OO 第一单元总结
程序结构分析
第一次作业
方法
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
LexicalParser.isValidExpr(String) |
0 | 1 | 1 | 1 |
LexicalParser.splitIntoFactors(String) |
0 | 1 | 1 | 1 |
LexicalParser.splitIntoTerms(String) |
0 | 1 | 1 | 1 |
Main.main(String[]) |
1 | 1 | 2 | 2 |
Monomial.Monomial(BigInteger,BigInteger) |
0 | 1 | 1 | 1 |
Monomial.Monomial(String) |
13 | 1 | 6 | 8 |
Monomial.add(Monomial) |
2 | 2 | 2 | 2 |
Monomial.derivative() |
0 | 1 | 1 | 1 |
Monomial.equals(Object) |
3 | 3 | 2 | 4 |
Monomial.getCoe() |
0 | 1 | 1 | 1 |
Monomial.getExp() |
0 | 1 | 1 | 1 |
Monomial.hashCode() |
0 | 1 | 1 | 1 |
Monomial.multiply(Monomial) |
0 | 1 | 1 | 1 |
Monomial.toString() |
19 | 11 | 9 | 11 |
Polynomial.Polynomial() |
0 | 1 | 1 | 1 |
Polynomial.Polynomial(String) |
3 | 1 | 2 | 2 |
Polynomial.derivative() |
0 | 1 | 1 | 1 |
Polynomial.equals(Object) |
2 | 3 | 1 | 3 |
Polynomial.hashCode() |
0 | 1 | 1 | 1 |
Polynomial.toString() |
5 | 1 | 3 | 4 |
可以看到复杂度基本集中在 Monomial.Monomial(String) 和 Monomial.toString() 这两个方法上。这两个方法分别处理字符串到单项式、单项式到字符串的转换。由于第一次作业中语法分析相对简单,因此有一部分逻辑集中到了 Monomial.Monomial(String) 中。由于性能分相关优化情况较多,所以 ev 值高。其余方法的相关度量值基本都在合理范围内。
类

| Class | OCavg | OCmax | WMC |
|---|---|---|---|
LexicalParser |
1 | 1 | 3 |
Main |
2 | 2 | 2 |
Monomial |
2.9 | 11 | 29 |
Patterns |
n/a | n/a | 0 |
Polynomial |
2 | 4 | 12 |
可以看出,这次的项目设计层次清晰。复杂度主要集中在 Monomial 类,这一点的原因上面已经分析过。
这次作业的架构:
Patterns 是用于存储各语法元素的正则模板串的静态类。
LexicalParser 对字符串进行初步处理。
Monomial 负责处理和单项相关的几乎所有逻辑,调用 LexicalParser 进行初步分割。
Polynomial 存储多项式,调用 LexicalParser 进行初步分割。
Main 处理输入等杂项。
由于第一次作业的需求较为简单,所以项目架构并不是特别复杂。作为一个简单、正确的项目是充分的。
第二次作业
方法
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
Analyzer.Analyzer(String) |
0 | 1 | 1 | 1 |
Analyzer.analyze() |
2 | 2 | 1 | 2 |
Analyzer.constFac() |
0 | 1 | 1 | 1 |
Analyzer.consumeSpace() |
2 | 1 | 2 | 3 |
Analyzer.expFunc() |
1 | 1 | 2 | 2 |
Analyzer.expectType(TokenType...) |
2 | 2 | 2 | 2 |
Analyzer.exponent() |
5 | 3 | 2 | 3 |
Analyzer.expr() |
7 | 5 | 4 | 6 |
Analyzer.exprFac() |
0 | 1 | 1 | 1 |
Analyzer.factor() |
4 | 4 | 4 | 4 |
Analyzer.isType(TokenType...) |
1 | 1 | 1 | 2 |
Analyzer.leadZeroInt() |
2 | 2 | 2 | 2 |
Analyzer.pm() |
4 | 2 | 3 | 3 |
Analyzer.signedInt() |
3 | 3 | 3 | 3 |
Analyzer.term() |
3 | 1 | 4 | 4 |
Analyzer.trigFunc() |
4 | 2 | 3 | 4 |
Analyzer.varFac() |
3 | 3 | 3 | 3 |
Const.Const(BigInteger) |
0 | 1 | 1 | 1 |
Const.derivative() |
0 | 1 | 1 | 1 |
Const.getVal() |
0 | 1 | 1 | 1 |
Const.toString() |
0 | 1 | 1 | 1 |
Cos.Cos(Derivable) |
0 | 1 | 1 | 1 |
Cos.derivative() |
0 | 1 | 1 | 1 |
Cos.toString() |
0 | 1 | 1 | 1 |
Factor.Factor(Derivable,BigInteger) |
0 | 1 | 1 | 1 |
Factor.Factor(Factor) |
0 | 1 | 1 | 1 |
Factor.derivative() |
3 | 3 | 3 | 3 |
Factor.simplify() |
6 | 1 | 4 | 4 |
Factor.toString() |
7 | 4 | 5 | 5 |
Function.Function(Derivable) |
0 | 1 | 1 | 1 |
Function.getVar() |
0 | 1 | 1 | 1 |
Main.main(String[]) |
3 | 1 | 3 | 3 |
Prod.Prod(ArrayList<Factor>) |
0 | 1 | 1 | 1 |
Prod.Prod(Factor...) |
0 | 1 | 1 | 1 |
Prod.add(Factor) |
0 | 1 | 1 | 1 |
Prod.derivative() |
5 | 1 | 4 | 4 |
Prod.isEmpty() |
0 | 1 | 1 | 1 |
Prod.reduced() |
0 | 1 | 1 | 1 |
Prod.reducible() |
0 | 1 | 1 | 1 |
Prod.simplify() |
7 | 3 | 6 | 7 |
Prod.toString() |
0 | 1 | 1 | 1 |
Sin.Sin(Derivable) |
0 | 1 | 1 | 1 |
Sin.derivative() |
0 | 1 | 1 | 1 |
Sin.toString() |
0 | 1 | 1 | 1 |
Sum.Sum(ArrayList<Prod>) |
0 | 1 | 1 | 1 |
Sum.Sum(Prod...) |
0 | 1 | 1 | 1 |
Sum.derivative() |
0 | 1 | 1 | 1 |
Sum.reduced() |
0 | 1 | 1 | 1 |
Sum.reducible() |
0 | 1 | 1 | 1 |
Sum.simplify() |
0 | 1 | 1 | 1 |
Sum.toString() |
3 | 1 | 3 | 3 |
Token.Token(TokenType,String) |
0 | 1 | 1 | 1 |
Token.getLexeme() |
0 | 1 | 1 | 1 |
Token.getType() |
0 | 1 | 1 | 1 |
Token.toString() |
0 | 1 | 1 | 1 |
TokenParser.TokenParser(String) |
0 | 1 | 1 | 1 |
TokenParser.parseToken(int) |
7 | 1 | 4 | 5 |
TokenParser.parseTokens() |
3 | 3 | 2 | 3 |
Var.derivative() |
0 | 1 | 1 | 1 |
Var.toString() |
0 | 1 | 1 | 1 |
可以看到各方法复杂度基本都很低,说明方法分拆合理,逻辑清晰,符合 KISS。若干稍显复杂的方法均为语法处理或输出处理部分,这是由其需求的固有复杂性导致的,在数值上和架构上都很合理。
类
| Class | OCavg | OCmax | WMC |
|---|---|---|---|
Analyzer |
2.59 | 6 | 44 |
Const |
1 | 1 | 4 |
Cos |
1 | 1 | 3 |
Factor |
2.8 | 5 | 14 |
Function |
1 | 1 | 2 |
Main |
2 | 2 | 2 |
Prod |
1.67 | 5 | 15 |
Sin |
1 | 1 | 3 |
Sum |
1.29 | 3 | 9 |
Token |
1 | 1 | 4 |
TokenParser |
2.67 | 4 | 8 |
TokenType |
n/a | n/a | 0 |
Var |
1 | 1 | 2 |
唯一较复杂的类是 Analyzer,这个类实现了语法分析器。这样的复杂度是可以接受的。
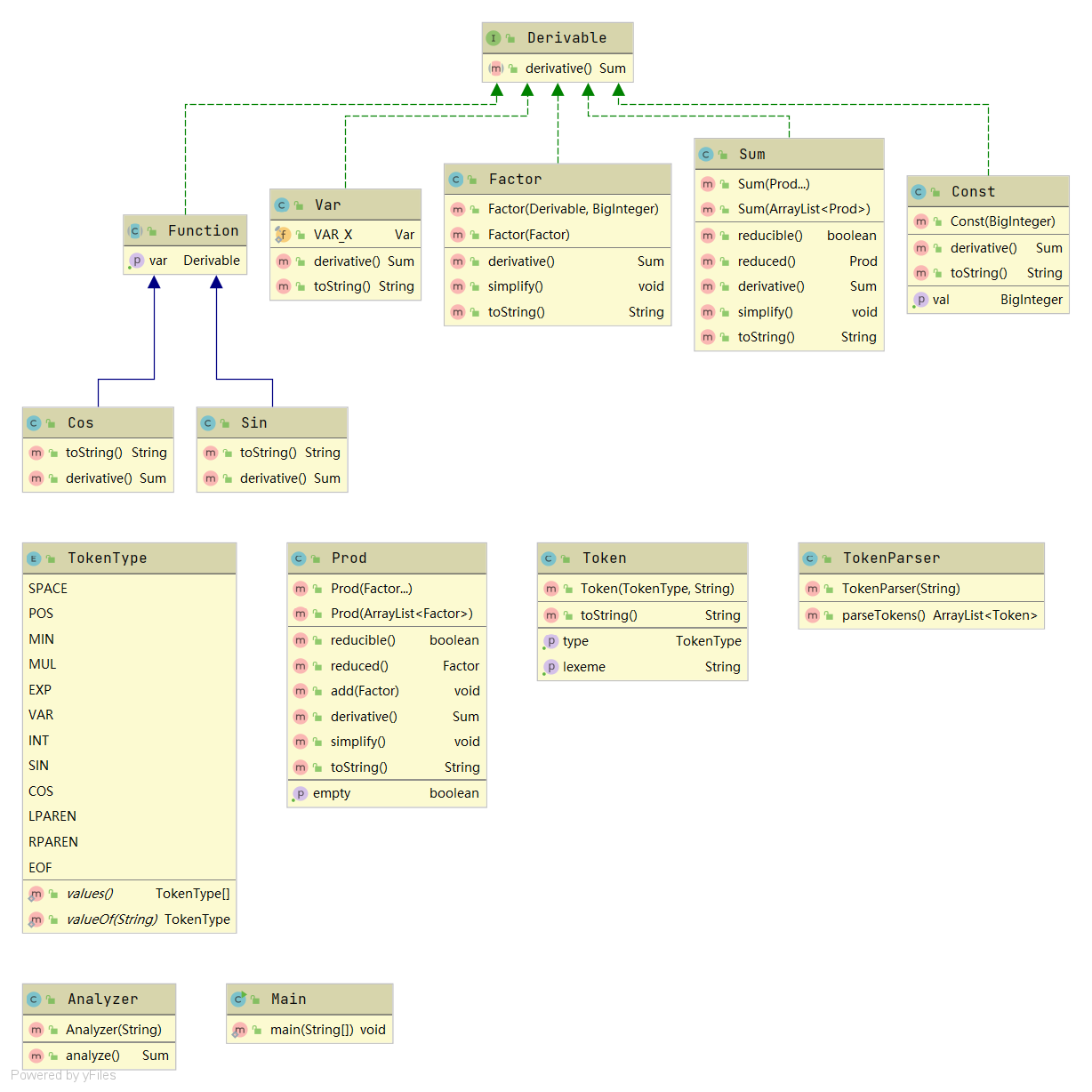
如类图所示,Derivable 接口是各数学对象的接口。在此之上有一个抽象类 Function 定义基本的函数行为,Sin 和 Cos 都是其子类。
输入经由 Main 按行分割后传递给词法分析器 TokenParser,其返回 Token 的 ArrayList 表示分析所得的语素。
Analyzer 接受上述语素序列,以朴素的递归下降方法解析之,产生 Sum 对象。
Sum 对象表示一系列数学对象之和,Prod 对象表示一系列数学对象之积,Factor 是各类因子的处理地,Var 对象表示数学变量,留出了一定的拓展接口,Const 就是朴素的常量。
架构各功能模块之间分工明晰。唯一的缺点是这样的架构不是很适合做优化。
第三次作业
方法
本次作业相对于第二次作业基本无改动,仅仅是增加了异常处理部分,因此各方法复杂度均与上一次作业大致持平,这里不再赘述。
经仔细对比发现两次作业所有方法的各项 metric 均未发生变化,因此这里略去数据。
本次作业唯一新的方法是 Analyzer 类的私有方法 expectType(TokenType...),用于消耗指定类型的语素。
类
经仔细对比发现两次作业所有类的各项 metric 均未发生变化,因此这里略去数据。
经仔细对比,两次作业的类结构完全相同,因此这里略去类图。
对于结构分析来说,既然结构完全相同,就没有再分析一遍的必要。
Bug 分析
第一次作业
第一次作业在公测和互测中均未被找出 bug。
第二次作业
本次作业共一个 bug。
这个 bug 是存在于架构整体设计中的。在原先的架构中,数学对象的 toString 方法在其开始运行时调用本数学对象的 simplify 方法,但 simplify 方法中又调用了其 field 的 toString,形成了循环调用,陷入死循环。
可以看到出现 bug 的方法的圈复杂度偏高。说明循环依赖确实是较难把控、较易出错的设计模式。
第三次作业
第三次作业在公测和互测中均未被找出 bug。
Hack 策略
在第一次作业中我主要通过通读代码、手动构造样例、创建不同分支分别运行的方式查找可能的 bug。我房间内的代码架构均比较复杂,因此没能“对症下药”。
后两次作业中我选择放弃 hack。
重构经历总结
第一次作业的架构基本上是针对 100 性能分来做的,采用了简单暴力的思维,未留出后续拓展余地,从设计的开始就准备了后面作业的重构。
第二次开始,本着 OO 思想和自己的设计思路,我进行了较为合理、全面的设计,并留出了不少的腾挪余地。可以看到第一次和第二次作业的类图基本没有共同之处。
与其说是重构,不如说第一次和后两次作业,我完全把它们当成了两个项目来做。
心得体会
之所以在完成任务上显得较为力不从心,在数次 ddl 时均压线提交,本质上还是由于生产力的落后。生产力的落后主要由身体健康、心理状态、生活节奏三方原因导致。
学业上的竞争本质上是生产力的竞争。如果没有足够的生产力,学业逆风是自然的。如果生产力一直低下到整天游走在 ddl 边缘的话,或许需要认真想想消失的生产力都去哪了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号