实验1-搭建完全分布式环境、启动HDFS、查看WebUI
实验目的
掌握启动HDFS方法,并能够访问HDFS提供的WebUI。
Hadoop完全分布式集群搭建:
Hadoop集群配置=HDFS集群配置+MapReduce配置+Yarn集群配置
本实验仅对HDFS集群进行配置
主要要记住哪个配置文件配置了哪些项
Hadoop-HDFS集群配置(JDK环境的配置、配置哪个节点是NameNode,配置哪些是DataNode以及数据存储路径等)
-
将 JDK路径明确配置给HDFS(修改hadoop-env.sh)
-
指定NameNode节点以及数据存储目录(core-site.xml)
-
指定SecondaryNameNode节点(修改hdfs-site.xml)
-
指定DataNode从节点(修改etc/hadoop/workers文件,每个节点占一行)
完全分布式环境搭建(补充)
【注意】如果你在上一节操作中开启了伪分布式模式Hadoop,执行以下指令以关闭服务并清空缓存:
/opt/hadoop-3.2.1/sbin/stop-dfs.sh
rm -rf /opt/hadoop-3.2.1/tmp/*
1.虚拟机克隆
确保虚拟机处于关闭状态
🐏选中目标虚拟机进行复制,建议复制上一节伪分布式搭建的虚拟机:
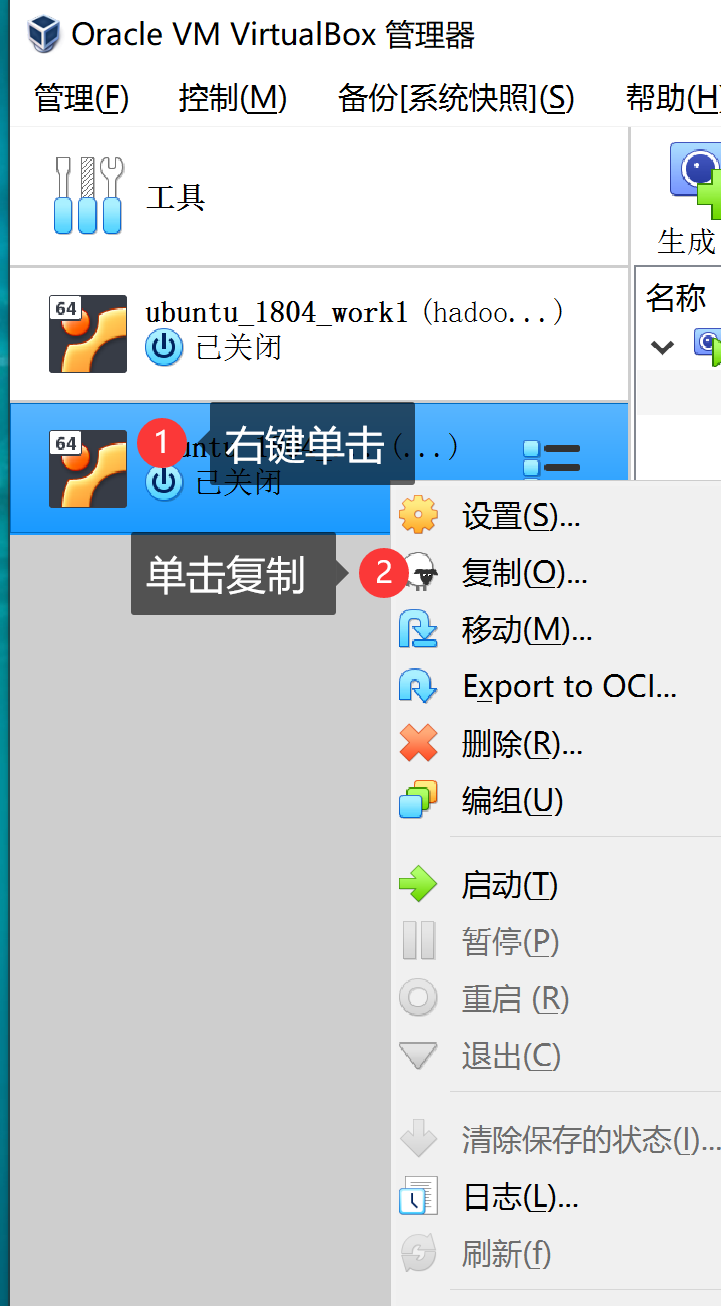
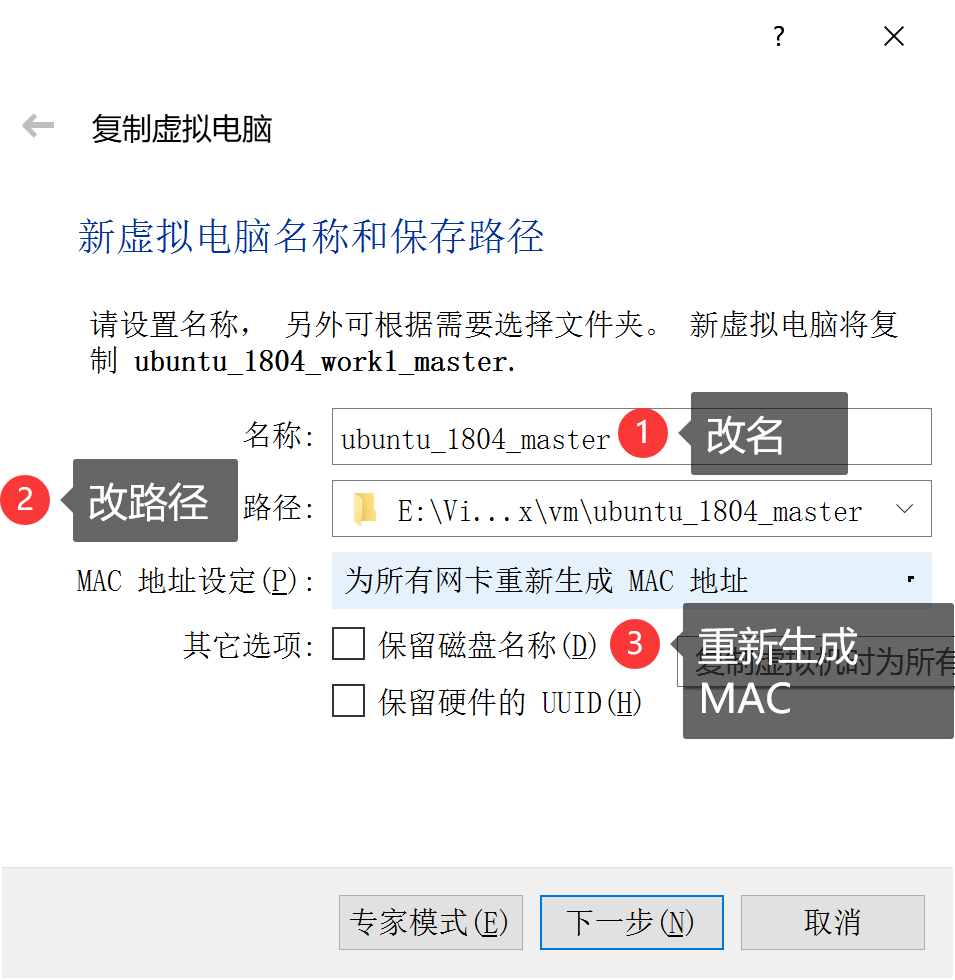
重定义副本名称和路径,并勾选“为所有网卡重新生成MAC地址”:
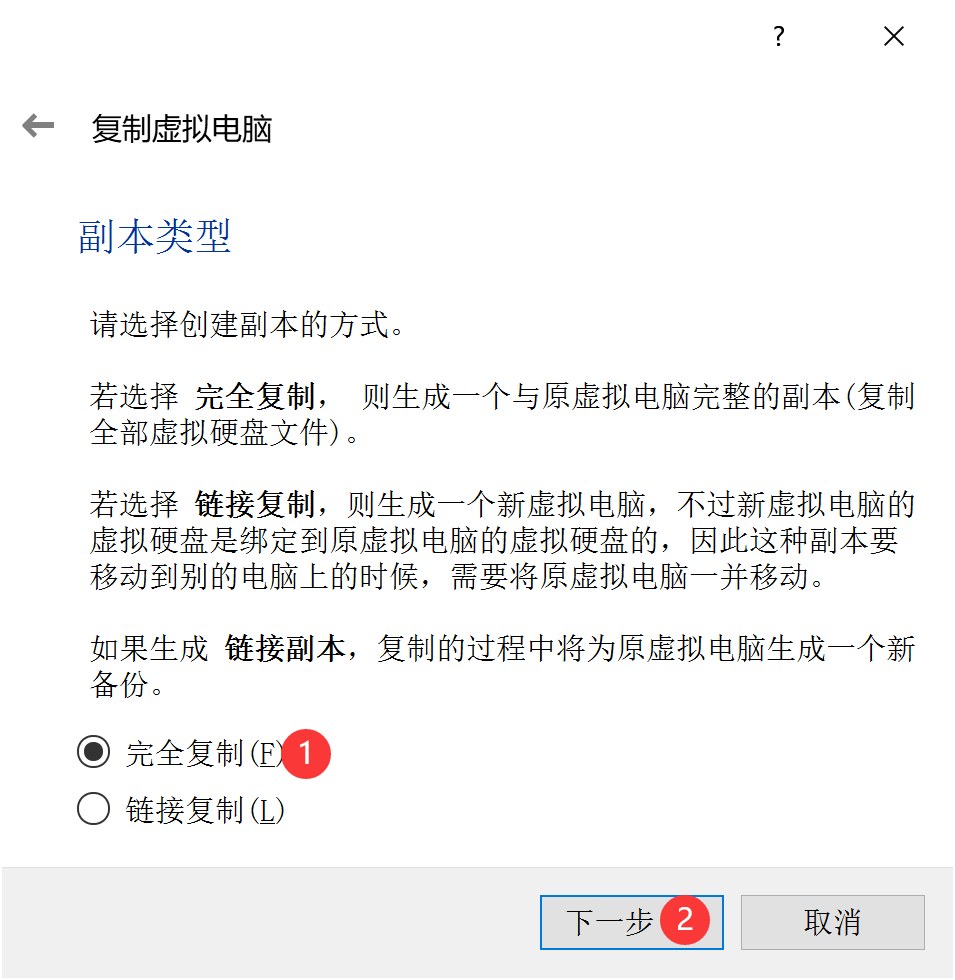
完全复制:
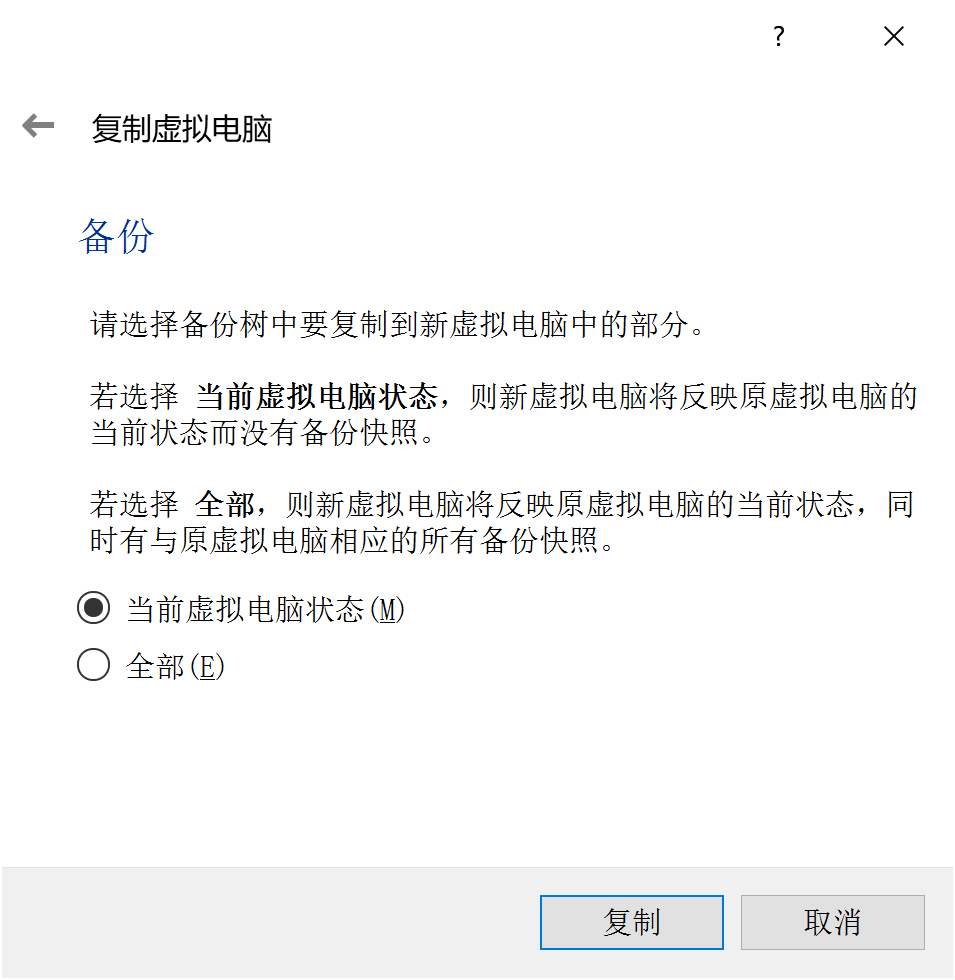
当前状状态:
同理,再次克隆出两组slave节点(slave1和slave2),克隆完成后,查看虚拟机列表:
2.master slave节点通信配置
修改静态ip
(此步不可用Xshell连接虚拟机)
将master节点开机,打开虚拟机内终端连接master节点,修改静态ip:
sudo vi /etc/netplan/*.yaml
进入yaml配置文件,修改以下第8行addresses地址改为[192.168.56.102/24],结果如下:
network:
ethernets:
enps03:
addresses: []
dhcp4: true
enp0s8:
dhcp4: false
addresses: [192.168.56.102/24]
nameservers:
addresses: [192.168.56.1]
version: 2
Esc键,:wq 保存退出
回到命令行,输入:
sudo netplan apply
如无报错,测试网络通断:(ctrl+c退出测试)
ping www.baidu.com
同理,分别修改slave1和slave2节点静态ip。
综上,配置节点ip如下:
| Hostname | Addresses |
|---|---|
| master | 192.168.56.102 |
| slave1 | 192.168.56.103 |
| slave2 | 192.168.56.104 |
打开xshell,登陆master节点分别ping测试slave1和slave2节点,以确保网络畅通:
#登陆master测试slave1和slave2
ping 192.168.56.103
ping 192.168.56.104
#登陆slave1测试master和slave2
ping 192.168.56.102
ping 192.168.56.104
修改hostname
Xshell连接master节点
输入以下命令:
sudo vi /etc/hostname
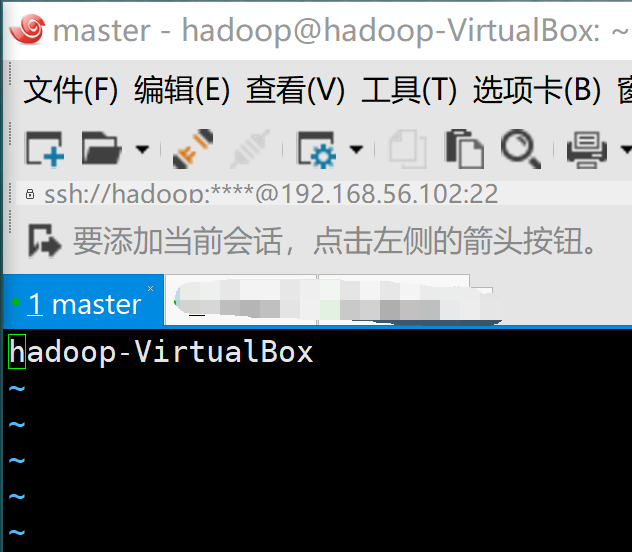
修改hostname:
:wq 保存退出
重启虚拟机后见:
slave1和slave2重复上述步骤对应修改hostname:
| Hostname | Addresses |
|---|---|
| master | 192.168.56.102 |
| slave1 | 192.168.56.103 |
| slave2 | 192.168.56.104 |
ssh公钥分发及hosts文件修改
以主机master为例,分步讲解如何实现主从机的免密访问:
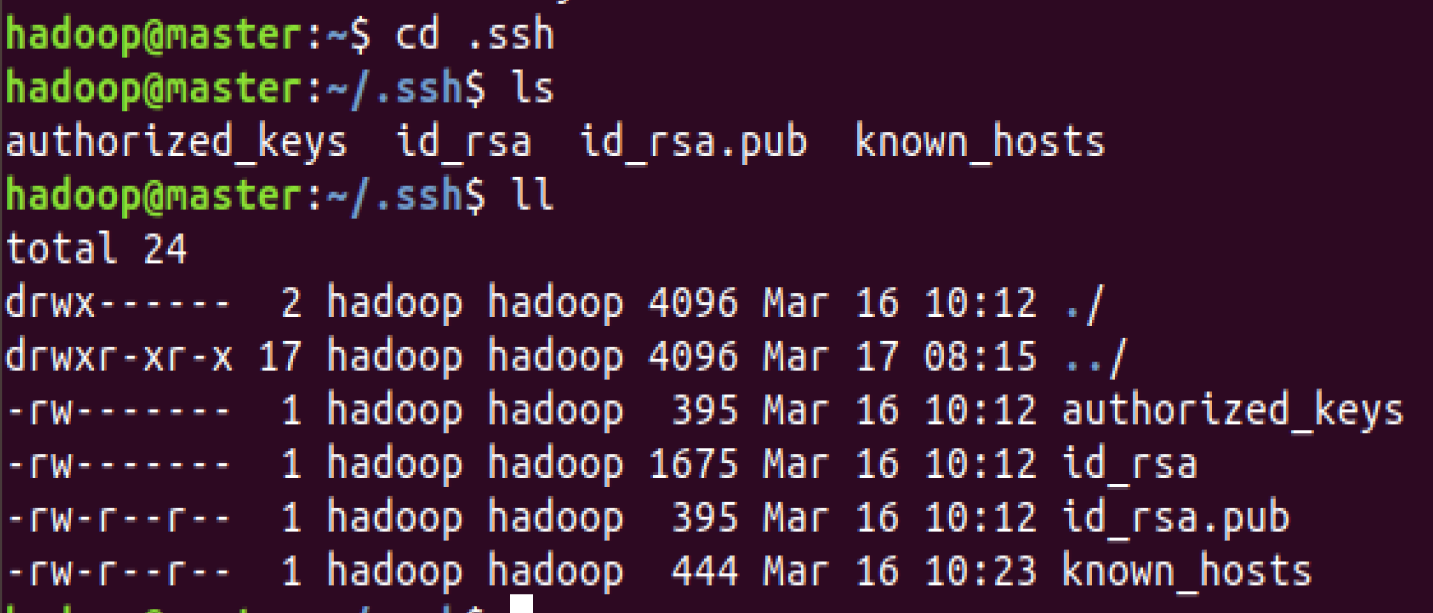
(1)查看~/.ssh目录,
cd ~/.ssh
ll
该目录下默认包含authorized_keys, id_rsa(私钥), id_rsa.pub(公钥), known_hosts四个文件:
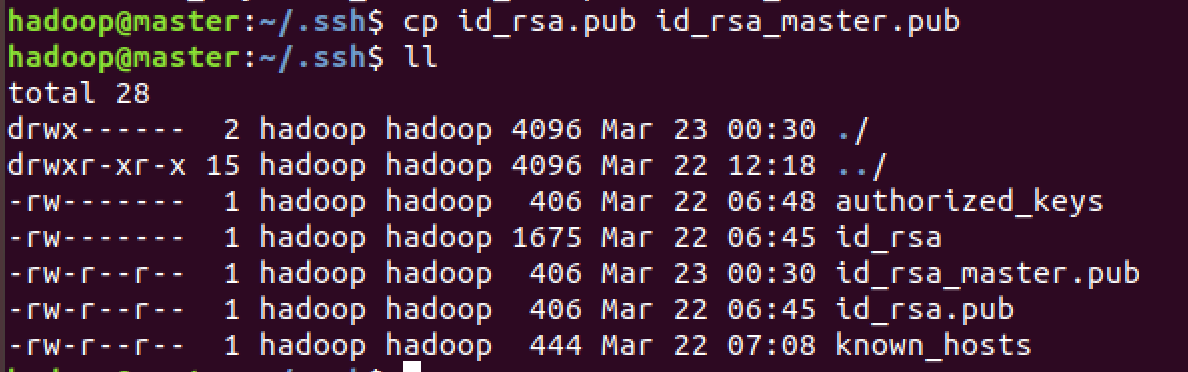
(2)使用cp id_rsa.pub id_rsa_master.pub命令,将master节点公钥id_rsa.pub复制为id_rsa_master.pub。
cp id_rsa.pub id_rsa_master.pub
(3)打开xshell使用scp命令将master节点的公钥上传到slave节点中:
本教程使用“hadoop”为虚拟机(节点)用户名,请在被传输的目标虚拟机上务必使用whoami确认用户名:
whoami
如用户名为hadoop,执行:
cd .ssh
scp ~/.ssh/id_rsa_master.pub hadoop@192.168.56.103:/home/hadoop/.ssh
scp ~/.ssh/id_rsa_master.pub hadoop@192.168.56.104:/home/hadoop/.ssh
如用户名为ubuntu,执行:
cd .ssh
scp ~/.ssh/id_rsa_master.pub ubuntu@192.168.56.103:/home/ubuntu/.ssh
scp ~/.ssh/id_rsa_master.pub ubuntu@192.168.56.104:/home/ubuntu/.ssh


(4)在slave1和slave2中分别调用cat ~/.ssh/id_rsa_master.pub >> ~/.ssh/authorized_keys命令,将主机master的公钥添加到authorized_keys中,目的在于使从机slave1和2可免密访问主机master:
sudo cat ~/.ssh/id_rsa_master.pub >> ~/.ssh/authorized_keys


(5)修改hosts
(master slave1 slave2节点均需要修改)
查看hosts:
sudo vi /etc/hosts
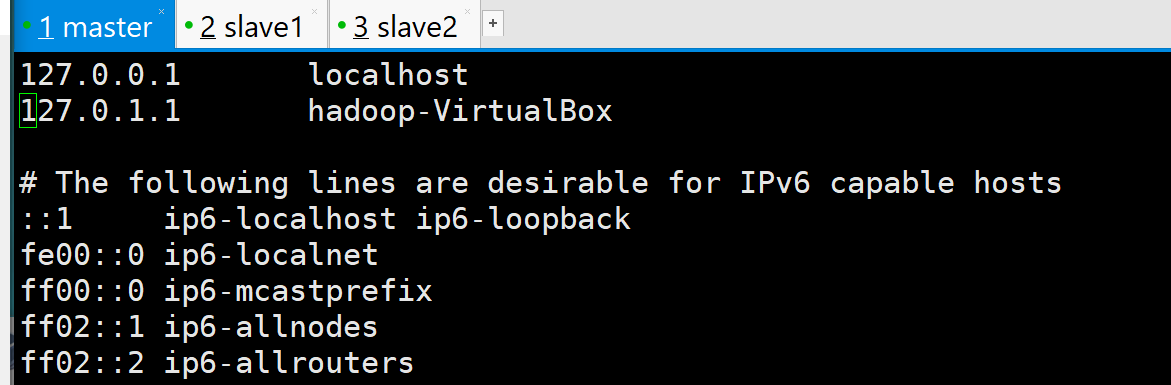
参考如下内容:
127.0.0.1 localhost
192.168.56.102 master
192.168.56.103 slave1
192.168.56.104 slave2
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
重启网络:
sudo /etc/init.d/networking restart

建议在修改完主机名后,在各节点分别使用ssh命令来检验:
ssh master
ssh slave1
ssh slave2
3.配置相关文件
配置当前环境变量
每个节点均配置
xshell登陆master节点,首先进入~/.bashrc:
sudo vi ~/.bashrc
Esc键——>Shift+G 键移动到文件末尾——>点击字母o键,新建行;
复制粘贴以下内容到~/.bashrc:
# set hadoop path
export HADOOP_HOME=/opt/hadoop-3.2.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Esc键——>:wq 保存退出文件后终端执行:
source ~/.bashrc
最后查看版本确保正确加入环境变量:
hadoop version
同理,配置slave1和slave2

创建 HDFS 存储目录
在master节点打开Hadoop安装目录并查看:
cd /opt/hadoop-3.2.1/
ll
创建dfs 、tmp目录:
mkdir dfs tmp
创建namenode文件、数据和临时文件存储路径,并查看当前目录:
cd dfs
mkdir name data tmp
ls

可在slave1和slave2节点终端中整体粘贴以下命令并回车执行:
cd /opt/hadoop-3.2.1/
mkdir dfs tmp
cd dfs
mkdir name data tmp
ls
检查Hadoop中的Java环境变量
检查hadoop-env.sh中的环境变量配置情况,如缺失及时补充:
sudo vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
分别在hadoop-env.sh以及yarn-env.sh添加:
export JAVA_HOME=/opt/jdk1.8.0_241
:wq保存退出。
配置 workers
xshell打开workers文件:
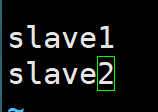
vi $HADOOP_HOME/etc/hadoop/workers
删除原内容添加,分行:
slave1
slave2
配置 core-site.xml
xshell打开master节点,执行命令:
sudo vi /opt/hadoop-3.2.1/etc/hadoop/core-site.xml
在<configuration></configuration>之间修改加入如下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.2.1/tmp</value>
</property>
</configuration>
配置 hdfs-site.xml
回到终端,键入:
sudo vi /opt/hadoop-3.2.1/etc/hadoop/hdfs-site.xml
在<configuration></configuration>之间修改加入如下配置:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.2.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.2.1/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
配置 mapred-site.xml
🚧 暂不讲解,后续实验补充。
配置 yarn-site.xml
🚧 暂不讲解,后续实验补充。
sudo cp -R /opt/hadoop-3.2.1/etc/hadoop_back /opt/hadoop-3.2.1/etc/hadoop
分发配置文件
备份
分别登陆slave1、2节点执行配置文件备份:
mv /opt/hadoop-3.2.1/etc/hadoop /opt/hadoop-3.2.1/etc/hadoop_back
ls /opt/hadoop-3.2.1/etc/
此步相当于使用mv命令将原文件重命名;
同时利于下一步使用scp命令更新配置文件目录“/opt/hadoop-3.2.1/etc/hadoop”,避免文件污染;
备份完成后如下:
或使用命令查看:
ll /opt/hadoop-3.2.1/etc/

分发配置文件到slave节点
xshell打开master节点:
scp -r /opt/hadoop-3.2.1/etc/hadoop root@slave1:/opt/hadoop-3.2.1/etc/hadoop
scp -r /opt/hadoop-3.2.1/etc/hadoop root@slave2:/opt/hadoop-3.2.1/etc/hadoop
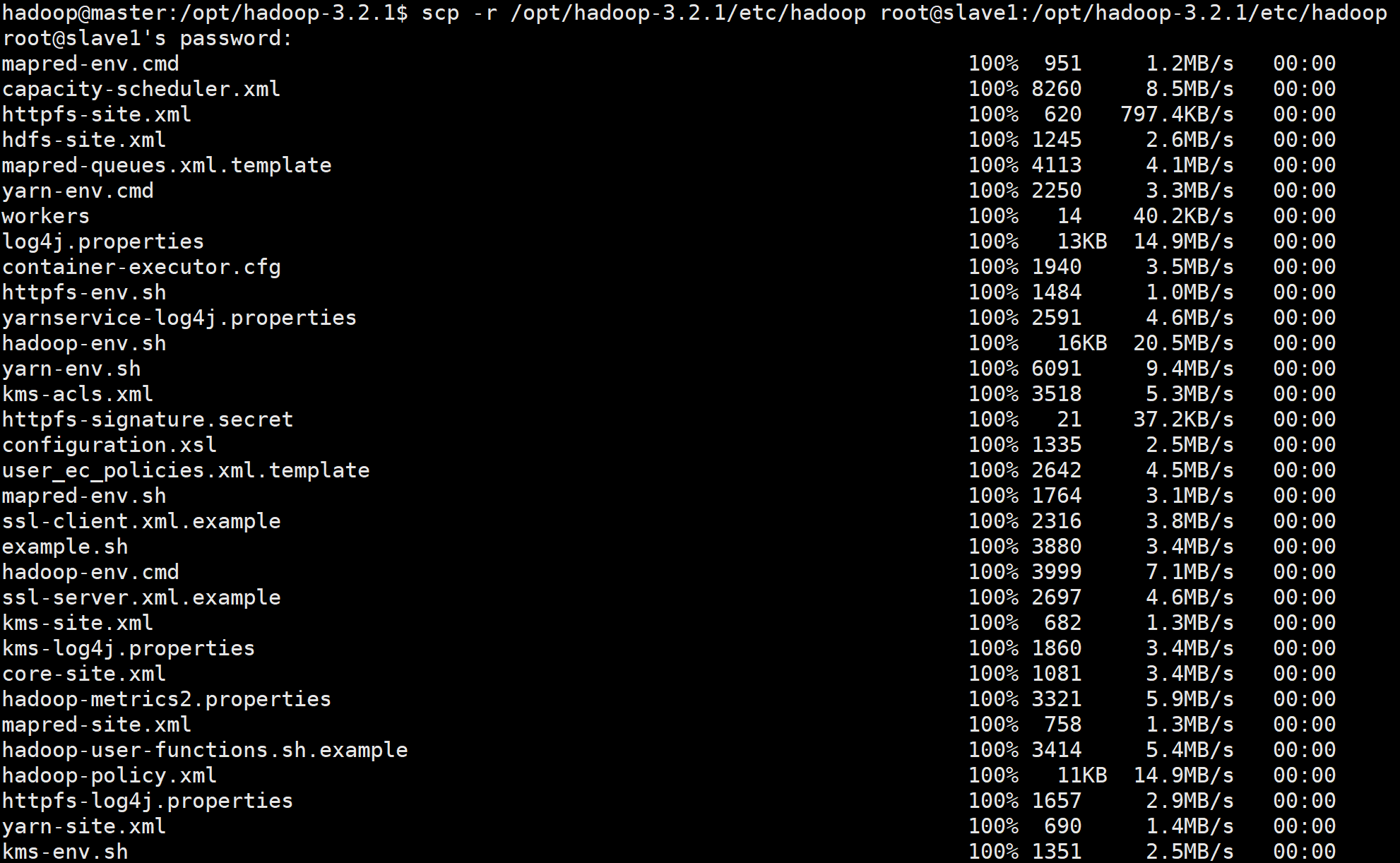
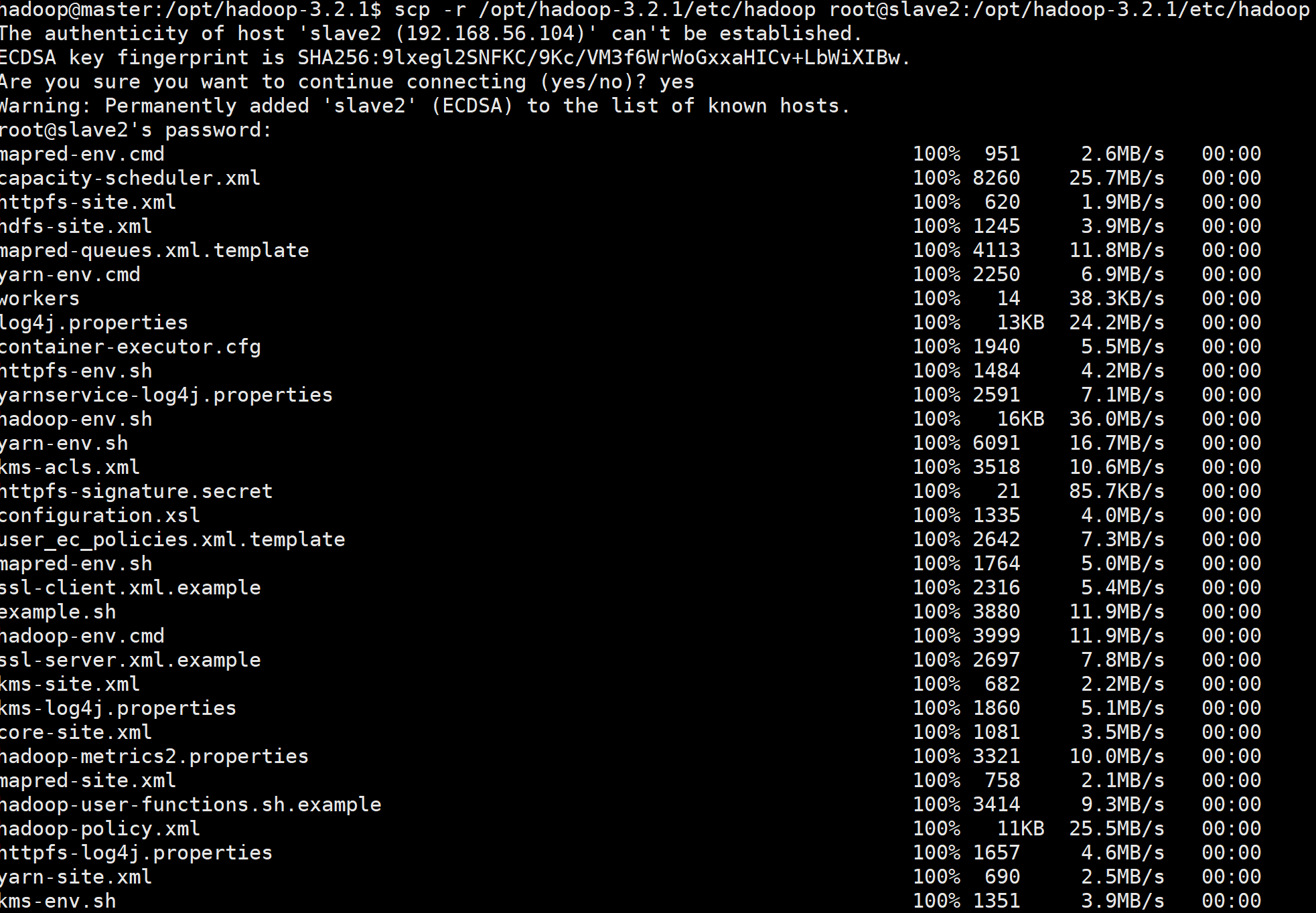
xshell登陆slave1和slave2,执行命令查看文件文件接收情况:
ll /opt/hadoop-3.2.1/etc/


从上图我们可以得知配置文件夹hadoop已经被顺利传输到slave1和2两个节点中;
为方便后续实验,我们对hadoop文件夹访问权限进行升级,slave1、slave2节点均执行:
cd /opt/hadoop-3.2.1/etc/
sudo chmod -R 777 hadoop
以上命令更正为:
cd /opt
sudo chmod -R 777 hadoop-3.2.1
注意:谨慎使用chmod 777 命令,仅限于实验。
实验步骤
启动前准备:
删除Hadoop路径下的临时文件:
rm -rf $HADOOP_HOME/tmp/*
启动NameNode和DataNode(web端口9870)
#1、只在Master节点执行 格式化NameNode,(格式化只需执行一次),执行命令
hdfs namenode -format
#2.只在Master节点启动NameNode
/opt/hadoop-3.2.1/sbin/hadoop-daemon.sh start namenode
#3.在Master及另外两台Slave节点分别启动DataNode:
/opt/hadoop-3.2.1/sbin/hadoop-daemon.sh start datanode
可以使用jps分别在各个节点查看线程是否正常运行:
master:

slave1:

slave2:

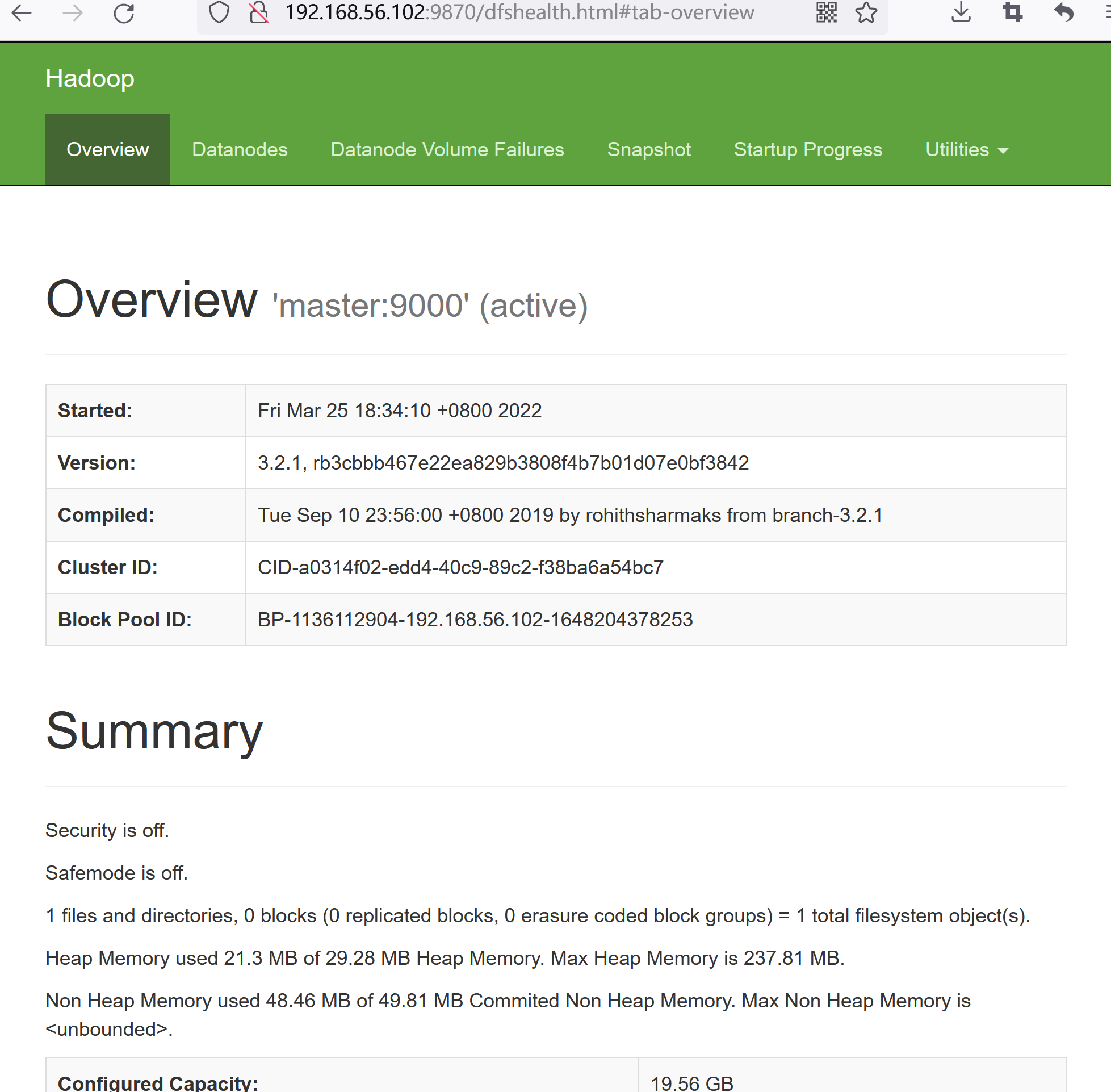
4.使用浏览器打开HDFS WebUI,IP为Master节点的IP:
网址改为:http://192.168.56.102:9870
得到HDFS管理界面:
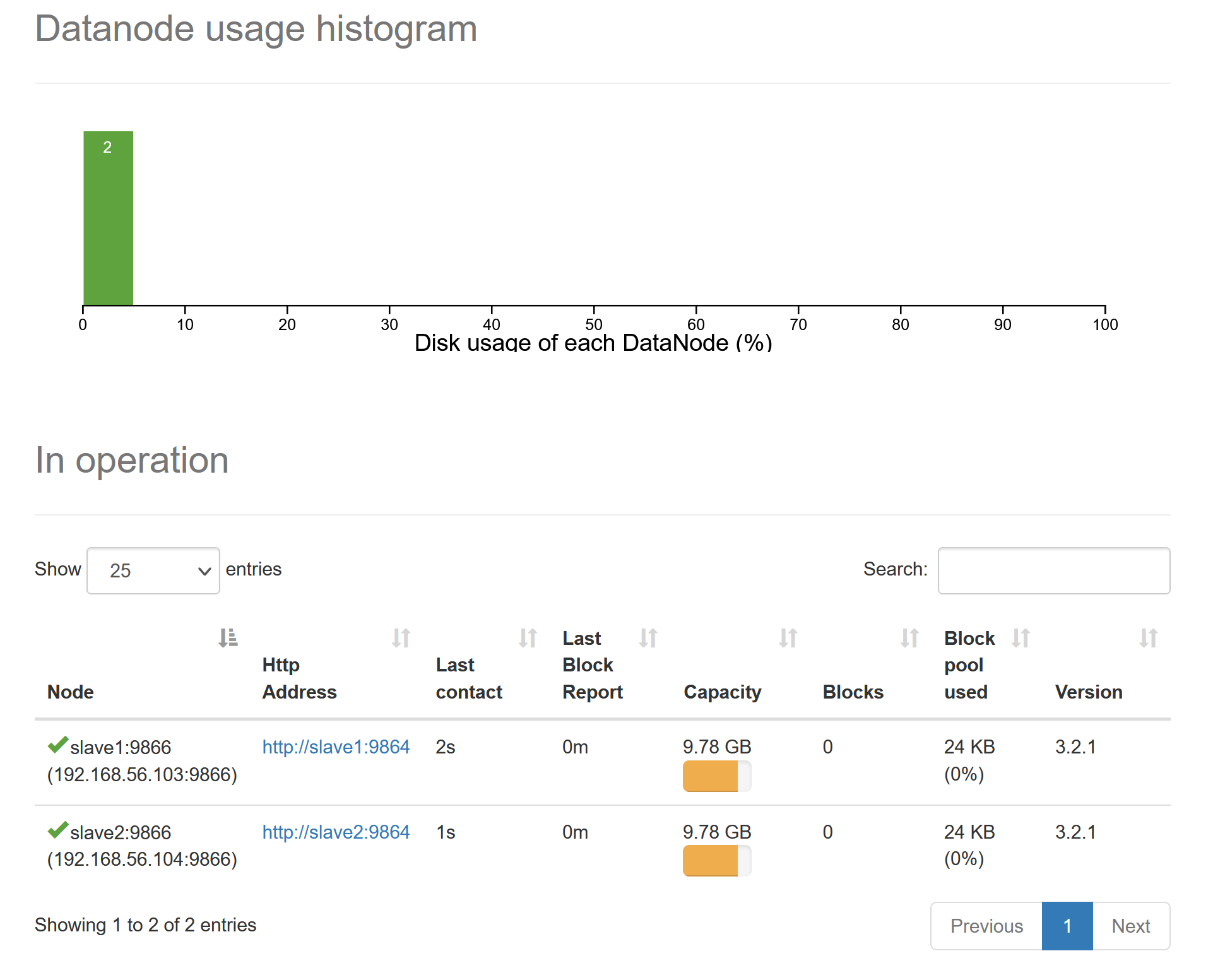
在Datanode标签中可查看如下slave1和slave2节点运行情况:
几点注意事项:
1.如果需要重新格式化 NameNode ,需要先将原来 NameNode 和 DataNode 下的文件全部删除:
rm -rf $HADOOP_HOME/dfs/data/*
rm -rf $HADOOP_HOME/dfs/name/*
2.反复启动未成功(jps命令未显示namenode或datanode运行时)可尝试删除logs,并删除tmp:
#log可酌情删除
rm -rf $HADOOP_HOME/logs/*
#删除临时文件
rm -rf $HADOOP_HOME/tmp/*
3.slave节点上datanode没有被调起,原因可能有很多,比如配置文件出错、虚拟机所需内存不够等,这些问题我们可以通过查看日志文件去分析。
路径如:
cd /opt/hadoop-3.2.1/logs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号