

canal-kakfa-flink实现mysql数据的实时同步(一)
一、canal介绍
官网的介绍:
名称:canal [kə'næl]
译意: 水道/管道/沟渠
语言: 纯java开发
定位: 基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql
关键词: mysql binlog parser / real-time / queue&topic
canal是阿里巴巴使用纯java语言开发的一款基于数据库日志增量解析,以提供增量数据订阅和消费的软件.
其实说白了,canal就是一款实现增量数据同步的工具,当前只支持监控并解析binlog。
那canal可以做哪些事情呢:
- 数据库镜像
- 数据库实时备份
- 数据库多级索引的维护
- 业务缓存刷新
- 带有业务逻辑数据的实时处理
canal的工作原理
Mysql主从同步原理
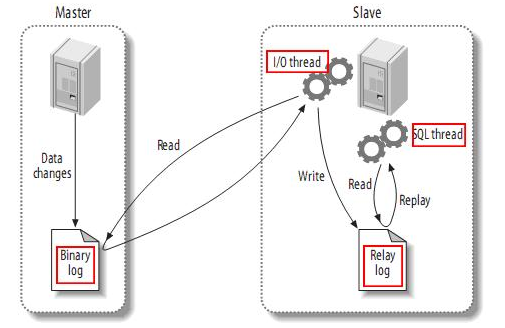
从图中可以看到:
- master实例将数据库的变更(delete,update,insert,...)日志顺序写入到binary log当中。
- 当slave连接到master的时候,master会为slave开启一个binlog dump线程,当master的binlog发生变化的时候,binlog dump线程会通知slave,并将变化的binlog数据发送给slave。
- 当主从同步开启的时候,在slave上会创建2个线程
- IO Thread
该线程连接到master机器,master上的binlog dump线程会将binlog内容发送给该线程,该IO线程接收到binlog内容之后,再将内容写到本地的relay log中。 - SQL Thread
该线程读取IO线程写入的relay log。并根据relay log的内容对slave数据库做相应的操作
- IO Thread
Canal 原理
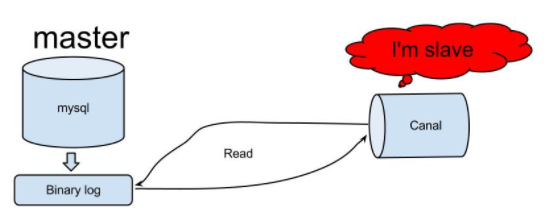
canal的工作原理其实是模拟了数据库的主从同步机制,将自己伪装成mysql slave:
- 模拟mysql master与slave的通信协议,它向master发送dump请求
- master收到canal发送过来的请求之后,开始推送binlog给canal
- canal接受binlog进行解析binary log对象(原始为protobuf byte流)并sink到下游(如:mysql,kafka,es,...)
Canal 架构
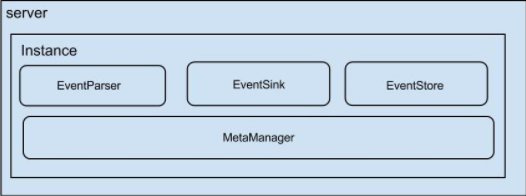
说明:
- server代表的是一个canal运行实例,代表的是一个jvm
- instace对应的是一个数据队列(一个server可以部署多个insance)
instance模块:
- eventParser:数据源接入,模拟slave和master进行交互,协议解析
- eventSink:Parser和Store的连接器,进行数据过滤,加工,分发工作
- eventStore:数据存储
- metaManager:增量订阅&消费信息管理器
二、Canal 的搭建
Mysql的配置
当前canal支持的版本有 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
-
对于自建的mysql,需要进行如下配置:
- 开启MySQL的binlog全日制功能
- 配置binlog-format为ROW模式
对应的my.cnf中的配置如下:
[mysqld] log-bin=mysql-bin # 开启 binlog binlog-format=ROW # 选择 ROW 模式 server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复- 重启mysql服务
- 创建
canal用户,并进行授权,使其具有mysql slave的权限:
CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; FLUSH PRIVILEGES; -
如果使用的是RDS数据库,则直接进行创建
canal用户并授权操作即可。
Canal的安装
-
下载
点击这里,下载所需要的版本的安装包,我这里以1.1.4为例:
![image]()
在下方找到deployer包:
![image]()
-
解压
执行
tar zxvf ./canal.deployer-1.1.4.tar.gz之后可以看到解压后的目录结构如下:![image]()
-
配置
进入到conf目录下
cd conf,可以看到有一个example的文件夹,这个是canal自带的一个instance文件夹,我们需要拷贝一个并重名为我们自己的cp -r ./example ./route,最终目录结构像这样:![image]()
执行
vi route/instance.properties编辑配置文件################################################# ## mysql serverId , v1.0.26+ will autoGen canal.instance.mysql.slaveId=1234 # enable gtid use true/false canal.instance.gtidon=false # position info 这里需要改成自己的数据信息 canal.instance.master.address=192.168.2.226:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # rds oss binlog canal.instance.rds.accesskey= canal.instance.rds.secretkey= canal.instance.rds.instanceId= # table meta tsdb info canal.instance.tsdb.enable=true #canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb #canal.instance.tsdb.dbUsername=canal #canal.instance.tsdb.dbPassword=canal #canal.instance.standby.address = #canal.instance.standby.journal.name = #canal.instance.standby.position = #canal.instance.standby.timestamp = #canal.instance.standby.gtid= # username/password 这里需要改成前面创建并授权了的数据库信息 canal.instance.dbUsername=canal canal.instance.dbPassword=canal@winner # The encoding that represents the databases corresponds to the encoding type in Java,such as UTF-8,GBK , ISO-8859-1 canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex 这里配置需要过滤的表名,正则语法,多个表(库名.表名),使用逗号分隔开来,(.*\\..* 表示读取所有的库中的表),这里列举过滤两张表为例 canal.instance.filter.regex=db1\\.user,db2\\.device # table black regex canal.instance.filter.black.regex= # table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch # table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2) #canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch # mq config 如果是准备将解析后的日志发送到kafka,这里用来配置每个表的数据发送到那个topic # 如果是打算所有的监控的标的日志数据都打到一个topic中的话,可以这样设置一个topic名即可 canal.mq.topic=example # dynamic topic route by schema or table regex 这里是动态topic的配置 # 如果你打算将不同的表的日志打到不同的topic中里面去的话,可以打开下面的配置,格式为[topic:table],如果是多个,可使用逗号分隔, 当然上面的静态topic和此动态topic是可以同时打开的 canal.mq.dynamicTopic=bi_binlog_config_topic:db1\\.user,bi_binlog_config_topic:db2\\.device canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3执行
vi canal.properties修改该配置文件################################################# ######### common argument ############# ################################################# # tcp bind ip 配置canal所在机器的ip canal.ip = 192.168.2.223 # register ip to zookeeper canal.register.ip = canal.port = 11111 canal.metrics.pull.port = 11112 # canal instance user/passwd # canal.user = canal # canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 # canal admin config #canal.admin.manager = 127.0.0.1:8089 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 # 配置canal的zk地址 canal.zkServers = 192.168.1.227:2181,192.168.1.226:2181,192.168.1.225:2181 # flush data to zk canal.zookeeper.flush.period = 1000 canal.withoutNetty = false # tcp, kafka, RocketMQ canal.serverMode = kafka # flush meta cursor/parse position to file canal.file.data.dir = ${canal.conf.dir} canal.file.flush.period = 1000 ## memory store RingBuffer size, should be Math.pow(2,n) canal.instance.memory.buffer.size = 16384 ## memory store RingBuffer used memory unit size , default 1kb canal.instance.memory.buffer.memunit = 1024 ## meory store gets mode used MEMSIZE or ITEMSIZE canal.instance.memory.batch.mode = MEMSIZE canal.instance.memory.rawEntry = true ## detecing config canal.instance.detecting.enable = false #canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now() canal.instance.detecting.sql = select 1 canal.instance.detecting.interval.time = 3 canal.instance.detecting.retry.threshold = 3 canal.instance.detecting.heartbeatHaEnable = false # support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery canal.instance.transaction.size = 1024 # mysql fallback connected to new master should fallback times canal.instance.fallbackIntervalInSeconds = 60 # network config canal.instance.network.receiveBufferSize = 16384 canal.instance.network.sendBufferSize = 16384 canal.instance.network.soTimeout = 30 # binlog filter config canal.instance.filter.druid.ddl = true canal.instance.filter.query.dcl = false canal.instance.filter.query.dml = false canal.instance.filter.query.ddl = false canal.instance.filter.table.error = false canal.instance.filter.rows = false canal.instance.filter.transaction.entry = false # binlog format/image check canal.instance.binlog.format = ROW,STATEMENT,MIXED canal.instance.binlog.image = FULL,MINIMAL,NOBLOB # binlog ddl isolation canal.instance.get.ddl.isolation = false # parallel parser config,# if your server has only one cpu,you need open this confi and set value to false canal.instance.parser.parallel = true ## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors() #canal.instance.parser.parallelThreadSize = 16 ## disruptor ringbuffer size, must be power of 2 canal.instance.parser.parallelBufferSize = 256 # table meta tsdb info canal.instance.tsdb.enable = true canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:} canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL; canal.instance.tsdb.dbUsername = canal canal.instance.tsdb.dbPassword = canal # dump snapshot interval, default 24 hour canal.instance.tsdb.snapshot.interval = 24 # purge snapshot expire , default 360 hour(15 days) canal.instance.tsdb.snapshot.expire = 360 # aliyun ak/sk , support rds/mq canal.aliyun.accessKey = canal.aliyun.secretKey = ################################################# ######### destinations ############# ################################################# canal.destinations = route # conf root dir canal.conf.dir = ../conf # auto scan instance dir add/remove and start/stop instance canal.auto.scan = true canal.auto.scan.interval = 5 canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml #canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml canal.instance.global.mode = spring canal.instance.global.lazy = false canal.instance.global.manager.address = ${canal.admin.manager} #canal.instance.global.spring.xml = classpath:spring/memory-instance.xml #canal.instance.global.spring.xml = classpath:spring/file-instance.xml canal.instance.global.spring.xml = classpath:spring/default-instance.xml ################################################## ######### MQ ############# ################################################## canal.mq.servers = 192.168.1.227:9092,192.168.1.226:9092,192.168.1.225:9092 canal.mq.retries = 0 canal.mq.batchSize = 16384 canal.mq.maxRequestSize = 1048576 canal.mq.lingerMs = 100 canal.mq.bufferMemory = 33554432 canal.mq.canalBatchSize = 50 canal.mq.canalGetTimeout = 100 # 该配置如果设置为false,则canal不进行日志解析,只发送原生的protpbuf二进制日志,消息体相对较小,如果为true,canal会将其解析为json格式,消息体相对较大,占用存储空间较大 canal.mq.flatMessage = true canal.mq.compressionType = none canal.mq.acks = all #canal.mq.properties. = # canal.mq.producerGroup = test # Set this value to "cloud", if you want open message trace feature in aliyun. # canal.mq.accessChannel = local # aliyun mq namespace #canal.mq.namespace = ################################################## ######### Kafka Kerberos Info ############# ################################################## canal.mq.kafka.kerberos.enable = false canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf" canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"配置文件中的配置项很多,总结一下,需要配置的项:
- instance.properties
## mysql serverId , v1.0.26+ will autoGen canal.instance.mysql.slaveId=1234 # position info canal.instance.master.address=192.168.1.218:3306 # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal@winner canal.instance.connectionCharset = UTF-8 # table regex canal.instance.filter.regex=db1\\.user,db2\\.device canal.mq.topic=example canal.mq.dynamicTopic=bi_binlog_config_topic:db1\\.user,bi_binlog_config_topic:db2\\.device - canal.properties
# tcp bind ip canal.ip = 192.168.1.173 # tcp, kafka, RocketMQ canal.serverMode = kafka canal.mq.flatMessage = true ################################################# ######### destinations ############# ################################################# canal.destinations =route #canal.instance.global.spring.xml = classpath:spring/file-instance.xml canal.instance.global.spring.xml = classpath:spring/default-instance.xml ################################################## ######### MQ ############# ################################################## canal.mq.servers = 192.168.1.227:9092,192.168.1.226:9092,192.168.1.225:19092 #canal.mq.producerGroup = test # Set this value to "cloud", if you want open message trace feature in aliyun. #canal.mq.accessChannel = local
- instance.properties


三、启动验证
启动
进入到文件解压目录下,执行命令sh bin/startup.sh启动服务
查看日志
执行命令tail -f logs/canal/canal.log,查看,到如下日志,说明服务启动成功:

topic数据验证
-
在kafka所部属的机器上通过客户端,进入kafka的安装目录,打开消费者:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.225:9092 --topic bi_binlog_config_topic --from-beginning -
对所监控的数据表进行执行insert/update/delete操作,验证topic中是否有数据过来
![image]()
-
可以看到kafka对应的topic中已经可以正确收到操作解析后的消息了

四、可能遇到的问题
1. canal启动后出现生产者发送消息失败的错误
-
报错信息
Caused by: org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for bi_binlog_device_topic-0: 30064 ms has passed since batch creation plus linger time 2021-04-01 10:10:50.481 [pool-4-thread-1] ERROR com.alibaba.otter.canal.kafka.CanalKafkaProducer - java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for bi_binlog_device_topic-0: 30028 ms has passed since batch creation plus linger time java.lang.RuntimeException: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for bi_binlog_device_topic-0: 30028 ms has passed since batch creation plus linger time at com.alibaba.otter.canal.kafka.CanalKafkaProducer.produce(CanalKafkaProducer.java:215) ~[canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.kafka.CanalKafkaProducer.send(CanalKafkaProducer.java:179) ~[canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.kafka.CanalKafkaProducer.send(CanalKafkaProducer.java:117) ~[canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.server.CanalMQStarter.worker(CanalMQStarter.java:183) [canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.server.CanalMQStarter.access$500(CanalMQStarter.java:23) [canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.server.CanalMQStarter$CanalMQRunnable.run(CanalMQStarter.java:225) [canal.server-1.1.4.jar:na] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [na:1.8.0_131] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [na:1.8.0_131] at java.lang.Thread.run(Thread.java:748) [na:1.8.0_131] Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for bi_binlog_device_topic-0: 30028 ms has passed since batch creation plus linger time at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:94) ~[kafka-clients-1.1.1.jar:na] at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:64) ~[kafka-clients-1.1.1.jar:na] at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:29) ~[kafka-clients-1.1.1.jar:na] at com.alibaba.otter.canal.kafka.CanalKafkaProducer.produce(CanalKafkaProducer.java:213) ~[canal.server-1.1.4.jar:na] ... 8 common frames omitted Caused by: org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for bi_binlog_device_topic-0: 30028 ms has passed since batch creation plus linger time -
原因排查
错误提示的是由于连接kafka集群超时引起的,但是按照网上说的
- 扩大超时限制
- 修改kafka的配置
advertised.listeners=PLAINTEXT://192.168.14.140:9092
在进行了上面的几步操作核查之后,发现并没有解决问题,开始找其他的出路。
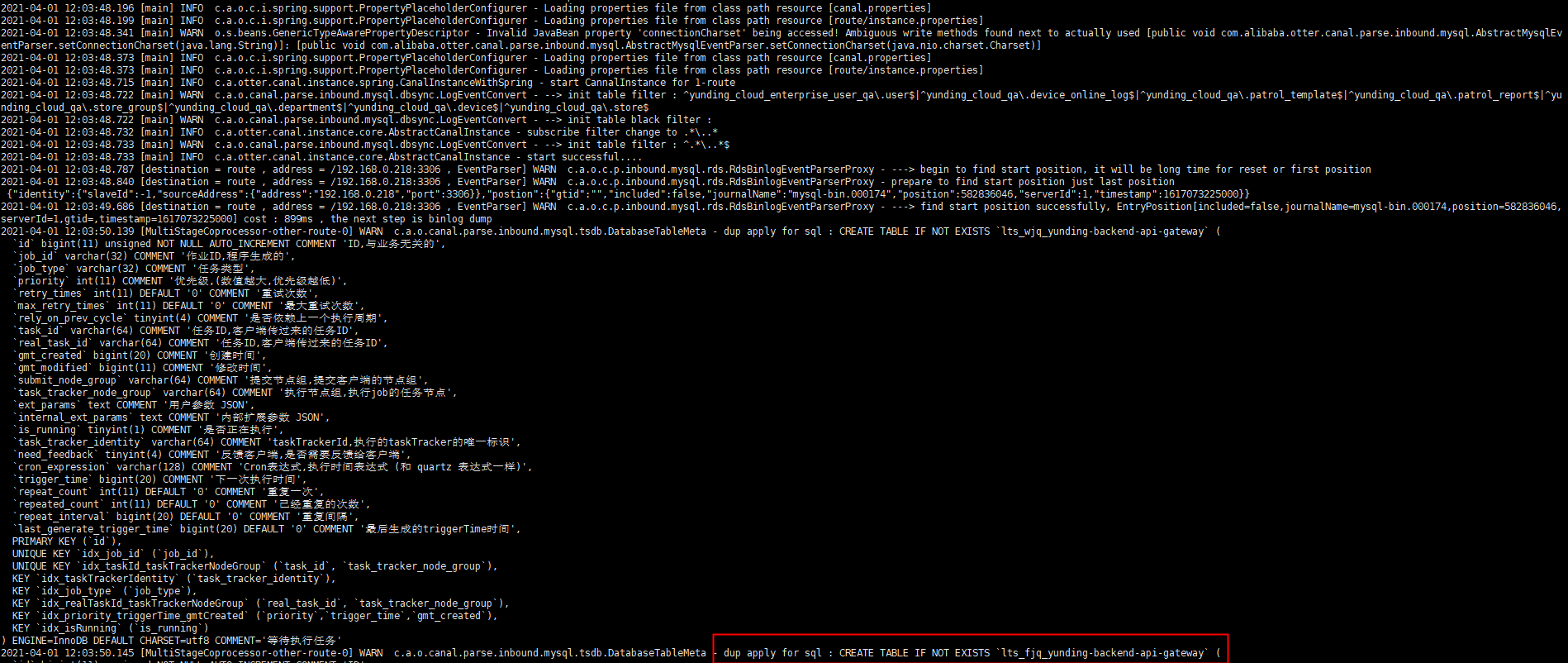
报错信息那种看到bi_binlog_device_topic-0,想应该是canal在往这个topic中写数据的时候出了问题,会不很可能是由于topic的问题导致了,所以由于是测试环境,打算把topic的数据清空,然后在重启canal之后,果然问题解决![image]()
可以看到已经正常读取日志了
-
问题解决
清空topic数据解决,这里有两种方式:
- 删除topic,然后重新创建
# 删除topic ./kafka-topics.sh --zookeeper localhost:2181 --delete --topic bi_binlog_config_topic # 创建topic ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic bi_binlog_config_topic - 清空topic中的数据
# 清空数据 ./kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name bi_binlog_store_topic --alter --add-config retention.ms=10000 # 查看状态 ./kafka-configs.sh --zookeeper localhost:2181 --describe --entity-type topics --entity-name bi_binlog_config_topic
- 删除topic,然后重新创建
2. 连接kafka集群超时
-
报错信息
2021-04-01 11:38:44.322 [pool-4-thread-2] ERROR com.alibaba.otter.canal.kafka.CanalKafkaProducer - java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms. java.lang.RuntimeException: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms. at com.alibaba.otter.canal.kafka.CanalKafkaProducer.produce(CanalKafkaProducer.java:215) ~[canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.kafka.CanalKafkaProducer.send(CanalKafkaProducer.java:179) ~[canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.kafka.CanalKafkaProducer.send(CanalKafkaProducer.java:117) ~[canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.server.CanalMQStarter.worker(CanalMQStarter.java:183) [canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.server.CanalMQStarter.access$500(CanalMQStarter.java:23) [canal.server-1.1.4.jar:na] at com.alibaba.otter.canal.server.CanalMQStarter$CanalMQRunnable.run(CanalMQStarter.java:225) [canal.server-1.1.4.jar:na] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [na:1.8.0_131] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [na:1.8.0_131] at java.lang.Thread.run(Thread.java:748) [na:1.8.0_131] Caused by: java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.TimeoutException: Failed to update metadata after 60000 ms. at org.apache.kafka.clients.producer.KafkaProducer$FutureFailure.<init>(KafkaProducer.java:1150) ~[kafka-clients-1.1.1.jar:na] at org.apache.kafka.clients.producer.KafkaProducer.doSend(KafkaProducer.java:846) ~[kafka-clients-1.1.1.jar:na] at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:784) ~[kafka-clients-1.1.1.jar:na] at org.apache.kafka.clients.producer.KafkaProducer.send(KafkaProducer.java:671) ~[kafka-clients-1.1.1.jar:na] at com.alibaba.otter.canal.kafka.CanalKafkaProducer.produce(CanalKafkaProducer.java:199) ~[canal.server-1.1.4.jar:na] ... 8 common frames omitted -
原因排查
出现该问题的原因是在instance.properties配置中配置了动态topic之后,把
canal.mq.topic=example给注释掉了导致的,所以需要把这个放开# mq config canal.mq.topic=example canal.mq.dynamicTopic=bi_binlog_store_topic:db0\\.patrol_report,bi_binlog_topic:db1\\.store1 -
问题解决
参照上一问题的解决方案
五、结束语
本文主要针对阿里开源同步工具canal做了简单的介绍,并对具体的搭建步骤,并将数据写入到kafka的过程做了简要的总结,数据写入到kafka之后,接下来的就是消费后续程序消费kafka的消息了,可以是flink、spark,...,这里做个笔记,希望能帮助到需要的人。
但是这样是有一个问题的,就是关于canal的单点故障的问题,所以一般生产环境中,我们都需要对canal进行高可用搭建。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号