
陪你解读Spring Batch(二)带你入手Spring Batch
前言
说得多不如show code。上一章简单介绍了一下Spring Batch。本章将从头到尾搭建一套基于Spring Batch(2.1.9)、Spring(3.0.5)、mybatis(3.4.5)、mysql、gradle的批处理简单应用来处理文件中大量交易数据的写入。
那么这里简单定义以下交易文件的格式,一个txnId交易Id,一个amt交易金额。一天比如有100w交易数据过来要落表。文件大概长这样,只是简单定义以下,实际开发肯定不会那么少。

因工作需求没有使用最新版本的Spring Batch,所以本章是基于XML config的例子。最新版本支持用Java Config配置Spring Batch Job、Job Scope等。有兴趣的同学可以自行研究一下。本人技术有限,本章讲的如有错误希望请指正。
2.1 项目依赖
首先我们要引入Spring Batch的依赖,这里的版本是2.1.9
springbatch = ["org.springframework.batch:spring-batch-core:2.1.9.RELEASE",
"org.springframework.batch:spring-batch-infrastructure:2.1.9.RELEASE"]
批量处理的过程中,我们都需要数据持久化。这里我用的数据库是mysql,ORM框架是mybatis。所以还要添加mysql-connect和mybatis的依赖
mybatis = "org.mybatis:mybatis:3.4.5" mysqlconnect = "mysql:mysql-connector-java:5.1.25" dbcp = "commons-dbcp:commons-dbcp:1.4"
事务和数据库的配置就不用说了,必须的。
<!-- transaction config -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost/m_test_db"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</bean>
2.2 配置Job
上一章节说过,其实文件批处理的场景,抽象的处理三大步骤分为,读,处理,写。那么我们就依照这张图来开始
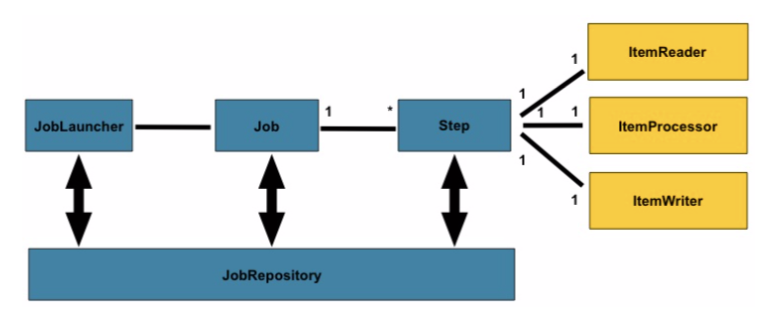
上图如果看不懂的请看上一章节来理解。那么我们先建立一个Spring Batch任务的xml文件,然后定义Job
<!--data-source,transaction-manager 数据源以及事务管理器-->
<batch:job-repository id="jobRepository"
data-source="dataSource" transaction-manager="transactionManager"
isolation-level-for-create="SERIALIZABLE"
table-prefix="DPL_" max-varchar-length="1000"/>
<batch:job id="investmentMatchFileJob"
job-repository="jobRepository">
<batch:step id="investmentMatchFileToDb">
<batch:tasklet>
<batch:chunk reader="txnListFileReader" writer="txnListResultWriter"
commit-interval="300"/>
</batch:tasklet>
</batch:step>
</batch:job>
结合上面的图看,是不是找到点感觉了?一个Job可以有多个Step组合,每一个Step由开发者自己编写,可一把一个大Step分成多个小Step,完全看开发者意愿。每一个Step对应一个ItemReader、ItemProcessor和ItemWriter。所有的批处理框架都可以抽象成最简单的过程,读取数据,处理数据,写数据。所以Spring Batch提供了3个接口,ItemReader、ItemProcessor和ItemWriter。JobRepository则是记录Job、Step和发起Job的执行信息等。
xml配置Job必须依赖的有三项,名称,JobRepository和Step列表。还有一个没介绍就是commit-interval属性,这就是控制读了多少行进行一次写。总不可能读一行写一行对吧?这里配置多少,那么Writer的入参list的size就是多少。
2.2.1 JobRepository
JobRepository是记录Job、Step和发起Job的执行信息,SpringBatch一共会让你导入9张表,具体哪9张表请导入依赖然后查看schema-mysql.sql文件。
这里要说明的一点是table-prefix属性,默认是以BATCH_开头的,你可以改变前缀,当然你的sql脚本的表名前缀也要改动。注意,这里只能改前缀,不可以改表的全名。表的列可以增加,比如说你的公司建表必须要有id,created_at,xxxx等字段的话,可以增加列,没有问题。但是原有列的名称不可以修改。脚本会在3张以SEQ结尾的表插入0,必须要先插入。
2.3 Step
2.3.1 Reader
上面配置的reader是以下这个bean,value="file:#{jobParameters['txnListFile']}"。这里用到SPEL表达式,传入文件路径参数。FlatFileItemReader只能处理一个文件,实际使用中不可能只处理一个文件,所以你也可以导入下面那个叫MultiResourceItemReader类,通过给MultiResourceItemReader设置Resource数组可以实现一个Job读取一个目录下多个文件。但是这里注意,JobRepository不会记录每个文件的处理情况。
<bean id="txnListFileReader"
class="org.springframework.batch.item.file.FlatFileItemReader"
scope="step">
<!--输入文件-->
<property name="resource" value="file:#{jobParameters['txnListFile']}"/>
<!--将每行映射为一个对象-->
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<!--从划分的字段中构建一个对象-->
<property name="fieldSetMapper" ref="InvestMatchItemMapper"/>
<!--根据某种分隔符来分-->
<property name="lineTokenizer" ref="TxnListItemMapperFileLineTokenizer"/>
</bean>
</property>
<!--跳过开头的的一些行-->
<property name="linesToSkip" value="1"/>
<property name="encoding" value="UTF-8"/>
</bean>
<bean id="InvestMatchItemMapper" class="me.grimmjx.sync.TxnListItemMapper"/>
<bean id="TxnListItemMapperFileLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="delimiter" value="|"/>
<property name="names">
<list>
<value>txnId</value>
<value>amt</value>
</list>
</property>
</bean>
<!--以下的内容是对一个目录下多个文件进行批处理的样例-->
<bean id="txnListFileReader"
class="org.springframework.batch.item.file.MultiResourceItemReader"
scope="step">
<property name="resources" value="file:#{jobParameters['txnListFile']}/*.txt"/>
<property name="delegate">
<bean class="org.springframework.batch.item.file.FlatFileItemReader"
scope="step">
<property name="lineMapper">
<bean
class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="fieldSetMapper" ref="InvestMatchItemMapper"/>
<property name="lineTokenizer"
ref="TxnListItemMapperFileLineTokenizer"/>
</bean>
</property>
<property name="linesToSkip" value="1"/>
<property name="encoding" value="UTF-8"/>
</bean>
</property>
</bean>
以下图来理解比较方便
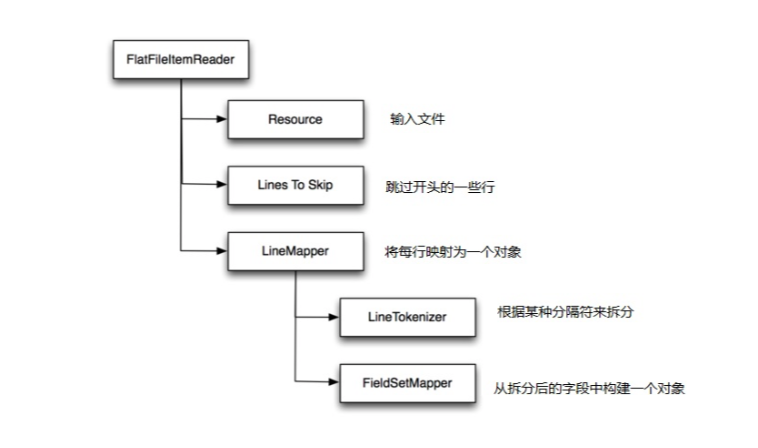
从xml配置来看,delimiter控制如何分割,names就是文件每一列的名字。在这么多配置里,我们只需要写一个Java类。这里就是从一行数据,转换成一个对象。
/** * @author GrimMjx * 交易记录匹配器类。 */ public class TxnListItemMapper implements FieldSetMapper<TxnList>{ @Override public TxnList mapFieldSet(FieldSet fieldSet) throws BindException { TxnList txnList = new TxnList(); txnList.setTxnId(fieldSet.readString("txnId")); txnList.setAmt(fieldSet.readBigDecimal("amt")); return txnList; } }
2.3.2 Writer
writer的bean为
<bean id="txnListResultWriter" class="me.grimmjx.sync.TxnListResultWriter" scope="step"/>
writer执行的是写入操作,我们要实现ItemWriter<T>接口,以下为这个类的Java代码。这里的操作很简单,将构建好的对象集合直接写入库。注意了,外面没有幂等的话,最好这里先判断库里有没有,不要无脑写入。
/** * @author GrimMjx * 交易数据写入类。 */ public class TxnListResultWriter implements ItemWriter<TxnList> { @Autowired private TxnListMapper txnListMapper; @Override public void write(List<? extends TxnList> items) throws Exception { List<TxnList> txnLists = Lists.newArrayList(); for (TxnList item : items) { txnLists.add(item); } txnListMapper.insertBatch(txnLists); } }
2.4 启动Job
这里先定义一个bean,与之前的Job相关联。
<bean id="DefaultFileProcessor" class="me.grimmjx.processor.DefaultFileProcessor">
<property name="job" ref="investmentMatchFileJob"/>
<property name="jobLauncher" ref="jobLauncher"/>
</bean>
以下为这个processor的Java代码
/** * 默认文件处理器类。 * * @author GrimMjx */ public class DefaultFileProcessor { /** * 批次job */ protected Job job; /** * 任务启动器 */ protected JobLauncher jobLauncher; public void process() { String baseDir = "/Users/miaojiaxing/test/2019.01.31.txt"; JobParametersBuilder builder = new JobParametersBuilder(); builder.addString("txnListFile", baseDir); // 携带参数 // builder.addString("packageCode", "12345"); builder.addString("dateTime", System.currentTimeMillis() + ""); JobParameters jobParas = builder.toJobParameters(); try { jobLauncher.run(job, jobParas); } catch (Exception e) { throw new RuntimeException("Run springBatchJob meet error", e); } } public void setJob(Job job) { this.job = job; } public void setJobLauncher(JobLauncher jobLauncher) { this.jobLauncher = jobLauncher; } }
最后我们试试
/** * @author GrimMjx * <p> * 测试类。 */ public class MainTest { public static void main(String[] args) { ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml"); DefaultFileProcessor bean = ctx.getBean("DefaultFileProcessor", DefaultFileProcessor.class); bean.process(); DefaultFileProcessor rereadProcessor = ctx.getBean("rereadProcessor", DefaultFileProcessor.class); rereadProcessor.process(); } }

没有问题。
下一章节将结合校验清洗、异常弹性处理、并行配置附上代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号