re模块之豆瓣top250爬取
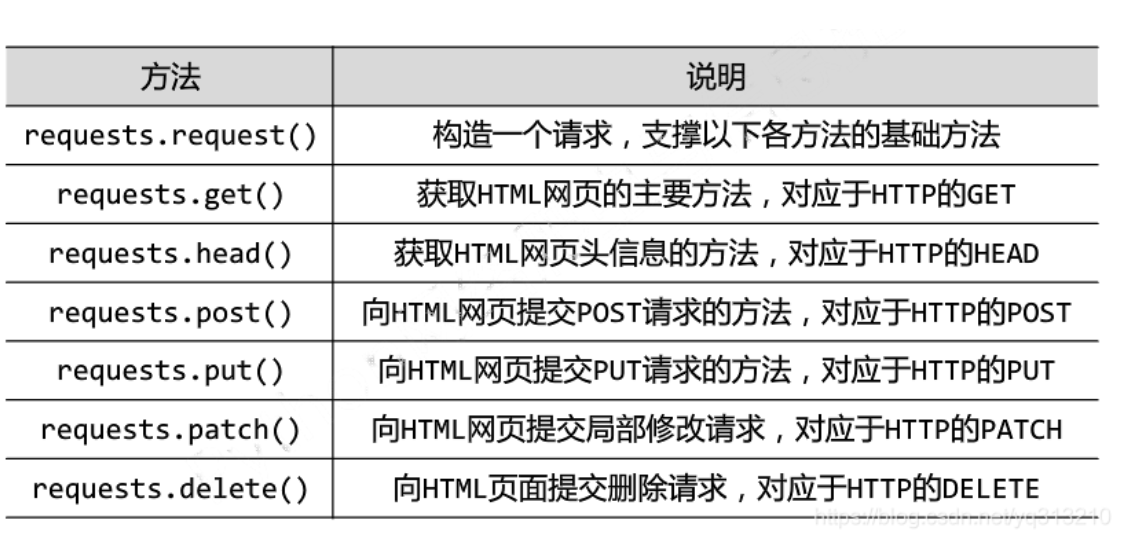
步骤:获取源代码 -> requests
通过re提取有效信息
数据分析csv
首先开启检查查找url和user-agent
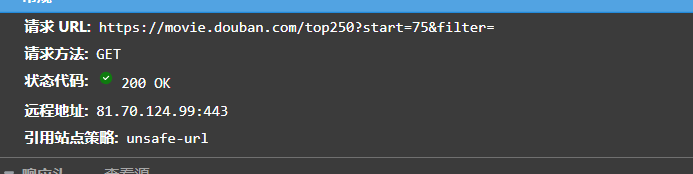
请求方式是get,那对应的就是headers,若是post,对应的是data
我们看到的url知识第一页,这里写个循环就可:
with open('豆瓣Top250爬取.csv','a',encoding='utf-8') as f:
for k in range(0,250,25):
url = 'https://movie.douban.com/top250?start=' + str(k) + '&filter='
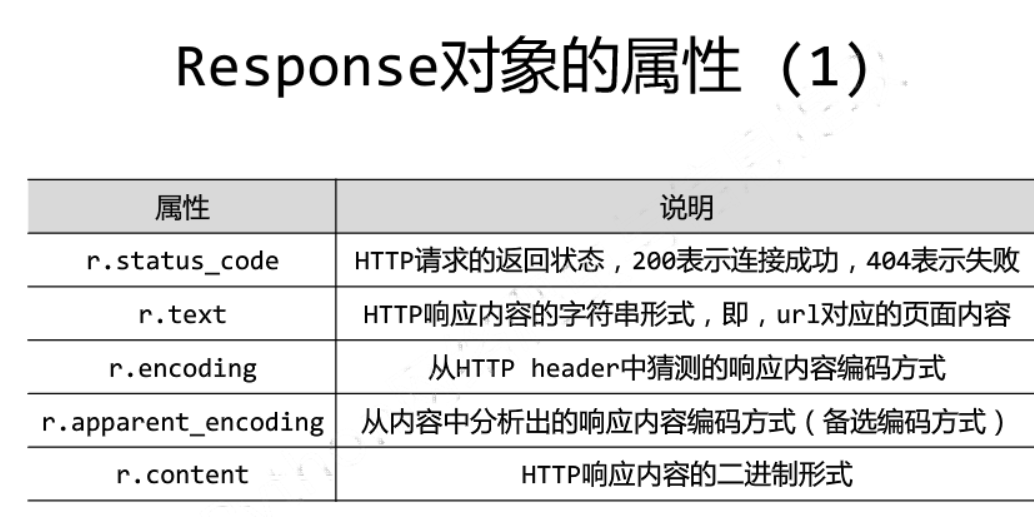
接下来用requests获取源代码
# 拿到源代码
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0.1; Moto G (4)) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Mobile Safari/537.36 Edg/95.0.1020.40'
}
resp = requests.get(url,headers = headers)
page = resp.text
接下来用正则表达式解析数据
# 解析数据 .*? 过滤不需要的内容如空格换行
obj = re.compile(r'<li>.*? <div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="">.*?<br>(?P<year>.*?) .*?'
r'<span class="rating_num" property="v:average">(?P<rating>.*?)</span>.*?'
r'<span>(?P<people>.*?)</span>',re.S)
最后读取到字典中就可
# 开始匹配
res = obj.finditer(page)
f = open("top统计.csv",mode = 'w',encoding='utf-8') # 形成data.csv的文件
csvwriter = csv.writer(f)
for i in res:
# print("电影名称:" + i.group("name"))
# print("上映年份:" + i.group("year").strip()) # 处理空格strip
# print("评分:" + i.group("rating"))
# print("共有" + i.group("people"))
dic = i.groupdict()
dic['year'] = dic['year'].strip()
dic['name'] = "电影名称:" + dic['name'] + " "
dic['rating'] = "评分:" + dic['rating'] + " "
dic['people'] = "共有" + dic['people']
csvwriter.writerow(dic.values())
resp.close()
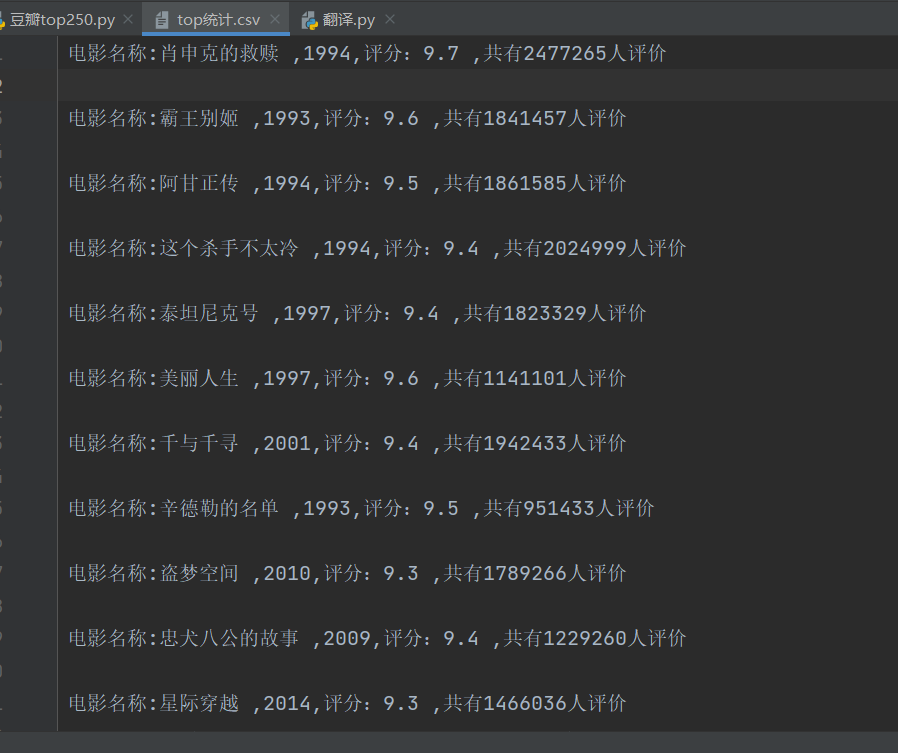
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号