
BUAA OO-Blogs Unit1
OO-Blogs Unit1
单元简介
这一单元通过迭代开发,实现了基本的表达式求导(包括\(sin\),\(cos\),乘方),并能检测格式的正确性。
HW1
要求
实现一个只包含+,-,*,^的求导计算器,保证输入合法。
思路和实现
程序执行过程分为三部分:解析->求导->输出
由于这一次作业的需求十分简单,故用Map储存,管理起来相当方便。
类图如下
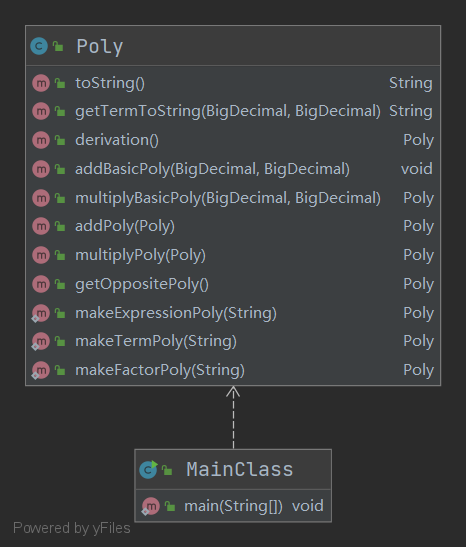
除了MainClass用于读入输出之外,只有一个Poly类。这个类提供了解析、加减乘导运算、和输出方法,所以有他足矣。然而,虽然可以支持这一次的作业,但是在引入新的函数时,就体现了其较差的扩展性。
复杂度分析如下
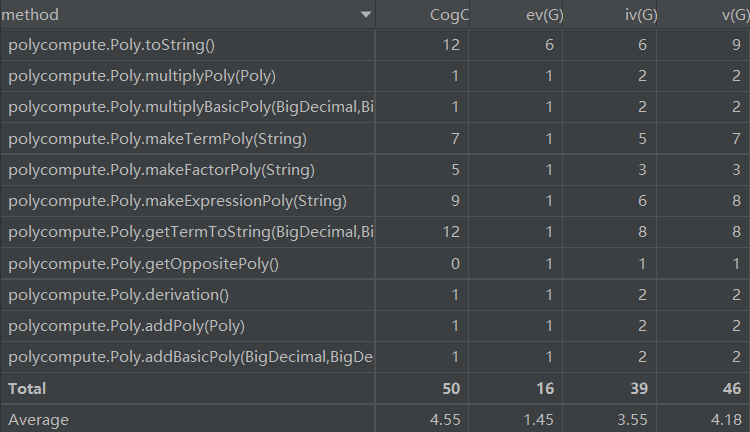
可以看到,两个toString方法的复杂度较高,这是因为优化过程中做了一些特判,导致if罗列,个人认为是难以避免的。
这一次作业的优化空间很小,在这样的储存方式下,我只做了正项提前和输出的一些优化,除了神奇的x**2 -> x*x之外,应该已经是最简了。
总之,这一次作业还是足够简单的,求导不是问题,Parse才是大头。
评测
用python写了个简单的评测机。利用xeger生成随机数据,然后将程序跑的结果和sympy对拍。大量随机数据的覆盖性还是不错的,在debug的过程中起到了不错的作用,虽然性能分没拿满,但也99+飘过。
纵然强测过了,但在互测环节还是出现了一些没想到的问题。对别人的代码,我采用黑盒测试,没有查出bug。
BUG
Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems.
虽然自己写了评测机评测,但万万没想到被正则表达式hack了。
hack的数据是499个x连乘,会导致我的regex匹配时爆栈。我用于匹配项的正则表达式是这样写的因子(\*因子)*,这里的*在贪婪(Greedy)模式下工作。java在匹配时会进行大量递归导致爆栈。因此,修复时,将*改为*+,这时为独占(Possessive)模式,特点是不回溯,解决了爆栈问题。
regex非常方便,在处理小数据、无嵌套结构时可以说是易如反掌。但在面对大数据时,如果想用它解决问题,那么一定要对运行过程有清楚的了解,以便对其作各种复杂度分析。
从这个bug也可以看到,边界压力测试是十分必要的。后面我也进行了较为充分的压力测试,不过后两次作业数据量都很小,因此也并没有显著的效果。
HW2
要求
在上一次作业的基础上,增加了因子\(sin(x), cos(x)\)及基本括号嵌套(不涉及函数内嵌套)。
思路和实现
程序执行过程分为五部分:解析->化简->求导->化简->输出
可以看到,线性储存很难对括号嵌套(除非全部展开,但这样做对函数内嵌套无法处理,扩展性差),因此,我推翻重构,采用树形储存,其中用到了继承与多态。
类图如下(不含依赖关系)
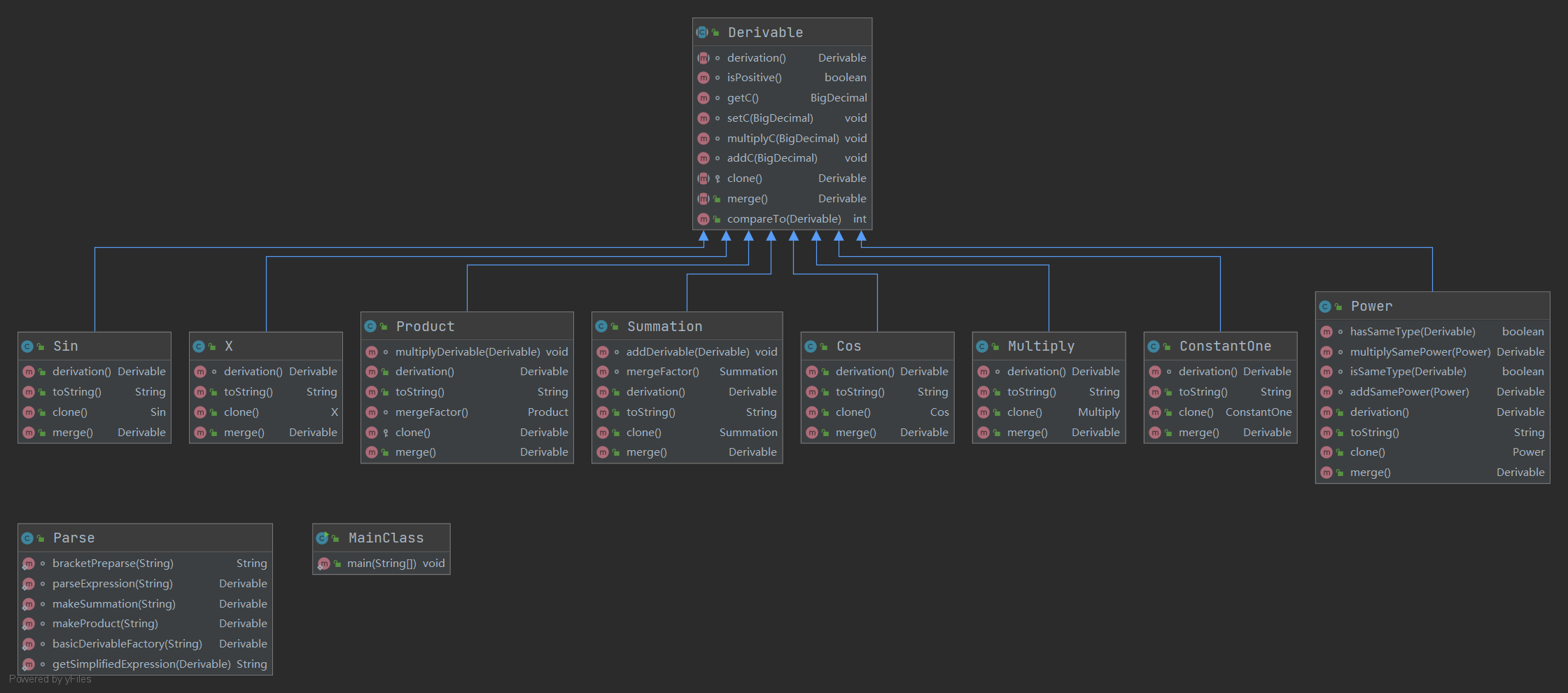
整体的思路还算清晰,将运算和函数都继承一个抽象类并实现求导、化简合并方法。并利用一个Parse类解析字符串,生成一个Derivable变量。
依赖关系如下
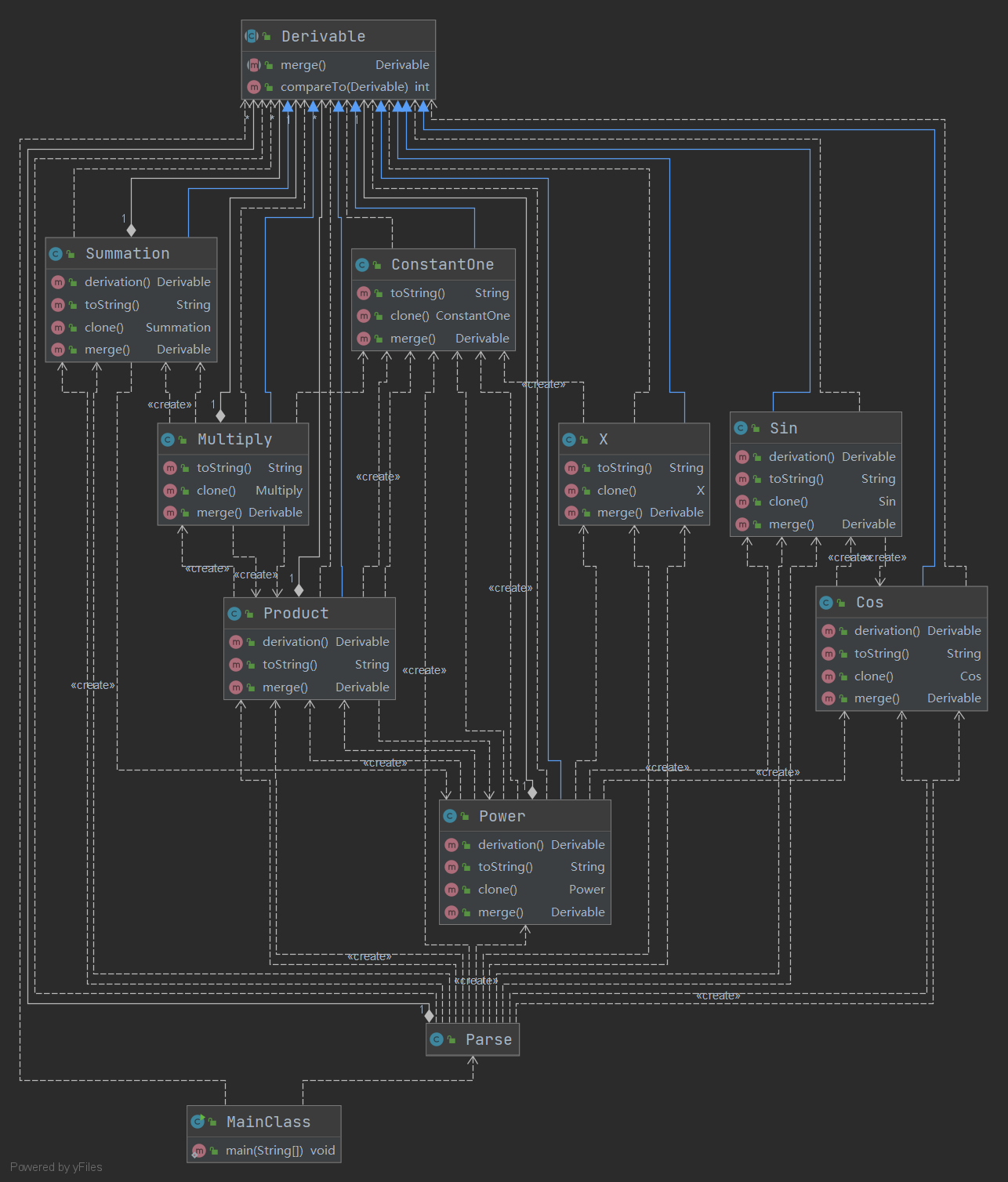
可以看到,依赖关系相比类图复杂许多,继承Derivable的各个类之间有复杂的依赖关系,这是在求导(sin->cos)或是化简(x**0->1)时直接new对象所导致的,增大了类间耦合度。当时设计的时候还没有注意到,现在看到类图,发现了工厂模式的好处,它可以使所有继承Derivable类只依赖于一个工厂模式,而不直接的将两个类产生依赖关系,即降低了耦合度,又使改变类的属性更加方便(只需要更改工厂)。
其实,在解析中(Parse类内)用到了一个工厂方法,但并没有用于其他类。看得出当时有这样的想法,但还是格局太小。
复杂度分析如下
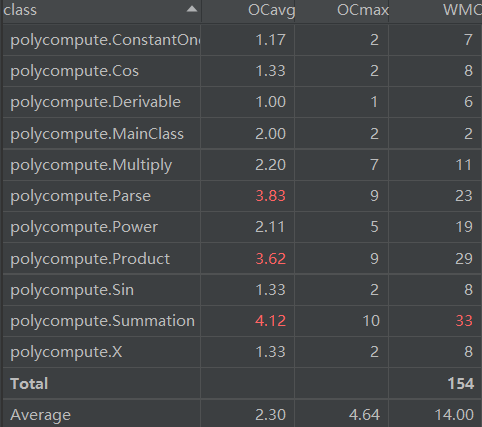
可以看到,有三个类的复杂度显著的比较高。其中Parse类是用来解析字符串,查看method metrics发现,其中很大的复杂度是由其中的一个工厂方法贡献的。另外两个连乘类和连加类的复杂度高,主要是在化简合并同类项时进行了一些嵌套循环导致的,如果要降低复杂度,或许将内层循环抽象出方法是可行的方案。
优化方面,由于每个Derivable子类都实现了一个化简合并方法,故只需要dfs的向下化简即可。实现中,我只进行了一些比较基本的化简操作,比如乘法链和加法链的合并,和一些诸如0项删除之类的细节优化罢了。
优化过程中有两点值得一提。一是由于无论是乘法链还是加法链中合并都不需考虑系数大小,我为Derivable类增加了一个系数属性,这确实为合并操作提供了一些方便。但实际操作中,在面向(自己的)评测机debug时,大量的bug都出现在了Derivable对象系数的维护上。在面向对象设计中,一个类应当只管理自己内部的功能,而用这种方法求导时,还要管理生成的对象的属性,这就造成耦合度过高,bug出现概率大增。因此,这不是一个好的设计,很有一点因小失大的感觉。后来仔细一想,用一些简单的办法即使不添加系数属性,也可以同样的完成化简的效果。
二是,注意到乘法链(线性储存)实现求导并不容易,而二元乘法树形储存又对化简不是很友好。因此,为了同时获得二者的优势,我在读入时用线性,即Product类存储。在对一个Product对象求导时,先将其转化为树形储存(利用二元乘法类Multiply),对树形储存的乘法链求导,最后化简时再把树拉成链即可。
此外,基于评测机的大量实验表明,在解析和求导之间增加化简步骤能起到相当显著的效果,原因显然,不再赘述。
评测
这次有了括号嵌套结构,直接基于xeger的数据生成已经不支持了。因此我的评测机根据设定的概率,递归的生成数据。
这一次强测和互测均没有测出bug,但由于我优化做的太少,而且貌似合并有一点小bug没有合并全,强测也只有99出头。
互测环节继续划水,hack无果。
HW3
要求
在上一次作业的基础上,增加了三角函数内括号嵌套,及Wrong Format检查。
思路和实现
有了上一次的结构,这一次基本无需大改就能实现。类图也只是比HW2多加了几条依赖关系,复杂度分布也几乎相同,就不重复展示了。
那么这里简单说一下之前一直没有提的解析和WF判定过程。
自从HW2增加了括号嵌套的机制,已经没法直接应用regex了,但这并不意味着一定要转向递归下降(虽然我承认那确实是一个很优雅的解决方案),仍然可以通过一些小trick将字符串转化为可以用它解决的形式。
嵌套结构之所以没法用regex解决,一个核心问题是无法匹配最外层括号,否则就可以匹配后递归的去处理。但注意到,匹配最内层括号对regex是简单的,只需要\([^\(\)]*\)就可以匹配出来。这样,我们就可以一直用这样的表达式匹配,匹配出所有括号对内的内容,用一个标记替换,并将匹配出的字符串存入数组中。这样处理结束之后,一对最外层括号和里面的内容就变成一个标记,regex可以轻松处理。
WF判定通过抛出异常来实现。主要有三个点位,一个是括号预处理后检查是否有未匹配的括号,二是括号预处理后直接用正则表达式检查是否合规,三是检查指数是否超过50。一旦检测到错误直接抛出异常,在最外层捕获输出即可。
评测
评测机数据生成部分只增加了\(sin\),\(cos\)内嵌套因子,有了上次的基础不难实现。
此外,这次由于格式有较多坑点,输出的化简过程相当琐碎,因此我认为进行输出结果的格式检查是必要的,但又不想用python再写一个格式检查。因此我将目标程序得到的结果再输给目标程序判断是否WF。实际上,这也部分检查了原代码WF格式判断(确实不够充分,但总比没有强)。
在自己的评测中,发现修复完上次合并化简的小bug效果还是不错的,在评测机生成的比较普通的随机数据下,长度基本不长于sympy得到的结果。
最后在强测和互测中也未查出bug,得分99.5+在这样简单的优化下已经是不错的结果了。
总结
关于互测
三次互测房均采用了黑盒测试,用评测机大量数据测试,一无所获。然而,除了第一次别人用边界数据hack掉了几个人之外,我测试过的人都没有被hack,所以也很难讲到底是我的评测机还不够强,还是大家写的代码都太稳了?(希望是后者:P)
至于为什么没有读别人的代码,因为写的难看的读不下去,写的好看的也几乎没什么问题,而且效率上看远不如评测机,所以几乎没有用这种费力不讨好的办法。但诚然,这就少了一些学习别人代码的机会,也算有得有失。
关于优化
这三次作业我的性能分都不曾拿满,但也不曾低于99。我知道进一步优化方向,简单的比如尝试展开合并,复杂的再做一些三角优化。但有两点值得考量,第一点很显然,优化部分的复杂性通常很高,优化的越多出bug的概率就越大。第二是投入和产出的关系,也就是俗称的性价比。当然这里的产出不止指性能分了,做出结果的成就感等也应考虑在内。总之,这是一个trade-off的过程,做出任何一种选择都有其优劣所在,我也并不后悔我的选择。
心得
第一次用看起来像面向对象的思想设计程序,确实能体会到这种设计思路的优点。在使用某个类的元素时不需要考虑其内部实现,只要调用其方法即可,降低了编程时所需的思维深度。Java提供的继承多态等特性也为编程提供了极大方便。但就像前面写的那样,这次的设计还不够OO,导致一些bug出现,或许下次作业可以作出更好的设计。
编程过程中,我感觉我对扩展性的理解和实践都还不够充分。我仍然更多的试图在动手前一次性想清楚一切细节,一次成型;相比之下,却没有为增强扩展性做足够的努力。当然不是说不应该在动手前尽可能全面的考虑,只是说在实际情况下需求不会一次性完全的给出,所以这样的考虑总是不充分的,应当将更多的关注聚焦在扩展性上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号