人脸识别技术原理与工程实践
1人脸识别应用场景(验证)

我们先来看看人脸识别的几个应用。第一个是苹果的FACE ID,自从苹果推出FaceID后,业界对人脸识别的应用好像信心大增,各种人脸识别的应用从此开始“野蛮生长”。
事实上,人脸识别技术在很多场景的应用确实可以提升认证效率,同时提升用户体验。前两年,很多机场安检都开始用上了人脸验证;今年4月,很多一、二线城市的火车站也开通了“刷脸进站”的功能;北京的一些酒店开始使用人脸识别技术来做身份验证。
2 人脸识别应用场景(识别)
我们再来看看几个场景。

第一个是刷脸的自动售货机。当我第一次看到这个机器的时候就有个疑问:”现在人脸识别算法已经做到万无一失了吗,认错人,扣错钱怎么办?”,后来才发现,其实关键不在于算法,产品设计才是最重要的。用过这个售货机的人可能知道,第一次使用的时候,要求输入手机号的后四位,这个看似简单的产品设计,可以让自动售货机的误识别率降低到亿分之一,这样底概率的条件下,误识别带来的损失完全可以忽略。同时这款自动售货机还会提醒你,你的消费行为会绑定“芝麻信用”,想想有几个人会为了一瓶“可乐”去影响自己的征信记录呢?
第二个是刷脸买咖啡,进入咖啡店后,在你选好喝什么咖啡前,系统已经识别出站在点单台前的用户是谁,并做好点单准备;
第三个是在人脸门禁系统。小伙伴们再已不用担心忘记带工卡了。人脸门禁对识别速度和准确度的要求是相对较高的,设备挂在门的侧面墙也会影响体验,增加产品设计和开发的难度。
3 “人脸验证”还是“人脸识别”?
其实,前面两页的场景是有些区别的,不知道大家看出来了没有。

第一个的场景,用户实际提供了两个信息,一是用户的证件信息,比如身份证号码,或APP账号;另一个信息是用户的现场照片;这类场景的目标实际上是:让人脸识别系统验证现场照片是否是证件所宣称的那个人。我们把这类场景叫着“人脸验证”。
第二个的场景,用户实际只提供的现场照片,需要人脸识别系统判断照片上的人是谁。我们把这类场景叫着“人脸识别”。
“人脸验证”拿现场人脸跟用户所宣称的人脸做1比1的比较,而“人脸识别”是拿现场人脸跟后台注册人脸库中的所有人脸比较,是1比N的搜索。可以看出,两种场景的技术原理一致,但是难度不同,第二页场景的难度普遍比第一页高得多。
4 人脸识别原理
计算机是怎么识别人脸的呢?如果我们大家是人脸识别系统的设计者,我们应用怎样来设计这个系统?
“把人脸区域从图片中抠出来,然后拿抠出来的人脸跟事先注册的人脸进行比较”,没错,就是这样,说起来简单,做又是另外一回事了,这里又有两个新的问题:
一是,“怎样判断图片中是有没有人脸?”,“怎样知道人脸在图片中的具体位置呢”,这是人脸检测要解决的问题,人脸检测告诉我们图像中是否有人脸以及人脸的具体位置坐标。
二是,“我们怎样比较两个人脸是不是同一个人呢?”,一个像素一个像素比较吗?光照,表情不一致,人脸偏转都将导致该方法不可行。”人是怎样判断两种照片中的人脸是不是同一个人的呢?”,我们是不是通过比较两种照片上的人,是不是高鼻梁、大眼睛、瓜子脸这样的面部特征来做判断的呢?

我们来看一下计算机人脸识别的流程,首先是获取输入图像,然后检测图像中是否有人脸,人脸的具体位置,然后判断图像的质量,比如图像是否模糊,光照度是否足够,然后检测人脸偏转的角度,旋转人脸到一个正脸位置,再然后提取人脸特征,比对人脸特征,最后输出识别结果。其中图像质量检测和人脸对齐这两步是可选的步骤,根据具体应用场景来决定。
5 人脸检测-经典方法
我们来看看经典的人脸检测方法。

OpenCV和Dlib是两个常用的算法库。
OpenCV 中使用Haar Cascade来做人脸检测,其实Haar Cascade可以检测任何对象,比如人脸和脸上眼睛的位置。
DLIB中是使用方向梯度直方图(Histogram of Oriented Gradient, HOG),即通过计算图像局部区域的梯度方向直方图来提取特征,这种方法的本质在于梯度的统计信息,而梯度主要存在于边缘的地方。
OpenCV和DLIB各自也有他们自己的基于深度学习的人脸检测方法,使用起来非常简单。从这几种方法都可以做到CPU实时或GPU实时;经典的检测方法对正脸的检测效果比较好,深度学习的方法适应性更强,可以检测各种角度的人脸。
6 MTCNN人脸检测
2016年提出来的MTCNN算法是目前公认比较好的人脸检测算法是(Multi-task Cascaded Convolutional Networks),可以同时实现face detection和alignment,也就是人脸检测和对齐。
这里的对齐指的是检测人脸眼睛、鼻子、嘴巴轮廓关键点LandMark。

MTCNN算法主要包含三个子网络:P-Net (Proposal Network)、 R-Net(Refine Network)、O-Net(Output Network),这3个网络按照由粗到细的方式处理输入照片,每个网络有3条支路用来分别做人脸分类、人脸框的回归和人脸关键点定位。
左上角,最开始对在多个尺度上对图像做了resize,构成了图像金字塔,然后这些不同尺度的图像作为P、P、O网络的输入进行训练,目的是为了可以检测不同尺度的人脸。
P-Net主要用来生成候选人脸框。 R-Net主要用来去除大量的非人脸框。O-Net和R-Net有点像,在R-NET基础上增加了landmark位置的回归,最终输出包含一个或多个人脸框的位置信息和关键点信息。
7 人脸特征提取-经典方法
接下来,我们来看一下人脸特征提取。经典的人脸特征提取方法有EigenFace和FisherFace两种。
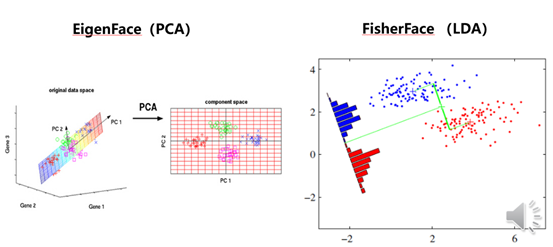
EigenFace的思想是把人脸从像素空间变换到另一个空间,在另一个空间中做相似性的计算。EigenFace的空间变换方法是主成分分析PCA。这个方法90年代开始应用于人脸识别,因为主成分有人脸的形状,所以也称为“特征脸”。
FisherFace是一种基于线性判别分析LDA(全称Linear Discriminant Analysis,)的人脸特征提取算法, LDA和PCA都是利用特征值排序找到主元的过程。LDA强调的是不同人脸的差异而不是照明条件、人脸表情和方向的变化。所以,Fisherface对人脸光照、人脸姿态变化的影响更不敏感。
8 人脸特征提取-深度学习法
我们再来看看深度学习法。

利用神经网络学习高度抽象的人脸特征,然后将特征表示为特征向量,通过比较特征向量之间的欧式距离来判定两张照片是否是同一个人。
9人脸特征提取-深度学习法
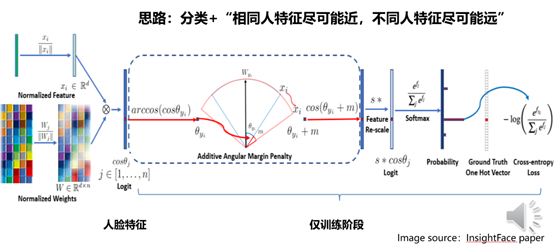
总体思路是把人脸识别人物当分类任务来训练,通过在损失函数上施加约束,让相同的人的照片提取的特征距离尽可能近,不是同一个人的照片的提取的特征距离尽可能的远。
第一个Logit的地方输出的是人脸的特征向量,一般是128维或者512维,浮点向量。这个Logit前面是CNN分类网络,这个Logit后面的部分是通过在损失函数上施加约束来训练模型,让模型区分相同的人和不同的人,后面的部分只需要在训练阶段计算,推理阶段是不需要的。
10 人脸特征提取-Metric Learning
基于深度学习的人脸特征提取方法主要有两类,一类Metric Learning,另一个是Additive Margin,这两类方法的底层原理都是一样的,就是“通过训练网络,让相同人的特征距离尽可能近,不同人的特征距离尽可能的远”。
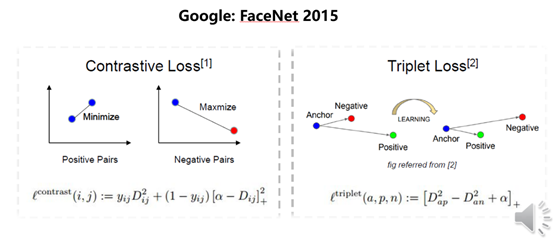
孪生网络和Triplet都属于 Metric Learning这类方法。左边孪生网络顾名思义,就是有两个网络,一个网络训练让相同的人之间的距离尽可能的近,另一个网络让不同人之间的距离尽可能远。
右边Triplet网络是对孪生网络的改进,将样本组织为锚点、正样本、负样本的元组,通过训练网络让锚点与正样本之间的距离尽可能的近,锚点与负样本之间的距离尽可能的远,并且至少远于一个阀值阿尔法。
11 人脸特征提取-Additive Margin
Additive Margin这类方法主要是在分类模型的基础,通过控制损失函数来达到“让相同人的特征距离尽可能近,让不同人的特征距离尽可能远”的目标。
前面介绍的Metric Learning的方法最大的问题在于:需要重新组织样本,模型最终能否收敛很大程度上取决于采样是不是合理。基于Additive Margin的方法则不需要这一步,完全将人脸特征提取当做分类任务来训练,参数的设置也不需要太多trick,Additive Margin的方法大都是在损失函数上做文章。
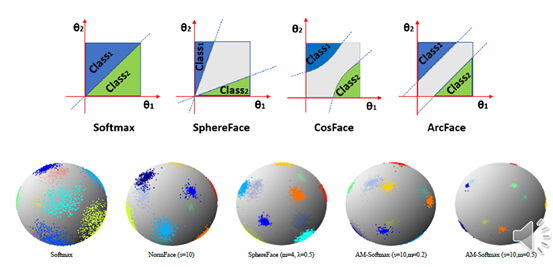
最近几年,这个类方法研究的比较多,上面这个图中的softmax,Sphereface,Cosface,ArcFace都是Additive Margin方法,可以看出它都是通过改进损失函数,来实现“让相同人的特征距离尽可能近,让不同人的特征距离尽可能远”这个目标。
上面这个图中,颜色相同的点表示一个人,不同的点表示不同的人,这个图的展示比较形象,可以看出最后一个超球体的效果非常不错。
Additive Margin正在成为主流, InsightFace也属于这一类,损失函数正是这个ArcFace。
大家可用思考一下,为什么分类方法不能直接用于人脸识别?这里不做详细讨论了。
12 人脸特征提取-效果评估
我们再来看一下怎样评估人脸特征提取算法的效果。

主要是通过召回率和虚警率两个指标来衡量。应用场景不同,这个两个指标的设置也不同,一般情况下,在实践中我们都要求在虚警率小于某个值(比如万分之一)的条件下,召回率达到某个值(比如99%)。很多产品宣称的识别准确率达到多少多少,很大可能是在公开数据集比如LFW上的测试结果。
公开的训练数据集比较推荐的有:MS1MV2,这个数据集微软前段事件已经宣布撤回不再提供下载,这个数据集大概有85000个不同的人的380万张照片。另一个数据集是GLINT_ASIA,有9万多人的280万张照片。
13 工程实践的挑战及经验分享
很多人都认为人脸识别应用,算法包打天下,事实并非如此,即使是最好的识别算法也扛不住像图像质量差。图像质量差、姿势变化、面部形状/纹理随着时间推移的变化、遮挡这些问题,是我们在工程实践中面临的挑战。
当然,大多数问题工程上我们有应对方法。比如图像模糊,光照不足,我们可以先检测图像是否模糊,关照是否不足,质量不过关,就不把图像送给识别算法。
再比如,用他人照片或视频来欺骗人脸识别系统,目前已经有多种活体检测方法来检测并防止这种情况。

经过一段时间在人脸识别领域的摸爬滚打,个人认为影响用户体验的关键因素是识别快、识别准,识别快主要靠产品设计,识别准主要靠算法。
拿人脸门禁来举个例子,产品设计上可以在前端采集照片的时候过滤掉模糊、无人脸的照片,避免无效识别,同时前端在采集照片的时候,可以同时采集多张并发传给后台,做并发识别,这些方法都可以大大提升识别通过的速度,提升用户体验。
本文来自博客园,作者:木子欢儿,转载请注明原文链接:https://www.cnblogs.com/HGNET/p/11938904.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号