
Spark操作HBase
Spark写HBase
要通过Spark向 HBase 写入数据,我们需要用到PairRDDFunctions.saveAsHadoopDataset的方式。
package cn.com.win
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.log4j.Logger
import org.apache.spark.{SparkConf, SparkContext}
object TestHbase {
def main(args: Array[String]) {
val log = Logger.getLogger("TestHbase")
//初始化Spark
val conf = new SparkConf().setMaster("local[2]").setAppName("testHbase")
val sc = new SparkContext(conf)
// 定义HBase 的配置
val hconf = HBaseConfiguration.create()
val jobConf = new JobConf(hconf, this.getClass)
// 指定输出格式和输出的表名
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE, "wifiTarget")
val arr = Array(("tjiloaB#3#20190520", 10, 11), ("tjiloaB#3#20190521", 12, 22), ("tjiloaB#3#20190522", 13, 42))
val rdd = sc.parallelize(arr)
val localData = rdd.map(convert)
localData.saveAsHadoopDataset(jobConf)
sc.stop()
}
// 定义函数 RDD -> RDD[(ImmutableBytesWritable,Put)]
def convert(triple: (String, Int, Int)) = {
val p = new Put(Bytes.toBytes(triple._1))
p.addColumn(Bytes.toBytes("wifiTargetCF"), Bytes.toBytes("inNum"), Bytes.toBytes(triple._2))
p.addColumn(Bytes.toBytes("wifiTargetCF"), Bytes.toBytes("outNum"), Bytes.toBytes(triple._3))
(new ImmutableBytesWritable, p)
}
}
执行结果:
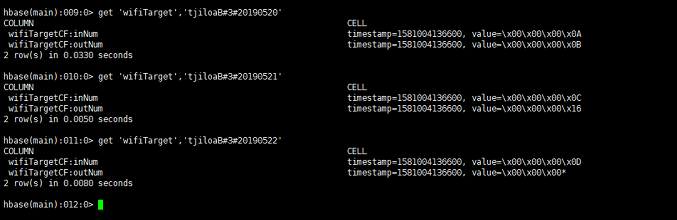
Spark读取HBase
Spark读取HBase,我们主要使用SparkContext 提供的newAPIHadoopRDDAPI将表的内容以 RDDs 的形式加载到 Spark 中。
指定列:
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Scan
import org.apache.hadoop.hbase.filter.PrefixFilter
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.{SparkConf, SparkContext}
/**
* AUTHOR Guozy
* DATE 2020/2/7-0:33
**/
object TestHbase2 {
def main(args: Array[String]): Unit = {
//初始化Spark
val conf = new SparkConf().setMaster("local[2]").setAppName("testHbase")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
val scan = new Scan()
val filter = new PrefixFilter("tjiloaB#3#20190520".getBytes())
scan.setFilter(filter)
val hconf = HBaseConfiguration.create()
hconf.set(TableInputFormat.INPUT_TABLE, "wifiTarget")
hconf.set(TableInputFormat.SCAN, convertScanToString(scan))
val dataRdd = sc.newAPIHadoopRDD(hconf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count = dataRdd.count()
println("dataRdd Count is " + count)
dataRdd.cache()
dataRdd.map(_._2).filter(!_.isEmpty).take(20).foreach { result =>
val key = Bytes.toString(result.getRow)
val innum = Bytes.toInt(result.getValue(Bytes.toBytes("wifiTargetCF"), Bytes.toBytes("inNum")))
val outnum = Bytes.toInt(result.getValue(Bytes.toBytes("wifiTargetCF"), Bytes.toBytes("outNum")))
println(s"key:${key},inNum:${innum},outNum:${outnum}")
}
sc.stop()
}
/**
* 将Scan转换为String
*/
def convertScanToString(scan: Scan): String = {
val proto = ProtobufUtil.toScan(scan);
Base64.encodeBytes(proto.toByteArray());
}
运行结果:
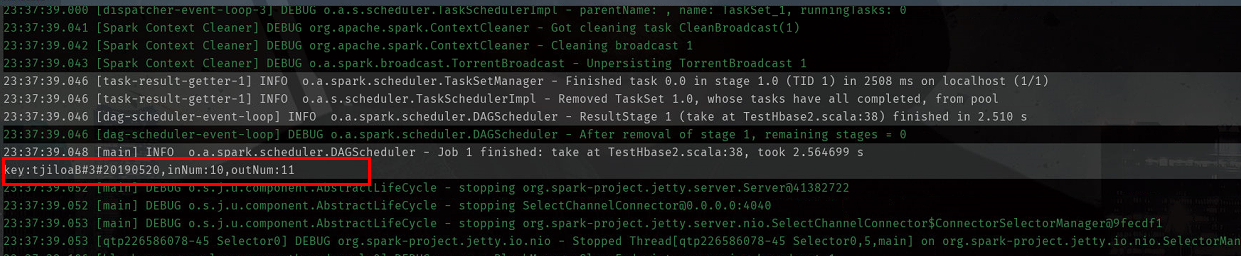
循环遍历列:
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Scan
import org.apache.hadoop.hbase.filter.PrefixFilter
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.protobuf.ProtobufUtil
import org.apache.hadoop.hbase.util.{Base64, Bytes}
import org.apache.spark.{SparkConf, SparkContext}
/**
* AUTHOR Guozy
* DATE 2020/2/7-0:33
**/
object TestHbase2 {
def main(args: Array[String]): Unit = {
//初始化Spark
val conf = new SparkConf().setMaster("local[2]").setAppName("testHbase")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
val scan = new Scan()
val filter = new PrefixFilter("tjiloaB#3#20190520".getBytes())
scan.setFilter(filter)
val hconf = HBaseConfiguration.create()
hconf.set(TableInputFormat.INPUT_TABLE, "wifiTarget")
hconf.set(TableInputFormat.SCAN, convertScanToString(scan))
val dataRdd = sc.newAPIHadoopRDD(hconf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count = dataRdd.count()
println("dataRdd Count is " + count)
dataRdd.cache()
dataRdd.map(_._2).filter(!_.isEmpty).take(20).foreach { result =>
val key = Bytes.toString(result.getRow)
val cells = result.listCells().iterator()
while (cells.hasNext) {
val cell = cells.next()
val innum = Bytes.toInt(cell.getValueArray, cell.getValueOffset, cell.getValueLength)
val outnum = Bytes.toInt(result.getValue(Bytes.toBytes("wifiTargetCF"), Bytes.toBytes("outNum")))
println(s"key:${key},inNum:${innum},outNum:${outnum}")
}
}
sc.stop()
}
/**
* 将Scan转换为String
*/
def convertScanToString(scan: Scan): String = {
val proto = ProtobufUtil.toScan(scan);
Base64.encodeBytes(proto.toByteArray());
}
运行结果
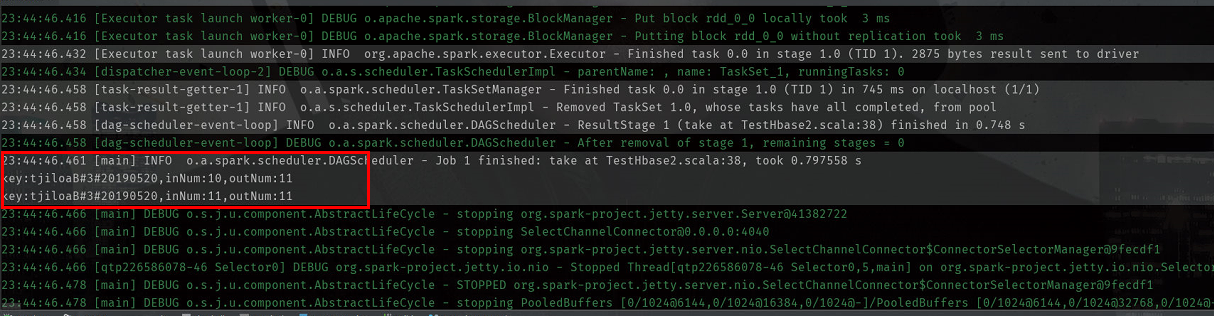
注意:在导入包的时候,TableInputFormat对应的包是 org.apache.hadoop.hbase.mapreduce,而不是 org.apache.hadoop.hbase.maped

 浙公网安备 33010602011771号
浙公网安备 33010602011771号