机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类
将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分、产品类别划分等)中。
重要概念:质心


K-means聚类要求的变量是数值变量,方便计算距离。
算法实现
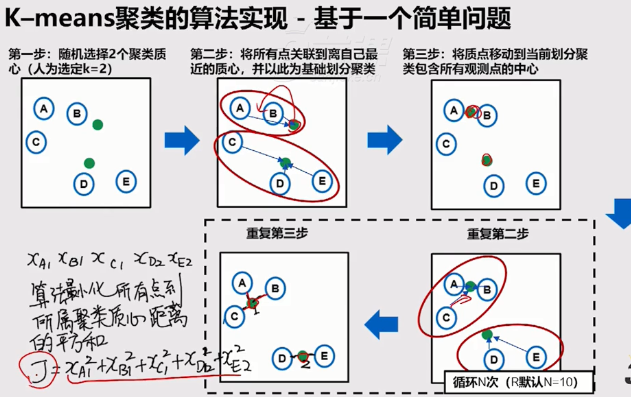
R语言实现
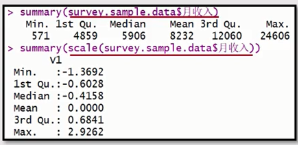
k-means算法是将数值转换为距离,然后测量距离远近进行聚类的。不归一化的会使得距离非常远。
补充:scale归一化处理的意义
两个变量之间数值差别太大,比如年龄与收入的数值差别就很大。
步骤

第一步,确定聚类数量,即k的值
方法:肘部法则+实际业务需求

第二步,运行K-means模型
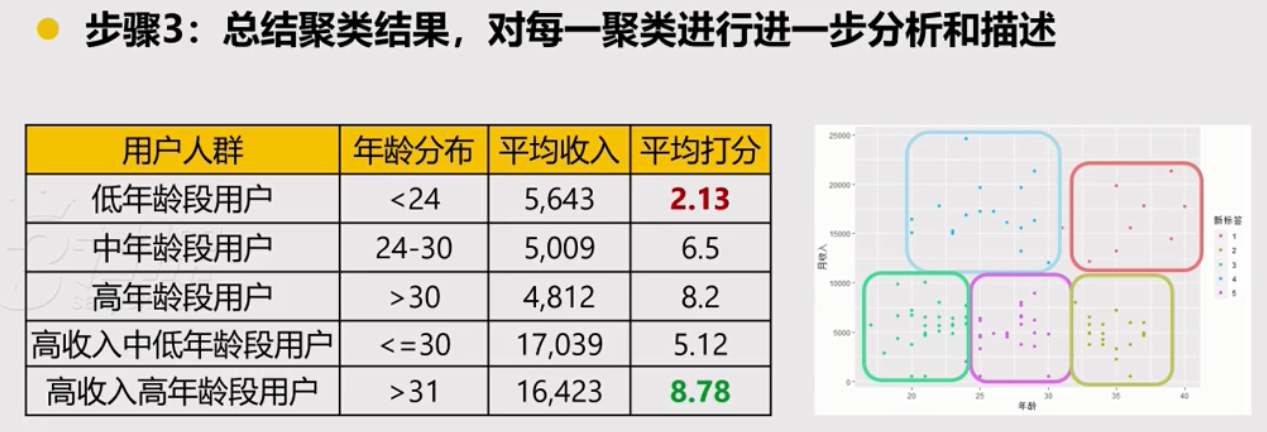
求出分组变量 kmeans_cluster$cluster,做为一个新增变量赋值给原数据survey.sample.data,最终以它作为输出图像的分组基础。

第三步,总结聚类模型结果
k-means聚类的优劣
计算快,可解释性强,能够处理多种数据类型。
重要缺点有二:
1.均值聚类只对圆形或者椭圆形的散点分布形状敏感。如果一些散点图紧紧地形成了月牙形或者圆环形等不规则的聚类形状,K均值聚类就会犯错误。
2.均值聚类要求每个类别中的散点图数量都差不多。如果有一个部分点单独聚成一类,k均值聚类会把它们打散并和其他类合并。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号