【Python】解析Python中的迭代器
目录结构:
在开始文章之前,先贴上一张Iterable、Iterator与Generator之间的关系图: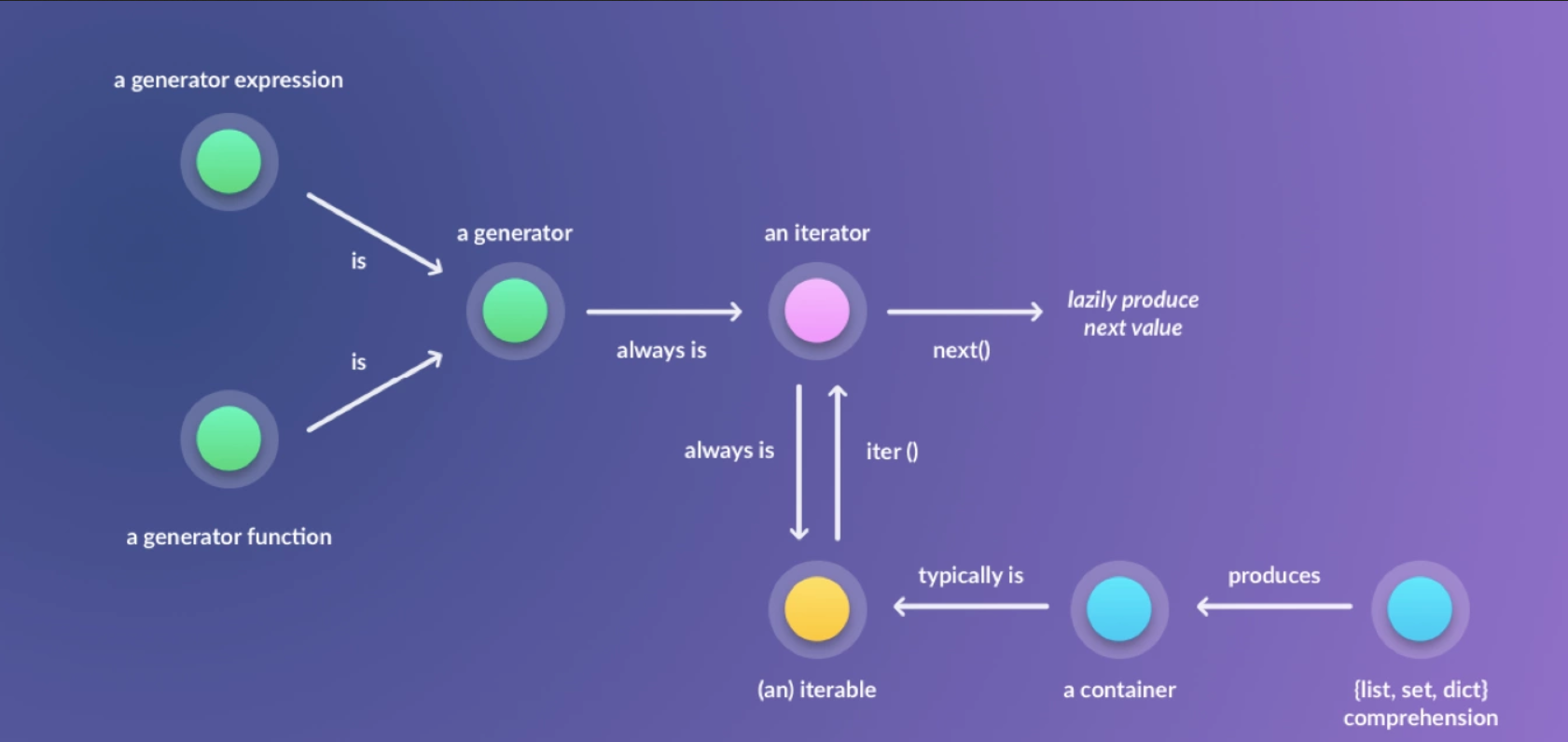
1. Iterator VS Iterable
迭代器(Iterator)
迭代器是实现了迭代器协议的类对象,迭代器协议规定了迭代器类必需定义__next()__方法。当对迭代器对象调用next()方法时,对象会去调用__next()__计算迭代器的返回值。
可迭代对象(Iterable)
可迭代对象可以是任何对象,不一定是能返回迭代器的数据结构。一个可迭代对象会直接或间接性的调用这两个方法__iter()__和__next()__;其中__iter()__方法只能返回迭代器对象,__next()__则供给迭代器进行调用。
通常情况下,可迭代类都会实现__iter()__和__next()__,并且__iter()__返回它自己,换句话说,该类即是迭代器又是可迭代类。
下面的代码展示了迭代器和可迭代器对象之间的差别:
a_set = {1, 2, 3}#定义set数据类型,set是可迭代类型
b_iterator = iter(a_set)#得到set的迭代器
#Output: 1
print(next(b_iterator))
#Output: <class 'set'>
print(type(a_set))
#Output: <class 'set_iterator'>
print(type(b_iterator))
从结果可以看出a_set是一个可迭代类型(set类型),b_iterator是一个迭代器(set_iterator),它们两个是完全不一同的类型。
下面的自定义了一个迭代器:
class Series(object): def __init__(self, low, high): self.current = low self.high = high def __iter__(self): return self def __next__(self): if self.current > self.high: raise StopIteration else: self.current += 1 return self.current - 1 n_list = Series(1,10) print(list(n_list))
从上面的代码可以看出,__iter__返回了迭代器本身。__next__返回迭代器的下一个值,如果没有下一个返回值那么会抛出StopIteration异常。如果没有在合适的位置抛出StopIteration异常结束迭代,那么在某些循环语句中(例如:for loop),将会形成死循环,所以在__next__中必需要在合适位置添加退出语句(抛出StopIterator异常)。
2.Itertools 模块
Itertools是Python的内置模块,其中包含了能够创建迭代器的函数。简而言之,它提供了许多能够与迭代器交互的方法。
下面是我们使用Itertools模块中count函数的案例:
from itertools import count sequence = count(start=0, step=1) while(next(sequence) <= 10): print(next(sequence),end=" ")
输出:
1 3 5 7 9 11
Itertools中的cycle函数可以创建无限迭代器,例如:
from itertools import cycle dessert = cycle(['Icecream','Cake']) count = 0 while(count != 4): print('Q. What do we have for dessert? A: ' + next(dessert)) count+=1
输出:
Q. What do we have for dessert? A: Icecream
Q. What do we have for dessert? A: Cake
Q. What do we have for dessert? A: Icecream
Q. What do we have for dessert? A: Cake
关于更多itertools模块的使用,可以参见python文档。
3.生成器(Generator)
生成器可以说是迭代器的亲兄弟,生成器允许我们像上面那样写迭代器而不用额外定义__iter__()和__next__()方法。
看下面的案例:
def series_generator(low, high): while low <= high: yield low low += 1 n_list = [] for num in series_generator(1,10): n_list.append(num) print(n_list)
如果一个方法中出现了yield关键字,那么该方法就是一个生成器。生成器中没有return语句,函数的返回值实际上是一个generator。当循环开始执行到yield语句后,low的值会被扩展到要返回的generator中。当下一次循环再次到达yield语句时,generator会从上一次停止的地方恢复执行,并且将最新的low值添加到generator中。这样一种循环,直到low>high退出循环。
生成器支持延迟计算,只有当去取生成器中的值时才会执行生成器的函数体。
例如:
def test(): print("进入test函数") for i in range(2): print("yield number ",i) yield i if "__main__" == __name__: print("开始调用test") res = test() print("结束调用test") next(res) next(res)
输出:
开始调用test
结束调用test
第一次next(res)
进入test函数
yield number 0
第二次next(res)
yield number 1
从结果可以看出,只有使用next调用迭代器时(使用for,while循环也可以),才会去执行生成器函数中的内容。
python中生成器可以分为生成器函数和生成器表达式,这两种类型的表现形式完全不同。
生成器函数是一个函数体中有yield关键字的,我们上面定义的test就是生成器函数。
生成器表达式的使用比较受限制,一个生成器表达式返回一个生成器。下面是一个使用生成器表达式的案例:
squares = (x * x for x in range(1,10)) print(type(squares)) print(list(squares))
输出:
<class 'generator'> [1, 4, 9, 16, 25, 36, 49, 64, 81]
生成器的效率是非常高的,生成器可以更好的利用内存和CPU的使用效率,并且通常生成器的代码都比较少,这使用生成器的代码非常好容易理解。应此应该尽量多的在代码中使用生成器
参考文档
https://www.datacamp.com/community/tutorials/python-iterator-tutorial

 浙公网安备 33010602011771号
浙公网安备 33010602011771号