Linux处理TIME_WAIT和FIN_WAIT_2状态
- 以3.10版本内核为例,4.1+版本内核在处理FIN-WAIT-2时有所改变,后面会提到
- 代码做适度精简
TL;DR
- Linux TCP的TIME_WAIT状态超时默认为60秒,不可修改
- Linux TCP的FIN_WAIT_2和TIME_WAIT共用一套实现
- 可以通过tcp_fin_timeout修改FIN_WAIT_2的超时
- 3.10内核和4.1+内核对tcp_fin_timeout实现机制有所变化
- reuse和recycle都需要开启timestamp,对NAT不友好
- 推荐使用4.3+内核,参数配置可以看最后

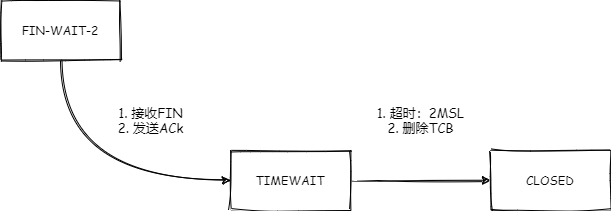
图1. TCP 状态机
源码解析
入口
初步认为tcp_input.c#tcp_fin为此次的入口,主动断开连接方收到被关闭方发出的FIN指令后,进入time-wait状态做进一步处理。
link:linux/net/ipv4/tcp_input.c
/*
* /net/ipv4/tcp_input.c
* ...
* If we are in FINWAIT-2, a received FIN moves us to TIME-WAIT.
*/
static void tcp_fin(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
inet_csk_schedule_ack(sk);
sk->sk_shutdown |= RCV_SHUTDOWN;
sock_set_flag(sk, SOCK_DONE);
switch (sk->sk_state) {
case TCP_SYN_RECV:
case TCP_ESTABLISHED:
...
case TCP_CLOSE_WAIT:
case TCP_CLOSING:
...
case TCP_LAST_ACK:
...
case TCP_FIN_WAIT1:
...
case TCP_FIN_WAIT2:
/* 接收被关闭连接方的FIN -- 发送 ACK,转到TIME_WAIT状态 */
tcp_send_ack(sk);
tcp_time_wait(sk, TCP_TIME_WAIT, 0);
break;
default:
/* Only TCP_LISTEN and TCP_CLOSE are left, in these
* cases we should never reach this piece of code.
*/
pr_err("%s: Impossible, sk->sk_state=%d\n",
__func__, sk->sk_state);
break;
}
...
}
处理time-wait
在tcp_minisocks.c中,会处理状态回收,控制time-wait桶大小等,先在这里给出结论:
a)net.ipv4.tcp_tw_recycle需要和net.ipv4.tcp_timestamps同时打开才可以快速回收
b) 连接状态为TIME_WAIT时,清理时间为默认60s,不可修改
link:linux/net/ipv4/tcp_minisocks.c
// tcp_death_row 结构
/*
在tcp_death_row中存在两种回收机制,一种是timeout较长的sock口,放入tw_timer定时器的队列中,
一种timeout较短的套接口,放入twcal_timer定时器的队列中;
tw_timer定时器超时精度为 TCP_TIMEWAIT_LEN / INET_TWDR_TWKILL_SLOTS=7.5s
而 twcal_timer 的定时单位并不是固定的值,而是根据常量 HZ 定义的, 在3.10内核中为250HZ,
超时精度为:1<<INET_TWDR_RECYCLE_TICK个tick,
即 $((1<<5))=32个tick, 也就是相当于约 32/250≈1/8s的精度
具体处理在inet_twsk_schedule()方法中
*/
struct inet_timewait_death_row tcp_death_row = {
.sysctl_max_tw_buckets = NR_FILE * 2,
.period = TCP_TIMEWAIT_LEN / INET_TWDR_TWKILL_SLOTS,
.death_lock = __SPIN_LOCK_UNLOCKED(tcp_death_row.death_lock),
.hashinfo = &tcp_hashinfo,
.tw_timer = TIMER_INITIALIZER(inet_twdr_hangman, 0,
(unsigned long)&tcp_death_row),
.twkill_work = __WORK_INITIALIZER(tcp_death_row.twkill_work,
inet_twdr_twkill_work),
/* Short-time timewait calendar */
.twcal_hand = -1,
.twcal_timer = TIMER_INITIALIZER(inet_twdr_twcal_tick, 0,
(unsigned long)&tcp_death_row),
};
/*
* /net/ipv4/tcp_minisocks.c
* 将socket状态转为time-wait或者fin-wait-2状态
*/
void tcp_time_wait(struct sock *sk, int state, int timeo)
{
struct inet_timewait_sock *tw = NULL;
const struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcp_sock *tp = tcp_sk(sk);
bool recycle_ok = false;
// 是否开启了recycle,且存在时间戳扩展,标记recycle_ok为true,为后面回收做准备
if (tcp_death_row.sysctl_tw_recycle && tp->rx_opt.ts_recent_stamp)
recycle_ok = tcp_remember_stamp(sk);
// 如果当前等待回收time-wait的数量小于配置的桶大小,把当前sock扔到处理队列里面
if (tcp_death_row.tw_count < tcp_death_row.sysctl_max_tw_buckets) // 2
tw = inet_twsk_alloc(sk, state);
if (tw != NULL) {
struct tcp_timewait_sock *tcptw = tcp_twsk((struct sock *)tw);
const int rto = (icsk->icsk_rto << 2) - (icsk->icsk_rto >> 1); // 3.5*RTO
struct inet_sock *inet = inet_sk(sk);
tw->tw_transparent = inet->transparent;
tw->tw_mark = sk->sk_mark;
tw->tw_rcv_wscale = tp->rx_opt.rcv_wscale;
tcptw->tw_rcv_nxt = tp->rcv_nxt;
tcptw->tw_snd_nxt = tp->snd_nxt;
tcptw->tw_rcv_wnd = tcp_receive_window(tp);
tcptw->tw_ts_recent = tp->rx_opt.ts_recent;
tcptw->tw_ts_recent_stamp = tp->rx_opt.ts_recent_stamp;
tcptw->tw_ts_offset = tp->tsoffset;
tcptw->tw_last_oow_ack_time = 0;
... ifdef endif...
/* Get the TIME_WAIT timeout firing. */
// 从tcp_fin方法过来的入参timeo为0,会被重新赋值为3.5rto
if (timeo < rto)
timeo = rto;
// 如果需要回收话,设置超时时间为当前rto;否则超时时间设为60s,当状态是time-wait时,
// timeo也设置为60s,这是后面处理状态的时间
// btw,rto的值,一般都会小于配置的值,除非双方出现网络抖动和硬件异常需要多次超时重传
if (recycle_ok) {
tw->tw_timeout = rto;
} else {
tw->tw_timeout = TCP_TIMEWAIT_LEN;
if (state == TCP_TIME_WAIT)
timeo = TCP_TIMEWAIT_LEN;
}
/* Linkage updates. */
__inet_twsk_hashdance(tw, sk, &tcp_hashinfo);
// 两种timer
// 1. TCP_TIMEWAIT_LEN定义的60s的timer
// 2. TIMEOUT为3.5*RTO的timer
inet_twsk_schedule(tw, &tcp_death_row, timeo,
TCP_TIMEWAIT_LEN);
inet_twsk_put(tw);
} else {
/* Sorry, if we're out of memory, just CLOSE this
* socket up. We've got bigger problems than
* non-graceful socket closings.
*/
NET_INC_STATS_BH(sock_net(sk), LINUX_MIB_TCPTIMEWAITOVERFLOW);
}
tcp_update_metrics(sk);
tcp_done(sk);
}
time-wait轮询处理
根据timeo值大小计算slot,判断后,进入不同的timer,等待清理
/*
* /net/ipv4/inet_timewait_sock.c
*/
void inet_twsk_schedule(struct inet_timewait_sock *tw,
struct inet_timewait_death_row *twdr,
const int timeo, const int timewait_len)
{
struct hlist_head *list;
unsigned int slot;
/* timeout := RTO * 3.5
*
* 3.5 = 1+2+0.5 to wait for two retransmits.
*
* RATIONALE: if FIN arrived and we entered TIME-WAIT state,
* our ACK acking that FIN can be lost. If N subsequent retransmitted
* FINs (or previous seqments) are lost (probability of such event
* is p^(N+1), where p is probability to lose single packet and
* time to detect the loss is about RTO*(2^N - 1) with exponential
* backoff). Normal timewait length is calculated so, that we
* waited at least for one retransmitted FIN (maximal RTO is 120sec).
* [ BTW Linux. following BSD, violates this requirement waiting
* only for 60sec, we should wait at least for 240 secs.
* Well, 240 consumes too much of resources 8)
* ]
* This interval is not reduced to catch old duplicate and
* responces to our wandering segments living for two MSLs.
* However, if we use PAWS to detect
* old duplicates, we can reduce the interval to bounds required
* by RTO, rather than MSL. So, if peer understands PAWS, we
* kill tw bucket after 3.5*RTO (it is important that this number
* is greater than TS tick!) and detect old duplicates with help
* of PAWS.
*/
// 通过timeout值计算slot号
slot = (timeo + (1 << INET_TWDR_RECYCLE_TICK) - 1) >> INET_TWDR_RECYCLE_TICK;
spin_lock(&twdr->death_lock);
/* Unlink it, if it was scheduled */
if (inet_twsk_del_dead_node(tw))
twdr->tw_count--;
else
atomic_inc(&tw->tw_refcnt);
// 如果所计算的slot大于默认值(1<<5),进入慢timer去处理,其他的进入快timer
if (slot >= INET_TWDR_RECYCLE_SLOTS) {
/* Schedule to slow timer */
if (timeo >= timewait_len) {
slot = INET_TWDR_TWKILL_SLOTS - 1;
} else {
slot = DIV_ROUND_UP(timeo, twdr->period);
if (slot >= INET_TWDR_TWKILL_SLOTS)
slot = INET_TWDR_TWKILL_SLOTS - 1;
}
tw->tw_ttd = inet_tw_time_stamp() + timeo;
slot = (twdr->slot + slot) & (INET_TWDR_TWKILL_SLOTS - 1);
list = &twdr->cells[slot];
} else {
tw->tw_ttd = inet_tw_time_stamp() + (slot << INET_TWDR_RECYCLE_TICK);
if (twdr->twcal_hand < 0) {
twdr->twcal_hand = 0;
twdr->twcal_jiffie = jiffies;
twdr->twcal_timer.expires = twdr->twcal_jiffie +
(slot << INET_TWDR_RECYCLE_TICK);
add_timer(&twdr->twcal_timer);
} else {
if (time_after(twdr->twcal_timer.expires,
jiffies + (slot << INET_TWDR_RECYCLE_TICK)))
mod_timer(&twdr->twcal_timer,
jiffies + (slot << INET_TWDR_RECYCLE_TICK));
slot = (twdr->twcal_hand + slot) & (INET_TWDR_RECYCLE_SLOTS - 1);
}
list = &twdr->twcal_row[slot];
}
hlist_add_head(&tw->tw_death_node, list);
if (twdr->tw_count++ == 0)
mod_timer(&twdr->tw_timer, jiffies + twdr->period);
spin_unlock(&twdr->death_lock);
}
EXPORT_SYMBOL_GPL(inet_twsk_schedule);
4.1+内核修改了什么
4.1 的内核,对TIME_WAIT处理逻辑做了改动,具体改动见PR,这里做一下简单翻译。
tcp/dccp:摆脱单独一个time-wait timer
大约15年前,当时内存昂贵且机器只有一个CPU时,使用timer作为time-wait套接字是不错的选择,
但是这个没法扩展,代码丑陋且延迟极大(经常能看到cpus在death_lock pinlock上达到30ms的自旋)
我们现在可以让每个time-wait sock额外使用64个字节,并将time-wait负载扩展到所有的CPU
来获得更好的性能
测试如下:
下面的测试中, 在server端(lpaa24)/proc/sys/net/ipv4/tcp_tw_recycle 设为 1
修改前 :
lpaa23:~# ./super_netperf 200 -H lpaa24 -t TCP_CC -l 60 -- -p0,0
419594
lpaa23:~# ./super_netperf 200 -H lpaa24 -t TCP_CC -l 60 -- -p0,0
437171
当测试运行时,可以观察到25到33ms的延迟
lpaa24:~# ping -c 1000 -i 0.02 -qn lpaa23
...
1000 packets transmitted, 1000 received, 0% packet loss, time 20601ms
rtt min/avg/max/mdev = 0.020/0.217/25.771/1.535 ms, pipe 2
lpaa24:~# ping -c 1000 -i 0.02 -qn lpaa23
...
1000 packets transmitted, 1000 received, 0% packet loss, time 20702ms
rtt min/avg/max/mdev = 0.019/0.183/33.761/1.441 ms, pipe 2
修改后 :
吞吐量提高90% :
lpaa23:~# ./super_netperf 200 -H lpaa24 -t TCP_CC -l 60 -- -p0,0
810442
lpaa23:~# ./super_netperf 200 -H lpaa24 -t TCP_CC -l 60 -- -p0,0
800992
即时网络利用率提高了90%以上,延迟依旧保持在一个很低的水平上:
lpaa24:~# ping -c 1000 -i 0.02 -qn lpaa23
...
1000 packets transmitted, 1000 received, 0% packet loss, time 19991ms
rtt min/avg/max/mdev = 0.023/0.064/0.360/0.042 ms
commit:789f558cfb3680aeb52de137418637f6b04b7d22
link:v4.1/net/ipv4/inet_timewait_sock.c
void inet_twsk_schedule(struct inet_timewait_sock *tw, const int timeo)
{
tw->tw_kill = timeo <= 4*HZ;
if (!mod_timer_pinned(&tw->tw_timer, jiffies + timeo)) {
atomic_inc(&tw->tw_refcnt);
atomic_inc(&tw->tw_dr->tw_count);
}
}
EXPORT_SYMBOL_GPL(inet_twsk_schedule);
然后在4.3对上面的PR又做了修订 ,详细见PR。做下简单翻译:
当创建一个timewait socket时,我们需要在允许其他CPU找到它之前配置计时器。
允许cpus查找socket的信号将tw_refcnt设置为非零值
我们需要先调用inet_twsk_schedule(),才能在 __inet_twsk_hashdance()中设置tw_refcnt值
这也意味着我们需要从inet_twsk_schedule()中删除tw_refcnt的更改,然后由调用方处理。
请注意,由于我们使用了mod_timer_pinned(),因此可以保证在BH上下文中运行时设置tw_refcnt之前,
计时器不会过期。
为了使内容更具可读性,我引入了inet_twsk_reschedule() helper。
重新设置计时器时,可以使用mod_timer_pending()来确保不需要重新设置已取消的计时器。
注意:如果流的数据包能击中多个cpus,则可能会触发此错误。 除非以某种方式破坏了流量控制,
否则通常不会发生这种情况。 大概修改5个月后发现了这个错误。
reqsk_queue_hash_req()中的SYN_RECV socket需要类似的修复程序,但将在单独的修补程序中提
供该修复程序以进行正确的跟踪。
commit:ed2e923945892a8372ab70d2f61d364b0b6d9054
link:v4.3/net/ipv4/inet_timewait_sock.c#L222
void __inet_twsk_schedule(struct inet_timewait_sock *tw, int timeo, bool rearm)
{
if (!rearm) {
BUG_ON(mod_timer_pinned(&tw->tw_timer, jiffies + timeo));
atomic_inc(&tw->tw_dr->tw_count);
} else {
mod_timer_pending(&tw->tw_timer, jiffies + timeo);
}
}
简单来说,就是CPU利用率提升,吞吐量提高。推荐使用4.3+内核
几个常见参数介绍
net.ipv4.tcp_tw_reuse
重用 TIME_WAIT 连接的条件:
- 设置了 tcp_timestamps = 1,即开启状态。
- 设置了 tcp_tw_reuse = 1,即开启状态。
- 新连接的 timestamp 大于 之前连接的 timestamp 。
- 在处于 TIME_WAIT 状态并且持续 1 秒之后。
get_seconds() - tcptw->tw_ts_recent_stamp > 1。
重用的连接类型:仅仅只是 Outbound (Outgoing) connection ,对于 Inbound connection 不会重用。
安全指的是什么:
- TIME_WAIT 可以避免重复发送的数据包被后续的连接错误的接收,由于 timestamp 机制的存在,重复的数据包会直接丢弃掉。
- TIME_WAIT 能够确保被动连接的一方,不会由于主动连接的一方发送的最后一个 ACK 数据包丢失(比如网络延迟导致的丢包)之后,一直停留在 LAST_ACK 状态,导致被动关闭方无法正确地关闭连接。为了确保这一机制,主动关闭的一方会一直重传( retransmit ) FIN 数据包。
int tcp_twsk_unique(struct sock *sk, struct sock *sktw, void *twp)
{
const struct tcp_timewait_sock *tcptw = tcp_twsk(sktw);
struct tcp_sock *tp = tcp_sk(sk);
/* With PAWS, it is safe from the viewpoint
of data integrity. Even without PAWS it is safe provided sequence
spaces do not overlap i.e. at data rates <= 80Mbit/sec.
Actually, the idea is close to VJ's one, only timestamp cache is
held not per host, but per port pair and TW bucket is used as state
holder.
If TW bucket has been already destroyed we fall back to VJ's scheme
and use initial timestamp retrieved from peer table.
*/
// 需要开启时间戳扩展
if (tcptw->tw_ts_recent_stamp &&
(twp == NULL || (sysctl_tcp_tw_reuse &&
get_seconds() - tcptw->tw_ts_recent_stamp > 1))) {
tp->write_seq = tcptw->tw_snd_nxt + 65535 + 2;
if (tp->write_seq == 0)
tp->write_seq = 1;
tp->rx_opt.ts_recent = tcptw->tw_ts_recent;
tp->rx_opt.ts_recent_stamp = tcptw->tw_ts_recent_stamp;
sock_hold(sktw);
return 1;
}
return 0;
}
EXPORT_SYMBOL_GPL(tcp_twsk_unique);
net.ipv4.tcp_tw_recycle
详见上面处理time-wait一节的分析
不建议开启 tw_recycle 配置。事实上,在 linux 内核 4.12 版本,已经去掉了 net.ipv4.tcp_tw_recycle 参数了,参考commit
tcp_max_tw_buckets
设置 TIME_WAIT 最大数量。目的为了阻止一些简单的DoS攻击,平常不要人为的降低它。如果缩小了它,那么系统会将多余的TIME_WAIT删除掉,日志里会显示:「TCP: time wait bucket table overflow」。
如何设置正确的值
定时器精度相关分析请看参考[3]
4.1内核
- tcp_fin_timeout <= 3, FIN_WAIT_2 状态超时时间为 tcp_fin_timeout 值。
- 3<tcp_fin_timeout <=60, FIN_WAIT_2状态超时时间为 tcp_fin_timeout值+定时器精度(以7秒为单位)误差时间。
- tcp_fin_timeout > 60, FIN_WAIT_2状态会先经历keepalive状态,持续时间为tmo=tcp_fin_timeout-60值, 再经历timewait状态,持续时间为 (tcp_fin_timeout -60)+定时器精度,这里的定时器精度根据(tcp_fin_timeout -60)的计算值,会最终落在上述两个精度范围(1/8秒为单位或7秒为单位)。
4.3+内核
- tcp_fin_timeout <=60, FIN_WAIT_2 状态超时时间为 tcp_fin_timeout 值。
- tcp_fin_timeout > 60, FIN_WAIT_2 状态会先经历 keepalive 状态,持续时间为 tmo=tcp_fin_timeout-60 值 , 再经历 timewait 状态,持续时间同样为 tmo= tcp_fin_timeout-60 值。
参考
[1] Linux TCP Finwait2/Timewait状态要义浅析,https://blog.csdn.net/dog250/article/details/81582604
[2] TCP的TIME_WAIT快速回收与重用,https://blog.csdn.net/dog250/article/details/13760985
[3] 由优化FIN_WAIT_2状态超时引入的关于tcp_fin_timeout参数研究,https://www.talkwithtrend.com/Article/251641
[4] TCP TIME_WAIT 详解,https://www.zhuxiaodong.net/2018/tcp-time-wait-instruction/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号