
OO summary Unit 3
2022-06-04 00:07 BUAA_GreenDragon 阅读(22) 评论(1) 编辑 收藏 举报本单元主要考察了对JML规格的理解与运用,并实现了一个小型的社交系统,支持消息私发/群发、建立小组、发表情包、发对单/对群红包等功能,并具有一定的异常处理能力。
由于JML的规格已经给出,对于方法的种种条件都加以约束,因此大部分时间只需要照猫画虎即可,实现的难度相较于前两个单元可谓是小了不少。但同时要想取得高分(不被卡TLE),就必须在理解规格描述的方法约束后通过算法进行优化,不能完全按部就班,这增加了不小的难度。
架构设计与图模型分析
1. 架构设计
-
容器的选择
-
本单元的任务主要突出在对于图的动态维护与实时查询,且对于数据管理并未约束为有序,并且对于时间复杂度具有一定的要求。因此在保存中间变量时应当尽可能地采用 HashMap 或者 HashSet 等查询复杂度为
O(1)的容器,应当尽量避免使用 ArrayList 等数组容器。-
private final HashMap<Integer, MyPerson> people;
private final HashMap<Integer, MyGroup> groups;
private final HashMap<Integer, Integer> emojis;
HashMap<Integer, Integer> dis = new HashMap<>(); //记录最短路径的数组
-
-
-
架构分析
-
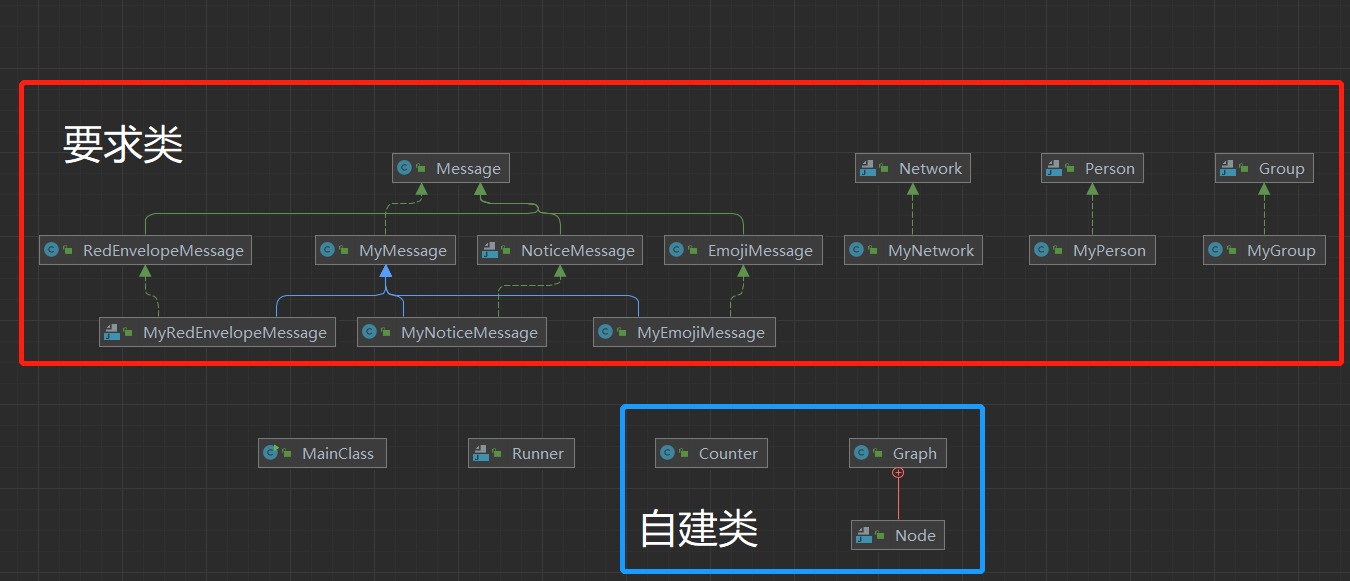
本次作业由于逻辑框架非常清晰,具体的任务主要为方法的实现而不是层次的设计,因此可以自由发挥的空间较小,因此大部分同学的框架应该是非常相像的。除了题目要求实现全部指定接口的要求类之外,我一共新建了三个类储存过程信息。
-
Counter类:用于记录异常触发次数;
-
Graph类:构建图模型,主要用于最短路径Dijkstra算法的计算;
-
Graph的内部类Node:构造了图模型的节点类,储存了person的id与相应的value值;
-
-
HW 11的类图:
-
2. 图模型的构建
本单元的社交网络构建中涉及到图的相关运算,主要涉及到四条指令: qci 、 qbs 、qlc 与 sim 。
-
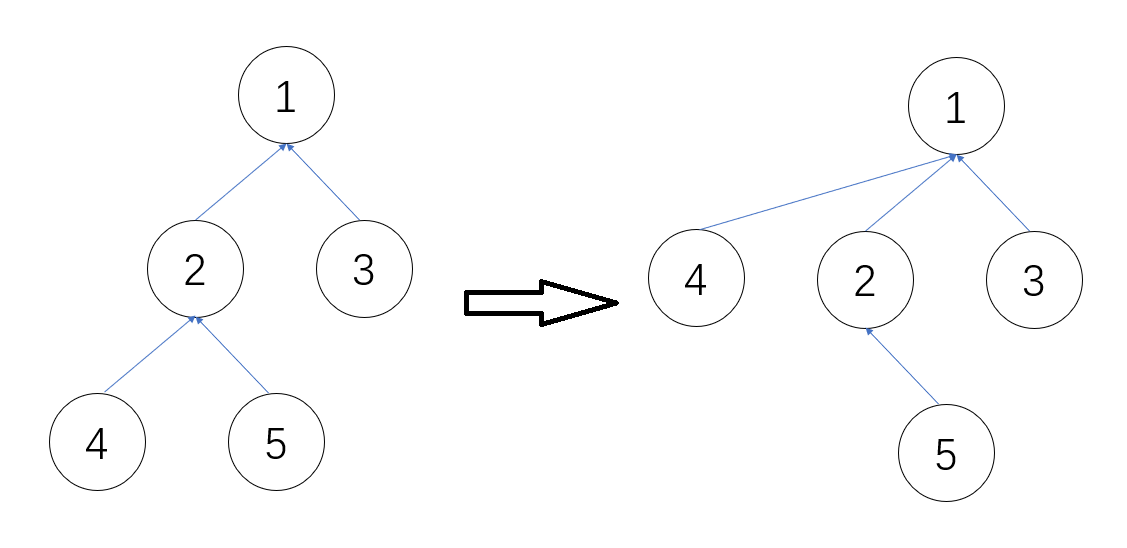
针对前两条指令 qci 、 qbs ,采用了路径压缩的并查集做法:
-
在
MyPerson类中定义了一个静态的 HashMap 储存所有 person 的父节点的 id,这样的一个 HashMap 实际上记录了所有 person 与其中关系所组成的一个森林。当判断两人是否相连时,只需要递归查找父节点是否相等即可。 -
由于本次作业中并未强调人与人之间联系的次序,因此可以采用路径压缩的做法节省查询时间。具体做法就是将路径上所有节点的父节点更新为这棵关系树的父节点,这样最终最多只需要往上找一层即可。
-
路径压缩示意图:
-
-
针对第三条指令 qlc :
-
采用了prim算法,但并无进行优化。
-
-
针对第四条指令 sim :
-
加入了Graph类构建图模型。其相关定义如下:
-
Graph类:其中记录了
HashMap<Integer, ArrayList<Node>> edges,表示图的边集合。其中 Node 为Graph的内部类, ArrayList 记录了从对应 id 的 person 出发的熟人的节点; -
内部类Node类:Node表示为图的节点,记录 HashMap 的键值 personId 表示的 person 所对应的其中一位熟人的 id 与他们间的社交值 value。并且Node中实现了 Comparable 接口,用于Dijkstra算法堆优化中小顶堆的维护。
-
//Node
private final int personId;
private final int value;
-
-
-
其中,对于涉及到prim算法的 qlc 方法以及涉及到Dijkstra算法的 sim 方法都是采用“即查即算”的的思想,并没有加入相关查询值的缓冲计算。我认为这一步的主要难度在于:在动态维护图模型的背景下,已经缓冲的值如何知道什么时候应该被更新。这一步应当是设计到算法层面的内容,已经超出了我的实力范围,而且采用了堆优化的Dijkstra算法已经能够满足时间复杂度的需求,因此就没有考虑这方面了。
性能问题及优化
HW 9
HW 9强测中拿了满分,互测被干碎了,有显著的性能问题。
HW 9实现的功能较少,主要容易被hack的点在于对于指令 qci 与 qbs 的查询上,在具体的实现上,笔者采用了深搜 dfs 的递归算法,时间复杂度应该为 O(n),并且相应的在 MyNetwork 类中完全按照规格实现方法,写了个 O(n^2) 的 qbs 方法,导致虽然强测拿满了,但是在互测中被狠狠地hack了(指全房就我被刀了,共7次)。
原先的 qbs 算法:
public int queryBlockSum() {
int sum = 0;
for (int i = 0; i < people.size(); i++) {
int flag = 0;
for (int j = 0; j < i; j++) {
try {
if (isCircle(people.get(i).getId(), people.get(j).getId())) {
flag = 1;
break;
}
} catch (PersonIdNotFoundException e) {
e.print();
}
}
if (flag == 0) {
sum++;
}
}
return sum;
}
根据分析,罪魁祸首应该是这个 O(n^2) 的 qbs ,于是在之后的作业中均采用了并查集的方法,利用 HashMap 记录每 MyPerson 的父节点,并且实现了路径压缩,成功将 qbs 的复杂度下降到 O(n) ,将 qci 的复杂度降到了 O(1),解决了CTLE的问题。
改进后带路径压缩的并查集算法:
public int find(int id) {
if (union.get(id) == id) {
return id;
} else {
int father = find(union.get(id));
union.replace(id, father);
return father;
}
}
HW 10
HW 10完成的相对较好,没有显著的性能问题,强测中拿了满分,互测也没有被hack。
在最小生成树的实现中采用了prim算法,但是并没有进行优化。
其次对于 Mygroup 内年龄 age 与社交值 value 的相关计算增加了中间值进行缓冲,将对应的查询方法的时间复杂度降到 O(1)。
-
ageAriSum(年龄算数和),在组内增 / 减人的时候维护; -
ageSqrSum(年龄平方和),在组内增 / 减人的时候维护; -
valueSum(社交值和),在组内增 / 减人、以及在NetWork中增加对应关系的时候维护,这里尤其要注意在 ar 指令时要遍历组内所有的group,找到包含该 relation 两端 person 的组,并增加该组的 value 值。
HW 11
HW 11强测中拿了满分,互测被hack了两刀。
HW 11中实现了最短路径的算法,采用Dijkstra算法,由于该社交网络为稀疏图,因此进行了堆优化将时间复杂度从 O(m + n^2) 下降为 O(n * logn + m) (其中n为点数目,m为边的数目)。
public int dijkstra(int id1, int id2) {
HashMap<Integer, Integer> dis = new HashMap<>();
PriorityQueue<Graph.Node> queue = new PriorityQueue<>();
dis.put(id1, 0);
queue.add(new Graph.Node(id1, 0));
while (!queue.isEmpty()) {
Graph.Node tmp = queue.poll();
//若该点已经被计算为最短路径,则剔除,从优先队列中更新tmp
while (tmp.getValue() > dis.get(tmp.getPersonId())) {
tmp = queue.poll();
}
//找到了就退出
if (tmp.getPersonId() == id2) {
break;
}
//找到与该点相连的所有点
ArrayList<Integer> fromTmp = Graph.getInstance().getEdges().get(tmp.getPersonId());
int v = tmp.getPersonId();
//找到未标记顶点且 其权值 > v的权值 + (v,j)的权值,更新其权值
for (int i : fromTmp) {
if (!dis.containsKey(i)) {
dis.put(i, dis.get(v) + getPerson(i).queryValue(getPerson(v)));
queue.add(new Graph.Node(i, dis.get(i)));
} else if (dis.get(v) + getPerson(i).queryValue(getPerson(v)) < dis.get(i)) {
dis.replace(i, dis.get(v) + getPerson(i).queryValue(getPerson(v)));
queue.add(new Graph.Node(i, dis.get(i)));
}
}
}
return dis.get(id2);
}
主要的性能出错还是在 qbs 方法上,原因为我才用了 ArrayList 记录每个节点的父亲节点,并且在记录小群体数目的时候使用了 contains() 方法。经过查阅资料发现,这个 contains() 方法实际上也是一个 O(n) 的方法,它会遍历当前的 ArrayList 再返回 Boolean 值。这就导致了我原先以为 qbs 是 O(n) 的时间复杂度,但是其实是 O(n^2) ,导致被卡CPU时间了。
改进后采用了 HashMap 记录,真正达到了 O(n) 复杂度,就过了bug修复。事实证明,容器的选择非常重要,应该尽量采用 HashMap 、 HashSet 等哈希的容器,尽量减少使用 ArrayList 、 List 这类数组容器,一些方法可能本身就带有 O(n) 的复杂度,非常容易出锅!
改进后的 qbs 方法:
public int queryBlockSum() {
HashMap<Integer, Integer> fathers = new HashMap<>();
for (MyPerson person : people.values()) {
//改用了HashMap
fathers.put(person.getFather(), 1);
}
return fathers.size();
}
自测数据准备
本单元的测试策略流程主要为:
-
自己肉眼检查 + 随机生成数据并与小伙伴对拍 + 针对容易卡时间方法的造数据
1. 本人天眼识别
我先是对照每个方法是否完成了 JML 相关的约束,再检查每个方法的时间复杂度,并针对时间复杂度较高的方法查询资料进行优化。在本环节内对Dijkstra算法进行了堆优化。
2. 随机生成数据
用C++写测评机,配合上命令行的管道生成测试数据进行对拍,数据生成策略为广撒网,生成总共了7000个测试样例,除了先前随机生成的ap,ar,ag指令之外,后面随机生成的各种指令概率均等,保证了在样本足够大的时候可以测出多种情况。
不过在用测评机对拍的时候,时不时会出现“显示某个人错了,重新跑一遍后又没有问题”的奇怪情况,推测可能是在文本结尾判断的时候出问题,或者是命令行哪里操作不当了,不是很明白。
在HW 10的对拍中发现了两处错误:
-
第一处错误:
-
在
qlc指令中发现查询值比小伙伴们的小一些,经检查发现是在最小生成树的prim算法中对于最小值的界定没有考虑到value值可以取到 0 的情况,导致在边为0的时候被忽略掉,使最终查询结果偏大。后修改将判定条件改为 -1 即可。
//改进后对于边的选取的判定
if (minWeight[j] != -1 && minWeight[j] < min) {
//balabala
} -
-
第二处错误:
-
在
MyGroup类中维护valueSum时忘记考虑无论是增加还是减少组内成员,valueSum都应该是以两倍增加 / 减少,而不是一倍。
valueSum +=(-=) 2 * p1.queryValue(person); -
在HW 9与HW 11的自测中尚未测出bug。
3. 针对性测试
针对容易卡时间的方法进行专门的承压测试,例如集中查询 qlc 2000次,查询 sim 2000次等。
Network拓展
假设出现了几种不同的Person
-
Advertiser:持续向外发送产品广告
-
Producer:产品生产商,通过Advertiser来销售产品
-
Customer:消费者,会关注广告并选择和自己偏好匹配的产品来购买 -- 所谓购买,就是直接通过Advertiser给相应Producer发一个购买消息
-
Person:吃瓜群众,不发广告,不买东西,不卖东西
如此Network可以支持市场营销,并能查询某种商品的销售额和销售路径等
1. 扩展分析
-
为了引入广告的概念,可以新建产品类
Product,认为一种产品对应一种广告,广告作为产品内部属性; -
这几种新增都是person,可以考虑构建不同的类继承自
MyPerson类,增加相应的属性与方法:-
吃瓜群众
Person:由于什么活动都没有,可以直接使用MyPerson类; -
广告商
Advertiser:规定每个广告商只能推销一种产品,将需要推广的产品Product作为内部属性,还要记录该产品对应的生产商Producer; -
消费者
Customer:增加对Advertiser的容器作为内部属性,用于记录订阅 / 不喜欢某种产品的广告,而且应该使用 HashMap 记录,HashMap<Advertiser, Integer> likes,当Advertiser对应的数值为正且越高,认为该消费者对于该产品越有兴趣,反之则是不感兴趣; -
生产商
Producer:一种产品的生产商Producer应当与对应的广告商Advertiser绑定,将其作为内部属性,还应当加入销售额totalSell和销售路径perchaser两种属性,还可以引进库存rest;
-
-
结合生活中的例子(如:微信)来看,决定广告的选择与推送应当是社交系统
NetWork的工作,可以根据消费者的喜好(likes)来进行广告推送。
2. 具体实现
-
接口规格:
/*@ public instance model non_null Person[] people; //原有的
@ public instance model non_null Advertiser[] advertisers; //新增
@ public instance model non_null Customer[] customers; //新增
@ public instance model non_null Producer[] producers; //新增
@*/ -
方法实现:
-
sendAd():
/*@ public normal_behavior
@ requires dislikes.contains(getAdvertiser(advertiserId)) &&
containsAdvertiser(advertiserId) && getAdvertiser(advertiserId).getProducer != null &&
containsCustomer(customerId);
@ assignable \nothing;
@ ensures (\forall Advertiser ad; \old(hasAdvertiser(ad)); hasAdvertiser(ad));
@ ensures allAds.length == \old(allAds).length;
@ also
@ public normal_behavior
@ requires !dislikes.contains(getProducer(producerId).getAdvertiser()) &&
containsAdvertiser(advertiserId) && getAdvertiser(advertiserId).getProducer != null &&
containsCustomer(customerId);
@ assignable customers[*].allAds;
@ ensures (\forall Advertiser ad; \old(hasAdvertiser(ad)); hasAdvertiser(ad));
@ ensures hasAdvertiser(getAdvertiser(advertiserId));
@ ensures (\old(hasAdvertiser(getAdvertiser(advertiserId)))) ==>
(allAds.length == \old(allAds).length);
@ ensures (\old(!hasAdvertiser(getAdvertiser(advertiserId)))) ==>
(allAds.length == \old(allAds).length + 1);
@ also
@ public exceptional_behavior
@ signals (AdvertiserNotFoundException e) !containsAdvertiser(advertiserId);
@ signals (ProducerNotFoundException e) !containsAdvertiser(advertiserId) &&
getAdvertiser(advertiserId).getProducer == null;
@ signals (CustomerNotFoundException e) !containsCustomer(customerId);
@*/
public void sendAd(Customer customerId, Advertiser advertiserId)
throws CustomerNotFoundException, ProducerNotFoundException, AdvertiserNotFoundException;该方法实现了广告商发广告的操作。由于广告商持续向用户输出广告,因此不需要加入广告重复的判断,只需要判断广告是否在原有的数组内再决定是否添加广告即可。另外扩展了“减少此推荐”的功能,建立了dislike数组,当广告位于此范围时不予推销。
-
sendProduct():
/*@ public normal_behavior
@ requires containsAdvertiser(advertiserId) &&
getAdvertiser(advertiserId).getProducer != null && containsProducer(producerId);
@ assignable producers[*].rest, advertisers[*].num;
@ ensures getProducer(producerId).getRest == \old(getProducer(producerId).getRest) - num;
@ ensures getAdvertiser(advertiserId).getNum == \old(getAdvertiser(advertiserId).getNum) + num;
@ also
@ public exceptional_behavior
@ signals (AdvertiserNotFoundException e) !containsAdvertiser(advertiserId);
@ signals (ProducerNotFoundException e) !containsProducer(producerId);
@ signals (ProducerNotFoundException e) !containsAdvertiser(advertiserId) &&
getAdvertiser(advertiserId).getProducer == null;
@*/
public void sendProduct(Producer producerId, Advertiser advertiserId, int num)
throws ProducerNotFoundException, AdvertiserNotFoundException;该方法实现了“通过Advertiser来销售产品”的功能,此时生产商的库存
rest减少num个,广告商(中间商)的库存增加num个。-
purchase():
/*@ public normal_behavior
@ requires \old(getAdvertiser(advertiserId).getNum()) + \old(getProducer(producerId).getRest()) < num &&
containsAdvertiser(advertiserId) && containsCustomer(customerId) && containsProducer(producerId) &&
getAdvertiser(advertiserId).getProducer != null;
@ assignable \nothing;
@ ensures \results == false;
@ also
@ public normal_behavior
@ requires \old(getAdvertiser(advertiserId).getNum()) + \old(getProducer(producerId).getRest()) >= num &&
containsAdvertiser(advertiserId) && containsCustomer(customerId) && containsProducer(producerId) &&
getAdvertiser(advertiserId).getProducer != null;
@ assignable customers[*].restMoney, producers[*].allSell, producers[*].purchasers;
@ ensures getCustomer(customerId).getRestMoney() ==
\old(getCustomer(customerId).getRestMoney()) - num * getProducer(producerId).getSingleValue();
@ ensures (\forall Customer c; \old(hasPurchasers(c)); hasPurchasers(c));
@ ensures \old(getProducer(producerId).getPurchasers.length) ==
getProducer(producerId).getPurchasers.length - 1;
@ ensures hasPurchasers(getCustomer(customerId));
@ ensures getProducer(producerId).getAllSell() ==
\old(getProducer(producerId).getAllSell()) + num * getProducer(producerId).getSingleValue();
@ also
@ public exceptional_behavior
@ signals (AdvertiserNotFoundException e) !containsAdvertiser(advertiserId);
@ signals (ProducerNotFoundException e) !containsProducer(producerId);
@ signals (ProducerNotFoundException e) !containsAdvertiser(advertiserId) && containsProducer(producerId) &&
getAdvertiser(advertiserId).getProducer == null;
@ signals (CustomerNotFoundException e) !containsCustomer(customerId);
@*/
public boolean purchase(Producer producerId, Customer customerId, Advertiser advertiserId, int num)
throws CustomerNotFoundException, ProducerNotFoundException, AdvertiserNotFoundException;该方法实现了消费者通过广告商向生产商发送购买信息的功能,该方法执行后消费者钱包余额减少,生产商销售额增加,生产者将该消费者记录以便后续销售路径查询。另外额外拓展了库存查询功能,当广告商与生产商的库存之和不能满足消费者的需求时,本次购买不成立。
-
个人体会
对JML的理解
在我看来,JML作为java的建模语言,优缺点明显。
-
优点:
-
准确无误,对于方法以及数据的约束可以帮助程序员与用户准确理解代码的用途,且没有二义性,便于代码文档的维护。
-
大批的工具集支持,有泛用性。
-
-
缺点:
-
难写:单单一个删除元素的操作就要包括对于前置条件、后置条件以及异常处理的约束,导致 JML 一般都很长,并且细节繁多,撰写 JML 是种考验;
-
理解困难:JML 只是给出了约束,把方法最直接的条件与实现结果讲清楚了,具体的实现方法非常自由,没有具体算法的说明,会使程序员不明所以。像作业9的测验题最后一题,考察最小生成树算法,光看给出的 JML 语言,完全不知道在干嘛。真心感觉不如注释好用。
-
总结一下就是 JML 是个好东西,但是对于我个人写代码而言可能用处不大,在以后实际工程化的开发中可能用的多一些。
构造自测数据的体会
盲目捏造所谓的“超级数据”实际上可能效率非常低。像在HW 10中我和小伙伴捏造了一个10万行整的数据,虽然找到了我的bug,但是由于缺少相关的文本比对工具,导致我连找到哪条指令出错了都非常难以定位,最后从定位bug到修bug的过程也是耗费了相当多的时间。
因此我认为应当采用本周研讨课上王小鸽同学的做法:先针对某个指令集中针对测试,这部分应该以千行数量级的数据为主,便于准确定位bug;“超级数据”的使用应当是在最后环节确认没有bug的时候,数量级也不宜太大。
本单元学习的感悟
JML诞生于java,服务于java。这种规格化的语言约束了方法的前置、后置条件,对于方法所有的“入口”都规定了相应的“出口”,有了 JML 文档,就好像有了把万能钥匙一样,这种感觉是非常奇妙的。另外,JML只关心方法实现的最终结果,忽视了中间具体的实现过程,非常能够看出面向对象这种注重抽象表达的感觉。
再者,我对于第三单元学习的整体感觉是挺棒的,课程的内容结合的也比较紧密,课上讲解JML规格约束的相关知识,实验课通过代码写 JML,作业再通过给定的 JML 写代码,整个环节非常紧凑。另外我认为像本次博客作业以及研讨课中 “自行设计方法并给出JML规格描述”的想法非常有新意,而且可能实用性更强一些,毕竟真正难的是根据需求写JML,对着JML写代码是相对容易很多的。
