.to('cuda')
# generate! right now x is (B. T) where B = 5, T = 8
# set the seed to 42
torch.manual_seed(42)
torch.cuda.manual_seed(42)
while x.size(1) < max_length:
# forward the model to get the logits
with torch.no_grad():
logits, _ = model(x) # (B, T, vocab_size)
logits = logits[:, -1, :] # (B, vocab_size)
# get the probabilities
probs = F.softmax(logits, dim=-1)
topk_probs, topk_indices = torch.topk(probs, 50, dim=-1)
ix = torch.multinomial(topk_probs, 1) # (B, 1)
xcol = torch.gather(topk_indices, -1, ix) # (B, 1)
# append to the sequence
x = torch.cat((x, xcol), dim=1)
# print the generated text
for i in range(num_return_sequences):
tokens = x[i,:max_length].tolist()
decoded = enc.decode(tokens)
print(">",decoded)
- 00:28:08 loading the huggingface/GPT-2 parameters
- 00:31:00 implementing the forward pass to get logits
- 00:33:31 sampling init, prefix tokens, tokenization
- 00:37:02 sampling loop
- 00:41:47 sample, auto-detect the device
- 00:45:50 let’s train: data batches (B,T) → logits (B,T,C)
- 00:52:53 cross entropy loss
- 00:56:42 optimization loop: overfit a single batch
- 01:02:00 data loader lite
- 01:06:14 parameter sharing wte and lm_head
- 01:13:47 model initialization: std 0.02, residual init (GPT class 里)
SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms
- 01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms
- 01:39:38 float16, gradient scalers, bfloat16, 300ms
- 01:48:15 torch.compile, Python overhead, kernel fusion, 130ms
- 02:00:18 flash attention, 96ms
- 02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms
梯度累计
示例
import torch
# super simple little MLP
net = torch.nn.Sequential(
torch.nn.Linear(16, 32),
torch.nn.GELU(),
torch.nn.Linear(32, 1),
)
torch.random.manual_seed(42)
x = torch.randn(4, 16)
y = torch.randn(4, 1)
net.zero_grad()
yhat = net(x)
loss = torch.nn.functional.mse_loss(yhat, y)
loss.backward()
print(net[0].weight.grad.view(-1)[:10])
# the loss objective here is (due to readuction='mean')
# L = 1/4 [
# (y[0] - yhat[0])**2 +
# (y[1] - yhat[1])**2 +
# (y[2] - yhat[2])**2 +
# (y[3] - yhat[3])**2
# ]
# NOTE: 1/4!
# tensor([-0.0838, -0.0392, 0.0034, 0.0486, -0.0005, 0.0181, -0.0319, -0.0595,
-0.0926, -0.0011])
# now let's do it with grad_accum_steps of 4, and B = 1
# the loss objective here is different because
# accumilation in gradient <---> SUM in loss
# i.e. we instead get:
# L0 = (y[0] - yhat[0])**2
# L1 = (y[1] - yhat[1])**2
# L2 = (y[2] - yhat[2])**2
# L3 = (y[3] - yhat[3])**2
# L = L0 + L1 + L2 + L3
# NOTE: the "normalizer" of 1/4 is lost
net.zero_grad()
for i in range(4):
yhat = net(x[i])
loss = torch.nn.functional.mse_loss(yhat, y[i])
loss = loss / 4 # <-- this is the "normalizer"!
loss.backward()
print(net[0].weight.grad.view(-1)[:10])
# tensor([-0.0838, -0.0392, 0.0034, 0.0486, -0.0005, 0.0181, -0.0319, -0.0595,
-0.0926, -0.0011])
# train_loader = DataLoaderLite(B=16, T=1024)
# 0.5e6 是批处理token的大小
# 0.5e6 / 1024 = 488.28125
# 但不能把B设成488,否则GPU会炸
total_batch_size = 524288 # 2**19, ~0.5M, in number of tokens
B = 16 # micro batch size
T = 1024 # sequence length
assert total_batch_size % (B * T) == 0, "make sure total_batch_size is divisible by B * T"
grad_accum_steps = total_batch_size // (B * T)
print(f"total desired batch size: {total_batch_size}")
print(f"=> calculated gradient accumulation steps: {grad_accum_steps}")
total_batch_size = 524288 # 2**19, ~0.5M, in number of tokens
B = 16 # micro batch size
T = 1024 # sequence length
assert total_batch_size % (B * T) == 0, "make sure total_batch_size is divisible by B * T"
grad_accum_steps = total_batch_size // (B * T)
print(f"total desired batch size: {total_batch_size}")
print(f"=> calculated gradient accumulation steps: {grad_accum_steps}")
train_loader = DataLoaderLite(B=B, T=T)
torch.set_float32_matmul_precision('high')
optimizer = model.configure_optimizers(weight_decay=0.1, learning_rate=6e-4, device=device)
for step in range(max_steps):
t0 = time.time()
optimizer.zero_grad()
loss_accum = 0.0
# 混合精度
for micro_step in range(grad_accum_steps):
x, y = train_loader.next_batch()
x, y = x.to(device), y.to(device)
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
logits, loss = model(x, y)
# we have to scale the loss to account for gradient accumulation,
# because the gradients just add on add on each successive bacward().
# addition of gradients corresponds to a SUM in the objective, but
# instead of a SUM we want MEAN. Scale the loss here so it comes out right
loss = loss / grad_accum_steps
loss_accum += loss.detach()
loss.backward()
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# determine and set the learning rate for this iteration
lr = get_lr(step)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
optimizer.step()
torch.cuda.synchronize() # wait for the GPU to finish work
t1 = time.time()
dt = (t1 - t0) # time difference in miliseconds
tokens_processed = train_loader.B * train_loader.T
tokens_per_sec = tokens_processed / dt
print(f"step {step:4d} | loss: {loss_accum.item():.6f} | lr: {lr:.8f} | norm: {norm:.4f} | dt: {dt*1000:.2f}ms | tok/sec: {tokens_per_sec:.2f}")


 浙公网安备 33010602011771号
浙公网安备 33010602011771号