【spark】淘宝双十一数据分析与预测
项目分析
该项目设计数据预处理、存储、查询和可视化分析,涵盖Linux、MySQL,Hadoop、Hive、Sqoop、Echarts、Spark的运用。
项目实现流程
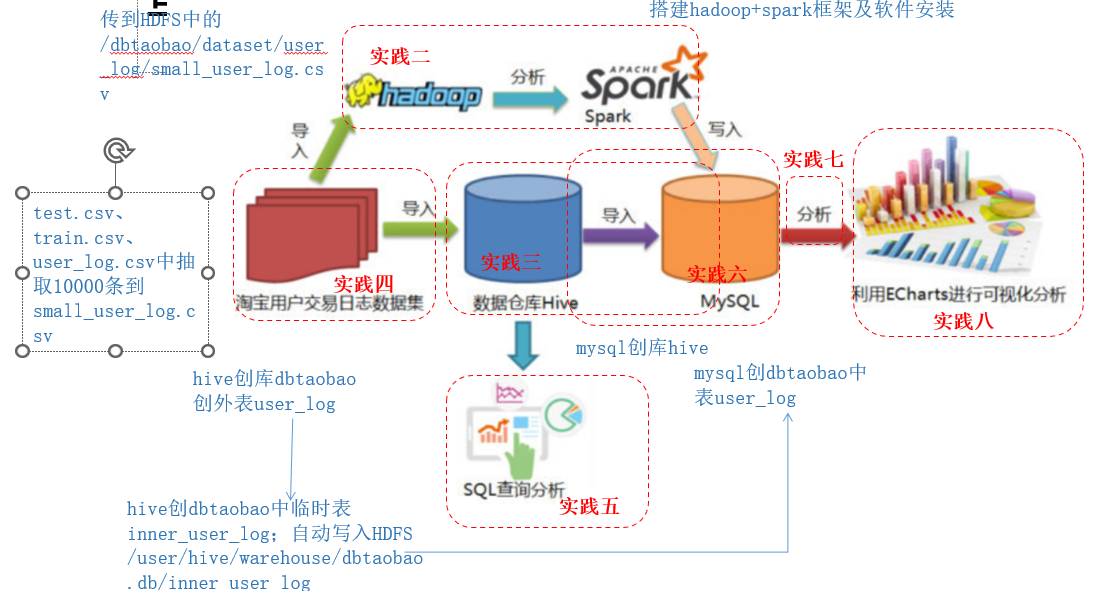
数据集分析
该数据集包含回头客数据集合用户行为日志,日志字段定义如下:
| 数据集 | 序号 | 字段 | 说明 | 取值范围 |
|---|---|---|---|---|
| train.csv test.csv |
1 | user_id | 买家id | |
| 2 | age_range | 买家年龄分段 | 1:年龄<18 2:年龄=[18,24] 3:年龄=[25.29] 4:年龄=[30,34] 5:年龄=[35,39] 6:年龄=[40,49] 7/8:年龄>=50 0/NULL:未知 |
|
| 3 | gender | 性别 | 0:女 1:男 |
|
| 4 | merchant_id | 商家id | ||
| 5 | label | 是否回头客 | 0:不是 1:是 -1:超出预测范围 NULL:测试集 |
|
| user_log.csv | 1 | user_id | 买家_id | |
| 2 | item_id | 商品id | ||
| 3 | cat_id | 商品类别id | ||
| 4 | metchant_id | 卖家id | ||
| 5 | brand_id | 品牌id | ||
| 6 | month | 交易时间:月 | ||
| 7 | day | 交易时间:日 | ||
| 8 | action | 行为 | 0:点击 1:加入购物车 2:购买 3:关注商品 |
|
| 9 | age_range | 买家年龄分段 | 同上 | |
| 10 | gender | 性别 | 同上 | |
| 11 | province | 收货地址省份 |
在安装好hadoop、spark、java、mysql、Hive、sqoop环境的基础上,展开如下操作:
一 本地数据集导入到hive
1.数据集导入本地
2.数据集预处理
3.数据集导入HDFS中
4.在数据仓库hive创建数据库
5.把本地数据集上传到数据仓库
- 数据集导入本地
- 在/usr/local创建dbtaobao,并对dbtaobao赋予操作权限
sudo chown -R hadoop:hadoop ./dbtaobao
- 使用unzip把数据集解压到dbtaobao中
sudo apt install unzip
unzip data_format.zip -d /usr/local/dbtaobao/dataset
- 数据预处理
- 删除文件第一行记录,即字段行
set -i 'l d' user_log.csv
# 查看前五行记录
head -5 user_log.csv
- 获取前100000条数据,生成small_user_log.csv
# 新建一个脚本predeal.sh完成截取任务
#!/bin/bash
infile=$1
outfile=$2
awk -F "," 'BEGIN{
id=0;
}
{
if($6==11&&$7==11)
{
id=id+1;
print($1","$2","$3","$4","$5","$6","$7","$8","$9","$10","$11)
if(id==10000)
{
exit
}
}
}' $infile > $outfile
# 设置脚本权限
chmod+x ./predeal.sh
./predeal.sh ./user_log.csv ./small_user_log.csv
- 数据集导入HDFS中
- 使用put命令把small_user_log.csv导入hive
# 启动hadoop
cd /usr/local/hadoop
./sbin/start-dfs.sh
# 在HDFS创建dbtaobao/dataset
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /dbtaobao/dataset/user_log
# 把small_user_log.csv上传到HDFS
cd/ usr/local/hadoop
./bin/hdfs dfs -put /usr/local/dbtapbap/dataset/small_user_log.cdv /dbtaobao/dataset/user_log
# 查看HDFS中的small_user_log.csv的前10条记录
./bin/hdfs dfs-cat /dbtaobao/dataset/user_log/small_user_log.csv | head -10
- 在数据仓库hive创建数据库
# 启动mysql
service mysql start
# 启动hive
cs /usr/local/hive
./bin/hive
# 创建数据库dbtaobao
create database dbtaobao;
use dbtaobao
# 创建外部表user_log,字段为user_log.csv的字段
create external table dbtaobao.user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_it INT,month STRING,dat STRING,action INT,age_range INT,gender INT,province STRING) comment 'welcome to bigdata training,now create dbtaobao.user_log!'row format delimited fields terinated by ',' sorted as textfile location '/dbtaobao/dataset/user_log'
# 查询数据
select * from user_log limit 10;
二 hive查询分析
1.简单查询分析、查询条数统计分析、关键字条件查询分析、用户行为分析、用户实时查询分析
- 简单查询分析
(1) 查看日志前10个交易日志的商品品牌
(2) 查询前20个交易日志中购买商品时的时间和商品的种类
(3) 利用嵌套语句完成(2)要求,如果列名太复杂可以设置该列的别名,以简化操作的难度 - 查询条数统计分析
(1) 用聚合函数count()计算出表内有多少条行数据
(2) 在函数内部加上distinct,查出uid不重复的数据有多少条
(3) 查询不重复的数据有多少条(为了排除客户刷单情况) - 关键字条件查询分析
(1) 查询双11那天有多少人购买了商品
(2) 取给定时间和给定品牌为2661,求当天购买的此品牌商品的数量 - 用户行为分析
(1) 查询一件商品在某天的购买比例或浏览比例
(2) 查询双11那天,男女买家购买商品的比例
(3) 查询某一天在该网站购买商品超过5次的用户id - 用户实时查询分析
(1) 不同的品牌的浏览次数
三 使用sqoop将数据从hive导入mysql
1.在hive创建临时表inner_user_log
2.mysql创建数据表、视图
3.使用sqoop将数据从hive导入mysql
- 在hive创建临时表innser_user_log
create table tbtaobao.inner_user_log(user_id INT,item_id INT,cat_id INT,merchant_id INT,brand_it INT,month STRING,dat STRING,action INT,age_range INT,gender INT,province STRING) row format delimited fields terminated by ',' sorted as textfile;
- 将user_log表中的数据插入到inner_user_log
insert overwrite table dbtaobao.inner_user_log select * from dbtaobao.user_log;
- mysql创建数据表、视图
- 登录mysql
mysql -u root -p
- 创建数据库dbtaobao
create database dbtaobao;
use dbtaobao;
show varibles like "char%";
- 创建数据表user_log
create table `dbtaobao`.`user_log` (`user_id` varchar(20),`item_id` varchar(20),`cat_id` varchar(20),`merchant_id` varchar(20),`brand_id` varchar(20),`month` varchar(6),`day` varchar(6),`action` varchar(6),`age_range` varchar(10),`gender` varchar(6),`province` varchar(6)) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
- 创建视图
create view user_log-view as select * from user_log;
- 使用sqoop将数据从hive导入mysql
sqoop export --connet jdbc:mysql://localhost:3306/dbtaobao --username root --password root --table user_log --export-dir '/usr/hive/warehouse/dbtaobao.db/inner_user_log' --fields-terminated-by ',';
四 使用spark预测回头客
1.预处理数据集test.csv和train.csv
2.将预处理后的数据存入HDFS中
3.在mysql创建数据表
4.使用svm预测回头客
- 添加预处理脚本predeal_test.sh,label字段表示-1值剔除掉,保留需要预测的数据.并假设需要预测的数据中label字段均为1
#!/bin/bash
infile=$1
outfile=$2
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && !$5){
id=id+1;
print $1","$2","$3","$4","1
if(id==10000){
exit
}
}
}' $infile > $outfile
chmod +x ./predeal_test.sh
- 执行预处理脚本,生成test_after.csv
cd /usr/local/dbtaobao/dataset
./predeal_test.sh ./test.csv ./test_after.csv
- 删除train.csv的首行字段
set -i 'ld' train.csv
- 剔除train.csv中字段值为空的数据,生成train_afer.csv
#!/bin/bash
infile=$1
outfile=$2
awk -F "," 'BEGIN{
id=0;
}
{
if($1 && $2 && $3 && $4 && ($5!=-1)){
id=id+1;
print $1","$2","$3","$4","$5
if(id==10000){
exit
}
}
}' $infile > $outfile
- 将预处理后的数据存入HDFS中(因为在pyspark中会读取hdfs的数据)
hadoop fs -put /usr/local/dbtaobao/dataset/train_after.csv /dbtaobao/dataset
hadoop fs -put /usr/local/dbtaobao/dataset/test_after.csv /dbtaobao/dataset
- 在mysql创建数据表
create table rebuy (score varchar(40),label varchar(40));
- 使用svm预测回头客
- 导入mysql驱动包
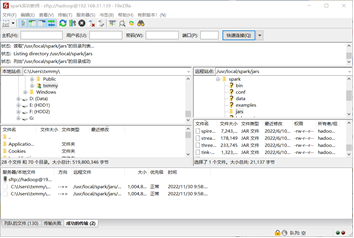
- 启动pyspark
cd /usr/local/spark
./bin/pyspark --jars /usr/local/spark/jars/mysql-connector-java-5.1.46-bin.jar --driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.46-bin.jar
- 导入所需要的包
mkdir /usr/local/spark/mycode
cd /usr/local/spark/mycode/svm_usr.py
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.linalg import Vectors,Vector
from pyspark.mllib.classification import SVMModel,SVMWithSGD
from pyspark.sql.types import Row
from pyspark.sql.types import *
# 读取训练数据
sc=SparkContext.getOrCreate()
train_data=sc.textFile("/dbtaobao/dataset/train_after.csv")
test_data=sc.textFile("/dbtaobao/dataset/test_after.csv")
def GetParts(line):
parts=line.split(",")
return LabeledPoint(float(parts[4]),Vectors.dense(float(parts[1]),float(parts[2]),float(parts[3])))
train=train_data.map(lambda line:GetParts(line))
test=test_data.map(lambda line:GetParts(line))
epochs=100
# 构建和训练模型
model=SVMWithSGD.train(train,epochs)
# 卡着不动则执行,即ctrl+c后,再次执行语句
model.clearThreshold()
- 评估模型
def Getpoint(point):
score=model.predict(point.features)
return str(score)+" "+str(point.label)
model.clearThreshold()
scoreAndLab=test.map(lambda point:Getpoint(point))
scoreAndLab.foreach(lambda x:print(x))
- 评估结果添加到数据库中
rebuyRDD=scoreAndLab.map(lambda x:x.split(" "))
# 设置模式信息
schema=StructType([StrucField("score",StringType(),True),StrucField("label",StringType(),True)])
# 创建Row对象,每个Row对象都是rowRDD中的一行
rebuyDF=spark.createDataFrame(rowRDD,schema,True)
# 创建一个prop变量保存JDBS连接参数
prop={}
prop['user']='root'
prop['password']='root'
prop['driver']='com.mysql.jdbc.Driver'
# 连接数据库,使用append模式
rebuyDF.write.jdbc("jdbc:mysql://localhost:3306/dbtaobao",'dbtaobao.rebuy','append',prop)
五 使用Echarts制作可视化图表
1.搭建tomcat+mysql+JSP
2.使用eclipse搭建web应用
- 搭建tomcat+mysql+JSP
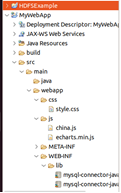
- 新建项目MyWebApp,导入js、css、mysql驱动文件
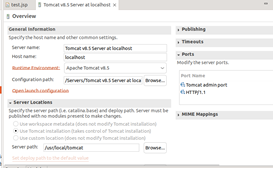
- 配置tomcat服务器
- 使用eclipse搭建web应用
-
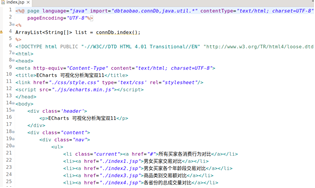
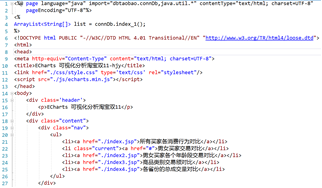
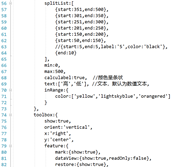
创建前端index.jsp



-
创建前端index1.jsp


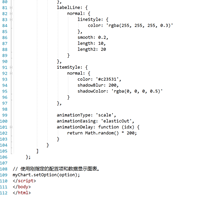
-
创建前端index2.jsp



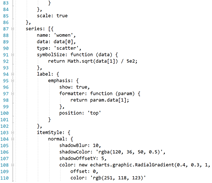
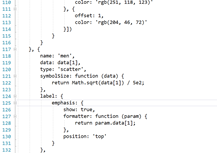

-
创建前端index3.jsp



-
创建前端index4.jsp

65-1382748803.png)

758593-1776881578.png)
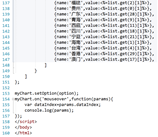
-
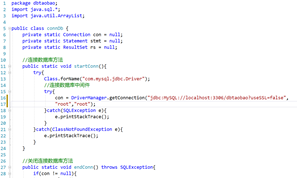
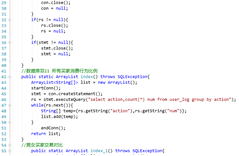
创建后端连接数据库的类connDb


预览图:
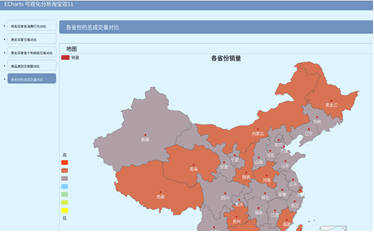
总结
- 可以进一步使用其他前端框架实现可视化
- pyspark训练时速度较慢,能否结合gpu进行训练?如何解决pyspark训练太慢的问题
- 可以进一步部署该项目
- 使用spark完成实时分析项目

 浙公网安备 33010602011771号
浙公网安备 33010602011771号